
Maison >Périphériques technologiques >IA >Aperçu GPT-5 ! L'Allen Institute for Artificial Intelligence publie le modèle multimodal le plus puissant pour prédire les nouvelles capacités de GPT-5
Aperçu GPT-5 ! L'Allen Institute for Artificial Intelligence publie le modèle multimodal le plus puissant pour prédire les nouvelles capacités de GPT-5

- PHPzavant
- 2024-01-11 18:21:41641parcourir
Quand GPT-5 arrivera-t-il et quelles capacités aura-t-il ?
Un nouveau modèle de l'Allen Institute for AI vous donne la réponse.
Unified-IO 2 lancé par l'Allen Institute for Artificial Intelligence est le premier modèle capable de traiter et de générer du texte, des images, de l'audio, de la vidéo et des séquences d'action.
Ce modèle d'IA avancé est entraîné à l'aide de milliards de points de données. La taille du modèle n'est que de 7 B, mais il présente les capacités multimodales les plus larges à ce jour.

Adresse papier : https://arxiv.org/pdf/2312.17172.pdf
Alors, quelle est la relation entre Unified-IO 2 et GPT-5 ?
En juin 2022, l'Allen Institute for Artificial Intelligence a lancé la première génération d'Unified-IO, devenant ainsi l'un des modèles multimodaux capables de traiter simultanément des images et du langage.
À peu près au même moment, OpenAI teste GPT-4 en interne et le publiera officiellement en mars 2023.
Unified-IO peut donc être considéré comme un aperçu des futurs modèles d'IA à grande échelle.
Cela dit, OpenAI teste peut-être GPT-5 en interne et le publiera dans quelques mois.
Les capacités que nous montre Unified-IO 2 cette fois seront également ce que nous pouvons espérer au cours de la nouvelle année :
GPT-5 et d'autres nouveaux modèles d'IA peuvent gérer plus de modalités, un apprentissage approfondi pour effectuer de nombreuses tâches de manière locale et avoir une compréhension de base de l'interaction avec des objets et des robots.
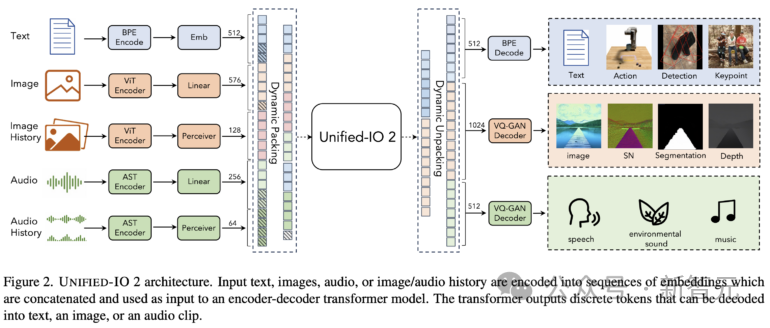
Les données d'entraînement d'Unified-IO 2 comprennent : 1 milliard de paires image-texte, 1 000 milliards de balises de texte, 180 millions de clips vidéo, 130 millions d'images avec texte, 3 millions d'actifs 3D et 1 million de séquences de mouvements d'agents robots.
L'équipe de recherche a combiné un total de plus de 120 ensembles de données dans un package de 600 To couvrant 220 tâches visuelles, langagières, auditives et motrices.
Unified-IO 2 adopte une architecture encodeur-décodeur avec quelques modifications pour stabiliser l'entraînement et utiliser efficacement les signaux multimodaux.
Le modèle peut répondre aux questions, écrire du texte selon les instructions et analyser le contenu du texte.
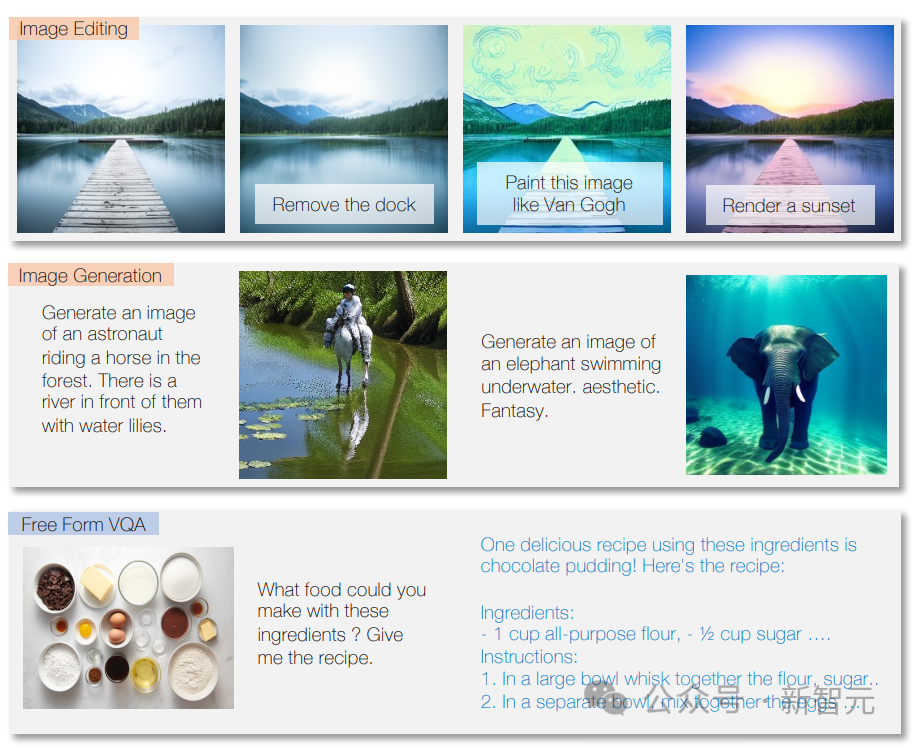
Le modèle peut également identifier le contenu de l'image, fournir des descriptions d'image, effectuer des tâches de traitement d'image et créer de nouvelles images basées sur des descriptions textuelles.
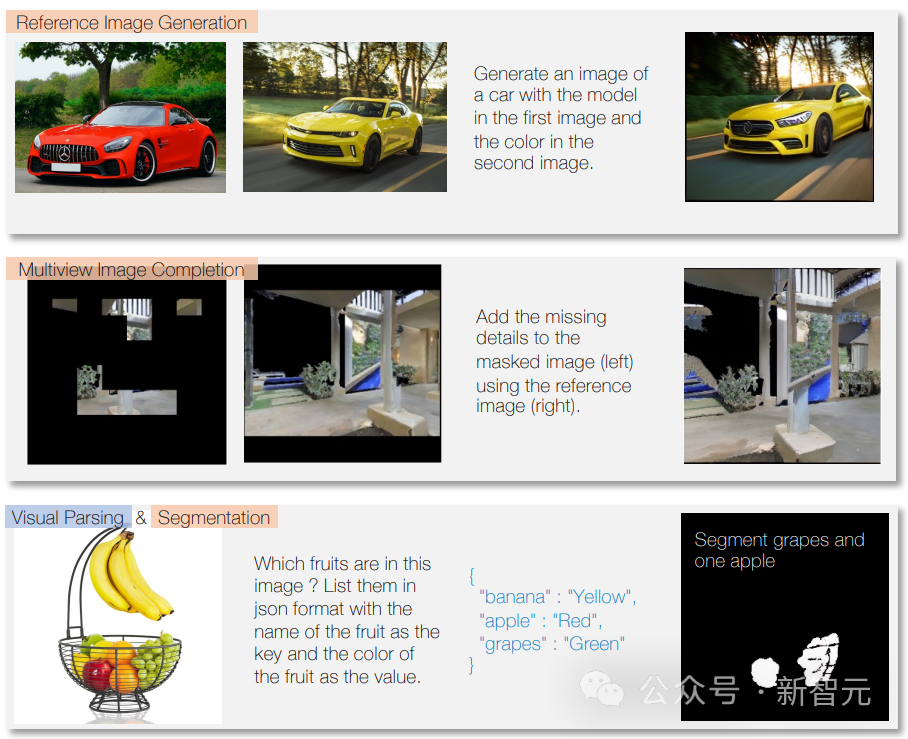
Il peut également générer de la musique ou des sons en fonction de descriptions ou d'instructions, ainsi qu'analyser des vidéos et répondre à des questions à leur sujet.
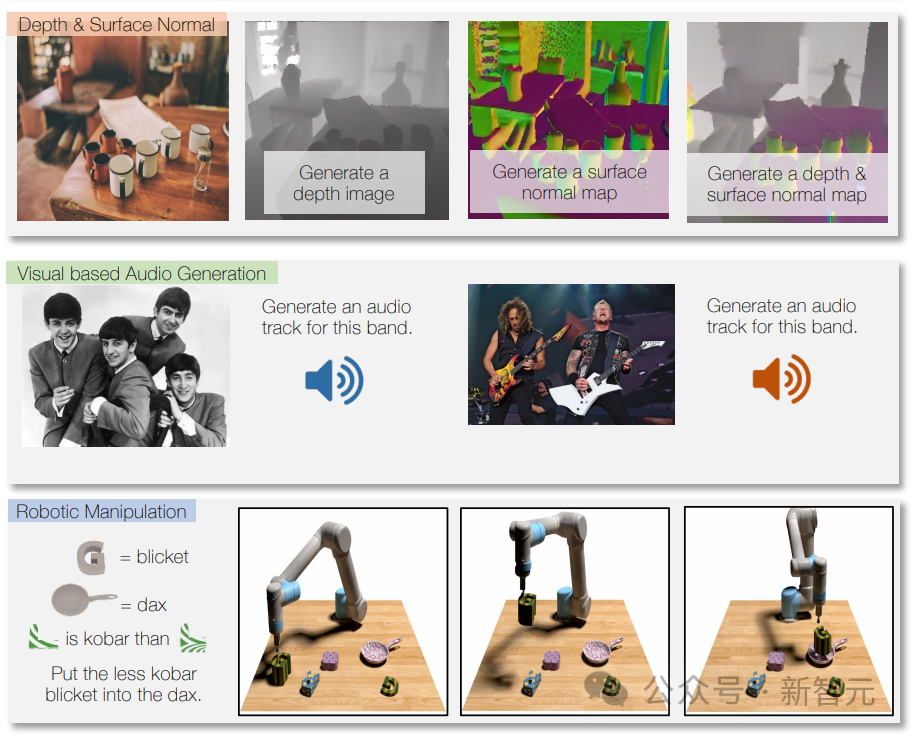
En utilisant les données du robot pour l'entraînement, Unified-IO 2 peut également générer des actions pour le système du robot, telles que la conversion d'instructions en séquences d'action pour le robot.
Grâce à la formation multimodale, il peut également gérer différentes modalités, par exemple l'étiquetage des instruments utilisés dans une certaine piste sur l'image.

Unified-IO 2 fonctionne bien sur plus de 35 tests, notamment la génération et la compréhension d'images, la compréhension du langage naturel, la compréhension vidéo et audio et la manipulation robotique.
Dans la plupart des tâches, il est aussi bon ou meilleur que les modèles dédiés.
Unified-IO 2 a obtenu le score le plus élevé jusqu'à présent sur le benchmark GRIT pour les tâches d'image (GRIT est utilisé pour tester la façon dont un modèle gère le bruit de l'image et d'autres problèmes).
Les chercheurs prévoient désormais d'étendre davantage Unified-IO 2, d'améliorer la qualité des données et de transformer le modèle codeur-décodeur en une architecture de modèle de décodeur standard de l'industrie.
Unified-IO 2
Unified-IO 2 est le premier modèle multimodal autorégressif capable de comprendre et de générer des images, du texte, de l'audio et du mouvement.
Pour unifier différentes modalités, les chercheurs étiquetent les entrées et les sorties (images, texte, audio, actions, cadres de délimitation, etc.) dans un espace sémantique partagé, puis utilisent un seul modèle de transformateur encodeur-décodeur pour le traiter.
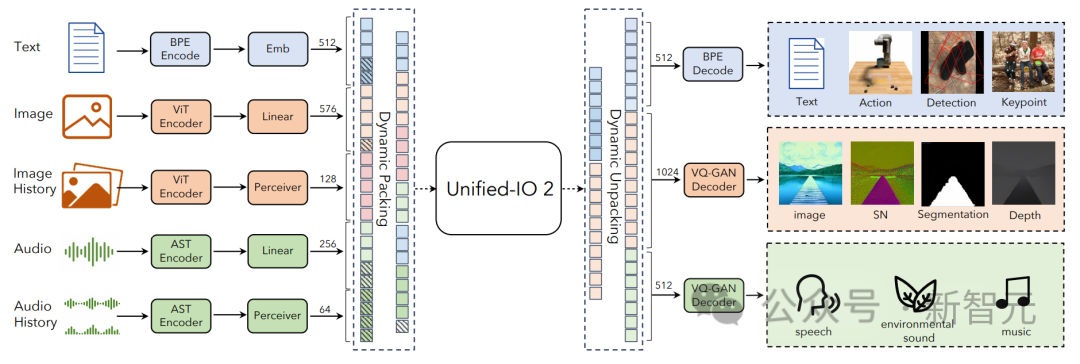
En raison de la grande quantité de données utilisées pour entraîner le modèle et provenant de différentes modalités, les chercheurs ont adopté une série de techniques pour améliorer l'ensemble du processus de formation.
Pour faciliter efficacement l'apprentissage auto-supervisé des signaux selon plusieurs modalités, les chercheurs ont développé un nouvel hybride multimodal de cibles de débruitage qui combine le débruitage et la génération multimodaux.
Le packaging dynamique a également été développé pour multiplier par 4 le débit d'entraînement afin de gérer des séquences très variables.
Pour surmonter les problèmes de stabilité et d'évolutivité lors de la formation, les chercheurs ont apporté des modifications architecturales au rééchantillonneur de perceptron, notamment l'intégration de la rotation 2D, la normalisation QK et le mécanisme d'attention du cosinus mis à l'échelle.
Pour les ajustements de commande, assurez-vous que chaque mission dispose d'une invite claire, que ce soit en utilisant une mission existante ou en en créant une nouvelle. Des tâches ouvertes sont également incluses et des tâches synthétiques sont créées pour des modèles moins courants afin d'améliorer la variété des tâches et de l'enseignement.
Représentation unifiée des tâches
encode les données multimodales en séquences de jetons dans un espace de représentation partagé, y compris les aspects suivants :
Texte, structures et opérations clairsemées
L'entrée de texte et la sortie sont tokenisées à l'aide du codage par paire d'octets dans LLaMA, les structures clairsemées telles que les cadres de délimitation, les points clés et les poses de caméra sont discrétisées puis codées à l'aide de 1 000 jetons spéciaux ajoutés au vocabulaire.
Les points sont codés à l'aide de deux marqueurs (x, y), les cases sont codées avec une séquence de quatre marqueurs (en haut à gauche et en bas à droite) et les cuboïdes 3D sont représentés avec 12 marqueurs (codage du centre de projection, profondeur virtuelle, paire (nombre de tailles de boîtes normalisées et rotation concentrique continue).
Pour les tâches incarnées, les actions discrètes du robot sont générées sous forme de commandes textuelles (par exemple, "avancer"). Des balises spéciales sont utilisées pour coder l'état du robot (comme la position et la rotation).
Images et structures denses
Les images sont codées à l'aide de transformateurs visuels pré-entraînés (ViT). Les fonctionnalités de patch de la deuxième et de l’avant-dernière couches de ViT sont concaténées pour capturer des informations visuelles de bas niveau et de haut niveau.
Lors de la génération d'une image, utilisez VQ-GAN pour convertir l'image en marqueurs discrets. Ici, un modèle VQ-GAN dense pré-entraîné avec une taille de patch de 8 × 8 est utilisé pour encoder l'image 256 × 256 en. 1024 jetons et livre de codes. La taille est de 16512.
Représentez ensuite l'étiquette de chaque pixel (y compris la profondeur, la normale à la surface et le masque de segmentation binaire) sous la forme d'une image RVB.
Audio
U-IO 2 encode jusqu'à 4,08 secondes d'audio dans un spectrogramme, puis utilise un convertisseur de spectrogramme audio (AST) pré-entraîné pour encoder le spectrogramme et concatène les AST. Les caractéristiques de la deuxième et avant-dernière couche et appliquez un calque linéaire pour créer l'intégration d'entrée, tout comme l'image ViT.
Lors de la génération de l'audio, utilisez ViT-VQGAN pour convertir l'audio en jetons discrets. La taille du patch du modèle est de 8 × 8 et le spectrogramme 256 × 128 est codé en 512 jetons. La taille du livre de codes est de 8 196.
Historique de l'image et de l'audio
Le modèle permet de fournir jusqu'à quatre segments d'image et audio supplémentaires en entrée, ces éléments sont également codés à l'aide de ViT ou AST, puis à l'aide d'un rééchantillonneur de perceptron, les fonctionnalités sont encore plus avancées. compressé en nombre inférieur (32 pour les images et 16 pour l’audio).
Cela réduit considérablement la longueur de la séquence et permet au modèle d'examiner des images ou des clips audio en détail tout en utilisant des éléments de l'historique comme contexte.
Architecture et technologie de modèle pour une formation stable
Les chercheurs ont observé qu'à mesure que nous intégrons d'autres modes, les implémentations standard après l'utilisation d'U-IO conduisent à une formation de plus en plus instable.
Comme le montrent les points (a) et (b) ci-dessous, l'entraînement uniquement sur la génération d'images (courbe verte) conduit à une perte stable et à une convergence des normes de gradient.
L'introduction de la combinaison de tâches d'image et de texte (courbe orange) augmente légèrement la norme de gradient par rapport à la modalité unique, mais reste stable. Cependant, l’inclusion de la modalité vidéo (courbe bleue) entraîne une amélioration illimitée de la norme de gradient.
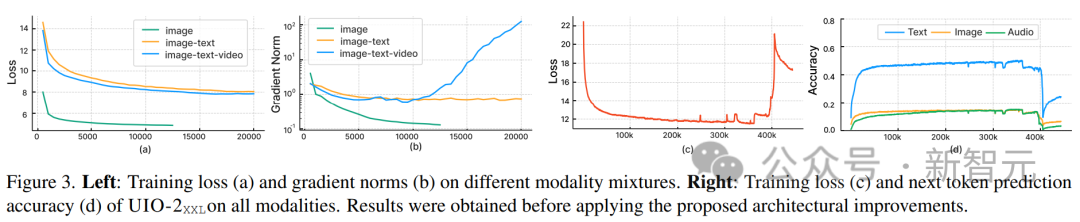
Comme le montrent les points (c) et (d) de la figure, lorsque la version XXL du modèle est entraînée sur toutes les modalités, la perte explose après 350 000 pas et la précision de prédiction du marqueur suivant apparaît à 400 000 pas en chute libre.
Pour résoudre ce problème, les chercheurs ont apporté diverses modifications architecturales :
Appliquez l'intégration de position de rotation (RoPE) à chaque couche du transformateur. Pour les modalités non textuelles, RoPE est étendu aux emplacements 2D ; lorsque les modalités image et audio sont incluses, LayerNorm est appliqué à Q et K avant les calculs d'attention aux produits scalaires.
De plus, à l'aide d'un rééchantillonneur de perceptron, chaque image et clip audio sont compressés en un nombre fixe de jetons, et en utilisant une attention cosinusoïdale mise à l'échelle pour appliquer une normalisation plus stricte dans le perceptron, qui est un train considérablement stable.
Pour éviter l'instabilité numérique, le logarithme d'attention float32 est également activé, et ViT et AST sont gelés pendant la pré-entraînement et affinés à la fin de l'ajustement des instructions.
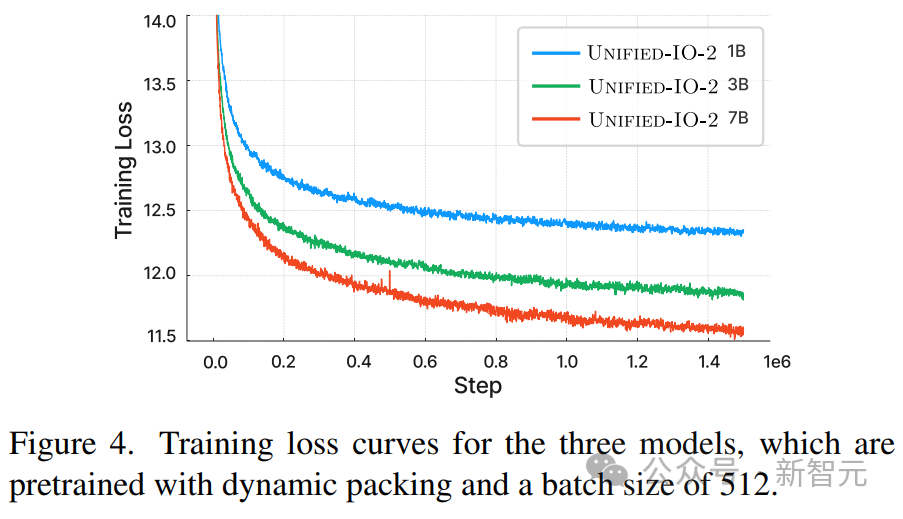
La figure ci-dessus montre que malgré l'hétérogénéité des modalités d'entrée et de sortie, la perte pré-entraînement du modèle est stable.
Objectifs de formation multimodales
Cet article suit le paradigme UL2. Pour les cibles image et audio, deux paradigmes similaires sont définis ici :
[R] : masquer le débruitage, masquer aléatoirement x% des caractéristiques de l'image ou du patch audio d'entrée et laisser le modèle le reconstruire
[S] ; : Nécessite que le modèle génère la modalité cible dans d'autres conditions modales d'entrée.
Pendant la formation, préfixez le texte saisi avec un marqueur modal ([Texte], [Image] ou [Audio]) et un marqueur de paradigme ([R], [S] ou [X]) pour indiquer la tâche , et utilisez le masquage dynamique pour l'autorégression.
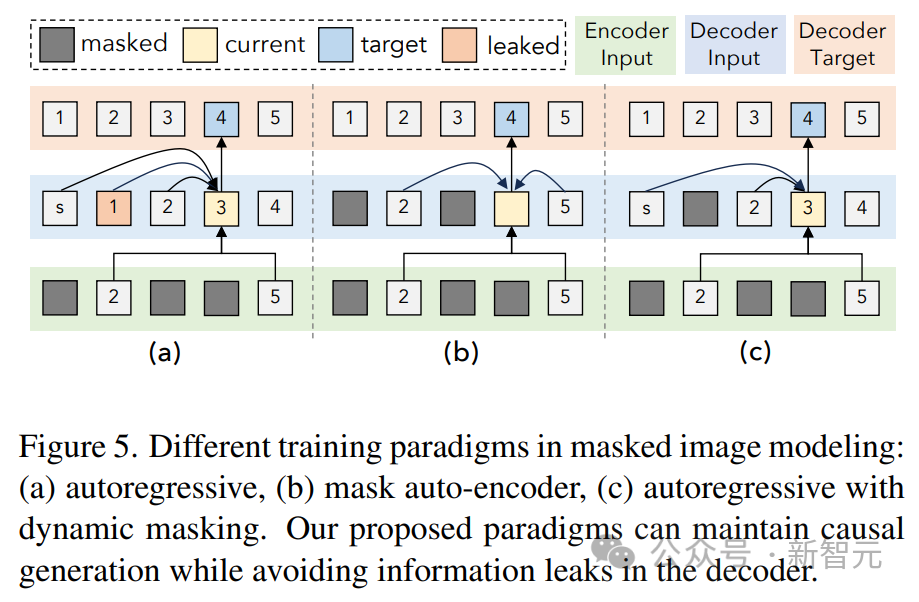
Comme le montre la figure ci-dessus, un problème avec le débruitage du masquage d'image et audio est la fuite d'informations du côté du décodeur.
La solution ici est de masquer le jeton dans le décodeur (à moins de prédire ce jeton), ce qui n'interfère pas avec la prédiction causale tout en éliminant les fuites de données.
Optimisation de l'efficacité
La formation sur une grande quantité de données multimodales se traduira par des longueurs de séquence très variables pour l'entrée et la sortie du convertisseur.
Le packaging est utilisé ici pour résoudre ce problème : les balises de plusieurs exemples sont regroupées dans une séquence et l'attention est protégée pour empêcher les convertisseurs de s'engager de manière croisée entre les exemples.
Pendant la formation, un algorithme heuristique est utilisé pour réorganiser les données transmises au modèle afin que les échantillons longs correspondent à des échantillons courts pouvant être compressés. Le packaging dynamique de cet article augmente le débit de formation de près de 4 fois.
Réglage des instructions
Le réglage des instructions multimodales est un processus clé pour doter le modèle de différentes compétences et capacités pour diverses modalités, et même s'adapter à des instructions nouvelles et uniques.
Les chercheurs créent un ensemble de données de réglage des instructions multimodales en combinant un large éventail d'ensembles de données et de tâches supervisées.
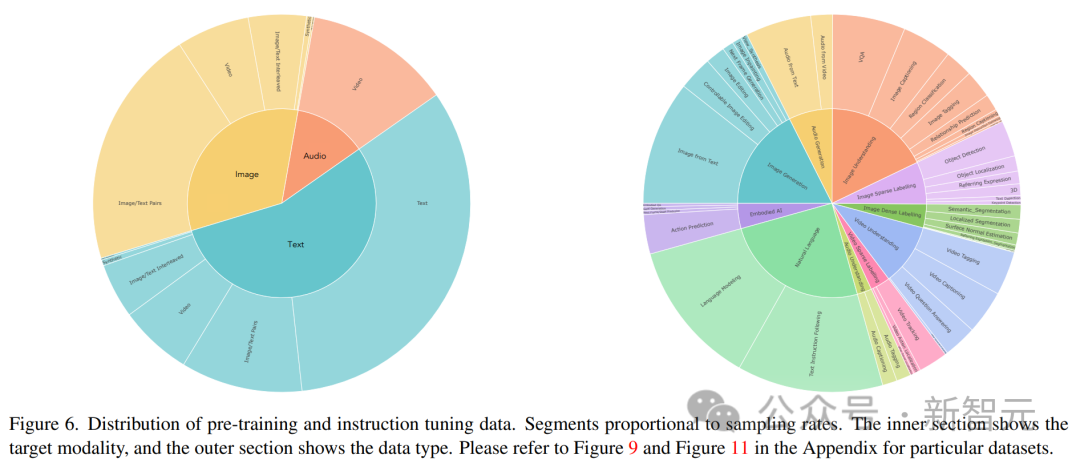
La distribution des données de réglage des commandes est illustrée dans la figure ci-dessus. Dans l'ensemble, le mélange de réglage des instructions comprenait 60 % de données d'indices, 30 % de données héritées de la pré-formation (pour éviter un oubli catastrophique), 6 % de données d'augmentation de tâches construites à l'aide de sources de données existantes et 4 % de texte de forme libre (pour activer le chat). -comme les réponses).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que le modèle de données relationnelles
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?
- Application et recherche de recherche d'industrie basée sur un modèle de langage pré-entraîné
- Les programmeurs sont en danger ! On dit qu'OpenAI recrute des troupes d'externalisation dans le monde entier et forme étape par étape les agriculteurs de code ChatGPT.
- NUS et Byte ont collaboré de manière intersectorielle pour obtenir une formation 72 fois plus rapide grâce à l'optimisation des modèles, et ont remporté le prix AAAI2023 Outstanding Paper.