
Maison >Périphériques technologiques >IA >PixelLM, un grand modèle multimodal d'octets qui implémente efficacement le raisonnement au niveau des pixels sans dépendance SA
PixelLM, un grand modèle multimodal d'octets qui implémente efficacement le raisonnement au niveau des pixels sans dépendance SA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-10 21:46:36692parcourir
Les grands modèles multimodaux explosent. Êtes-vous prêt à vous lancer dans des applications pratiques dans des tâches précises telles que l'édition d'images, la conduite autonome et la robotique ?
À l'heure actuelle, les capacités de la plupart des modèles sont encore limitées à la génération de descriptions textuelles de l'image globale ou de zones spécifiques, et leurs capacités de compréhension au niveau des pixels (telles que la segmentation d'objets) sont relativement limitées.
En réponse à ce problème, certains travaux ont commencé pour explorer l'utilisation de grands modèles multimodaux pour gérer les instructions de segmentation des utilisateurs (par exemple, "Veuillez segmenter les fruits riches en vitamine C dans l'image").
Cependant, les méthodes disponibles sur le marché souffrent de deux inconvénients principaux :
1) Incapacité à gérer des tâches impliquant plusieurs objets cibles, ce qui est indispensable dans des scénarios réels
2) S'appuyer sur des outils comme SAM Pour un tel pré-apprentissage ; -modèle de segmentation d'image entraîné, la quantité de calcul requise pour une propagation directe de SAM est suffisante pour que Llama-7B génère plus de 500 jetons.
Afin de résoudre ce problème, l'équipe de création intelligente de ByteDance s'est associée à des chercheurs de l'Université Jiaotong de Pékin et de l'Université des sciences et technologies de Pékin pour proposer PixelLM, le premier modèle d'inférence efficace à grande échelle au niveau des pixels qui ne repose pas sur SAM.
Avant de l'introduire en détail, expérimentons les effets réels de segmentation de plusieurs groupes de PixelLM :
Par rapport aux travaux précédents, les avantages de PixelLM sont :
- Il peut gérer habilement n'importe quel nombre de cibles de domaine ouvert et divers raisonnements complexes. Divisez les tâches.
- Éviter les modèles de segmentation supplémentaires et coûteux, améliorer l'efficacité et les capacités de migration vers différentes applications.
De plus, afin de soutenir la formation et l'évaluation des modèles dans ce domaine de recherche, l'équipe de recherche a construit un ensemble de données MUSE pour des scénarios de segmentation de raisonnement multi-objectifs basés sur l'ensemble de données LVIS et GPT-4V. Il contient 200 000 plus de 900 000. paires question-réponse, impliquant plus de 900 000 masques de segmentation d’instance.


Afin d'obtenir les effets ci-dessus, comment cette recherche a-t-elle été menée ?
Le principe derrière
 Images
Images
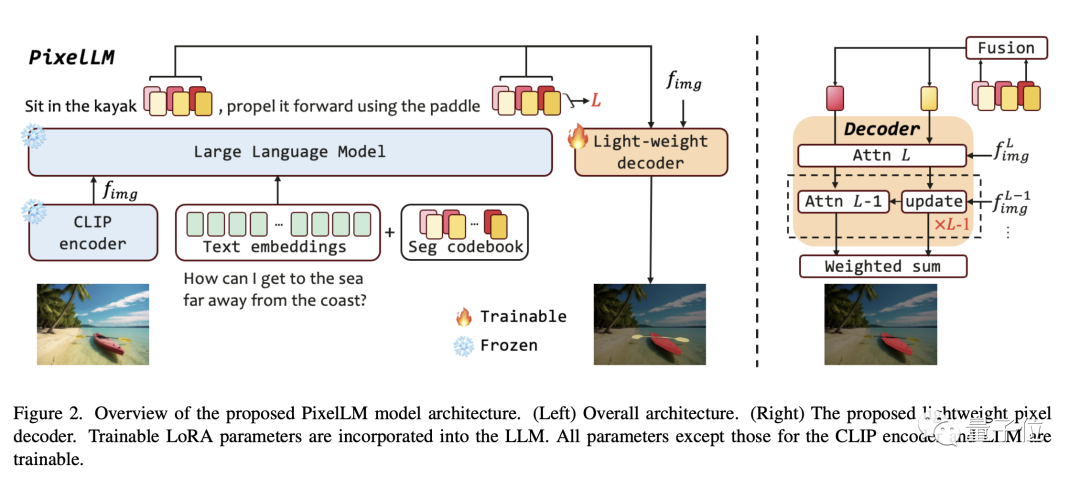
Comme le montre le schéma-cadre de l'article, l'architecture PixelLM est très simple et se compose de quatre parties principales. Les deux dernières sont le cœur de PixelLM :
- Pré-. Encodeur de vision CLIP-ViT formé
- Grand modèle de langage
- Décodeur de pixels léger
- Table de codes de segment Seg Codebook
Le livre de codes Seg contient des jetons apprenables, qui sont utilisés pour encoder des informations cibles à différentes échelles de CLIP-ViT. Ensuite, le décodeur de pixels génère des résultats de segmentation d'objets basés sur ces jetons et les caractéristiques d'image de CLIP-ViT. Grâce à cette conception, PixelLM peut générer des résultats de segmentation de haute qualité sans modèle de segmentation externe, améliorant ainsi considérablement l'efficacité du modèle.
Selon la description du chercheur, les jetons du livre de codes Seg peuvent être divisés en L groupes, chaque groupe contient N jetons et chaque groupe correspond à une échelle de fonctionnalités visuelles CLIP-ViT.
Pour l'image d'entrée, PixelLM extrait les caractéristiques de l'échelle L des caractéristiques de l'image produites par l'encodeur visuel CLIP-ViT. La dernière couche couvre les informations globales de l'image et sera utilisée par LLM pour comprendre le contenu de l'image.
Les jetons du livre de codes Seg seront saisis dans le LLM avec les instructions textuelles et la dernière couche de caractéristiques de l'image pour produire une sortie sous forme d'autorégression. La sortie comprendra également les jetons du livre de codes Seg traités par LLM, qui seront entrés dans le décodeur de pixels avec les fonctionnalités CLIP-ViT à l'échelle L pour produire le résultat final de segmentation.
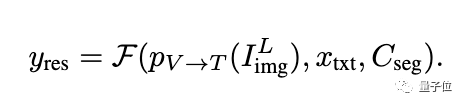 Images
Images
 Images
Images
Alors pourquoi devons-nous définir chaque groupe pour qu'il contienne N jetons ? Les chercheurs ont expliqué en conjonction avec la figure suivante :
Dans les scénarios impliquant plusieurs cibles ou la sémantique contenue dans les cibles est très complexe, bien que LLM puisse fournir une réponse textuelle détaillée, l'utilisation d'un seul jeton peut ne pas capturer complètement toute la sémantique cible. contenu.
Afin d'améliorer la capacité du modèle dans des scénarios de raisonnement complexes, les chercheurs ont introduit plusieurs jetons dans chaque groupe d'échelle et ont effectué une opération de fusion linéaire d'un jeton. Avant que le jeton ne soit transmis au décodeur, une couche de projection linéaire est utilisée pour fusionner les jetons au sein de chaque groupe.
L'image ci-dessous montre l'effet lorsqu'il y a plusieurs jetons dans chaque groupe. La carte d'attention représente à quoi ressemble chaque jeton après avoir été traité par le décodeur. Cette visualisation montre que plusieurs jetons fournissent des informations uniques et complémentaires, ce qui permet d'obtenir une sortie de segmentation plus efficace.
 Photos
Photos
De plus, afin d'améliorer la capacité du modèle à distinguer plusieurs cibles, PixelLM a également conçu une perte de raffinement de cible supplémentaire.
Ensemble de données MUSE
Bien que les solutions ci-dessus aient été proposées, afin d'exploiter pleinement les capacités du modèle, le modèle nécessite toujours des données de formation appropriées. En examinant les ensembles de données publiques actuellement disponibles, nous constatons que les données existantes présentent les limitations majeures suivantes :
1) Description insuffisante des détails de l'objet ;
2) Manque de paires question-réponse avec un raisonnement complexe et des nombres cibles divers ;
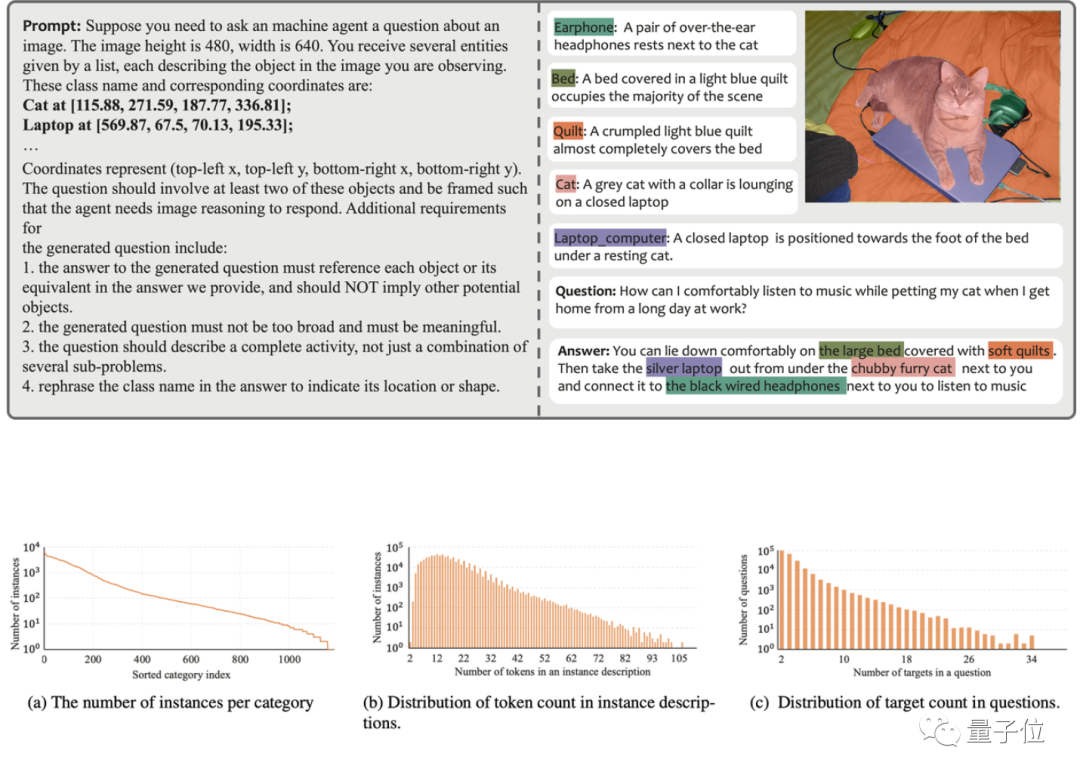
Afin de résoudre ces problèmes, l'équipe de recherche a utilisé GPT-4V pour créer un pipeline d'annotation de données automatisé, et a ainsi généré l'ensemble de données MUSE. La figure ci-dessous montre un exemple des invites utilisées lors de la génération de MUSE et des données générées.
 Images
Images
Dans MUSE, tous les masques d'instance proviennent de l'ensemble de données LVIS, et des descriptions textuelles détaillées générées en fonction du contenu de l'image sont ajoutées. MUSE contient 246 000 paires de questions-réponses, et chaque paire de questions-réponses implique en moyenne 3,7 objets cibles. De plus, l'équipe de recherche a mené une analyse statistique exhaustive de l'ensemble de données :
Statistiques de catégorie : il existe plus de 1 000 catégories dans MUSE à partir de l'ensemble de données LVIS d'origine, et 900 000 instances avec des descriptions uniques basées sur des paires de questions-réponses varient en fonction de l'ensemble de données. contexte. La figure (a) montre le nombre d'instances de chaque catégorie dans toutes les paires question-réponse.
Statistiques du nombre de jetons : La figure (b) montre la répartition du nombre de jetons décrits dans les exemples, dont certains contiennent plus de 100 jetons. Ces descriptions ne se limitent pas à de simples noms de catégories ; elles sont plutôt enrichies d'informations détaillées sur chaque instance, y compris l'apparence, les propriétés et les relations avec d'autres objets, via un processus de génération de données basé sur GPT-4V. La profondeur et la diversité des informations contenues dans l'ensemble de données améliorent la capacité de généralisation du modèle formé, lui permettant de résoudre efficacement les problèmes du domaine ouvert.
Statistiques du nombre de cibles : la figure (c) montre les statistiques du nombre de cibles pour chaque paire question-réponse. Le nombre moyen de cibles est de 3,7 et le nombre maximum de cibles peut atteindre 34. Ce nombre peut couvrir la plupart des scénarios d'inférence cible pour une seule image.
Évaluation de l'algorithme
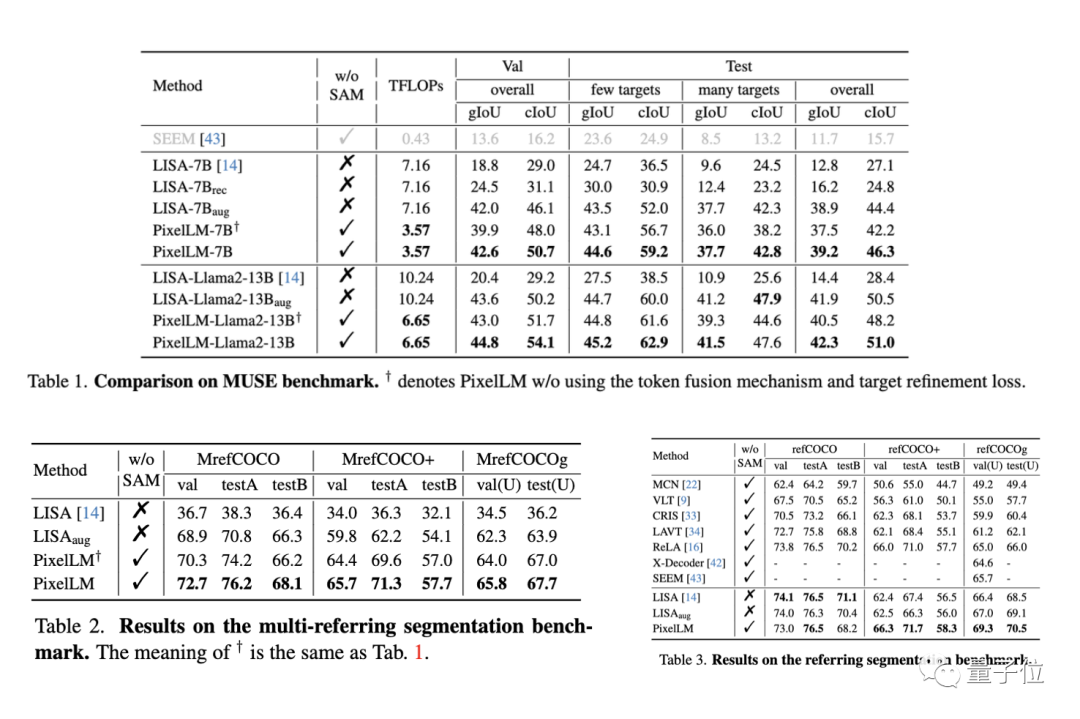
L'équipe de recherche a évalué les performances de PixelLM sur trois benchmarks, dont le benchmark MUSE, le benchmark de segmentation référent et le benchmark de segmentation multi-référence, l'équipe de recherche exige que le modèle soit présent. un problème Segmentez en continu plusieurs objets contenus dans chaque image dans le benchmark de segmentation référent.
Dans le même temps, puisque PixelLM est le premier modèle à gérer des tâches complexes de raisonnement en pixels impliquant plusieurs cibles, l'équipe de recherche a établi quatre lignes de base pour mener une analyse comparative des modèles.
Trois des lignes de base sont basées sur LISA, le travail le plus pertinent sur PixelLM, notamment :
1) LISA originale
2) LISA_rec : entrez d'abord la question dans LLAVA-13B pour obtenir la réponse textuelle de la cible, puis utilisez LISA pour segmenter le texte ;
3) LISA_aug : ajoutez directement MUSE aux données d'entraînement de LISA.
4) L'autre est SEEM, un modèle de segmentation général qui n'utilise pas de LLM.
 Photos
Photos
Sur la plupart des indicateurs des trois benchmarks, les performances de PixelLM sont meilleures que celles des autres méthodes, et comme PixelLM ne s'appuie pas sur SAM, ses TFLOP sont bien inférieurs à ceux des modèles de même taille.
Les amis intéressés peuvent d'abord y prêter attention et attendre que le code soit open source~
Lien de référence :
[1]https://www.php.cn/link/9271858951e6fe9504d1f05ae8576001
[2]https:/ /www.php.cn/link/f1686b4badcf28d33ed632036c7ab0b8
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comprendre le modèle de boîte CSS : Comprendre ce qu'est le modèle de boîte CSS en 5 minutes ?
- Comment comparer les performances d'une carte graphique
- Les composants clés qui affectent les performances d'un ordinateur sont
- une configuration Cardeon pour des performances élevées
- Comment supprimer des modèles redondants dans ZBrush