
Maison >Tutoriel système >Linux >Méthodes d'amélioration des performances du serveur Web
Méthodes d'amélioration des performances du serveur Web

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-07 18:10:321314parcourir
| Présentation | Avec le développement continu d'Internet, de plus en plus de besoins dans la vie quotidienne sont satisfaits grâce à Internet. De la nourriture, des vêtements, du logement et des transports à l'éducation financière, des poches à l'identité, les gens dépendent constamment d'Internet et de plus en plus de personnes utilisent Internet pour répondre à leurs propres besoins. |
En tant que serveur Web confronté directement aux demandes des clients, il devra sans aucun doute résister à plus de demandes en même temps et offrir aux utilisateurs une meilleure expérience. À l'heure actuelle, les performances du côté Web deviennent souvent un goulot d'étranglement pour le développement commercial et il est urgent d'améliorer les performances. L'auteur de cet article a résumé quelques expériences d'amélioration des performances du serveur Web pendant le processus de développement et les a partagées avec tout le monde.
Analyse des problèmesPour les performances du serveur Web, nous analysons d'abord les indicateurs pertinents. Du point de vue de l'utilisateur, lorsqu'un utilisateur appelle un service Web, plus le temps de retour de la requête est court, meilleure est l'expérience utilisateur. Du point de vue du serveur, plus le nombre de requêtes utilisateur pouvant être traitées simultanément est élevé, plus les performances du serveur seront élevées. En combinant les deux aspects, nous résumons les deux directions de l'optimisation des performances :
1. Augmentez le nombre maximum de requêtes simultanées que le serveur peut prendre en charge
;2. Améliorer la vitesse de traitement de chaque demande.
La direction de l'optimisation est clarifiée. Tout d'abord, nous introduisons un modèle architectural commun côté serveur, c'est-à-dire qu'une requête Web provenant d'un navigateur ou d'une application est traitée et renvoyée via plusieurs couches de structures côté serveur.
Mode Architecture : équilibrage de charge IP->serveur de cache->proxy inverse->serveur d'applications->base de données
Comme le montre la figure 1, pour faciliter l'explication, donnons un exemple pratique : LVS(Keepalived)->Squid->nginx->Go->MySQL
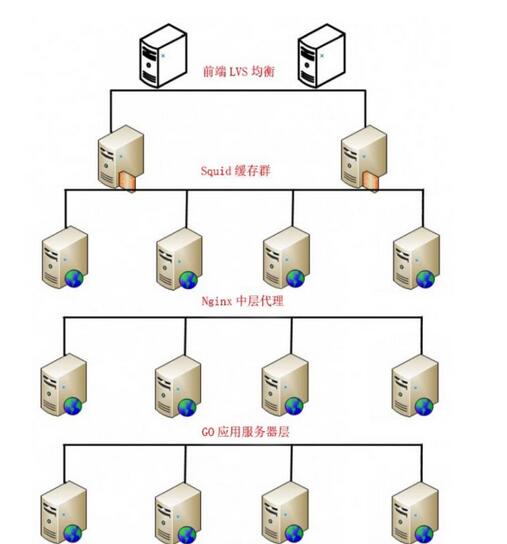
Figure 1 : Architecture côté serveur
Nous distribuons les requêtes à chaque couche, afin que plusieurs branches de la structure de niveau inférieur puissent travailler en même temps pour augmenter le nombre maximum global de simultanéités.
En combinaison avec l'architecture, nous analyserons les problèmes qui entravent habituellement les performances et trouverons les solutions correspondantes.
Dans des circonstances normales, les couches d'équilibrage de charge IP, de serveur de cache et de proxy nginx sont principalement des problèmes de stabilité du cluster. Les endroits où les goulots d'étranglement des performances sont susceptibles de se produire sont souvent la couche du serveur d'applications et la couche de base de données. Énumérons quelques exemples ci-dessous :
. 1. Impact de l'obstruction(1) Question :
La plupart des requêtes Web sont de nature bloquante. Lorsqu'une requête est traitée, le processus est suspendu (occupant le processeur) jusqu'à ce que la requête soit terminée. Dans la plupart des cas, les requêtes Web se terminent suffisamment rapidement pour que ce problème ne soit pas un problème. Cependant, pour les requêtes qui prennent beaucoup de temps à se terminer (comme les requêtes qui renvoient de grandes quantités de données ou des API externes), cela signifie que l'application est verrouillée jusqu'à la fin du traitement. Pendant cette période, les autres requêtes ne seront pas traitées. et il est évident que celles-ci ne sont pas valides. Le temps d'attente est gaspillé et les ressources du système sont occupées, ce qui affecte sérieusement le nombre de requêtes simultanées que nous pouvons nous permettre.
(2) Solution :
Pendant que le serveur Web attend que la requête précédente soit traitée, nous pouvons laisser la boucle d'E/S ouverte pour traiter d'autres requêtes d'application jusqu'à ce que le traitement soit terminé, démarrer une requête et donner un retour, au lieu de nous suspendre en attendant la requête. à terminer. Démarrez le processus. De cette façon, nous pouvons économiser du temps d'attente inutile et utiliser ce temps pour traiter davantage de requêtes, de sorte que nous puissions augmenter considérablement le débit des requêtes, ce qui signifie augmenter de manière macroscopique le nombre de requêtes simultanées que nous pouvons traiter.
(3) Exemple
Ici, nous utilisons Tornado, un framework Web Python, pour expliquer spécifiquement comment modifier la méthode de blocage afin d'améliorer les performances de concurrence.
Scénario : Nous construisons une application Web simple qui envoie des requêtes HTTP à l'extrémité distante (un site Web très stable). Pendant cette période, la transmission du réseau est stable et nous ne prenons pas en compte l'impact du réseau.
Dans cet exemple, nous utilisons Siege (un logiciel de test de stress) pour effectuer environ 10 requêtes simultanées au serveur en 10 secondes.
Comme le montre la figure 2, nous pouvons facilement voir que le problème ici est que, quelle que soit la rapidité avec laquelle chaque requête elle-même est renvoyée, la demande d'accès aller-retour du serveur à l'extrémité distante produira un décalage suffisamment important, car le processus n'attend pas. jusqu'à ce que la demande soit terminée et que les données soient toujours en état de suspension forcée avant le traitement. Ce n'est pas encore un problème avec une ou deux requêtes, mais lorsqu'on arrive à 100 (voire 10) utilisateurs cela signifie un ralentissement global. Comme le montre la figure, le temps de réponse moyen de 10 utilisateurs similaires en moins de 10 secondes a atteint 1,99 seconde, soit un total de 29 fois. Cet exemple ne montre qu'une logique très simple. Si vous ajoutez d'autres appels de logique métier ou de base de données, les résultats seront encore pires. Lorsque davantage de demandes d'utilisateurs sont ajoutées, le nombre de demandes pouvant être traitées en même temps augmentera lentement et certaines demandes peuvent même expirer ou échouer.
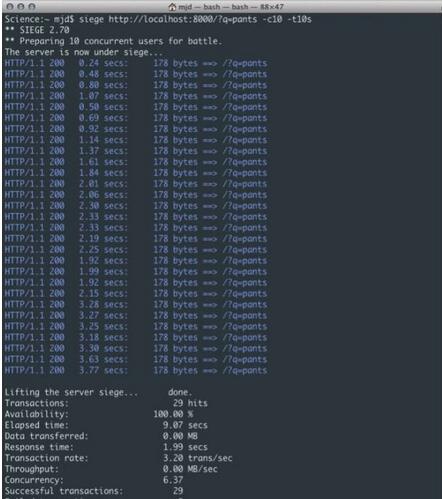
Figure 2 : Réponse de blocage
Ci-dessous, nous utilisons Tornado pour effectuer des requêtes HTTP non bloquantes.
Comme le montre la figure 3, nous sommes passés de 3,20 transactions par seconde à 12,59, traitant un total de 118 requêtes dans le même laps de temps. C'est vraiment une grande amélioration ! Comme vous pouvez l'imaginer, à mesure que les demandes des utilisateurs augmentent et que les temps de test augmentent, il sera en mesure de desservir davantage de connexions sans subir les ralentissements subis par la version ci-dessus. Cela augmente régulièrement le nombre de requêtes simultanées pouvant être chargées.
Pratique d'amélioration des performances du serveur Web
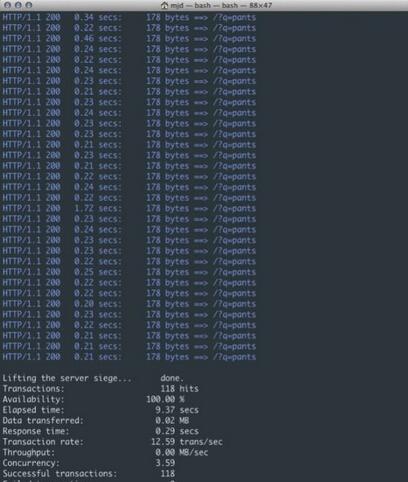
Figure 3 : Réponse non bloquante
2. L'impact de l'efficacité informatique sur le temps de réponse et le nombre de simultanéitésTout d’abord, introduisons les connaissances de base : une application est un processus exécuté sur la machine ; un processus est un corps d’exécution indépendant s’exécutant dans son propre espace d’adressage mémoire. Un processus se compose d'un ou plusieurs threads du système d'exploitation. Ces threads sont en fait des organes d'exécution qui travaillent ensemble et partagent le même espace d'adressage mémoire.
(1) Question
La méthode informatique traditionnelle s'exécute sur un seul thread, qui a une faible efficacité et une faible puissance de calcul.
(2) Solution
Une solution consiste à éviter complètement d’utiliser des threads. Par exemple, vous pouvez utiliser plusieurs processus pour décharger le système d'exploitation de la charge. Cependant, un inconvénient est que nous devons gérer toutes les communications inter-processus, ce qui entraîne généralement plus de frais généraux que le modèle de concurrence de mémoire partagée.
Une autre façon consiste à utiliser le multi-threading pour fonctionner. Cependant, il est reconnu que les applications utilisant le multi-threading sont difficiles à réaliser une synchronisation précise des différents threads et à verrouiller les données afin qu'un seul thread puisse modifier les données en même temps. Cependant, l'expérience passée en matière de développement de logiciels nous indique que cela entraînera une plus grande complexité, un code plus sujet aux erreurs et des performances moindres.
Le principal problème est le partage des données en mémoire, qui seront exploitées de manière imprévisible par plusieurs threads, conduisant à des résultats irréproductibles ou aléatoires (appelés « conditions de concurrence »). Cette approche classique n’est donc clairement plus adaptée à la programmation multicœur/multiprocesseur moderne : le modèle thread par connexion n’est pas assez efficace. Parmi les nombreux paradigmes appropriés, il en existe un appelé Communicating Sequential Processes (CSP, inventé par C. Hoare) et un autre appelé message-passing-model (déjà utilisé dans d'autres langages, comme Erlang).
La méthode que nous utilisons ici consiste à utiliser une architecture parallèle pour traiter les tâches. Un programme simultané peut utiliser plusieurs threads sur un processeur ou un cœur pour effectuer des tâches, mais seul le même programme peut s'exécuter sur plusieurs cœurs ou multiprocesseurs à un moment donné. dans le temps. Le vrai parallélisme est sur le processeur.
Le parallélisme est la capacité d'augmenter la vitesse en utilisant plusieurs processeurs. Les programmes concurrents peuvent donc être parallèles ou non.
Le mode parallèle peut utiliser plusieurs threads, multicœurs, multiprocesseurs et même plusieurs ordinateurs en même temps. Cela peut sans aucun doute mobiliser plus de ressources, compressant ainsi le temps de réponse, améliorant l'efficacité informatique et améliorant considérablement les performances du serveur. .
(3) Exemple
Voici une explication détaillée utilisant Goroutine dans le langage Go.
Dans le langage Go, la partie traitement simultané de l'application est appelée goroutines (coroutines), qui peuvent effectuer des opérations simultanées plus efficaces. Il n'y a pas de relation biunivoque entre les coroutines et les threads du système d'exploitation : les coroutines sont mappées (multiplexées, exécutées sur) un ou plusieurs threads en fonction de leur disponibilité ; le planificateur de coroutines. Le runtime Go fait très bien ce travail. Les coroutines sont légères, plus légères que les threads. Ils sont très discrets (et utilisent une petite quantité de mémoire et de ressources) : ils peuvent être créés dans le tas en utilisant seulement 4 Ko de mémoire de pile. Comme sa création est très peu coûteuse, il est facile de créer et d'exécuter un grand nombre de coroutines (100 000 coroutines consécutives dans le même espace d'adressage) si nécessaire. Et ils divisent la pile pour augmenter (ou réduire) dynamiquement l'utilisation de la mémoire ; la gestion de la pile est automatique, mais non gérée par le garbage collector, mais automatiquement libérée après la sortie de la coroutine. Les coroutines peuvent s'exécuter entre plusieurs threads du système d'exploitation ou au sein de threads, vous permettant de traiter un grand nombre de tâches avec une faible empreinte mémoire. Grâce au découpage du temps de coroutine sur les threads du système d'exploitation, vous pouvez avoir autant de coroutines de service que vous le souhaitez en utilisant un petit nombre de threads du système d'exploitation, et le runtime Go peut déterminer intelligemment quelles coroutines sont bloquées, les mettre en attente et en gérer d'autres. coroutines. Même les programmes peuvent exécuter différents segments de code simultanément sur différents processeurs et ordinateurs.
Nous souhaitons généralement diviser un long processus de calcul en plusieurs parties, puis laisser chaque goroutine être responsable d'une partie du travail, afin que le temps de réponse pour une seule demande puisse être doublé.
Par exemple, il existe une tâche divisée en 3 étapes. L'étape a va à la base de données a pour récupérer les données, l'étape b va à la base de données b pour récupérer les données, et l'étape c fusionne les données et les renvoie. Après avoir démarré la goroutine, les phases a et b peuvent être exécutées ensemble, ce qui réduit considérablement le temps de réponse.
Pour parler franchement, une partie du processus de calcul est convertie de série en parallèle. Une tâche n'a pas besoin d'attendre que d'autres tâches non liées terminent son exécution. L'exécution parallèle du programme sera plus utile dans les calculs réels.
Je n’entrerai pas ici dans les détails de cette partie des données complémentaires. Les étudiants intéressés peuvent consulter ces informations par eux-mêmes. Par exemple, la vieille histoire de l'amélioration des performances de 15 fois lorsque le serveur Web est passé de Ruby à Go (Ruby utilise des threads verts, c'est-à-dire qu'un seul processeur est utilisé). Même si cette histoire peut paraître un peu exagérée, les gains de performances apportés par le parallélisme ne font aucun doute. (Ruby passe à Go : http://www.vaikan.com/how-we-went-from-30-servers-to-2-go/).
3. Impact des E/S disque sur les performances(1) Question
La lecture des données à partir d'un disque repose sur un mouvement mécanique. Le temps passé à chaque lecture de données peut être divisé en trois parties : le temps de recherche, le délai de rotation et le temps de transmission. le temps spécifié, les disques grand public sont généralement inférieurs à 5 ms ; le délai de rotation est la vitesse du disque que nous entendons souvent. Par exemple, un disque avec 7 200 tr/min signifie qu'il peut tourner 7 200 fois par minute, ce qui signifie qu'il peut tourner 120 fois par seconde. et le délai de rotation est de 1/120/2 = 4,17 ms ; le temps de transmission fait référence au temps nécessaire pour lire sur le disque ou écrire des données sur le disque, généralement quelques dixièmes de milliseconde, ce qui est négligeable par rapport aux deux premières fois. Ensuite, le temps d'accès à un disque, c'est-à-dire le temps d'accès à une E/S de disque, est d'environ 9 ms (5 ms + 4,17 ms), ce qui semble plutôt bien, mais il faut savoir qu'une machine à 500 MIPS peut exécuter 500 millions d'éléments. par seconde. Instructions, car les instructions dépendent de la nature de l'électricité, autrement dit, il faut 400 000 instructions pour exécuter une E/S. La base de données contient souvent des centaines de milliers, des millions, voire des dizaines de millions de données, et à chaque fois. prend 9 millisecondes, c'est évidemment une catastrophe.
(2) Solution
Il n'existe pas de solution fondamentale à l'impact des E/S disque sur les performances du serveur, à moins que vous ne jetiez le disque et ne le remplaciez par autre chose. Nous pouvons rechercher en ligne la vitesse de réponse et le prix de divers supports de stockage. Si vous avez de l'argent, vous pouvez changer de support de stockage à volonté.
Sans changer le support de stockage, nous pouvons réduire le nombre d'accès au disque par l'application, comme la configuration du cache, et nous pouvons également placer certaines E/S disque en dehors du cycle de requête, comme l'utilisation de files d'attente et de piles pour traiter les données. /O.
4. Optimiser la requête de base de donnéesAvec l'évolution des modèles de développement commercial, le développement agile est adopté par de plus en plus d'équipes, et le cycle est de plus en plus court. De nombreuses instructions de requête de base de données sont écrites selon la logique métier. Au fil du temps, le format des requêtes SQL est souvent ignoré. . problème, provoquant une pression accrue sur la base de données et ralentissant la réponse aux requêtes de la base de données. Voici une brève introduction à plusieurs problèmes courants et méthodes d'optimisation que nous avons ignorés dans la base de données MySQL :
Le principe de correspondance des préfixes les plus à gauche est un principe très important. MySQL continuera à correspondre vers la droite jusqu'à ce qu'il rencontre une requête de plage (>, 3 et d = 4 Si vous créez un index dans l'ordre de (a, b, c, d), l'index de d ne sera pas utilisé. Si vous créez un index de (a, b, d, c), vous pouvez utiliser à la fois a et b , l'ordre de d peut être ajusté arbitrairement.
Essayez de choisir des colonnes avec une distinction élevée comme index. La formule de distinction est count(distinct col)/count(*), qui représente la proportion de champs qui ne sont pas répétés. Plus le ratio est grand, moins nous analysons d'enregistrements. de clés uniques est 1. Certains champs de statut et de genre peuvent avoir une distinction de 0 face au Big Data. Alors quelqu'un peut se demander : ce ratio a-t-il une valeur empirique ? Différents scénarios d'utilisation rendent cette valeur difficile à déterminer. Généralement, nous exigeons que les champs qui doivent être joints soient supérieurs à 0,1, c'est-à-dire qu'une moyenne de 10 enregistrements seront analysés pour chacun.
Essayez d'utiliser des champs numériques. Si les champs contiennent uniquement des informations numériques, essayez de ne pas les concevoir comme des champs de caractères. Cela réduirait les performances des requêtes et des connexions et augmenterait la surcharge de stockage. En effet, le moteur comparera chaque caractère de la chaîne un par un lors du traitement des requêtes et des connexions, et une seule comparaison suffit pour les types numériques.
Les colonnes d'index ne peuvent pas participer aux calculs. Gardez les colonnes "propres". Par exemple, si from_unixtime(create_time) = '2014-05-29', l'index ne peut pas être utilisé. La raison est très simple. dans le tableau de données, mais lors de la récupération, vous devez appliquer des fonctions à tous les éléments à comparer, ce qui est évidemment trop coûteux. Par conséquent, l'instruction doit être écrite sous la forme create_time = unix_timestamp('2014-05-29'); Essayez d'éviter un jugement de valeur nul sur les champs de la clause Where, sinon le moteur renoncera à l'utiliser.
Effectuez une analyse complète de la table à l'aide de l'index, par exemple :
sélectionnez l'identifiant à partir de t où num est nul
Vous pouvez définir la valeur par défaut 0 sur num, vous assurer qu'il n'y a pas de valeur nulle dans la colonne num du tableau, puis interroger comme ceci :
sélectionnez l'identifiant à partir de t où num=0
Essayez d'éviter d'utiliser ou dans la clause Where pour lier les conditions, sinon le moteur abandonnera l'utilisation de l'index et effectuera une analyse complète de la table, telle que :
sélectionnez l'identifiant à partir de t où num=10 ou num=20
Vous pouvez interroger comme ceci :
sélectionnez l'identifiant à partir de t où num=10 union tous sélectionnez l'identifiant à partir de t où num=20
La requête suivante entraînera également une analyse complète de la table (sans signe de pourcentage en tête) :
sélectionnez l'identifiant à partir de t où le nom est comme '%abc%'
Pour améliorer l’efficacité, envisagez la recherche en texte intégral.
In et not in doivent également être utilisés avec prudence, sinon cela entraînera une analyse complète de la table, telle que :
sélectionnez l'identifiant à partir de t où num in(1,2,3)
Pour les valeurs continues, n’utilisez pas in si vous pouvez utiliser entre :
sélectionnez l'identifiant à partir de t où num entre 1 et 3
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est la commande d'arrêt du système Linux ?
- Quelle est la commande Linux pour supprimer un utilisateur
- Collection de commandes Linux : comprendre la charge du système (organisée et partagée)
- Comment changer l'adresse IP sous Linux
- Comment filtrer et classer les journaux via les outils de ligne de commande Linux ?