
Maison >Périphériques technologiques >IA >2024 ICASSP | Solution innovante de l'équipe ByteDance Streaming Media Audio : résoudre les problèmes de compensation de perte de paquets et de réparation générale de la qualité sonore
2024 ICASSP | Solution innovante de l'équipe ByteDance Streaming Media Audio : résoudre les problèmes de compensation de perte de paquets et de réparation générale de la qualité sonore

- WBOYavant
- 2024-01-09 09:14:34785parcourir
Dans ce défi audio international ICASSP 2024, l'équipe ByteDance Streaming Audio s'est associée au laboratoire de recherche sur le traitement audio de la parole et du langage de la Northwestern Polytechnical University pour travailler sur la dissimulation de perte de paquets (PLC) et la réparation de la qualité sonore (parole) dans les deux défis. pistes d'amélioration du signal (SSI), il a obtenu de bons résultats sur plusieurs indicateurs et a atteint respectivement la première et la deuxième place, atteignant le premier niveau international.
L'Audio Challenge du sommet ICASSP a été lancé conjointement par la plus grande conférence audio internationale ICASSP et Microsoft, dans le but de stimuler la recherche sur les effets audio et l'amélioration de la qualité sonore par diverses institutions de recherche. Depuis la première session, il a attiré Amazon, Tencent, et Alibaba De nombreuses entreprises et instituts de recherche scientifique de renom dans le monde entier, notamment Baba, Baidu, Kuaishou, l'Académie chinoise des sciences et NPU, y ont participé. Avec le développement continu de la technologie dans le domaine du streaming multimédia, rendre le son clair et authentique est devenu une tendance inévitable dans le développement de l'industrie de la technologie audio. En se concentrant sur la manière d'offrir aux utilisateurs une meilleure expérience audio, plusieurs équipes de recherche ont procédé à une optimisation de bout en bout de l'audio, de la collecte au transfert. Ce processus inclut la manière de gérer les défauts de collecte audio, les défauts de traitement des algorithmes, les défauts de codage et de décodage. , et les défauts de transmission réseau. Attendez la réparation intégrée. Dans ce défi, l'équipe de streaming audio de ByteDance a participé à deux pistes de défi, la compensation des pertes de paquets et la réparation générale de la qualité sonore, sur la base de scénarios de mise en œuvre commerciaux réels.
ICASSP PLC Challenge vise à résoudre les problèmes de perte de paquets à long intervalle et de traitement audio pleine bande (taux d'échantillonnage de 48 kHz) dans les appels réseau IP. Le défi comporte des contraintes de latence strictes tout en fournissant un ensemble de données exigeant qui reflète des conditions de réseau défavorables. L'évaluation subjective sera menée à l'aide de la méthode d'évaluation de la qualité audio multidimensionnelle P.804, tandis que WER est également utilisé pour évaluer l'intelligibilité de la parole générée par les systèmes participants. L'équipe chargée de la technologie du streaming audio a efficacement réduit la complexité du modèle de compensation des pertes de paquets en optimisant la structure du modèle. Dans le même temps, grâce à une formation contradictoire multi-discriminatrice et à un apprentissage multitâche, le modèle de compensation des pertes de paquets peut restaurer les fragments de perte de paquets avec une haute qualité et une intelligibilité élevée, et a finalement obtenu la première place.
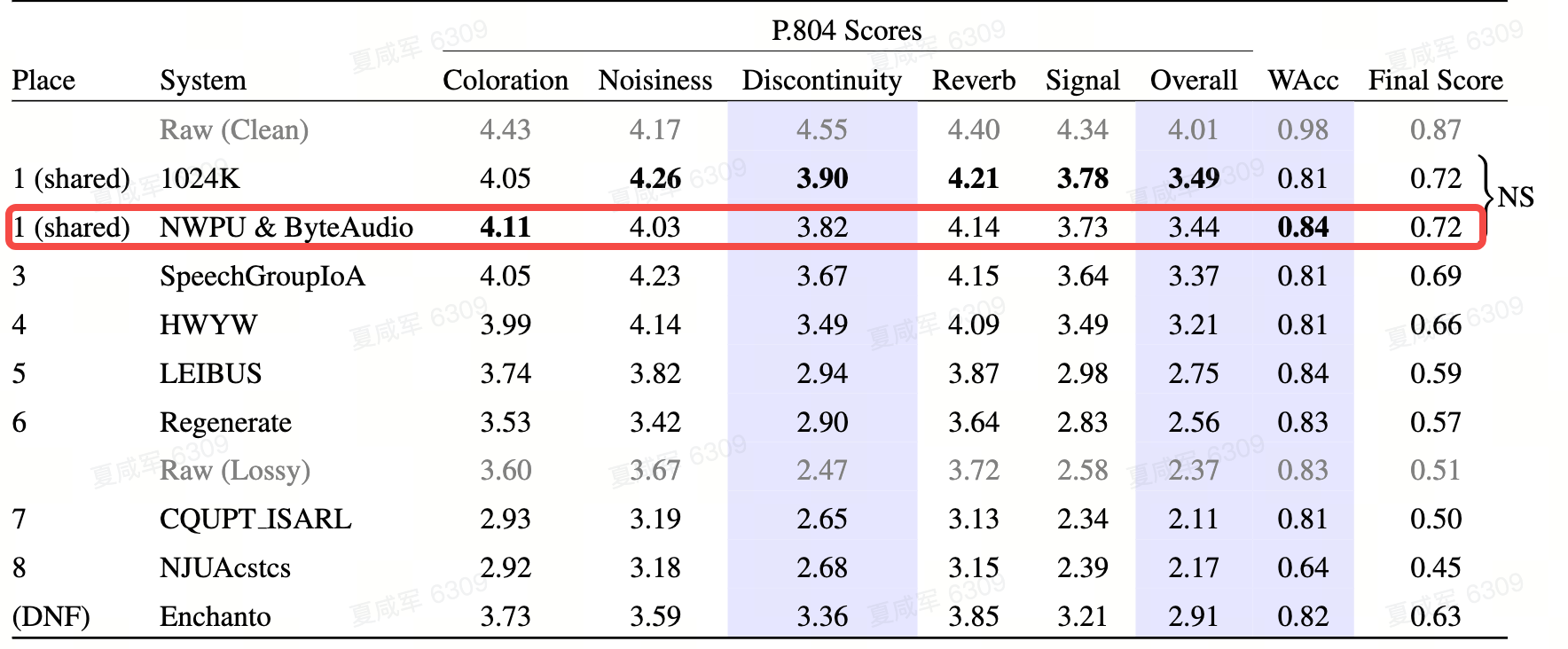
ICASSP SSI Challenge vise à résoudre cinq types de problèmes rencontrés par les signaux vocaux dans les systèmes de communication : distorsion de la réponse en fréquence, distorsion de discontinuité, distorsion du volume, bruit et réverbération. Ce défi utilise les scores d'opinion subjectifs et le taux de reconnaissance vocale selon la norme ITU-TP.804 pour juger de manière exhaustive les classements en partant du principe de définir strictement le retard et la causalité du modèle. L'équipe de technologie de streaming utilise une structure de modèle en deux étapes pour simplifier le problème de réparation complexe en plusieurs sous-tâches. Dans la première étape, elle répare principalement la distorsion de la réponse en fréquence, la distorsion de discontinuité et la distorsion du volume, et effectue une réduction préliminaire du bruit et une déréverbération ; la deuxième étape Cette étape supprime en outre les artefacts générés lors de la première étape ainsi que le bruit résiduel. Au final, l'équipe a obtenu la deuxième place sur la piste en temps réel.
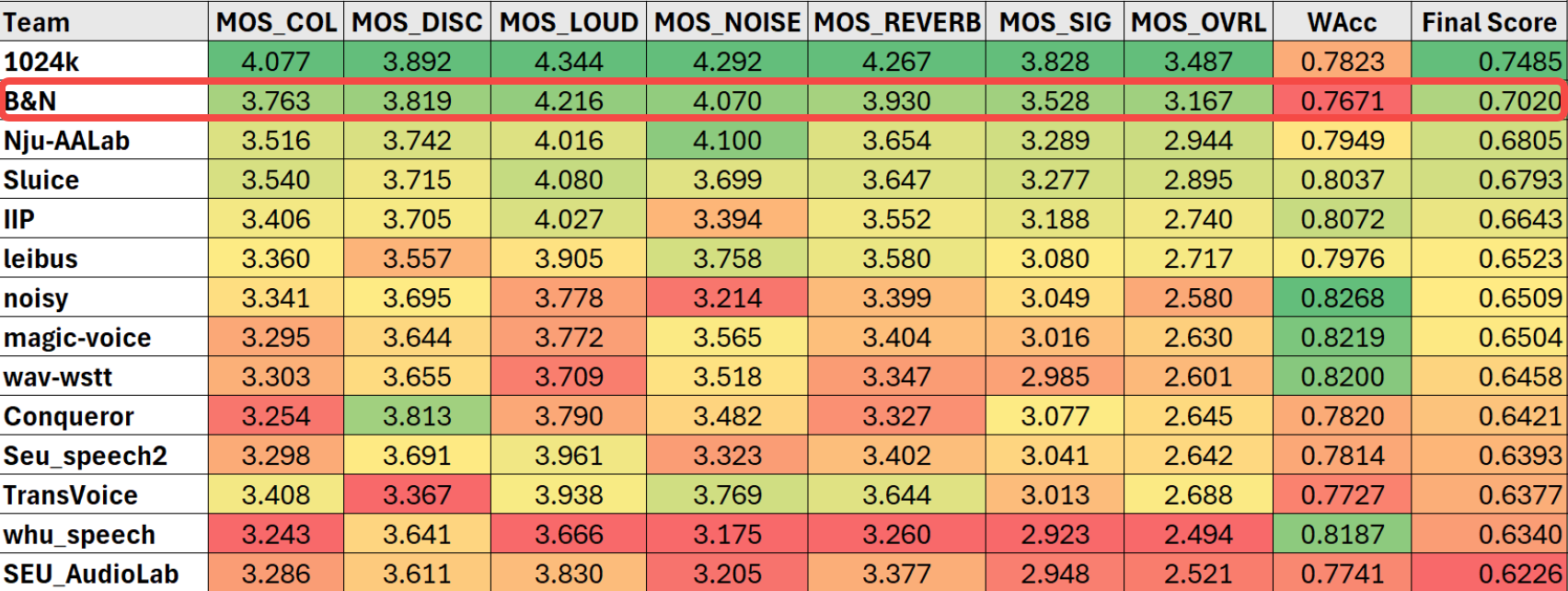
Système de compensation de perte de paquets
Afin de résoudre le problème de la complexité du traitement audio pleine bande à 48 kHz, un modèle de domaine fréquentiel est utilisé dans le système de compensation de perte de paquets, et l'audio est divisé en 0-8 kHz , 8- Les deux sous-bandes 24kHz sont traitées en parallèle. La principale quantité de calcul est concentrée dans la bande de fréquences 0-8 kHz qui a un plus grand impact sur le sens de l'audition, obtenant une compensation de perte de paquets de faible complexité et de haute qualité. Afin de résoudre le problème de la perte de paquets à long intervalle, un module de convolution dilatée temps-fréquence (TFDCM) est ajouté après chaque couche du codec. Tout en conservant une petite taille du noyau de convolution, il capture à long terme via la causalité. convolution dilatée couche par couche dans les dimensions temporelles et fréquentielles.
Afin de compenser une qualité audio supérieure, un discriminateur multi-résolution dans le domaine fréquentiel, un discriminateur multi-période dans le domaine temporel et MetricGAN sont utilisés en combinaison pour effectuer un entraînement contradictoire génératif, rendant le son audio généré excellent. Pour les problèmes de perte de paquets et d'intelligibilité à long intervalle, un cadre d'apprentissage multitâche est utilisé. En plus de l'apprentissage habituel de la similarité des signaux vocaux, des fonctions de prédiction de fréquence fondamentale et de perte de compréhension sémantique basées sur le chuchotement sont également introduites. Le modèle peut récupérer des fragments de perte de paquets d'une durée supérieure à 100 ms avec une haute qualité, et l'audio récupéré est hautement intelligible. L'indicateur du taux de précision des mots (WAcc) est en tête de toutes les équipes participantes, et le score d'évaluation global est à égalité pour la première place.
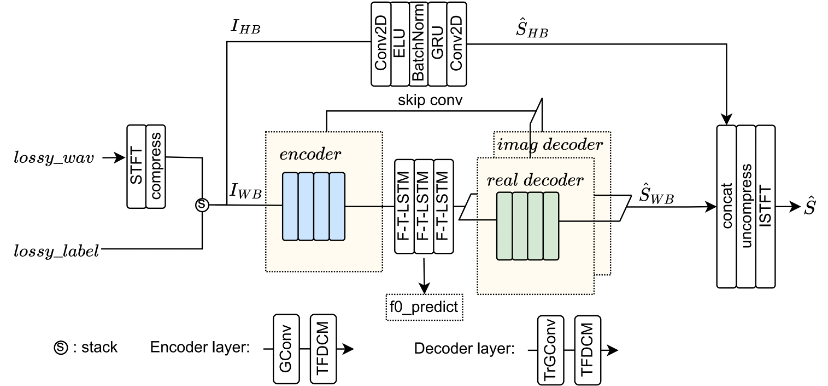
Schéma de structure du modèle de compensation de perte de paquets
Système de réparation de la qualité sonore
Afin de réparer l'audio affecté par plusieurs distorsions en même temps, une architecture de modèle en deux étapes est utilisée dans le système de construction, en se concentrant sur le traitement de différentes distorsions à différentes étapes. Le modèle de première étape utilise le mappage pour prédire directement le spectre complexe de l'audio réparé, de sorte que le modèle ait la capacité de générer des composants audio manquants et d'éliminer en même temps les signaux d'interférence, afin d'améliorer la capacité du modèle à capturer des informations. pendant longtemps, l'encodeur est introduit dans le décodeur (TFCM) en raison de l'instabilité de la méthode de cartographie, des artefacts peuvent se produire, donc un modèle en deux étapes utilisant le masquage (Masque) est introduit, et le procédé de modélisation de bande à bande complète effectue une modélisation fine des bandes de fréquences pour éliminer davantage les artefacts et le bruit résiduel générés par le modèle de première étape.
Afin d'améliorer le naturel des composants audio générés, un cadre de réseau contradictoire génératif est introduit, et un discriminateur multi-résolution et un discriminateur multi-résolution à bande moléculaire sont utilisés pour aider la formation du modèle. Dans le même temps, afin de faire converger plus facilement le modèle à plusieurs étages pendant l'entraînement, le modèle à deux étages est d'abord pré-entraîné sur les tâches de réduction du bruit et de déréverbération, puis les paramètres du modèle à une étape entraîné sont gelés et comparés au modèle de deuxième étape pré-entraîné. Les modèles d'étape sont mis en cascade pour une formation conjointe, accélérant ainsi la convergence des modèles.
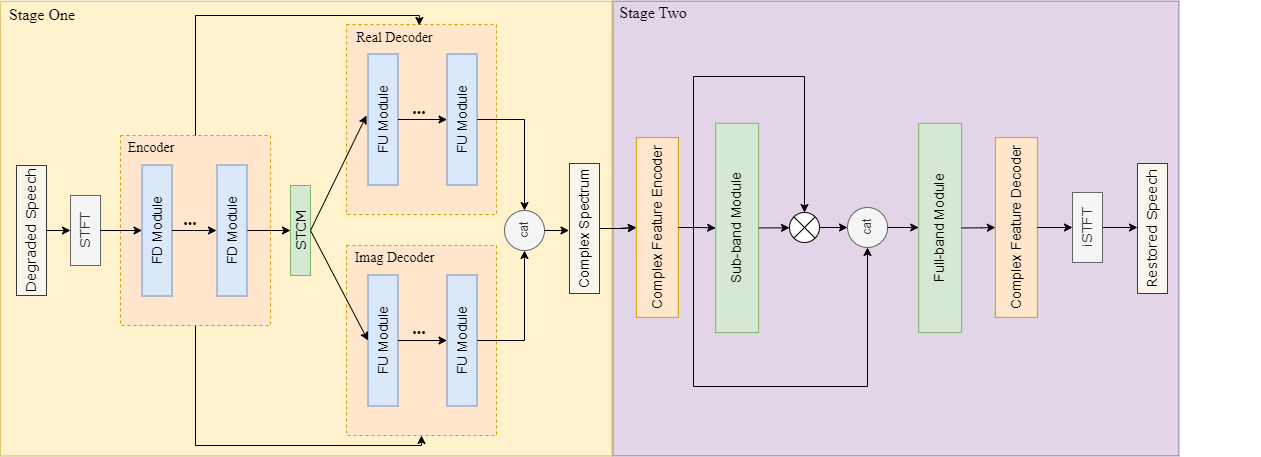
Schéma schématique de la structure du modèle de réparation de la qualité sonore
Présentation de l'équipe
L'équipe audio en streaming de Bytedance s'engage à fournir des capacités de communication audio et vidéo en temps réel de haute qualité et à faible latence sur l'Internet mondial pour aider les développeurs rapidement Il a créé de riches fonctions de scénario telles que les appels vocaux, les appels vidéo, les diffusions interactives en direct, le retweet des diffusions en direct, etc. Il couvre actuellement des scénarios interactifs audio et vidéo en temps réel tels que le divertissement interactif, l'éducation, les conférences, les jeux, les automobiles , la finance et l'IoT, au service de centaines de millions d'utilisateurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Dirigeant d'Audi : la pénurie de semi-conducteurs a plongé l'industrie automobile allemande dans une période de goulot d'étranglement qui durera plusieurs années
- Les normes façonnent une vie meilleure, conférence de promotion de la normalisation de l'industrie des robots et des machines-outils CNC à Suzhou
- Utiliser des concours pour promouvoir l'apprentissage et les résultats des tests afin d'aider l'industrie de l'Internet des objets à réaliser un développement de haute qualité
- Cette entreprise de Changning a lancé de nouveaux produits lors de la World VR Industry Conference !
- Le Forum général de développement de l'industrie des grands modèles d'intelligence artificielle et la cérémonie de dévoilement de la zone du cluster industriel des grands modèles d'intelligence artificielle générale dans le district de Shijingshan se sont déroulés avec succès.