
 Périphériques technologiquesIAL'équipe de l'Académie chinoise des sciences crée un cadre unifié pour améliorer la précision des prévisions des paramètres cinétiques des enzymes
Périphériques technologiquesIAL'équipe de l'Académie chinoise des sciences crée un cadre unifié pour améliorer la précision des prévisions des paramètres cinétiques des enzymes
Éditeur | Radis Skin
La prédiction des paramètres cinétiques des enzymes est cruciale pour la conception et l'optimisation des enzymes dans les applications biotechnologiques et industrielles, mais les performances limitées des outils de prédiction actuels sur diverses tâches limitent leur application pratique.
Des chercheurs de l'Académie chinoise des sciences ont récemment proposé UniKP, un cadre unifié basé sur des modèles linguistiques pré-entraînés qui peuvent être utilisés pour prédire les paramètres cinétiques des enzymes, notamment le nombre de renouvellement enzymatique (kcat), la constante de Michaelis-Menten (Km) et le catalyseur. efficacité ( kcat/Km), ces paramètres sont obtenus à partir de la séquence protéique et de la structure du substrat.
Un cadre à deux couches basé sur UniKP (EF-UniKP) est également proposé, qui peut prédire de manière stable les valeurs kcat en tenant compte de facteurs environnementaux tels que le pH et la température. Dans le même temps, l’équipe de recherche a également exploré systématiquement quatre méthodes de repondération représentatives, réduisant ainsi les erreurs de prédiction dans les tâches de prédiction de grande valeur.
L'étude s'intitule « UniKP : un cadre unifié pour la prédiction des paramètres cinétiques enzymatiques » et a été publiée dans la revue « Nature Communications » le 11 décembre 2023.

L'étude de l'efficacité catalytique des enzymes sur des substrats spécifiques est un enjeu important en biologie et a un impact profond sur l'évolution des enzymes, l'ingénierie métabolique et la biologie synthétique. Les données expérimentales in vitro mesurant kcat et Km, ainsi que le taux de renouvellement maximal et la constante de Michaelis-Menten, peuvent être utilisées comme indicateurs pour mesurer l'efficacité des enzymes dans la catalyse de réactions spécifiques et pour comparer les activités catalytiques relatives de différentes enzymes.
À l'heure actuelle, la mesure des paramètres cinétiques des enzymes repose principalement sur des mesures expérimentales, qui prennent du temps, sont coûteuses et demandent beaucoup de main d'œuvre, ce qui donne lieu à une petite base de données de valeurs de paramètres cinétiques mesurées expérimentalement. Par exemple, la base de données de séquences UniProt contient plus de 230 millions de séquences enzymatiques, tandis que les bases de données enzymatiques BRENDA et SABIO-RK contiennent des dizaines de milliers de valeurs kcat mesurées expérimentalement. L'intégration des identifiants Uniprot dans ces bases de données enzymatiques facilite la connexion entre les paramètres mesurés et les séquences protéiques. Cependant, l’échelle de ces connexions est encore beaucoup plus petite par rapport au nombre de séquences enzymatiques, ce qui limite les progrès dans les applications en aval telles que l’évolution dirigée et l’ingénierie métabolique.
Cadre de prédiction des paramètres cinétiques enzymatiques
Dans cette étude, des chercheurs de l'Académie chinoise des sciences ont proposé un nouveau cadre appelé UniKP, qui est basé sur des modèles de langage pré-entraînés et vise à améliorer la précision de la prédiction des paramètres cinétiques enzymatiques. . Ces paramètres incluent kcat, Km et kcat/Km, qui peuvent être prédits compte tenu de la séquence enzymatique et de la structure du substrat. Les chercheurs ont effectué une comparaison complète de 16 modèles d’apprentissage automatique différents et de 2 modèles d’apprentissage profond et ont constaté qu’UniKP fonctionnait bien en termes de précision des prédictions. Cette recherche devrait fournir de nouveaux outils et méthodes pour la recherche et les applications dans le domaine de la cinétique enzymatique.
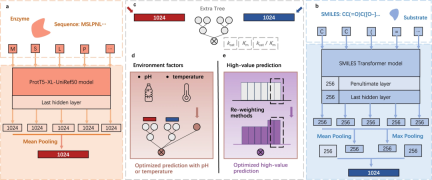
Illustration : aperçu de l'UniKP. (Source : article)
Par rapport au précédent modèle de pointe DLKcat, UniKP montre des performances supérieures dans la tâche de prédiction kcat, avec un coefficient de détermination moyen de 0,68, soit une amélioration de 20 %. Les chercheurs supposent que les modèles pré-entraînés ont contribué de manière significative aux performances d'UniKP en utilisant des informations non supervisées provenant de l'ensemble de la base de données pour créer des représentations faciles à apprendre des séquences enzymatiques et des structures de substrat.
L'analyse de l'apprentissage des modèles montre que l'information sur les protéines a un rôle dominant, peut-être en raison de la complexité de la structure de l'enzyme par rapport à la structure du substrat. De plus, UniKP peut capturer efficacement de petites différences dans les valeurs kcat entre les enzymes et leurs mutants, y compris les cas mesurés expérimentalement, ce qui est crucial pour la conception et la modification des enzymes. La différence entre le R^2 des prédictions UniKP et le R^2 de la méthode gmean pour les régions à identité élevée et faible démontre la capacité d'UniKP à extraire des informations interconnectées plus profondes et ainsi à bien performer dans ces tâches.
Cadre à deux couches EF-UniKP
La plupart des modèles actuels ne prennent pas en compte les facteurs environnementaux, ce qui constitue une limitation clé dans la simulation de conditions expérimentales réelles. Pour résoudre ce problème, les chercheurs ont proposé un cadre à deux couches EF-UniKP, qui prend en compte les facteurs environnementaux. Basé sur deux ensembles de données nouvellement construits contenant respectivement des informations sur le pH et la température, EF-UniKP présente des performances améliorées par rapport à l'UniKP initial. Il s’agit d’une prédiction kcat précise, à haut débit, indépendante de l’organisme et dépendant du contexte. De plus, cette approche a le potentiel d’être élargie pour inclure d’autres facteurs tels que le co-substrat et la concentration de NaCl.
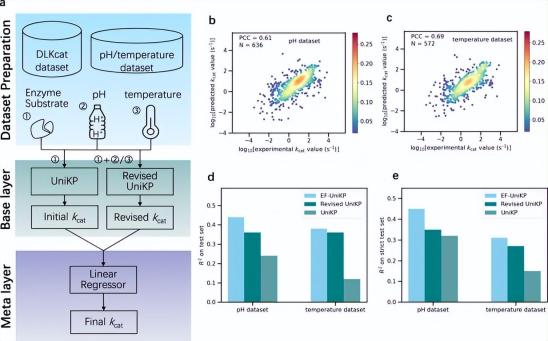
Illustration : Cadre à deux niveaux prenant en compte les facteurs environnementaux. (Source : Article)
Cependant, les modèles existants ne prennent pas en compte l'interaction entre ces facteurs en raison d'un manque de données complètes. À mesure que les techniques expérimentales progressent, notamment l’automatisation des laboratoires de biodiffusion et les méthodes d’évolution continue, les chercheurs anticipent une prolifération de données cinétiques enzymatiques. Cet afflux a non seulement enrichi le domaine mais a également amélioré la précision des modèles prédictifs.
En raison du déséquilibre élevé de l'ensemble de données kcat, qui entraîne des erreurs plus élevées dans les prédictions de valeurs kcat élevées, l'équipe a systématiquement exploré quatre méthodes de repondération représentatives pour atténuer ce problème. Les résultats montrent que les paramètres d’hyperparamètres de chaque méthode sont essentiels à l’amélioration des prédictions de valeurs kcat élevées.
L'équipe a confirmé la forte généralité du cadre actuel dans la prédiction de la constante de Michaelis (Km) et la prédiction kcat/Km. UniKP atteint des performances de pointe dans la prévision des valeurs Km et, de manière plus impressionnante, surpasse les résultats combinés des modèles de pointe actuels dans la prévision des valeurs kcat/Km. En outre, les chercheurs ont validé le cadre UniKP sur la base de valeurs kcat/Km mesurées expérimentalement et de valeurs kcat/Km calculées à l'aide de modèles de prédiction kcat et Km sur l'ensemble de données kcat/Km.
Il est à noter que la corrélation observée entre les valeurs dérivées d'UniKP kcat/UniKP Km et l'expérimental kcat/Km est relativement faible (PCC = −0,01). Cette différence peut être due aux différents ensembles de données utilisés dans la construction des modèles respectifs, nécessitant ainsi le développement d'un modèle différent pour prédire les valeurs kcat/Km. À l’avenir, avec l’émergence d’ensembles de données unifiés contenant les valeurs kcat et Km, il est prévu que les résultats informatiques des modèles kcat et Km soient étroitement cohérents avec les résultats générés par le modèle dédié kcat/Km.
Applications du béton dans l'extraction et l'évolution des enzymes
L'application d'UniKP dans l'extraction des enzymes tyrosine ammoniac lyase (TAL) et l'évolution dirigée démontre son potentiel pour révolutionner la recherche en biologie synthétique et en biochimie. Cette étude montre qu'UniKP reconnaît efficacement les TAL hautement actifs et améliore rapidement l'efficacité catalytique des TAL existants, le RgTAL-489T ayant une valeur kcat/Km 3,5 fois supérieure à celle de l'enzyme de type sauvage.
De plus, le cadre dérivé EF-UniKP a toujours été capable d'identifier les enzymes TAL hautement actives avec une précision extrêmement élevée, la valeur kcat/Km de TrTAL de Tephrocybe rancida étant 2,6 fois supérieure à celle de l'enzyme de type sauvage. Les résultats ont montré que les valeurs kcat et kcat/Km des cinq séquences dépassaient celles de l'enzyme de type sauvage.
En accélérant le processus de découverte et d'optimisation des enzymes, UniKP devrait devenir un outil puissant pour faire progresser la biocatalyse, la découverte de médicaments, l'ingénierie métabolique et d'autres domaines qui reposent sur des processus catalysés par des enzymes.
Limitations et perspectives
Cependant, la version actuelle d'UniKP présente encore certaines limitations. Par exemple, alors qu'UniKP est capable de faire la différence entre les valeurs kcat mesurées expérimentalement d'une enzyme et ses variantes, les valeurs kcat prédites ne sont pas suffisamment précises. Cela peut être dû à des ensembles de données insuffisants par rapport au nombre de séquences protéiques et de structures de substrat connues.
Bien que la méthode de repondération puisse atténuer dans une certaine mesure le biais de prédiction causé par l'ensemble de données kcat déséquilibré (amélioration d'environ 6,5 %), des améliorations plus significatives peuvent être obtenues grâce à des techniques de suréchantillonnage minoritaire synthétique et d'autres méthodes de synthèse d'échantillons.
Un objectif central de la biologie synthétique est le développement de cellules numériques qui révolutionneront la façon dont les scientifiques étudient la biologie. Une condition préalable essentielle à cette étude est la détermination minutieuse des paramètres enzymatiques pour toutes les enzymes de la voie. Les outils assistés par l’intelligence artificielle mettent en lumière ce défi, en fournissant une méthode à haut débit pour prédire la cinétique des enzymes.
Bien que l'erreur des prédicteurs UniKP soit réduite par rapport aux modèles précédents, l'imprécision reste un obstacle important à la construction de modèles métaboliques précis. L'intégration d'un nombre croissant de valeurs kcat et Km déterminées expérimentalement peut améliorer la précision du modèle.
Ensuite, les chercheurs ont l'intention de combiner des algorithmes de pointe tels que l'apprentissage par transfert, l'apprentissage par renforcement et d'autres algorithmes d'apprentissage à petite échelle pour gérer efficacement des ensembles de données déséquilibrés. Et l’équipe vise à explorer des applications supplémentaires, notamment l’évolution des enzymes et l’analyse globale des organismes.
Lien papier : https://www.nature.com/articles/s41467-023-44113-1
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Gemma Scope: le microscope de Google pour regarder dans le processus de pensée de l'IAApr 17, 2025 am 11:55 AM
Gemma Scope: le microscope de Google pour regarder dans le processus de pensée de l'IAApr 17, 2025 am 11:55 AMExplorer le fonctionnement interne des modèles de langue avec Gemma Scope Comprendre les complexités des modèles de langue IA est un défi important. La sortie de Google de Gemma Scope, une boîte à outils complète, offre aux chercheurs un moyen puissant de plonger
 Qui est un analyste de Business Intelligence et comment en devenir un?Apr 17, 2025 am 11:44 AM
Qui est un analyste de Business Intelligence et comment en devenir un?Apr 17, 2025 am 11:44 AMDéverrouiller le succès de l'entreprise: un guide pour devenir un analyste de Business Intelligence Imaginez transformer les données brutes en informations exploitables qui stimulent la croissance organisationnelle. C'est le pouvoir d'un analyste de Business Intelligence (BI) - un rôle crucial dans GU
 Comment ajouter une colonne dans SQL? - Analytique VidhyaApr 17, 2025 am 11:43 AM
Comment ajouter une colonne dans SQL? - Analytique VidhyaApr 17, 2025 am 11:43 AMInstruction ALTER TABLE de SQL: Ajout de colonnes dynamiquement à votre base de données Dans la gestion des données, l'adaptabilité de SQL est cruciale. Besoin d'ajuster votre structure de base de données à la volée? L'énoncé de la table alter est votre solution. Ce guide détaille l'ajout de Colu
 Analyste d'entreprise vs analyste de donnéesApr 17, 2025 am 11:38 AM
Analyste d'entreprise vs analyste de donnéesApr 17, 2025 am 11:38 AMIntroduction Imaginez un bureau animé où deux professionnels collaborent sur un projet critique. L'analyste commercial se concentre sur les objectifs de l'entreprise, l'identification des domaines d'amélioration et la garantie d'alignement stratégique sur les tendances du marché. Simulé
 Que sont le comte et le coude à Excel? - Analytique VidhyaApr 17, 2025 am 11:34 AM
Que sont le comte et le coude à Excel? - Analytique VidhyaApr 17, 2025 am 11:34 AMExcel Counting and Analysis: Explication détaillée du nombre et des fonctions de compte Le comptage et l'analyse des données précises sont essentiels dans Excel, en particulier lorsque vous travaillez avec de grands ensembles de données. Excel fournit une variété de fonctions pour y parvenir, les fonctions Count et Count sont des outils clés pour compter le nombre de cellules dans différentes conditions. Bien que les deux fonctions soient utilisées pour compter les cellules, leurs cibles de conception sont ciblées sur différents types de données. Faisons des détails spécifiques du comptage et des fonctions de coude, mettons en évidence leurs caractéristiques et différences uniques et apprenez à les appliquer dans l'analyse des données. Aperçu des points clés Comprendre le nombre et le cou
 Chrome est là avec l'IA: vivre quelque chose de nouveau tous les jours !!Apr 17, 2025 am 11:29 AM
Chrome est là avec l'IA: vivre quelque chose de nouveau tous les jours !!Apr 17, 2025 am 11:29 AMLa révolution de l'IA de Google Chrome: une expérience de navigation personnalisée et efficace L'intelligence artificielle (IA) transforme rapidement notre vie quotidienne, et Google Chrome mène la charge dans l'arène de navigation Web. Cet article explore les exciti
 Côté humain de l'AI: le bien-être et le quadruple de basApr 17, 2025 am 11:28 AM
Côté humain de l'AI: le bien-être et le quadruple de basApr 17, 2025 am 11:28 AMRéinventuation d'impact: le quadruple bas Pendant trop longtemps, la conversation a été dominée par une vision étroite de l’impact de l’IA, principalement axée sur le résultat du profit. Cependant, une approche plus holistique reconnaît l'interconnexion de BU
 5 cas d'utilisation de l'informatique quantique qui change la donne que vous devriez connaîtreApr 17, 2025 am 11:24 AM
5 cas d'utilisation de l'informatique quantique qui change la donne que vous devriez connaîtreApr 17, 2025 am 11:24 AMLes choses évoluent régulièrement vers ce point. L'investissement affluant dans les prestataires de services quantiques et les startups montre que l'industrie comprend son importance. Et un nombre croissant de cas d'utilisation réels émergent pour démontrer sa valeur


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Version Mac de WebStorm
Outils de développement JavaScript utiles

SublimeText3 Linux nouvelle version
Dernière version de SublimeText3 Linux

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

SublimeText3 version anglaise
Recommandé : version Win, prend en charge les invites de code !

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

