
Maison >Périphériques technologiques >IA >La technologie TF-T2V développée conjointement par Huake, Ali et d'autres sociétés réduit le coût de production vidéo IA !
La technologie TF-T2V développée conjointement par Huake, Ali et d'autres sociétés réduit le coût de production vidéo IA !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-11 16:12:201283parcourir
Au cours des deux dernières années, avec l'ouverture d'ensembles de données d'images et de textes à grande échelle tels que LAION-5B, une série de méthodes étonnantes ont émergé dans le domaine de la génération d'images, telles que Stable Diffusion, DALL-E 2, ControlNet et Composer. L’émergence de ces méthodes a permis de grandes percées et progrès dans le domaine de la génération d’images. Le domaine de la génération d’images s’est développé rapidement au cours des deux dernières années seulement.
Cependant, la génération vidéo est encore confrontée à d'énormes défis. Premièrement, par rapport à la génération d’images, la génération vidéo doit traiter des données de plus grande dimension et prendre en compte des dimensions temporelles supplémentaires, ce qui pose le problème de la modélisation temporelle. Pour favoriser l’apprentissage de la dynamique temporelle, nous avons besoin de davantage de données sur les paires vidéo-texte. Cependant, une annotation temporelle précise des vidéos est très coûteuse, ce qui limite la taille des ensembles de données vidéo-texte. Actuellement, l'ensemble de données vidéo WebVid10M existant ne contient que 10,7 millions de paires vidéo-texte. Par rapport à l'ensemble de données d'images LAION-5B, la taille des données est très différente. Cela restreint considérablement la possibilité d’une expansion à grande échelle des modèles de génération vidéo.
Pour résoudre les problèmes ci-dessus, l'équipe de recherche conjointe de l'Université des sciences et technologies de Huazhong, du groupe Alibaba, de l'université du Zhejiang et du groupe Ant a récemment publié la solution vidéo TF-T2V :

Paper adresse : https://arxiv.org/abs/2312.15770
Page d'accueil du projet : https://tf-t2v.github.io/
Le code source sera bientôt publié : https://github.com /ali-vilab/i2vgen -xl (projet VGen).
Cette solution adopte une nouvelle approche et propose une génération de vidéo basée sur des données vidéo annotées sans texte à grande échelle, qui peuvent apprendre une dynamique de mouvement riche.
Tout d'abord, jetons un coup d'œil à l'effet de génération vidéo du TF-T2V :
Tâche vidéo Vincent
Mots rapides : générer une vidéo d'une grande créature ressemblant à du givre sur la neige- terrain couvert.

Mot rapide : Générez une vidéo animée d'une abeille de dessin animé.

Mot rapide : Générez une vidéo contenant une moto fantastique futuriste.

Mot rapide : Générez une vidéo d'un petit garçon souriant joyeusement.

Mot rapide : Générez une vidéo d'un vieil homme ressentant un mal de tête. Tâche de génération vidéo combinée synthèse vidéo en résolution :

Réglage semi-supervisé
La méthode TF-T2V dans le cadre semi-supervisé peut également générer des vidéos qui correspondent à la description textuelle du mouvement, telles que "Les gens courent de droite à gauche".


Introduction à la méthode
L'idée principale de TF-T2V est de diviser le modèle en une branche de mouvement et une branche d'apparence. La branche de mouvement est utilisée pour modéliser la dynamique du mouvement, et. la branche apparence est utilisée pour apprendre les informations apparentes. Ces deux branches sont formées conjointement et peuvent enfin réaliser une génération vidéo basée sur du texte.
Afin d'améliorer la cohérence temporelle des vidéos générées, l'équipe d'auteur a également proposé une perte de cohérence temporelle pour apprendre explicitement la continuité entre les images vidéo.
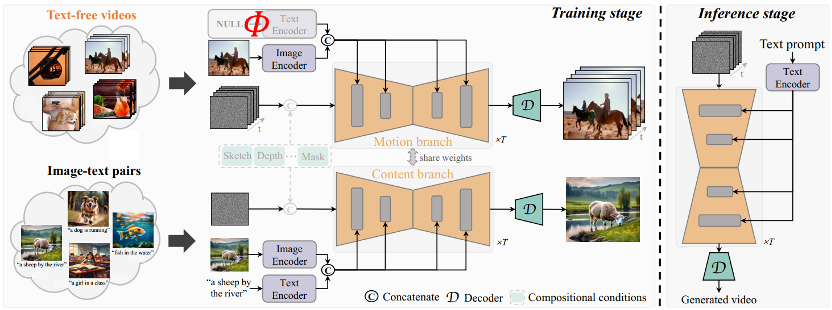
Il convient de mentionner que TF-T2V est un cadre général qui convient non seulement aux tâches vidéo Vincent, mais également aux tâches de génération vidéo combinées, telles que le croquis en vidéo, l'inpainting vidéo, la première image. -vers la vidéo, etc.
Pour des détails spécifiques et des résultats plus expérimentaux, veuillez vous référer à l'article original ou à la page d'accueil du projet.
De plus, l'équipe d'auteurs a également utilisé TF-T2V comme modèle d'enseignant et a utilisé une technologie de distillation cohérente pour obtenir le modèle VideoLCM :

Adresse papier : https://arxiv.org/abs/ 2312.09109
Page d'accueil du projet : https://tf-t2v.github.io/
Le code source sera bientôt publié : https://github.com/ali-vilab/i2vgen-xl (projet VGen) .
Contrairement à la méthode de génération vidéo précédente qui nécessitait environ 50 étapes de débruitage DDIM, la méthode VideoLCM basée sur TF-T2V peut générer des vidéos haute fidélité avec seulement environ 4 étapes de débruitage d'inférence, ce qui améliore considérablement l'efficacité de la génération vidéo. efficacité.
Jetons un coup d'œil aux résultats de l'inférence de débruitage en 4 étapes de VideoLCM :

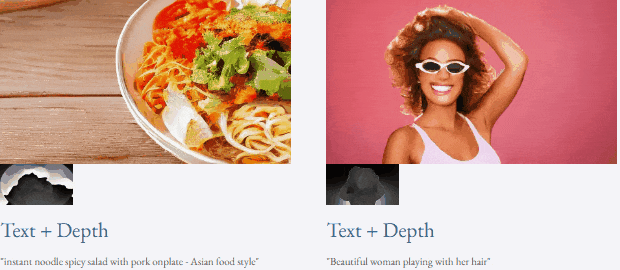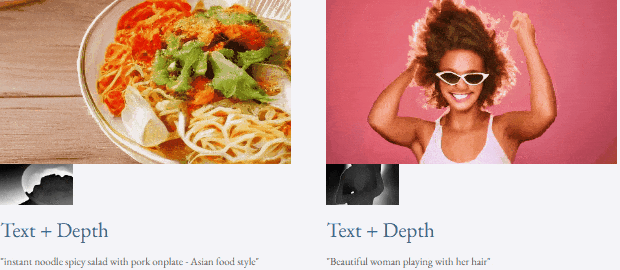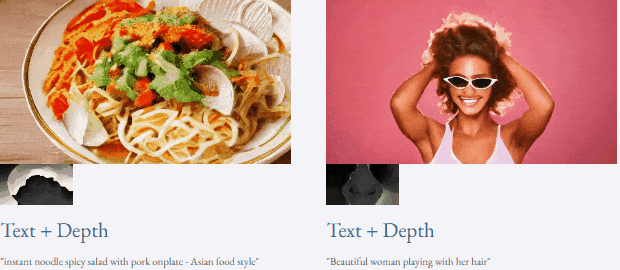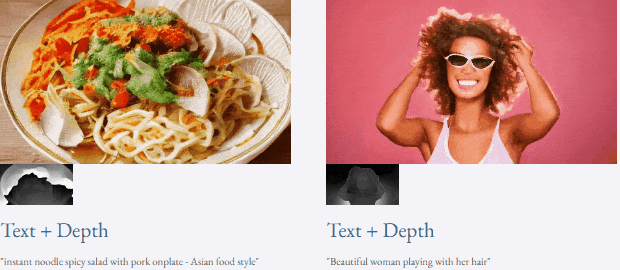

Pour des détails spécifiques et des résultats plus expérimentaux, veuillez vous référer à l'article original de VideoLCM ou au projet page d'accueil.
Dans l'ensemble, la solution TF-T2V apporte de nouvelles idées dans le domaine de la génération vidéo et surmonte les défis posés par la taille des ensembles de données et les problèmes d'étiquetage. Tirant parti des données vidéo d'annotation sans texte à grande échelle, TF-T2V est capable de générer des vidéos de haute qualité et est appliqué à une variété de tâches de génération vidéo. Cette innovation favorisera le développement de la technologie de génération vidéo et apportera des scénarios d'application et des opportunités commerciales plus larges à tous les horizons.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les 10 dernières recommandations de didacticiels vidéo thinkphp en 2023
- Recommandation du didacticiel Vue : 5 dernières sélections de didacticiels vidéo vue.js en 2023
- Quelles sont les raisons et les solutions à l'échec de la connexion à la base de données ?
- Comment insérer une vidéo en HTML
- Que signifie la vidéo 91 ?