
Maison >Périphériques technologiques >IA >NeurIPS23 | « Brain Reading » décode l'activité cérébrale et reconstruit le monde visuel
NeurIPS23 | « Brain Reading » décode l'activité cérébrale et reconstruit le monde visuel

- PHPzavant
- 2024-01-10 14:54:24634parcourir
Dans cet article NeurIPS23, des chercheurs de l'Université de Louvain, de l'Université nationale de Singapour et de l'Institut d'automatisation de l'Académie chinoise des sciences ont proposé une « technologie de lecture cérébrale » visuelle capable d'analyser l'activité cérébrale humaine à haute résolution. image que vous voyez de vos propres yeux.
Dans le domaine des neurosciences cognitives, les gens se rendent compte que la perception humaine n'est pas seulement affectée par des stimuli objectifs, mais aussi profondément affectée par les expériences passées. Ces facteurs agissent ensemble pour créer une activité complexe dans le cerveau. Par conséquent, décoder les informations visuelles issues de l’activité cérébrale devient une tâche importante. Parmi eux, l'imagerie par résonance magnétique fonctionnelle (IRMf), en tant que technologie non invasive efficace, joue un rôle clé dans la récupération et l'analyse des informations visuelles, en particulier les catégories d'images, en raison des caractéristiques de bruit des signaux IRMf et de la vision cérébrale. complexité de la représentation, cette tâche se heurte à des défis considérables. Pour résoudre ce problème, cet article propose un cadre d'apprentissage de la représentation IRMf en deux étapes, qui vise à identifier et à éliminer le bruit dans l'activité cérébrale, et se concentre sur l'analyse des modèles d'activation neuronale qui sont cruciaux pour la reconstruction visuelle, en reconstruisant avec succès des images de haut niveau du cerveau. activité. résolution et images sémantiquement précises.
 Lien article : https://arxiv.org/abs/2305.17214
Lien article : https://arxiv.org/abs/2305.17214
Lien projet : https://github.com/soinx0629/vis_dec_neurips/
La méthode proposée dans l'article est basée sur un double apprentissage contrastif , modèle croisé Le modèle de croisement et de diffusion des informations d'état a obtenu une amélioration de près de 40 % des indicateurs d'évaluation sur les ensembles de données IRMf pertinents par rapport aux meilleurs modèles précédents. La qualité, la lisibilité et la pertinence sémantique des images générées sont toutes supérieures aux méthodes existantes. Amélioration perceptible. Ce travail aide à comprendre le mécanisme de perception visuelle du cerveau humain et contribue à promouvoir la recherche sur la technologie d’interface visuelle cerveau-ordinateur. Les codes pertinents sont open source.
Bien que l'imagerie par résonance magnétique fonctionnelle (IRMf) soit largement utilisée pour analyser les réponses neuronales, la reconstruction précise des images visuelles à partir de ses données reste un défi, principalement parce que les données IRMf contiennent du bruit provenant de sources multiples, ce qui peut masquer les modèles d'activation neuronale. De plus, le processus de réponse neuronale déclenché par la stimulation visuelle est complexe et en plusieurs étapes, ce qui fait que le signal IRMf présente une superposition complexe non linéaire difficile à inverser et à décoder.
Les méthodes de décodage neuronal traditionnelles, telles que la régression des crêtes, bien qu'utilisées pour associer les signaux IRMf aux stimuli correspondants, ne parviennent souvent pas à capturer efficacement la relation non linéaire entre les stimuli et les réponses neuronales. Récemment, des techniques d'apprentissage profond, telles que les réseaux contradictoires génératifs (GAN) et les modèles de diffusion latente (LDM), ont été adoptées pour modéliser cette relation complexe avec plus de précision. Cependant, isoler l’activité cérébrale liée à la vision du bruit et la décoder avec précision reste l’un des principaux défis dans ce domaine.
Pour relever ces défis, ce travail propose un cadre d'apprentissage de la représentation IRMf en deux étapes, capable d'identifier et de supprimer efficacement le bruit dans les activités cérébrales et de se concentrer sur l'analyse des modèles d'activation neuronale qui sont essentiels à la reconstruction visuelle. Cette méthode génère des images haute résolution et sémantiquement précises avec une précision Top-1 de 39,34 % pour 50 catégories, dépassant la technologie de pointe existante.
Un aperçu de la méthode est une brève description d'une série d'étapes ou de processus. Il est utilisé pour expliquer comment atteindre un objectif spécifique ou accomplir une tâche spécifique. Le but d’un aperçu de la méthode est de fournir au lecteur ou à l’utilisateur une compréhension globale de l’ensemble du processus afin qu’il puisse mieux comprendre et suivre les étapes. Dans un aperçu de la méthode, vous incluez généralement la séquence d'étapes, le matériel ou les outils nécessaires, ainsi que les problèmes ou défis qui peuvent être rencontrés. En décrivant l'aperçu de la méthode de manière claire et concise, le lecteur ou l'utilisateur peut plus facilement comprendre et accomplir avec succès la tâche requiseApprentissage de la représentation IRMf (FRL)
 Phase 1 : Pré-entraîner l'encodeur automatique des masques à double contraste ( DC-MAE)
Phase 1 : Pré-entraîner l'encodeur automatique des masques à double contraste ( DC-MAE)
Afin de distinguer les modèles d'activité cérébrale partagée et le bruit individuel parmi différents groupes de personnes, cet article présente la technologie DC-MAE pour pré-entraîner les représentations IRMf à l'aide de données non étiquetées. DC-MAE se compose d'un encodeur  et d'un décodeur
et d'un décodeur  , où
, où  prend le signal IRMf masqué en entrée et
prend le signal IRMf masqué en entrée et  est entraîné pour prédire le signal IRMf non masqué. Ce que l'on appelle le « double contraste » signifie que le modèle optimise la perte de contraste dans l'apprentissage de la représentation IRMf et participe à deux processus de contraste différents.
est entraîné pour prédire le signal IRMf non masqué. Ce que l'on appelle le « double contraste » signifie que le modèle optimise la perte de contraste dans l'apprentissage de la représentation IRMf et participe à deux processus de contraste différents.
Dans la première étape de l'apprentissage contrastif, les échantillons  de chaque lot contenant n échantillons IRMf v sont masqués au hasard deux fois, générant deux versions masquées différentes
de chaque lot contenant n échantillons IRMf v sont masqués au hasard deux fois, générant deux versions masquées différentes  et
et 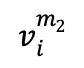 sous forme de paires d'échantillons positifs à des fins de comparaison. Par la suite, les couches convolutionnelles 1D convertissent ces deux versions en représentations intégrées, qui sont respectivement introduites dans l'encodeur fMRI . Le décodeur
sous forme de paires d'échantillons positifs à des fins de comparaison. Par la suite, les couches convolutionnelles 1D convertissent ces deux versions en représentations intégrées, qui sont respectivement introduites dans l'encodeur fMRI . Le décodeur  reçoit ces représentations latentes codées et produit des prédictions
reçoit ces représentations latentes codées et produit des prédictions  et
et  . Optimisez le modèle grâce à la première perte de contraste calculée par la fonction de perte InfoNCE, c'est-à-dire la perte de contraste croisé :
. Optimisez le modèle grâce à la première perte de contraste calculée par la fonction de perte InfoNCE, c'est-à-dire la perte de contraste croisé :

Dans la deuxième étape de l'apprentissage contrastif, chaque image originale non masquée  et son image masquée correspondante
et son image masquée correspondante 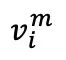 forment une paire d'échantillons positifs naturels. Le
forment une paire d'échantillons positifs naturels. Le 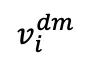 représente ici l'image prédite par le décodeur . La deuxième perte de contraste, qui est la perte de contraste propre, est calculée selon la formule suivante :
représente ici l'image prédite par le décodeur . La deuxième perte de contraste, qui est la perte de contraste propre, est calculée selon la formule suivante :

Optimiser la perte de contraste propre peut réaliser une reconstruction d'occlusion. Qu'il s'agisse de
peut réaliser une reconstruction d'occlusion. Qu'il s'agisse de  ou de
ou de  , l'échantillon négatif
, l'échantillon négatif  provient du même lot d'instances.
provient du même lot d'instances.  et sont optimisés conjointement comme suit :
et sont optimisés conjointement comme suit :  , où les hyperparamètres
, où les hyperparamètres  et
et  sont utilisés pour ajuster le poids de chaque terme de perte.
sont utilisés pour ajuster le poids de chaque terme de perte.
Deuxième étape : réglage à l'aide d'un guidage intermodal
Étant donné le faible rapport signal/bruit et la nature hautement convolutionnelle des enregistrements IRMf, il est important que les apprenants des fonctionnalités IRMf se concentrent sur celles les plus pertinentes pour le traitement visuel Et il est crucial de reconstruire le schéma d’activation cérébrale le plus informatif
Après la première étape de pré-formation, l'auto-encodeur IRMf est ajusté avec l'assistance d'image pour réaliser la reconstruction IRMf, et la deuxième étape suit également ce processus. Plus précisément, un échantillon  et sa réponse neuronale correspondante enregistrée par IRMf
et sa réponse neuronale correspondante enregistrée par IRMf  sont sélectionnés parmi un lot de n échantillons.
sont sélectionnés parmi un lot de n échantillons.  et
et  sont traités par blocage et masquage aléatoire, transformés respectivement en
sont traités par blocage et masquage aléatoire, transformés respectivement en  et
et  , puis entrés dans l'encodeur d'image
, puis entrés dans l'encodeur d'image  et l'encodeur IRMf respectivement pour générer
et l'encodeur IRMf respectivement pour générer  et
et  . Pour reconstruire l'IRMf
. Pour reconstruire l'IRMf , le module d'attention croisée permet de fusionner
, le module d'attention croisée permet de fusionner  et
et  :
:

W et b représentent respectivement le poids et le biais de la couche linéaire correspondante.  est le facteur d'échelle et
est le facteur d'échelle et  est la dimension du vecteur clé. CA est l'abréviation de attention croisée. Une fois
est la dimension du vecteur clé. CA est l'abréviation de attention croisée. Une fois  ajouté à
ajouté à  , il est entré dans le décodeur IRMf pour reconstruire
, il est entré dans le décodeur IRMf pour reconstruire  , et nous obtenons
, et nous obtenons  :
:

Des calculs similaires sont également effectués dans l'auto-encodeur d'image, et la sortie  de l'encodeur d'image
de l'encodeur d'image  est combinée avec le module d'attention croisée
est combinée avec le module d'attention croisée  Les sorties de sont combinées puis utilisées pour décoder l'image
Les sorties de sont combinées puis utilisées pour décoder l'image  , donnant
, donnant  :
: 
Les auto-encodeurs IRMf et d'image sont entraînés conjointement en optimisant la fonction de perte suivante :

Lors de la génération d'images, un modèle de diffusion latente peut être utilisé (LDM)

Après avoir terminé les première et deuxième étapes de la formation FRL, utilisez l'encodeur de la fonctionnalité IRMf pour piloter un modèle de diffusion latente (MLD) afin de générer des images à partir de l'activité cérébrale. Comme le montre la figure, le modèle de diffusion comprend un processus de diffusion directe et un processus de débruitage inverse. Le processus direct dégrade progressivement l'image en bruit gaussien normal en introduisant progressivement un bruit gaussien avec une variance variable.
Cette étude génère des images en extrayant des connaissances visuelles à partir d'un modèle de diffusion latente étiquette-image (LDM) pré-entraîné et en utilisant les données IRMf comme condition. Un mécanisme d’attention croisée est utilisé ici pour incorporer les informations IRMf dans le LDM, suite aux recommandations d’études de diffusion stable. Afin de renforcer le rôle de l’information conditionnelle, les méthodes d’attention croisée et de conditionnement par pas de temps sont utilisées ici. Dans la phase d'entraînement, l'encodeur VQGAN  et l'encodeur IRMf formés par les première et deuxième étapes de FRL sont utilisés pour traiter l'image u et fMRI v, et l'encodeur IRMf est affiné tout en gardant le LDM inchangé. la fonction est :
et l'encodeur IRMf formés par les première et deuxième étapes de FRL sont utilisés pour traiter l'image u et fMRI v, et l'encodeur IRMf est affiné tout en gardant le LDM inchangé. la fonction est : 
où,  est le schéma de bruit du modèle de diffusion. Dans la phase d'inférence, le processus commence avec un bruit gaussien standard au pas de temps T, et le LDM suit séquentiellement le processus inverse pour supprimer progressivement le bruit de la représentation cachée, en fonction des informations IRMf fournies. Lorsque le pas de temps zéro est atteint, la représentation cachée est convertie en image à l'aide du décodeur VQGAN
est le schéma de bruit du modèle de diffusion. Dans la phase d'inférence, le processus commence avec un bruit gaussien standard au pas de temps T, et le LDM suit séquentiellement le processus inverse pour supprimer progressivement le bruit de la représentation cachée, en fonction des informations IRMf fournies. Lorsque le pas de temps zéro est atteint, la représentation cachée est convertie en image à l'aide du décodeur VQGAN .
.
Expérience
Résultats de reconstruction

Par comparaison avec des études précédentes telles que DC-LDM, IC-GAN et SS-AE, et dans l'évaluation sur les ensembles de données GOD et BOLD5000, cette étude montre que Le modèle proposé surpasse considérablement ces modèles en termes de précision, avec une amélioration de 39,34 % et 66,7 % par rapport à DC-LDM et IC-GAN respectivement

L'évaluation sur quatre autres sujets de l'ensemble de données GOD montre, même lorsque DC-LDM est autorisé à être ajusté sur l'ensemble de tests, le modèle proposé dans cette étude est nettement meilleur que le DC-LDM dans la précision de classification Top-1 de 50 façons, prouvant que le modèle proposé est efficace dans différents sujets. Fiabilité et supériorité dans la reconstruction des sujets. ' activité cérébrale.
Les résultats de la recherche montrent que l'utilisation du cadre d'apprentissage de la représentation IRMf proposé et du LDM pré-entraîné peut mieux reconstruire l'activité visuelle du cerveau, dépassant de loin le niveau de base actuel. Ce travail permet d'explorer davantage le potentiel des modèles de décodage neuronal
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment rédiger une expérience de projet dans un CV d'ingénieur front-end
- Questions d'entretien d'ingénieur PHP senior Xiaomi 2022 (examen simulé)
- Qu'est-ce qu'un ingénieur web front-end ? Que fait un ingénieur web front-end ?
- Qu'est-ce qu'un ingénieur php ?
- Quelle est la différence entre un ingénieur logiciel et un programmeur ?