
Maison >Périphériques technologiques >IA >Robotique : comment se passe le modèle de base ?
Robotique : comment se passe le modèle de base ?

- 王林avant
- 2024-01-09 11:58:154361parcourir
Les robots sont une technologie au potentiel illimité, notamment avec le soutien de la technologie intelligente. Récemment, certains modèles à grande échelle dotés d'applications révolutionnaires sont considérés comme potentiellement des cerveaux intelligents pour les robots, capables d'aider les robots à percevoir et à comprendre le monde, et à prendre des décisions et à planifier. Récemment, une équipe conjointe dirigée par Yonatan Bisk de la CMU et Fei Xia de Google DeepMind a publié un rapport d'évaluation présentant l'application et le développement de modèles de base dans le domaine de la robotique.
Les êtres humains ont toujours rêvé de développer un robot capable de s'adapter de manière autonome à différents environnements. Cependant, réaliser ce rêve est un chemin long et difficile.
Dans le passé, les systèmes de perception des robots utilisaient généralement des méthodes traditionnelles d'apprentissage profond, qui nécessitaient une grande quantité de données étiquetées pour former des modèles d'apprentissage supervisé. Cependant, l’étiquetage de grands ensembles de données via le crowdsourcing est très coûteux.

De plus, les méthodes classiques d'apprentissage supervisé présentent certaines limites dans leurs capacités de généralisation. Afin d'appliquer ces modèles formés à des scénarios ou à des tâches spécifiques, une conception minutieuse de la technologie d'adaptation de domaine est généralement nécessaire, ce qui nécessite souvent une collecte et une annotation supplémentaires des données. De même, les méthodes traditionnelles de planification et de contrôle des robots nécessitent également une modélisation précise de la dynamique de l’environnement, de l’agent lui-même et des autres agents. Ces modèles sont souvent construits pour un environnement ou une tâche spécifique, et lorsque les conditions changent, le modèle doit être reconstruit. Cela montre que les performances de transfert des modèles classiques sont également limitées.
En fait, pour de nombreux cas d'utilisation, créer des modèles efficaces est soit trop coûteux, soit tout simplement impossible. Bien que les méthodes de planification et de contrôle de mouvement basées sur l'apprentissage profond (par renforcement) aident à atténuer ces problèmes, elles souffrent toujours d'un changement de distribution et d'une capacité de généralisation réduite.
Bien que le développement de systèmes robotiques à usage général présente de nombreux défis, les domaines du traitement du langage naturel (NLP) et de la vision par ordinateur (CV) ont récemment fait des progrès rapides, notamment les grands modèles de langage (LLM) pour la PNL, la diffusion utilisateur modèle pour la génération d'images haute fidélité, modèle visuel puissant et modèle de langage visuel pour les tâches CV telles que la génération de plans zéro/quelques plans.
Le soi-disant « modèle de base » est en fait un grand modèle de pré-formation (LPTM). Ils ont de puissantes capacités visuelles et verbales. Récemment, ces modèles ont également été appliqués dans le domaine de la robotique et devraient donner aux systèmes robotiques une perception du monde ouvert, une planification des tâches et même des capacités de contrôle des mouvements. En plus d’utiliser des modèles de base de vision et/ou de langage existants dans le domaine de la robotique, certaines équipes de recherche développent des modèles de base pour les tâches robotiques, comme des modèles d’action pour la manipulation ou des modèles de planification de mouvements pour la navigation. Ces modèles de robots de base démontrent de fortes capacités de généralisation et peuvent s’adapter à différentes tâches et même à des solutions spécifiques.
Il existe également des chercheurs qui utilisent directement des modèles de base vision/langage pour les tâches robotiques, ce qui montre la possibilité d'intégrer différents modules robotiques dans un seul modèle unifié.
Bien que les modèles de base de vision et de langage aient des perspectives prometteuses dans le domaine de la robotique et que de nouveaux modèles de base de robots soient également en cours de développement, il existe encore de nombreux défis difficiles à résoudre dans le domaine de la robotique.
Du point de vue du déploiement réel, les modèles sont souvent non reproductibles, incapables de se généraliser à différentes formes de robots (généralisation multi-incarnés) ou difficiles de comprendre avec précision quels comportements dans l'environnement sont réalisables (ou acceptables). En outre, la plupart des recherches utilisent une architecture basée sur Transformer, en se concentrant sur la perception sémantique des objets et des scènes, la planification et le contrôle au niveau des tâches. D'autres parties du système robotique sont moins étudiées, comme les modèles de base pour la dynamique mondiale ou les modèles de base capables d'effectuer un raisonnement symbolique. Ceux-ci nécessitent des capacités de généralisation inter-domaines.
Enfin, nous avons également besoin de données réelles à plus grande échelle et de simulateurs haute fidélité prenant en charge diverses tâches robotiques.
Cet article de synthèse résume les modèles de base utilisés dans le domaine de la robotique, dans le but de comprendre comment les modèles de base peuvent aider à résoudre ou à atténuer les principaux défis dans le domaine de la robotique.

Adresse papier : https://arxiv.org/pdf/2312.08782.pdf
Dans cette revue, les chercheurs ont utilisé des « modèles de base pour les robots ». Le terme « robotique » couvre deux aspects : (1) modèles de vision et de langage existants (principalement) pour les robots, principalement grâce à l'apprentissage zéro-shot et contextuel ; (2) spécifiquement développés et exploités à l'aide des données générées par les robots. Modèle de base du robot pour résoudre des tâches robotiques. Ils ont résumé les méthodes utilisées dans les articles pertinents pour les modèles de base de robots et ont réalisé une méta-analyse des résultats expérimentaux de ces articles.
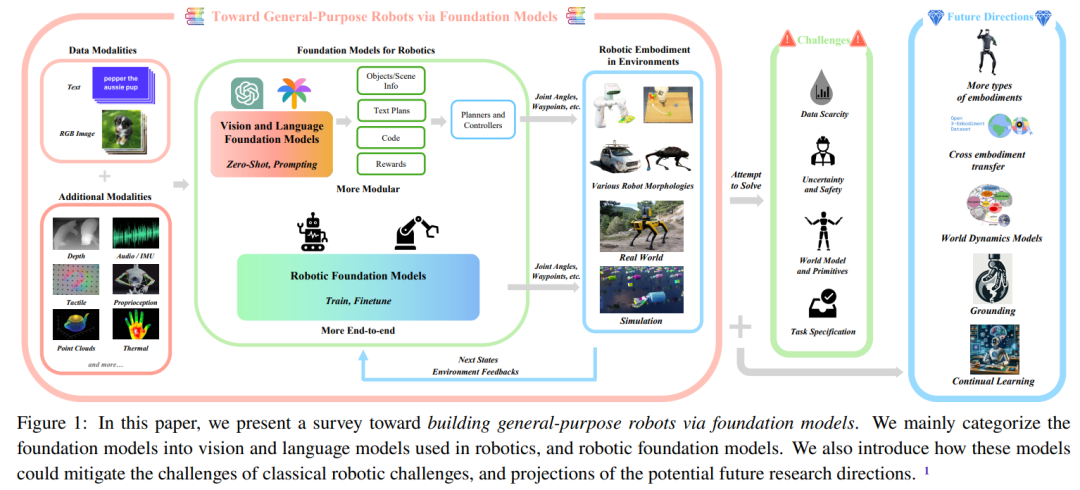
La figure 1 montre les principales composantes de ce rapport d'examen.
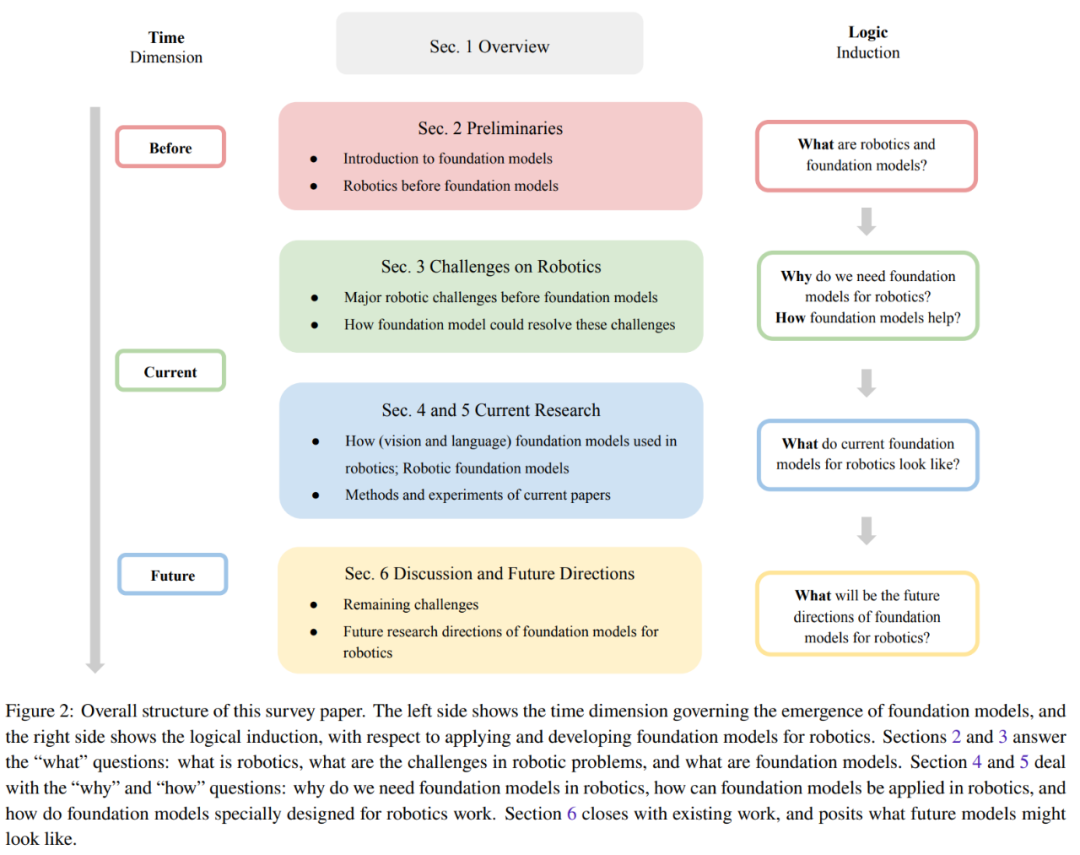
La figure 2 donne la structure globale de cette revue.
Connaissances préliminaires
Afin d'aider les lecteurs à mieux comprendre le contenu de cette revue, l'équipe propose d'abord une section de connaissances préparatoires.
Ils présenteront dans un premier temps les bases de la robotique et les meilleures technologies actuelles. L’accent est mis ici sur les méthodes utilisées dans le domaine de la robotique avant l’ère des modèles de base. Voici une brève explication, veuillez vous référer à l'article original pour plus de détails.
- Les principaux composants du robot peuvent être divisés en trois parties : la perception, la prise de décision et la planification, et la génération d'actions.
- L'équipe divise la perception du robot en perception passive, perception active et estimation de l'état.
- Dans la section prise de décision et planification des robots, les chercheurs ont introduit les méthodes de planification classiques et les méthodes de planification basées sur l'apprentissage.
- La génération d'actions machine dispose également de méthodes de contrôle classiques et de méthodes de contrôle basées sur l'apprentissage.
- Ensuite, l'équipe présentera les modèles de base et se concentrera principalement sur les domaines de la PNL et du CV. Les modèles impliqués comprennent : LLM, VLM, modèle visuel de base et modèle de génération d'images conditionnelles de texte.
Défis dans le domaine de la robotique
Cette section résume les cinq principaux défis auxquels sont confrontés les différents modules d'un système robotique typique. La figure 3 montre la classification de ces cinq défis.
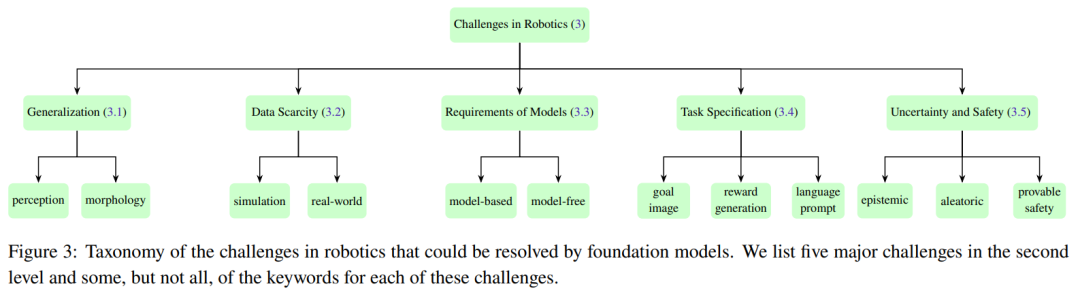
1. Généralisation
Les systèmes robotiques ont souvent des difficultés à détecter et comprendre avec précision leur environnement. Ils n’ont pas non plus la capacité de généraliser les résultats de la formation d’une tâche à une autre, ce qui limite encore davantage leur utilité dans le monde réel. De plus, en raison des différents matériels robotisés, il est également difficile de transférer le modèle vers différentes formes de robots. Le problème de généralisation peut être partiellement résolu en utilisant le modèle de base pour les robots.
Et d'autres questions telles que la généralisation à différentes formes de robots restent encore sans réponse.
2. Rareté des données
Afin de développer des modèles de robots fiables, des données à grande échelle et de haute qualité sont cruciales. Des efforts sont déjà en cours pour collecter des ensembles de données à grande échelle provenant du monde réel, notamment des valeurs automatisées, des trajectoires de fonctionnement des robots, etc. Et la collecte de données robotiques à partir de démonstrations humaines coûte cher. Et en raison de la diversité des tâches et des environnements, le processus de collecte de données suffisantes et étendues dans le monde réel sera encore plus compliqué. De plus, la collecte de données dans le monde réel pose des problèmes de sécurité.
Pour relever ces défis, de nombreux travaux de recherche ont tenté de générer des données synthétiques dans des environnements simulés. Ces simulations peuvent fournir un monde virtuel très réaliste, permettant aux robots d'apprendre et d'utiliser leurs compétences dans des scénarios presque réels. Cependant, l’utilisation d’environnements simulés présente également des limites, notamment en termes de variété d’objets, ce qui rend les compétences acquises difficiles à transférer directement dans des situations réelles.
De plus, dans le monde réel, il est très difficile de collecter des données à grande échelle, et il est encore plus difficile de collecter les données d'image/texte à l'échelle Internet utilisées pour entraîner le modèle de base.
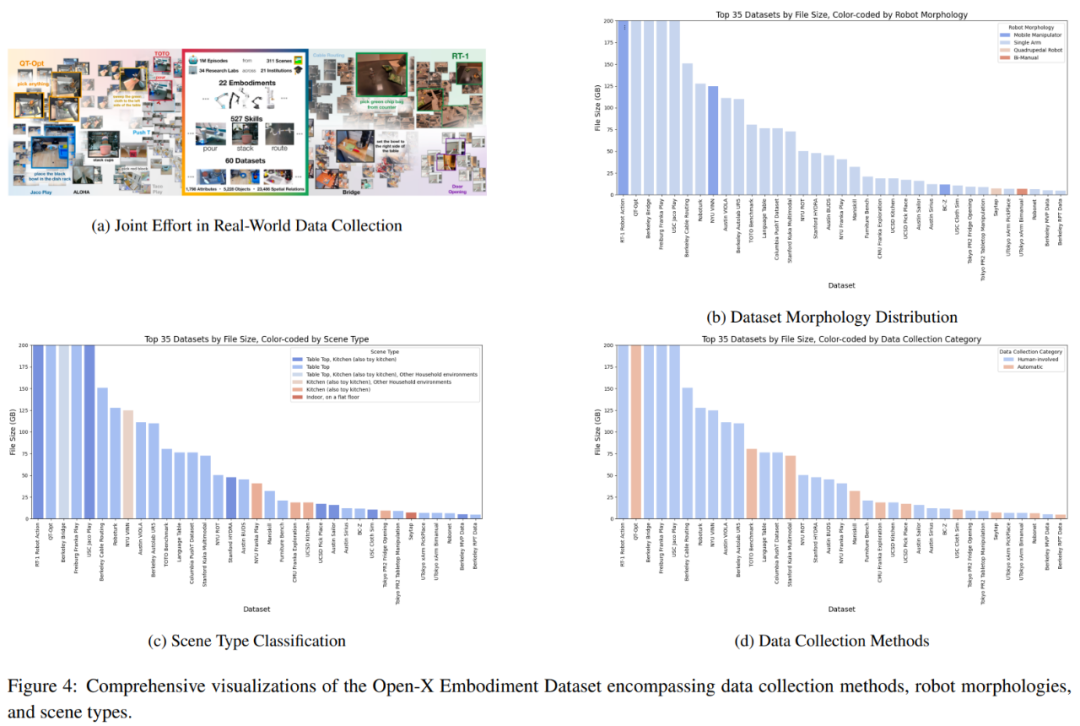
Une approche prometteuse est la collecte collaborative de données, qui collecte ensemble des données provenant de différents environnements de laboratoire et types de robots, comme le montre la figure 4a. Cependant, l’équipe a examiné en profondeur l’ensemble de données d’implémentation Open-X et a découvert qu’il existait certaines limites en termes de disponibilité des types de données.
3. Modèle et exigences primitives
Les méthodes classiques de planification et de contrôle nécessitent généralement un environnement et des modèles de robots soigneusement conçus. Les méthodes précédentes basées sur l’apprentissage (telles que l’apprentissage par imitation et l’apprentissage par renforcement) entraînaient les politiques de bout en bout, c’est-à-dire en obtenant des résultats de contrôle directement à partir d’entrées sensorielles, évitant ainsi la nécessité de créer et d’utiliser des modèles. Ces méthodes peuvent résoudre en partie le problème du recours à des modèles explicites, mais elles sont souvent difficiles à généraliser à différents environnements et tâches.
Cela conduit à deux questions : (1) Comment apprendre une politique indépendante du modèle qui peut bien se généraliser ? (2) Comment apprendre un bon modèle mondial afin que les méthodes classiques basées sur des modèles puissent être appliquées ?
4. Spécifications des tâches
Pour réaliser un agent à usage général, un défi clé consiste à comprendre les spécifications de la tâche et à les ancrer dans la compréhension actuelle du monde du robot. Généralement, ces spécifications de tâches sont fournies par l'utilisateur, qui n'a qu'une compréhension limitée des limites des capacités cognitives et physiques du robot. Cela soulève de nombreuses questions, notamment celles de savoir quelles sont les meilleures pratiques qui peuvent être fournies pour ces spécifications de tâches, mais également si la rédaction de ces spécifications est suffisamment naturelle et simple. Il est également difficile de comprendre et de résoudre les ambiguïtés dans les spécifications des tâches en fonction de la compréhension qu'a le robot de ses capacités.
5. Incertitude et sécurité
Pour déployer des robots dans le monde réel, un défi clé consiste à gérer l'incertitude inhérente à l'environnement et aux spécifications des tâches. Selon la source, l'incertitude peut être divisée en incertitude épistémique (incertitude causée par le manque de connaissances) et incertitude accidentelle (bruit inhérent à l'environnement).
Le coût de la quantification de l'incertitude (UQ) peut être si élevé que la recherche et les applications ne sont pas durables, et cela peut également empêcher la résolution optimale des tâches en aval. Compte tenu de la nature massivement surparamétrée du modèle sous-jacent, afin d'atteindre l'évolutivité sans sacrifier les performances de généralisation du modèle, il est crucial de fournir des méthodes UQ qui préservent le schéma de formation tout en modifiant le moins possible l'architecture sous-jacente. Concevoir des robots capables de fournir des estimations fiables de leur propre comportement et, en retour, de demander intelligemment des commentaires clairement exprimés reste un défi non résolu.
Malgré quelques progrès récents, garantir que les robots aient la capacité d'apprendre de l'expérience pour affiner leurs stratégies et rester en sécurité dans de nouveaux environnements reste un défi.
Aperçu des méthodes de recherche actuelles
Cette section résume les méthodes de recherche actuelles utilisées pour le modèle de base du robot. L'équipe a divisé les modèles de base utilisés dans le domaine de la robotique en deux grandes catégories : les modèles de base pour robots et les modèles de base de robots (RFM).
Le modèle de base pour les robots fait principalement référence à l'utilisation des modèles de base visuels et linguistiques pour les robots d'une manière sans échantillon, ce qui signifie qu'aucun réglage ni formation supplémentaire n'est requis. Le modèle de base du robot peut être démarré à chaud à l'aide d'une initialisation de pré-entraînement en langage visuel et/ou le modèle peut être entraîné directement sur l'ensemble de données du robot.
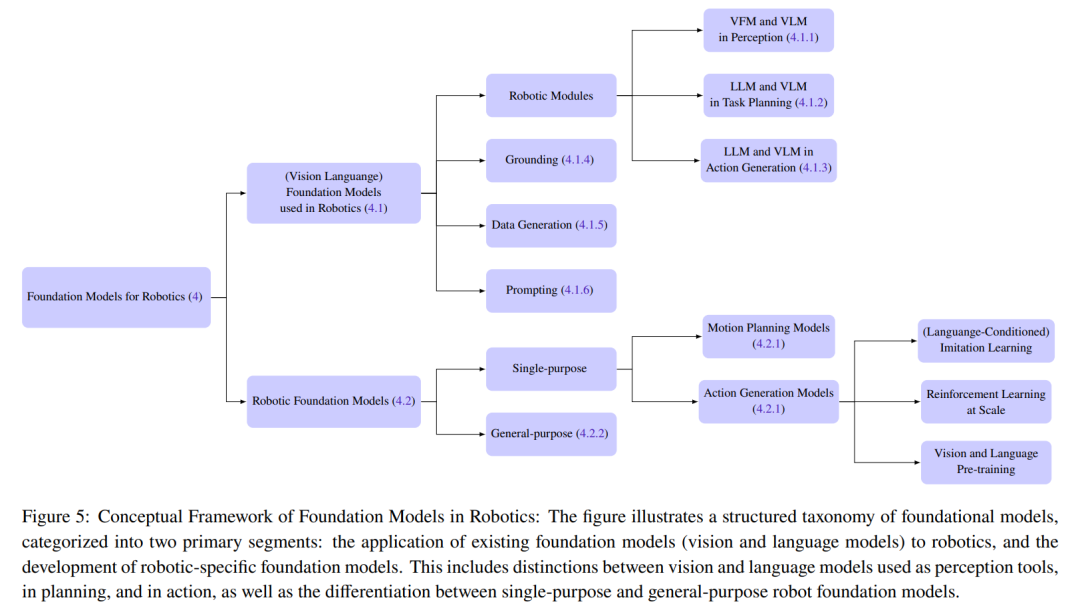
La figure 5 donne les détails de la classification
1. Modèle de base pour les robots
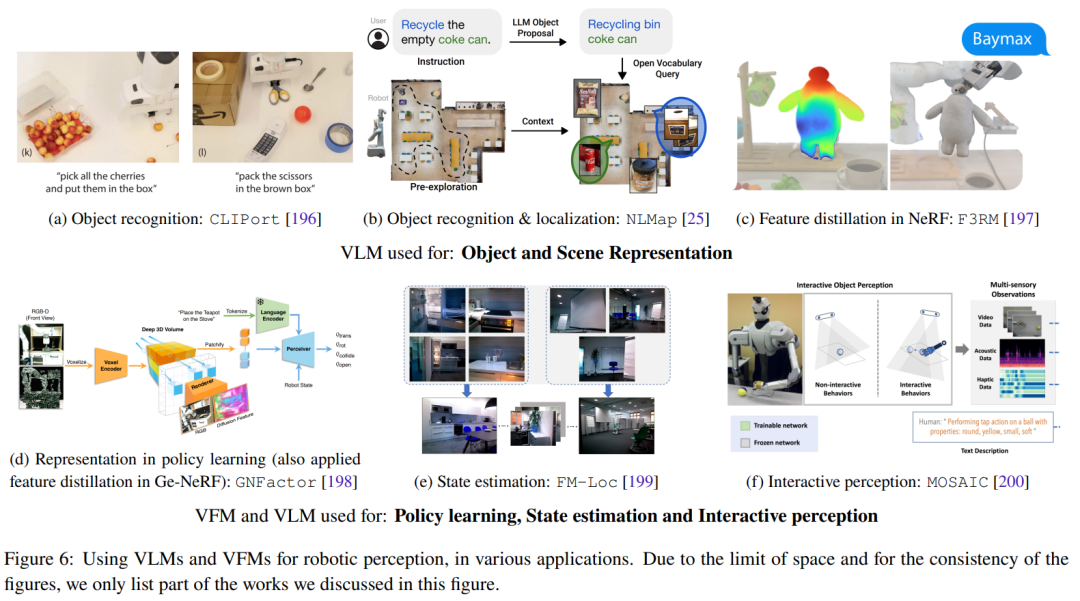
Cette section se concentre sur l'application zéro de modèles de base visuels et linguistiques dans le domaine de la robotique. Cela comprend principalement le déploiement de VLM de manière zéro-shot dans des applications de perception robotique, en utilisant les capacités d'apprentissage contextuel de LLM pour la planification et la génération d'actions au niveau des tâches et des mouvements. La figure 6 montre quelques travaux de recherche représentatifs.
2. Modèle fondamental du robot (RFM)
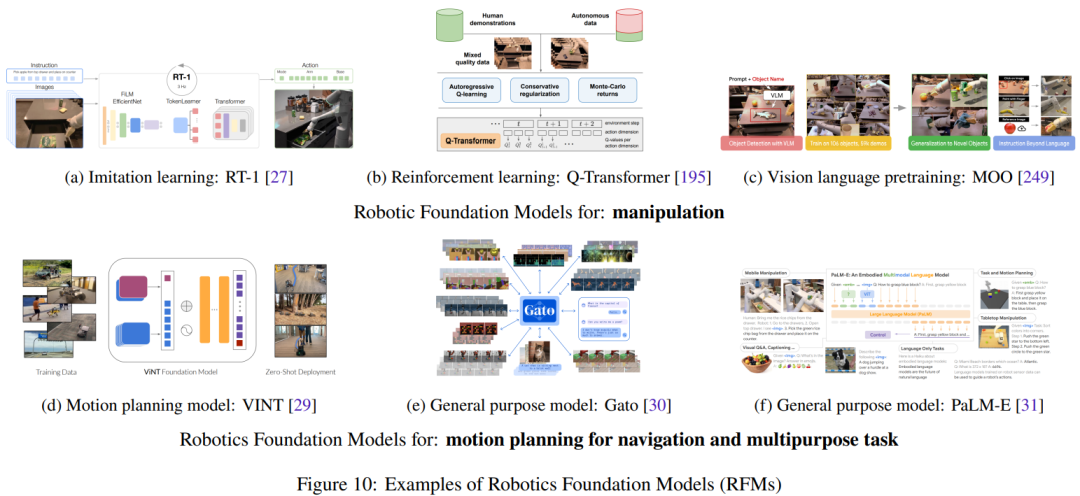
mentals Le modèle (RFM ) cette catégorie a également de plus en plus de chances de réussir. Ces modèles utilisent des données robotiques pour entraîner le modèle à résoudre des tâches robotiques.
Cette section résumera et discutera des différents types de RFM. Le premier est un RFM capable d’effectuer un type de tâche dans un seul module robotique, également appelé modèle de base de robot à objectif unique. Par exemple, RFM peut générer des actions de bas niveau pour contrôler le robot ou des modèles pouvant générer une planification de mouvement de niveau supérieur.
Plus tard, nous présenterons le RFM qui peut effectuer des tâches dans plusieurs modules robotiques, c'est-à-dire un modèle universel qui peut effectuer des tâches de perception, de contrôle et même non robotiques.
3. Comment les modèles de base peuvent-ils aider à résoudre les défis de la robotique ?
Les cinq défis majeurs auxquels est confronté le domaine de la robotique sont listés ci-dessus. Cette section décrit comment les modèles de base peuvent aider à relever ces défis.
Tous les modèles de base liés aux informations visuelles (tels que VFM, VLM et VGM) peuvent être utilisés dans le module de perception du robot. LLM, en revanche, est plus polyvalent et peut être utilisé pour la planification et le contrôle. Le Robot Basic Model (RFM) est généralement utilisé dans les modules de planification et de génération d'actions. Le tableau 1 résume les modèles sous-jacents pour résoudre différents défis robotiques.
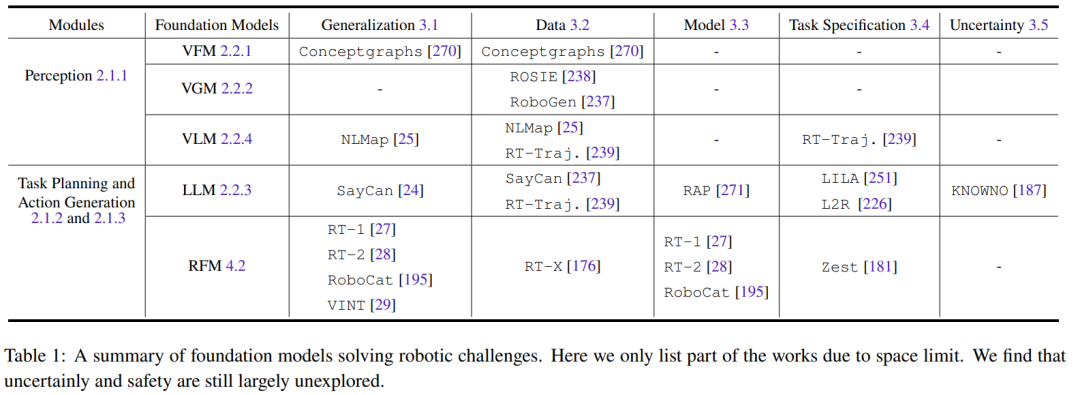
Comme le montre le tableau, tous les modèles de base sont efficaces pour généraliser les tâches des différents modules robotiques. LLM est particulièrement doué pour la spécification des tâches. Le RFM, en revanche, est efficace pour relever les défis des modèles dynamiques puisque la plupart des RFM sont des approches sans modèle. Pour la perception du robot, les capacités de généralisation et les défis du modèle sont couplés, car si le modèle de perception possède déjà de bonnes capacités de généralisation, il n'est pas nécessaire d'acquérir davantage de données pour effectuer une adaptation de domaine ou un réglage précis supplémentaire.
De plus, il y a encore un manque de recherche sur les défis de sécurité, qui constitueront une direction de recherche future importante.
Aperçu des expériences et évaluations actuelles
Cette section résume les résultats de la recherche actuelle sur les ensembles de données, les références et les expériences.
1. Ensembles de données et références
Il y a des limites à s'appuyer uniquement sur les connaissances acquises à partir d'ensembles de données linguistiques et visuelles. Comme le montrent certains résultats de recherche, certains concepts tels que la friction et le poids ne peuvent pas être facilement appris par ces seules modalités.
Par conséquent, pour permettre aux agents robotiques de mieux comprendre le monde, la communauté des chercheurs adapte non seulement des modèles fondamentaux issus des domaines du langage et de la vision, mais fait également progresser le développement de robots multimodaux de grande taille et diversifiés pour les entraîner et les affiner. modèles.
Actuellement, ces efforts sont divisés en deux directions principales : la collecte de données du monde réel et la collecte de données du monde simulé et leur migration vers le monde réel. Chaque direction a ses avantages et ses inconvénients. Les ensembles de données collectés dans le monde réel incluent RoboNet, Bridge Dataset V1, Bridge-V2, Language-Table, RT-1, etc. Les simulateurs couramment utilisés incluent Habitat, AI2THOR, Mujoco, AirSim, Arrival Autonomous Racing Simulator, Issac Gym, etc.
2. Analyse d'évaluation des méthodes actuelles
Une autre contribution majeure de cette équipe est une méta-analyse des expériences dans les articles mentionnés dans ce rapport de synthèse, qui peut aider les auteurs à clarifier les questions suivantes :
- Quelles tâches les gens recherchent et résolvent-ils ?
- Quels ensembles de données ou simulateurs ont été utilisés pour entraîner le modèle ? Quelles sont les plateformes robotiques utilisées pour les tests ?
- Quels modèles de base sont utilisés par la communauté des chercheurs ? Dans quelle mesure est-il efficace pour résoudre la tâche ?
- Quels modèles de base sont les plus couramment utilisés parmi ces méthodes ?
Le Tableau 2-7 et la Figure 11 donnent les résultats de l'analyse.
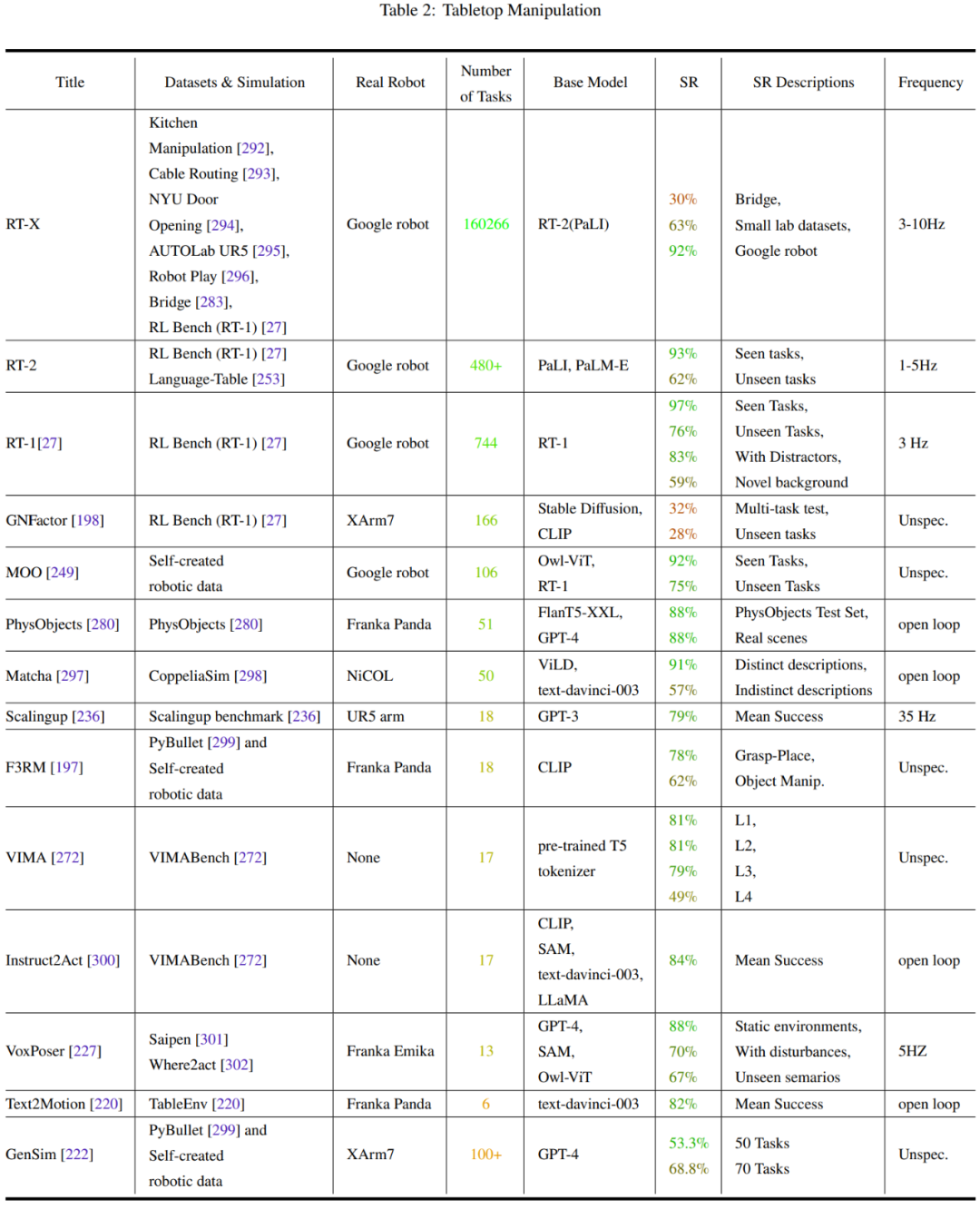
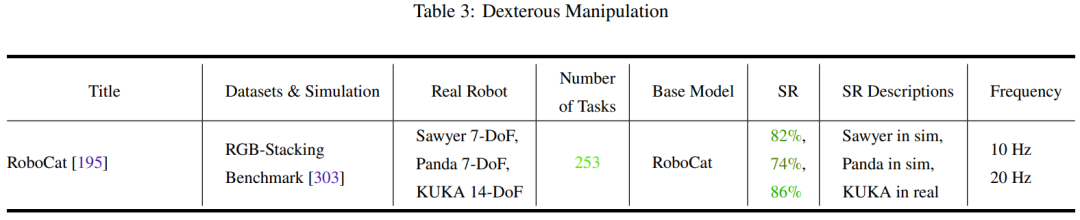
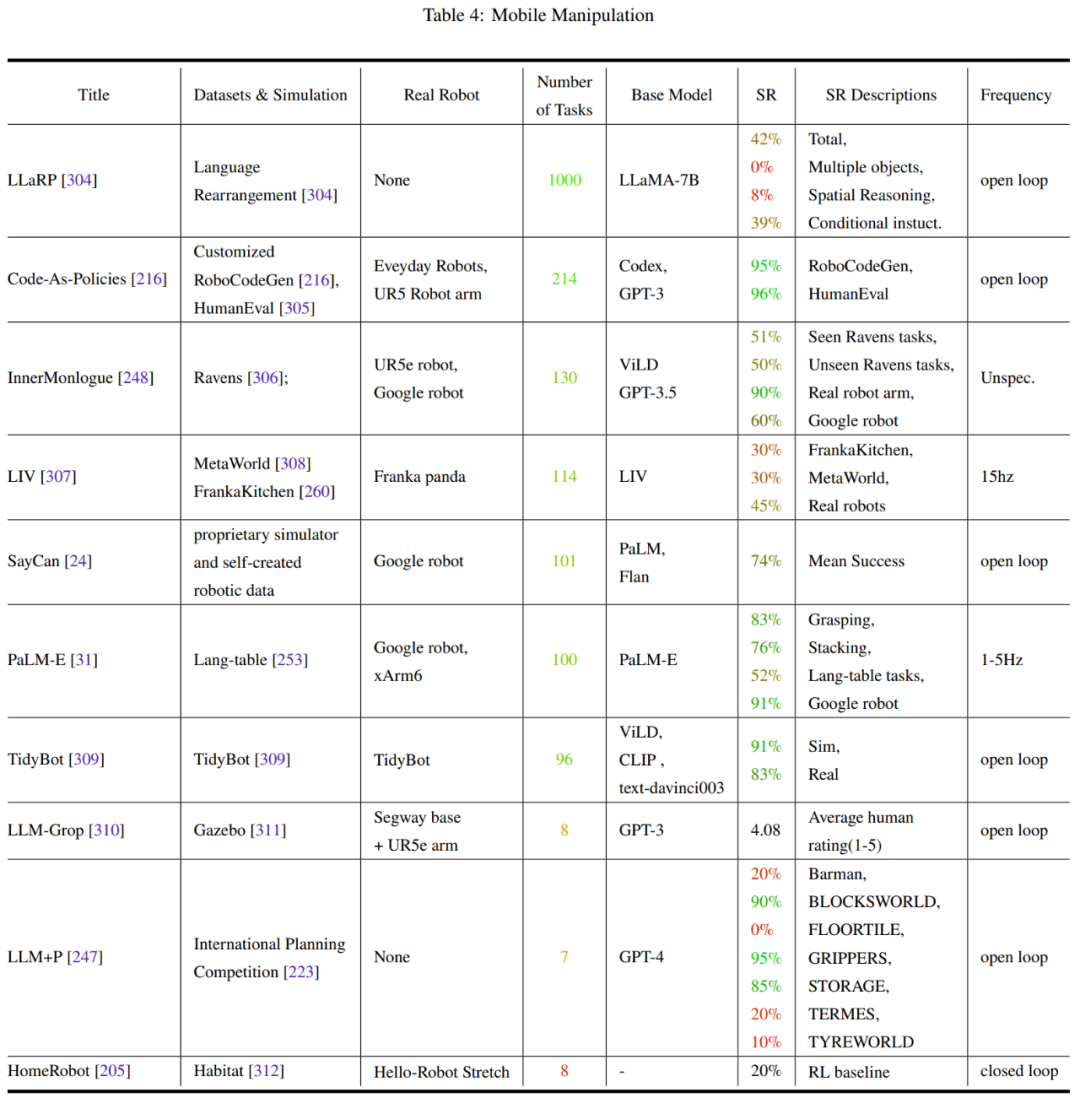
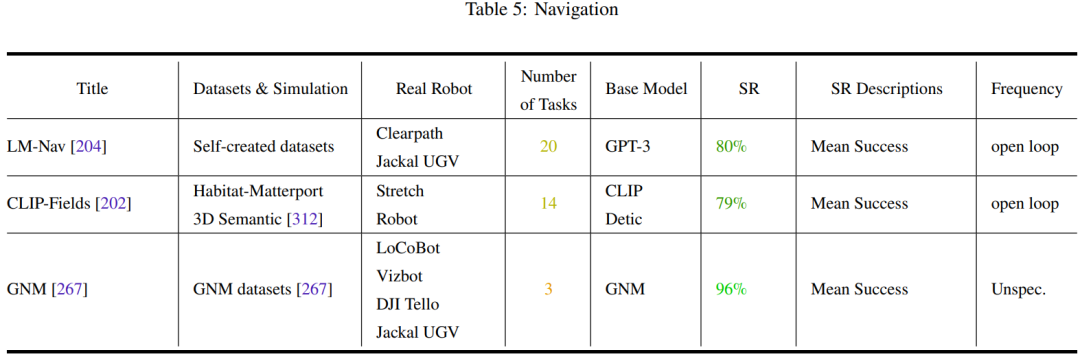

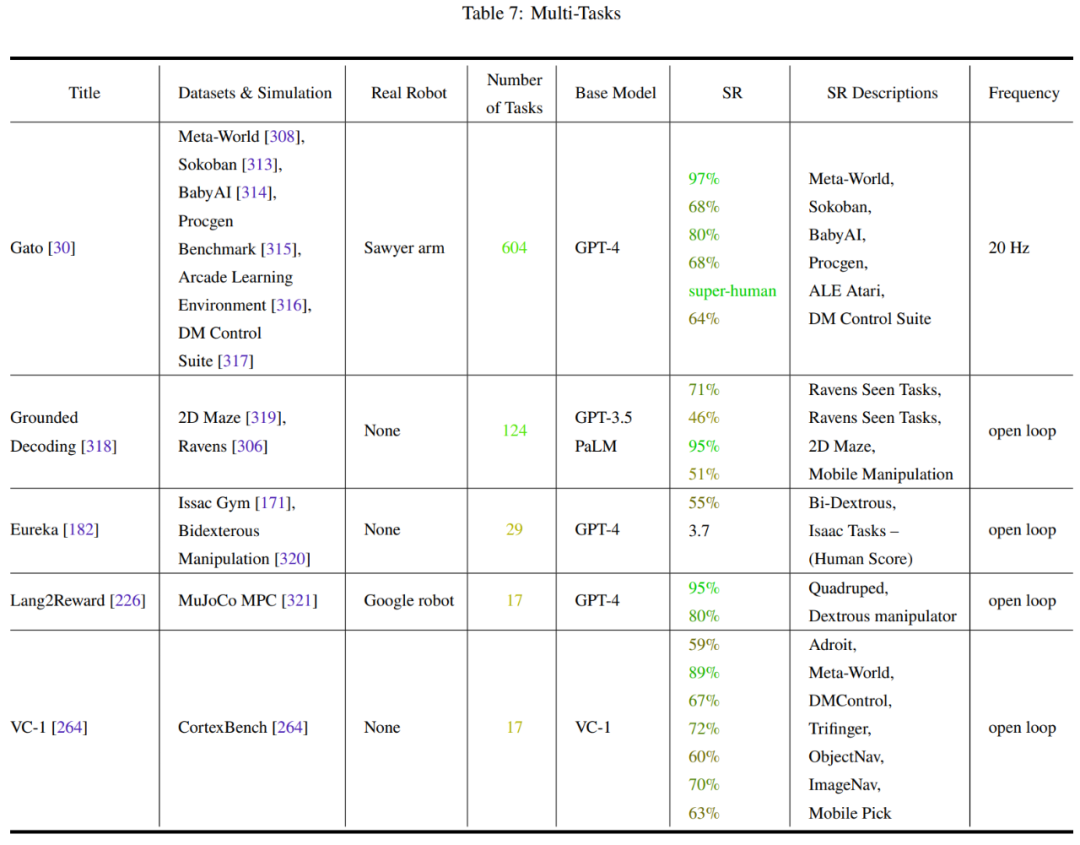
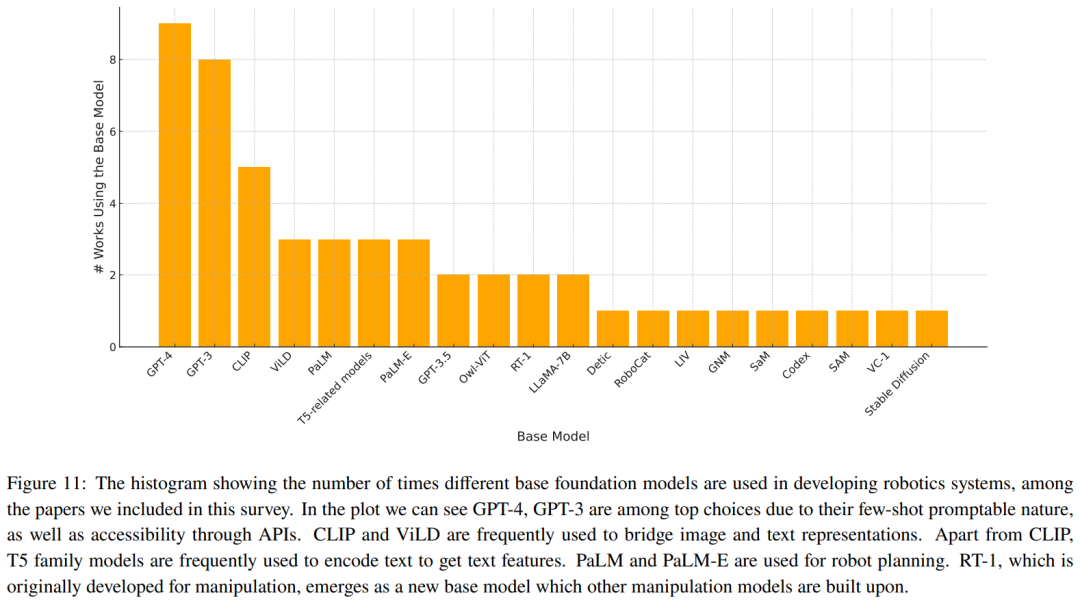
L'équipe a identifié quelques tendances clés :
- L'attention de la communauté des chercheurs aux tâches de fonctionnement des robots est déséquilibrée
- La capacité de généralisation et la robustesse doivent être améliorées
- L'exploration des actions de bas niveau est limitée
- La fréquence de contrôle est trop faible pour être déployée dans de vrais robots
- Manque de tests de référence unifiés
Discussion et orientations futures
L'équipe a résumé certains défis qui doivent encore être résolus et des orientations de recherche dignes de discussion :
- Établir une base standard pour l'incarnation du robot (grounding) )
- Sécurité et incertitude
- Les approches de bout en bout et les approches modulaires sont-elles incompatibles ?
- Adaptabilité aux changements physiques incarnés
- Approche modèle mondial ou approche indépendante du modèle ?
- Nouvelle plateforme robotique et informations multisensorielles
- Apprentissage continu
- Standardisation et reproductibilité
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI