La vague de grands modèles arrivant sur le terminal mobile devient de plus en plus forte, et finalement quelqu'un a déplacé les grands modèles multimodaux vers le terminal mobile. Récemment, Meituan, l'Université du Zhejiang, etc. ont lancé de grands modèles multimodaux qui peuvent être déployés sur le terminal mobile, y compris l'ensemble du processus de formation de base LLM, SFT et VLM. Peut-être que dans un avenir proche, chacun pourra posséder son propre grand modèle de manière pratique, rapide et à faible coût.
MobileVLM est un assistant de langage visuel rapide, puissant et ouvert conçu pour les appareils mobiles. Il combine une conception architecturale et une technologie pour les appareils mobiles, notamment des modèles de langage de paramètres 1.4B et 2.7B formés à partir de zéro, des modèles de vision multimodaux pré-entraînés de manière CLIP et une interaction multimodale efficace grâce à la projection. Les performances de MobileVLM sont comparables à celles des grands modèles sur divers tests de langage visuel. De plus, il démontre les vitesses d'inférence les plus rapides sur le processeur Qualcomm Snapdragon 888 et le GPU NVIDIA Jeston Orin. 
- Adresse papier : https://arxiv.org/pdf/2312.16886.pdf
- Adresse code : https://github.com/Meituan-AutoML/MobileVLM
Les modèles multimodaux à grande échelle (LMM), en particulier la famille des modèles de langage visuel (VLM), sont devenus une direction de recherche prometteuse pour la construction d'assistants universels en raison de leurs capacités considérablement améliorées en matière de perception et de raisonnement. Cependant, comment connecter les représentations de grands modèles de langage (LLM) et de modèles visuels pré-entraînés, extraire des fonctionnalités multimodales et effectuer des tâches telles que la réponse visuelle aux questions, les sous-titres d'images, le raisonnement visuel des connaissances et le dialogue a toujours été un problème. . Les excellentes performances de GPT-4V et Gemini dans cette tâche ont été prouvées à plusieurs reprises. Cependant, les détails techniques de mise en œuvre de ces modèles propriétaires sont encore mal compris. Parallèlement, la communauté des chercheurs a également proposé une série de méthodes d’ajustement linguistique. Par exemple, Flamingo exploite des jetons visuels pour conditionner des modèles de langage figés via des couches d'attention croisée fermées. BLIP-2 considère cette interaction insuffisante et introduit un transformateur de requête léger (appelé Q-Former) qui extrait les fonctionnalités les plus utiles de l'encodeur visuel gelé et les alimente directement dans le gel de LLM. MiniGPT-4 associe l'encodeur visuel gelé de BLIP-2 au modèle de langage gelé Vicuna via une couche de projection. De plus, LLaVA applique un réseau de cartographie simple pouvant être entraîné pour convertir les caractéristiques visuelles en jetons d'intégration ayant les mêmes dimensions que les intégrations de mots à traiter par le modèle de langage. Il est à noter que les stratégies de formation évoluent progressivement pour s'adapter à la diversité des données multimodales à grande échelle. LLaVA pourrait être la première tentative de reproduire le paradigme de réglage des instructions de LLM dans un scénario multimodal. Pour générer des données de trace d'instructions multimodales, LLaVA saisit des informations textuelles, telles que la phrase de description de l'image et les coordonnées du cadre englobant de l'image, dans le modèle de langage pur GPT-4. MiniGPT-4 est d'abord formé sur un ensemble de données complet de phrases de description d'image, puis affiné sur un ensemble de données d'étalonnage de paires [image-texte]. InstructBLIP effectue le réglage des commandes du langage visuel basé sur le modèle BLIP-2 pré-entraîné, et Q-Former est formé sur divers ensembles de données organisés dans un format optimisé par les commandes. mPLUG-Owl introduit une stratégie de formation en deux étapes : d'abord pré-entraîner la partie visuelle, puis utiliser LoRA pour affiner le grand modèle de langage LLaMA en fonction des données d'instruction provenant de différentes sources. Malgré les progrès mentionnés ci-dessus du VLM, il existe également un besoin d'utiliser des fonctions multimodales avec des ressources informatiques limitées. Gemini surpasse sota sur une gamme de références multimodales et introduit un VLM de qualité mobile avec des paramètres de 1,8 B et 3,25 B pour les appareils à faible mémoire. Et Gemini utilise également des techniques de compression courantes telles que la distillation et la quantification. L'objectif de cet article est de créer le premier VLM ouvert de qualité mobile, formé à l'aide d'ensembles de données publics et de technologies disponibles pour la perception visuelle et le raisonnement, et adapté aux plates-formes aux ressources limitées. Les contributions de cet article sont les suivantes :
- Cet article propose MobileVLM, qui est une transformation full-stack d'un modèle de langage visuel multimodal personnalisé pour les scénarios mobiles. Selon les auteurs, il s’agit du premier modèle de langage visuel à offrir des performances détaillées, reproductibles et puissantes à partir de zéro. Grâce à des ensembles de données contrôlés et open source, les chercheurs ont établi un ensemble de modèles linguistiques de base et de modèles multimodaux hautes performances.
- Cet article mène des expériences d'ablation approfondies sur la conception d'encodeurs visuels et évalue systématiquement la sensibilité des performances des VLM à divers paradigmes de formation, résolutions d'entrée et tailles de modèle.
- Cet article conçoit un réseau de cartographie efficace entre les fonctionnalités visuelles et les fonctionnalités textuelles, qui permet de mieux aligner les fonctionnalités multimodales tout en réduisant la consommation de raisonnement.
- Le modèle conçu dans cet article peut fonctionner efficacement sur des appareils mobiles à faible consommation, avec une vitesse mesurée de 21,5 jetons/s sur le processeur mobile de Qualcomm et le processeur de 65,5 pouces.
- MobileVLM et un grand nombre de grands modèles multimodaux fonctionnent également bien sur les benchmarks, prouvant son potentiel d'application dans de nombreuses tâches pratiques. Bien que cet article se concentre sur les scénarios de pointe, MobileVLM surpasse de nombreux VLM de pointe qui ne peuvent être pris en charge que par de puissants GPU dans le cloud. Conception de l'architecture globale de LMoBilevlmo
Considérant l'objectif principal d'obtenir une perception visuelle et un raisonnement efficaces pour les équipements marginaux avec des ressources limitées, les chercheurs ont conçu Mobilevlm. L'architecture globale, comme le montre la figure 1, le modèle contient trois composants : 1 ) encodeur visuel, 2) dispositif de bord LLM personnalisé (MobileLLaMA) et 3) réseau de cartographie efficace (appelé dans l'article « cartographie de sous-échantillonnage léger », LDP) pour aligner l'espace visuel et textuel.
Prenez une image 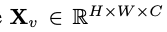 en entrée et l'encodeur visuel F_enc en extrait l'intégration visuelle
en entrée et l'encodeur visuel F_enc en extrait l'intégration visuelle 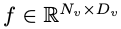 pour la perception de l'image, où N_v = HW/P^2 représente le nombre de patchs d'image et D_v représente la taille de la couche cachée de l'intégration visuelle. Afin d'atténuer le problème d'efficacité du traitement des jetons d'image, les chercheurs ont conçu un réseau de cartographie léger P pour la compression des caractéristiques visuelles et l'alignement modal du texte visuel. Il transforme f en espace d'intégration de mots et fournit des dimensions d'entrée appropriées pour le modèle de langage suivant, comme suit :
pour la perception de l'image, où N_v = HW/P^2 représente le nombre de patchs d'image et D_v représente la taille de la couche cachée de l'intégration visuelle. Afin d'atténuer le problème d'efficacité du traitement des jetons d'image, les chercheurs ont conçu un réseau de cartographie léger P pour la compression des caractéristiques visuelles et l'alignement modal du texte visuel. Il transforme f en espace d'intégration de mots et fournit des dimensions d'entrée appropriées pour le modèle de langage suivant, comme suit : 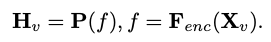
De cette façon, nous obtenons les jetons de l'image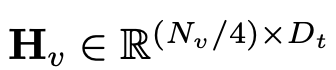 et les jetons du texte
et les jetons du texte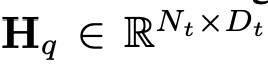 , où N_t représente le texte Le nombre de jetons, D_t représente la taille de l'espace d'intégration du mot. Dans le paradigme de conception MLLM actuel, LLM nécessite la plus grande quantité de calculs et de consommation de mémoire. Compte tenu de cela, cet article adapte une série de LLM faciles à inférence pour les applications mobiles, qui présentent des avantages considérables en termes de vitesse et peuvent exécuter des méthodes de prédiction autorégressives. entrée multimodale
, où N_t représente le texte Le nombre de jetons, D_t représente la taille de l'espace d'intégration du mot. Dans le paradigme de conception MLLM actuel, LLM nécessite la plus grande quantité de calculs et de consommation de mémoire. Compte tenu de cela, cet article adapte une série de LLM faciles à inférence pour les applications mobiles, qui présentent des avantages considérables en termes de vitesse et peuvent exécuter des méthodes de prédiction autorégressives. entrée multimodale 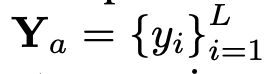 , où L représente la longueur des jetons de sortie. Ce processus peut être exprimé par
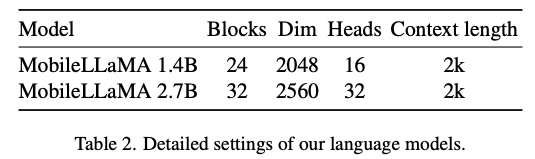
, où L représente la longueur des jetons de sortie. Ce processus peut être exprimé par 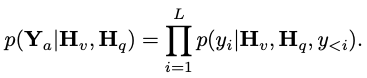 . Selon l'analyse empirique de la section 5.1 de l'article original, le chercheur a utilisé le CLIP ViT-L/14 pré-entraîné avec une résolution de 336 × 336 comme l'encodeur visuel F_enc . Le Visual Transformer (ViT) divise l'image en blocs d'image de taille uniforme et effectue une intégration linéaire sur chaque bloc d'image. Après intégration ultérieure avec le codage positionnel, la séquence vectorielle résultante est introduite dans le codeur de transformation régulier. Généralement, les jetons utilisés pour la classification seront ajoutés à la séquence pour les tâches de classification ultérieures. Pour le modèle de langage, cet article réduit la taille de LLaMA pour faciliter le déploiement, c'est-à-dire que le modèle proposé dans cet article peut prendre en charge de manière transparente presque tous les cadres d'inférence populaires. En outre, les chercheurs ont également évalué la latence du modèle sur les appareils de pointe afin de sélectionner une architecture de modèle appropriée. La recherche d'architecture neuronale (NAS) est un bon choix, mais les chercheurs ne l'ont pas encore appliqué immédiatement aux modèles actuels. Le tableau 2 montre les paramètres détaillés de l’architecture de cet article. Plus précisément, cet article utilise le tokenizer de morceaux de phrase dans LLaMA2 avec une taille de vocabulaire de 32 000 et entraîne la couche d'intégration à partir de zéro. Cela facilitera la distillation ultérieure. En raison de ressources limitées, la longueur du contexte utilisée par tous les modèles lors de la phase de pré-formation est de 2 000 k. Cependant, comme décrit dans « Extension de la fenêtre contextuelle de grands modèles de langage via une interpolation positionnelle », la fenêtre contextuelle pendant l'inférence peut être étendue jusqu'à 8 Ko. Les paramètres détaillés pour les autres composants sont les suivants.
. Selon l'analyse empirique de la section 5.1 de l'article original, le chercheur a utilisé le CLIP ViT-L/14 pré-entraîné avec une résolution de 336 × 336 comme l'encodeur visuel F_enc . Le Visual Transformer (ViT) divise l'image en blocs d'image de taille uniforme et effectue une intégration linéaire sur chaque bloc d'image. Après intégration ultérieure avec le codage positionnel, la séquence vectorielle résultante est introduite dans le codeur de transformation régulier. Généralement, les jetons utilisés pour la classification seront ajoutés à la séquence pour les tâches de classification ultérieures. Pour le modèle de langage, cet article réduit la taille de LLaMA pour faciliter le déploiement, c'est-à-dire que le modèle proposé dans cet article peut prendre en charge de manière transparente presque tous les cadres d'inférence populaires. En outre, les chercheurs ont également évalué la latence du modèle sur les appareils de pointe afin de sélectionner une architecture de modèle appropriée. La recherche d'architecture neuronale (NAS) est un bon choix, mais les chercheurs ne l'ont pas encore appliqué immédiatement aux modèles actuels. Le tableau 2 montre les paramètres détaillés de l’architecture de cet article. Plus précisément, cet article utilise le tokenizer de morceaux de phrase dans LLaMA2 avec une taille de vocabulaire de 32 000 et entraîne la couche d'intégration à partir de zéro. Cela facilitera la distillation ultérieure. En raison de ressources limitées, la longueur du contexte utilisée par tous les modèles lors de la phase de pré-formation est de 2 000 k. Cependant, comme décrit dans « Extension de la fenêtre contextuelle de grands modèles de langage via une interpolation positionnelle », la fenêtre contextuelle pendant l'inférence peut être étendue jusqu'à 8 Ko. Les paramètres détaillés pour les autres composants sont les suivants.
- Appliquez RoPE pour injecter des informations de localisation.
- Appliquer une pré-normalisation pour stabiliser l'entraînement. Plus précisément, cet article utilise RMSNorm au lieu de la normalisation des couches, et le taux d'expansion MLP utilise 8/3 au lieu de 4.
- Utilisez la fonction d'activation SwiGLU au lieu de GELU.
Réseau de cartographie efficaceLe réseau de cartographie entre l'encodeur visuel et le modèle de langage est crucial pour l'alignement des fonctionnalités multimodales. Il existe deux modes existants : Q-Former et projection MLP. Q-Former contrôle explicitement le nombre de jetons visuels inclus dans chaque requête pour forcer l'extraction des informations visuelles les plus pertinentes. Cependant, cette méthode perd inévitablement les informations de localisation spatiale des jetons et a une vitesse de convergence lente. De plus, il n’est pas efficace pour l’inférence sur les appareils de périphérie. En revanche, MLP préserve les informations spatiales mais contient souvent des éléments inutiles tels que l'arrière-plan. Pour une image avec une taille de patch de P, N_v = HW/P^2 jetons visuels doivent être injectés dans le LLM, ce qui réduit considérablement la vitesse d'inférence globale. Inspirés par l'algorithme de codage de position conditionnel CPVT de ViT, les chercheurs utilisent des convolutions pour améliorer les informations de position et encourager les interactions locales des encodeurs visuels. Plus précisément, nous avons étudié les opérations adaptées aux mobiles basées sur des convolutions profondes (la forme la plus simple de PEG) qui sont à la fois efficaces et bien prises en charge par une variété d'appareils de pointe. Afin de préserver les informations spatiales et de minimiser les coûts de calcul, cet article utilise la convolution avec une foulée de 2, réduisant ainsi le nombre de jetons visuels de 75%. Cette conception améliore considérablement la vitesse d'inférence globale. Cependant, les résultats expérimentaux montrent que la réduction du nombre d’échantillons de jetons réduira considérablement les performances des tâches en aval telles que l’OCR. Pour atténuer cet effet, les chercheurs ont conçu un réseau plus puissant pour remplacer un seul PEG. L'architecture détaillée d'un réseau de cartographie efficace, appelé Lightweight Downsampling Mapping (LDP), est présentée à la figure 2. Notamment, ce réseau cartographique contient moins de 20 millions de paramètres et fonctionne environ 81 fois plus rapidement que l'encodeur visuel. 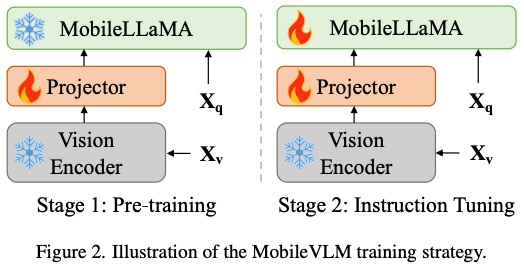
Cet article utilise la "normalisation des couches" au lieu de la "normalisation des lots" afin que l'entraînement ne soit pas affecté par la taille du lot. Formellement, LDP (noté P) prend en entrée une intégration visuelle 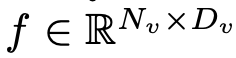 et génère un jeton visuel efficacement extrait et aligné
et génère un jeton visuel efficacement extrait et aligné 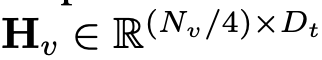 . La formule est la suivante :
. La formule est la suivante : 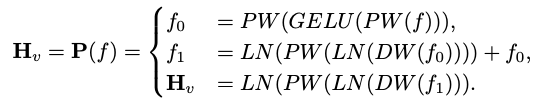
Résultats de l'évaluation MobileLLaMADans le tableau 3, les chercheurs l'article a été révisé sur le benchmark du langage naturel Le modèle proposé a été évalué de manière approfondie sur deux critères ciblant respectivement la compréhension du langage et le raisonnement de bon sens. Dans l’évaluation du premier, cet article utilise le harnais d’évaluation du modèle linguistique. Les résultats expérimentaux montrent que MobileLLaMA 1.4B est à égalité avec les derniers modèles open source tels que TinyLLaMA 1.1B, Galactica 1.3B, OPT 1.3B et Pythia 1.4B. Il convient de noter que MobileLLaMA 1.4B surpasse TinyLLaMA 1.1B, qui est formé sur des jetons de niveau 2T et est deux fois plus rapide que MobileLLaMA 1.4B. Au niveau 3B, MobileLLaMA 2.7B affiche également des performances comparables à INCITE 3B (V1) et OpenLLaMA 3B (V1), comme le montre le tableau 5. Sur le processeur Snapdragon 888, MobileLLaMA 2.7B est environ 40 % plus rapide qu'OpenLLaMA 3B. 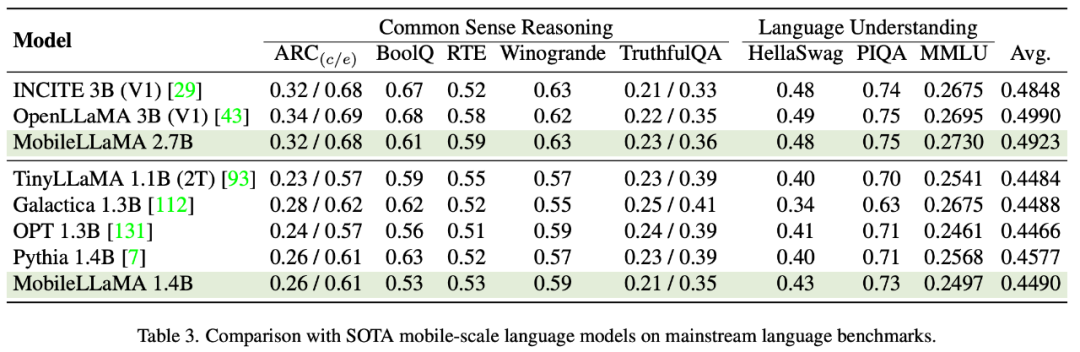
Comparaison avec SOTA VLMCet article évalue les performances multimodales de LLaVA sur GQA, ScienceQA, TextVQA, POPE et MME. De plus, cet article effectue également une comparaison complète à l'aide de MMBench. Comme le montre le tableau 4, MobileVLM atteint des performances compétitives malgré des paramètres réduits et des données de formation limitées. Dans certains cas, ses métriques surpassent même les précédents modèles de langage visuel multimodal de pointe. 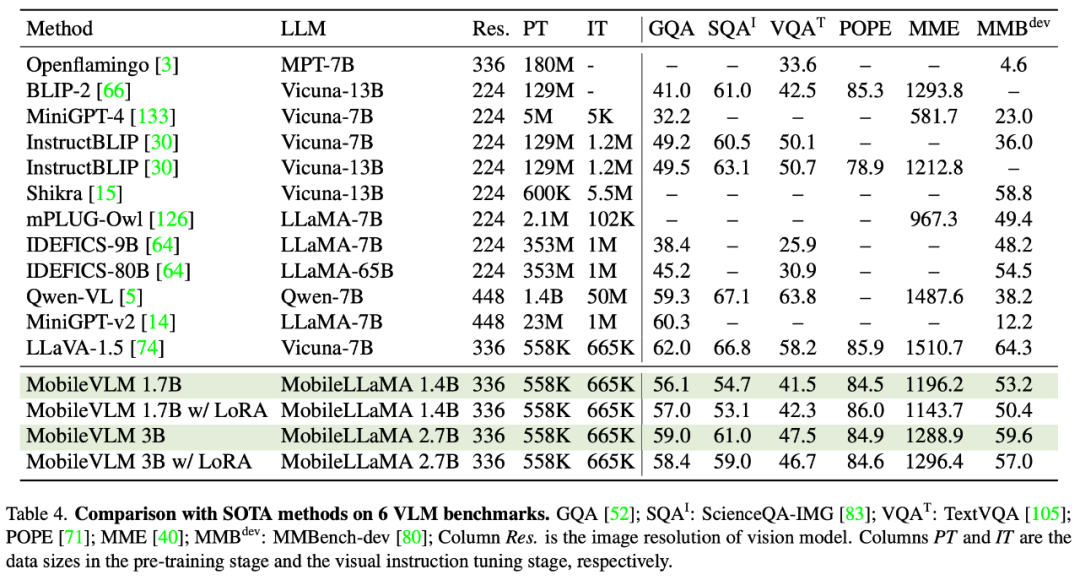
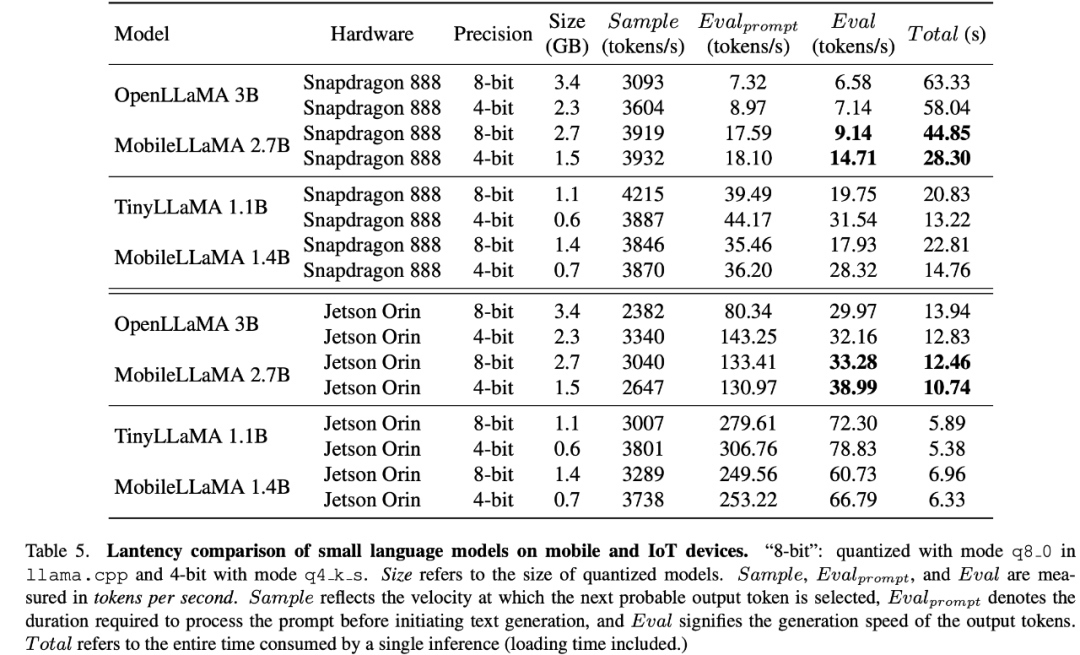
L'adaptation de bas rang (LoRA) peut atteindre des performances identiques, voire meilleures, qu'un LLM entièrement réglé avec moins de paramètres pouvant être entraînés. Cet article mène une étude empirique de cette pratique pour valider sa performance multimodale. Plus précisément, pendant la phase d'ajustement des instructions visuelles VLM, cet article gèle tous les paramètres LLM à l'exception de la matrice LoRA. Dans MobileLLaMA 1.4B et MobileLLaMA 2.7B, les paramètres mis à jour ne représentent respectivement que 8,87 % et 7,41 % du LLM complet. Pour LoRA, cet article définit lora_r sur 128 et lora_α sur 256. Les résultats sont présentés dans le tableau 4. On peut voir que sur 6 benchmarks, MobileVLM avec LoRA atteint des performances comparables à un réglage fin complet, ce qui est cohérent avec les résultats de LoRA. Test de latence sur les appareils mobilesLes chercheurs ont évalué la latence d'inférence de MobileLLaMA et MobileVLM sur les téléphones mobiles Realme GT et la plateforme NVIDIA Jetson AGX Orin. Le téléphone est alimenté par un SoC Snapdragon 888 et 8 Go de RAM, qui offrent 26 TOPS de puissance de calcul. Orin est livré avec 32 Go de mémoire et offre une étonnante puissance de calcul de 275 TOPS. Il utilise la version CUDA 11.4 et prend en charge la dernière technologie de calcul parallèle pour des performances améliorées. Dans le tableau 7, les chercheurs ont comparé les performances multimodales à différentes échelles et différents nombres de jetons visuels. Toutes les expériences ont utilisé CLIP ViT comme encodeur visuel. 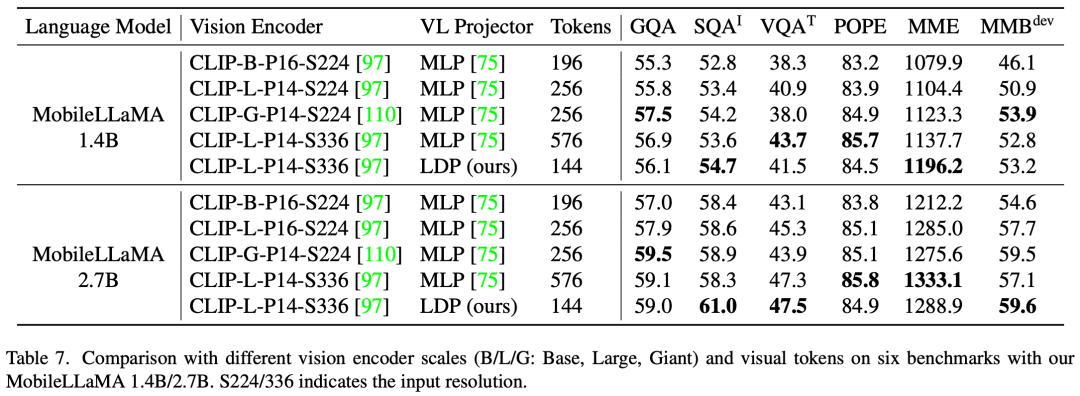
Réseau de cartographie VLÉtant donné que l'interaction des fonctionnalités et l'interaction des jetons sont bénéfiques, les chercheurs ont utilisé la convolution en profondeur pour la première et la convolution ponctuelle pour la seconde. Le tableau 9 montre les performances de divers réseaux cartographiés VL. La ligne 1 du tableau 9 est le module utilisé dans LLaVA, qui transforme uniquement l'espace des fonctionnalités à travers deux couches linéaires. La ligne 2 ajoute une convolution DW (en profondeur) avant chaque PW (par point) pour l'interaction des jetons, qui utilise un sous-échantillonnage 2x avec une foulée de 2. L'ajout de deux couches PW frontales apportera davantage d'interactions au niveau des fonctionnalités, compensant ainsi la perte de performances causée par la réduction des jetons. Les lignes 4 et 5 montrent que l’ajout de paramètres supplémentaires ne permet pas d’obtenir l’effet souhaité. Les lignes 4 et 6 montrent que le sous-échantillonnage des jetons à la fin du réseau cartographique a un effet positif. 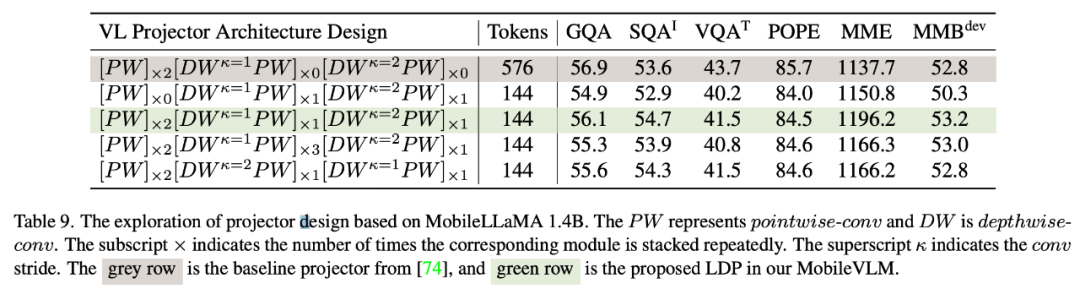
Résolution visuelle et nombre de jetonsÉtant donné que le nombre de jetons visuels affecte directement la vitesse d'inférence de l'ensemble du modèle multimodal, cet article compare deux options de conception : réduire la résolution d'entrée (RIR ) et en utilisant un projecteur à sous-échantillonnage léger (LDP). L'analyse quantitative de SFT
Vicuna affinée sur LLaMA est largement utilisée pour les grands modèles multimodaux. Le tableau 10 compare deux paradigmes SFT courants, Alpaca et Vicuna. Les chercheurs ont constaté que les scores SQA, VQA, MME et MMBench se sont tous considérablement améliorés. Cela montre que le réglage fin de grands modèles de langage à l'aide des données de ShareGPT en mode conversationnel Vicuna donne finalement les meilleures performances. Afin de mieux intégrer le format d'invite de SFT à la formation des tâches en aval, cet article supprime le mode conversation sur MobileVLM et constate que vicunav1 est le plus performant. 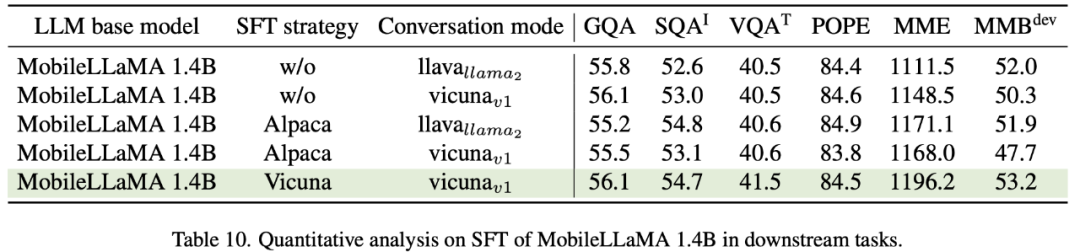
En bref, MobileVLM est un ensemble de modèles de langage visuel mobile efficaces et puissants personnalisés pour les appareils mobiles et IoT. Cet article réinitialise le modèle de langage et le réseau de cartographie visuelle. Les chercheurs ont mené des expériences approfondies pour sélectionner un réseau fédérateur visuel approprié, concevoir un réseau de cartographie efficace et améliorer les capacités du modèle grâce à des solutions de formation telles que le modèle de langage SFT (une stratégie de formation en deux étapes comprenant une pré-formation et un ajustement des instructions) et LoRA fine- réglage. Les chercheurs ont rigoureusement évalué les performances de MobileVLM sur les benchmarks VLM traditionnels. MobileVLM affiche également des vitesses sans précédent sur les appareils mobiles et IoT typiques. Les chercheurs pensent que MobileVLM ouvrira de nouvelles possibilités pour un large éventail d'applications telles que les assistants multimodaux déployés sur des appareils mobiles ou des véhicules autonomes, ainsi que des robots à intelligence artificielle plus larges. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

