
Maison >Tutoriel système >Linux >Apprenez à utiliser les variables intégrées AWK sous Linux
Apprenez à utiliser les variables intégrées AWK sous Linux

- PHPzavant
- 2024-01-06 16:22:06610parcourir
| Présentation | Nous démystifierons progressivement les fonctions de awk. Dans cette section, nous présenterons le concept de variables intégrées dans awk. Il existe deux types de variables que vous pouvez utiliser dans awk : les variables définies par l'utilisateur et les variables intégrées. |

Nous démystifierons progressivement les capacités d'awk. Dans cette section, nous présenterons le concept des variables intégrées d'awk. Il existe deux types de variables que vous pouvez utiliser dans awk : les variables définies par l'utilisateur et les variables intégrées. Les variables intégrées d'awk ont déjà des valeurs prédéfinies, mais nous pouvons également modifier ces valeurs avec précaution.
Les variables intégrées awk incluent :- FILENAME : nom du fichier d'entrée actuel
- NR : Numéro de ligne d'entrée actuel (faisant référence à la ligne d'entrée 1, 2, 3...etc.)
- NF : Numéro de champ de la ligne de saisie actuelle
- OFS : séparateur de champ de sortie
- FS : séparateur de champ de saisie
- ORS : Séparateur d'enregistrements de sortie
- RS : séparateur d'enregistrement d'entrée
Continuons à démontrer quelques méthodes d'utilisation des variables intégrées awk ci-dessus. Pour lire le nom du fichier d'entrée actuel, vous pouvez utiliser la variable intégrée FILENAME, comme suit : $ awk '{ print FILENAME } '. ~/domains.txt
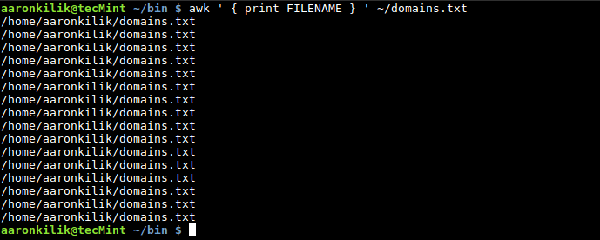
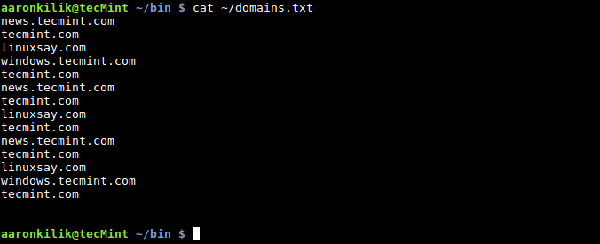
Vous verrez que chaque ligne affichera le nom du fichier une fois, ce qui est le comportement par défaut de awk lorsque vous utilisez la variable intégrée FILENAME. Nous pouvons utiliser NR pour compter le nombre de lignes (enregistrements) dans un fichier d'entrée, rappelez-vous : il comptera également les lignes vides, comme nous le verrons dans l'exemple suivant. Contenu du fichier de sortie Lorsque nous utilisons la commande cat pour afficher le fichier domains.txt, nous constaterons qu'il contient 14 lignes de texte et 2 lignes vides : $ cat ~/domains.txt
$ awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt

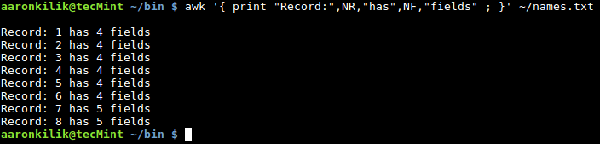
$ awk '{ "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
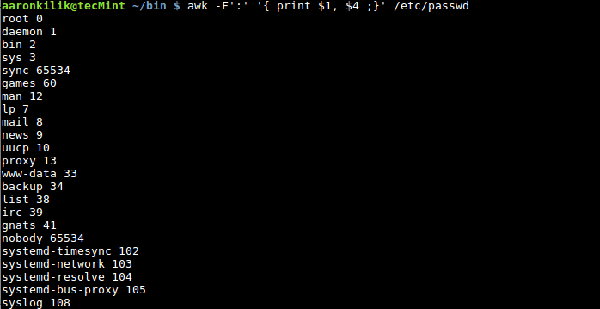
Vous pouvez également spécifier un délimiteur de fichier d'entrée à l'aide de la variable intégrée FS, qui définit comment awk divise les lignes d'entrée en champs. La valeur par défaut de FS est "espace" et "tabulation", mais nous pouvons également modifier la valeur FS en n'importe quel caractère pour permettre à awk de diviser la ligne d'entrée en fonction de la situation. Il existe deux manières d'y parvenir : la première consiste à utiliser les variables intégrées de FS ; la seconde consiste à utiliser l'option -F de awk. Regardons le fichier /etc/passwd sur le système Linux. Chaque champ du fichier est séparé par deux points (:). Par conséquent, lorsque nous voulons filtrer certains champs, nous pouvons spécifier les deux points (:) comme nouveau. séparateur de champs, et awk filtre chaque champ du fichier de mot de passe. Nous pouvons utiliser l'option -F, comme suit : $ awk -F':' '{ print $1, $4 ;}' /etc/passwd
.
De plus, nous pouvons également utiliser les variables intégrées de FS, comme suit : $ awk ' BEGIN { FS=":" } { print $1, $4 } ' /etc/passwd
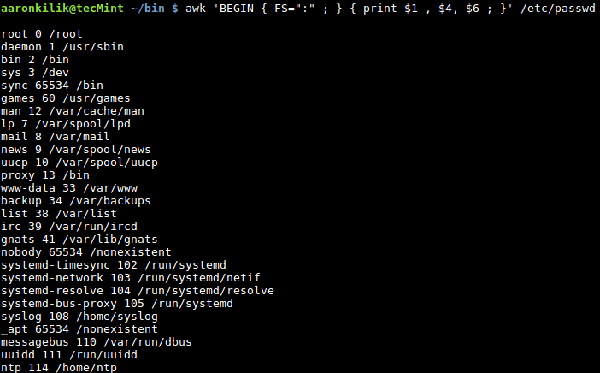
Utilisez la variable intégrée OFS pour spécifier un délimiteur de champ pour la sortie, qui définira comment utiliser le caractère spécifié pour séparer les champs de sortie : $ awk -F':' ' BEGIN { OFS. ="= =>" ;} { print $1, $4 ;}' /etc/passwd
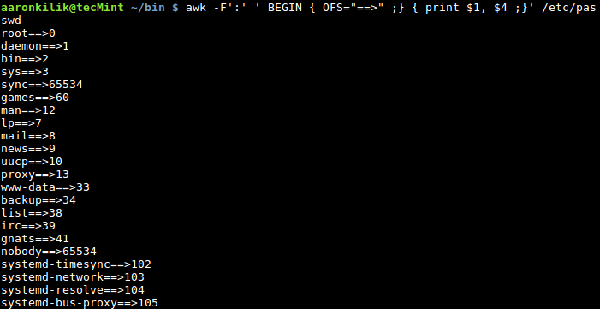
Dans cette section, nous avons appris l'idée d'utiliser des variables intégrées awk avec des valeurs prédéfinies. Mais nous pouvons également modifier ces valeurs, bien que cela ne soit pas recommandé à moins que vous sachiez ce que vous faites et compreniez parfaitement (ces valeurs variables).
Après cela, nous continuerons à apprendre à utiliser les variables shell dans les opérations de commande awk, alors restez à l'écoute avec nous.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!