
Maison >Tutoriel système >Linux >Le robot d'exploration Python analyse la critique du film 'Wolf Warrior'
Le robot d'exploration Python analyse la critique du film 'Wolf Warrior'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-05 21:44:121177parcourir
| Présentation | Au 20 août, 25e jour de sa sortie, "Wolf Warrior II" avait rapporté plus de 5 milliards de yuans au box-office, devenant ainsi le seul film asiatique à entrer dans le top 100 du box-office de l'histoire du cinéma mondial. Cet article utilise des robots d'exploration Python pour obtenir des données, analyser les critiques de films Douban et créer une image cloud des critiques de films Douban. Voyons maintenant quels sous-textes intéressants se cachent dans les critiques de « Wolf Warrior II ». |

Mis à part le box-office explosif, le film a également suscité diverses émotions chez le public. Certaines personnes ont même dit durement : quiconque ose critiquer "Wolf Warrior II" est soit un retard mental, soit un ennemi public.
Tout le monde a des critiques mitigées sur "Wolf Warrior II" et a laissé des commentaires sur Douban pour exprimer son opinion sur le film. Bien que divers commentaires aient été publiés et que les médias aient fait tout un plat, le public ne pouvait toujours pas dire quelle opinion était la plus fiable.
Jusqu'à présent, il y a eu plus de 150 000 commentaires. Lorsque vous lisez les commentaires, vous pouvez voir la plupart d'entre eux pendant un certain temps, soit des commentaires élogieux, soit des commentaires désobligeants. Il est donc difficile de dire en parcourant les commentaires quelle est l’opinion globale de chacun sur ce film. Utilisons maintenant l’analyse des données pour voir quelles choses intéressantes se sont produites dans ces commentaires !
Cet article utilise un robot d'exploration Python pour obtenir des données, analyser les critiques de films Douban et créer une image cloud des critiques de films Douban. Voyons maintenant quels sous-textes intéressants se cachent dans les critiques de « Wolf Warrior II ».
Acquisition de donnéesCet article utilise les données obtenues par le robot d'exploration Python. Il utilise principalement le package de requêtes et le package régulier re. Ce programme ne traite pas le code de vérification. J'ai déjà exploré la page Web de Douban. À cette époque, le contenu exploré étant petit, je n'ai pas rencontré le code de vérification. Lorsque j'ai écrit ce robot, je pensais qu'il n'y aurait pas de code de vérification, mais lorsqu'environ 15 000 commentaires ont été explorés, le code de vérification est apparu.
Puis j’ai pensé : n’est-ce pas seulement 120 000 ? Tout au plus, je n’ai saisi le code de vérification qu’une douzaine de fois, je n’ai donc pas eu à m’occuper du code de vérification. Mais ce qui s'est passé ensuite m'a un peu dérouté. Lorsque j'ai exploré environ 15 000 commentaires et saisi le code de vérification, j'ai pensé qu'il en explorerait environ 30 000, mais après en avoir exploré environ 3 000, cela n'a pas fonctionné. le code de vérification. .
Ensuite, cela a continué comme ça, en trébuchant. Parfois, il fallait beaucoup de temps pour explorer avant qu'un code de vérification soit nécessaire, et parfois ce n'était pas le cas. Mais finalement, les commentaires ont été explorés. Le contenu exploré comprend principalement : le nom de l'utilisateur, si vous l'avez vu, le nombre d'étoiles du commentaire, l'heure du commentaire, le nombre de personnes qui l'ont trouvé utile et le contenu du commentaire. Voici le code du robot Python :
demandes d'importation<br>
importer re<br>
importer des pandas en tant que PD<br>
url_first='https://movie.douban.com/subject/26363254/comments?start=0'<br>
head={'User-Agent':'Mozilla/5.0 (X11 ; Linux x86_64) AppleWebKit/537.36 (KHTML, comme Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36'}<br>
html=requests.get(url_first,headers=head,cookies=cookies)<br>
cookies={'cookie':'your own cookie'} #C'est-à-dire, trouvez le cookie correspondant à votre compte<br>
reg=re.compile(r'') #Page suivante<br>
ren=re.compile(r'<span>(.*?)</span>.*?comment">(.*?).*?.*?<span .>(.*?).*?<span>(.*?)</span>.* ?title="(.*?)"></span>.*?title="(.*?)">.*?class=""> (.*?)n',re.S) #Commentaires et autres contenus <br>
tandis que html.status_code==200:<br>
url_next='https://movie.douban.com/subject/26363254/comments'+re.findall(reg,html.text)[0]<br>
zhanlang=re.findall(ren,html.text)<br>
data=pd.DataFrame(zhanlang)<br>
data.to_csv('/home/wajuejiprince/document/zhanlang/zhanlangpinglun.csv', header=False,index=False,mode='a+') #Écrivez un fichier csv, 'a+' est le mode d'ajout<br>
données=[]<br>
zhanlang=[]<br>
html=requests.get(url_next,cookies=cookies,headers=head)
Dans le code ci-dessus, veuillez définir votre propre agent utilisateur, cookie, chemin d'enregistrement CSV, etc., et enregistrez le contenu analysé dans un fichier au format CSV.
Cet article utilise le langage R pour traiter les données. Bien que nous ayons accordé une grande attention à la structure du contenu analysé lors de l'exploration, il est inévitable que certaines valeurs ne correspondent pas à ce que nous voulons. Par exemple, certains contenus de commentaires apparaîtront dans l'élément commentateur, il est donc toujours nécessaire de nettoyer les données.
Chargez d'abord tous les packages que vous souhaitez utiliser :
bibliothèque (data.table)<br>
bibliothèque (intrigue)<br>
bibliothèque (stringr)<br>
bibliothèque (jiebaR)<br>
bibliothèque (wordcloud2)<br>
bibliothèque(magrittr)
Importer des données et nettoyer :
dt
Regardons d'abord les commentaires en fonction du nombre d'étoiles :
plot_ly(my_dt[,.(.N),by=.(五星数)],type = 'bar',x=~五星数,y=~N)plot_ly(my_dt[,.(.N),by=.(numéro cinq étoiles)],type = 'bar',x=~numéro cinq étoiles,y=~N)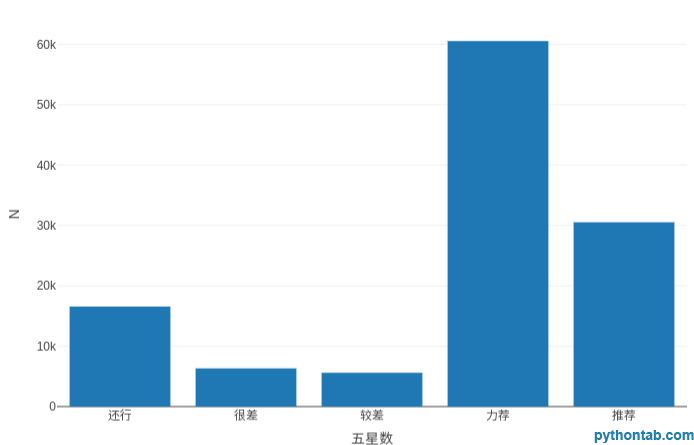
Le nombre d'étoiles à cinq branches correspond à 5 niveaux, 5 étoiles signifie fortement recommandé, 4 étoiles signifie recommandé, 3 étoiles signifie bien, 2 étoiles signifie mauvais et 1 étoile signifie très mauvais.
Il ressort clairement des critiques de Pentagram que nous avons des raisons de croire que la grande majorité des téléspectateurs seront satisfaits de ce film.
Nous devons d'abord segmenter les commentaires :
semaine <br>
Affichage global du cloud : <br>
<code>mots%data.table()<br>
définir des noms (mots, "N", "pinshu")<br>
mots[pinshu>1000] #Supprimer les mots de fréquence inférieure (moins de 1000)<br>
wordcloud2 (mots [pinshu> 1000], taille = 2, fontFamily = "Microsoft Yahei", couleur = "lumière aléatoire", backgroundColor = "gris")
Parce qu'il y avait trop de données, mon ordinateur en panne s'est figé, j'ai donc supprimé les mots avec des fréquences inférieures à 1 000 lors de la création de la carte nuageuse. Les résultats de l'image cloud sont les suivants :

Dans l’ensemble, les commentaires de tout le monde sur cette vidéo sont plutôt bons ! Des sujets tels que l'intrigue, l'action et le patriotisme sont au centre des discussions.
Mots-clés d'évaluation : Wu Jing, héroïsme personnel, thème principal, Chine, aura du protagoniste, secrétaire Dakang, très brûlant.
On peut voir que « brûler » n'est pas la réponse la plus populaire après l'avoir regardé. Le public est plus intéressé à admirer Wu Jing lui-même et à commenter le patriotisme et l'individualisme.
Affichage d'images cloud avec différents niveaux de commentairesMais à quoi cela ressemblerait-il si les commentaires des personnes ayant des notes différentes étaient affichés séparément ? Il s'agit de créer un graphique cloud pour le contenu de l'examen à cinq niveaux (fortement recommandé, recommandé, d'accord, mauvais, très mauvais), le code est le suivant (il suffit de changer le code en "fortement recommandé" par un autre).
1. Nuage de commentaires de critiques hautement recommandés




À en juger par les résultats de segmentation des mots des différents commentaires, ils ont tous un sujet commun : le patriotisme.
Le nombre de sujets patriotiques dans les commentaires fortement recommandés peut être plus élevé que dans les commentaires peu recommandés. Dans les commentaires fortement recommandés, les gens sont plus disposés à discuter d'autres sujets que des sujets patriotiques. La plupart des commentaires négatifs concernaient des sujets patriotiques. Et leur proportion est très intéressante De ceux qui le recommandent fortement à ceux qui commentent mal, la proportion de sujets patriotiques augmente progressivement.
Nous ne pouvons pas penser subjectivement qui a raison ou tort. Nous pouvons seulement dire qu'ils ont des perspectives différentes, donc les résultats qu'ils voient sont également différents. Lorsque nous ne sommes pas d’accord avec les autres, nous avons souvent des points de vue différents. Les personnes qui font de mauvais commentaires pensent peut-être davantage à des sujets patriotiques (il ne s’agit que d’une discussion sur des sujets patriotiques, pas sur ceux qui aiment ou n’aiment pas le pays) ! !
Après l'analyse, la raison fondamentale pour laquelle ce "Wolf Warrior 2" a été soutenu par tant de gens est qu'il a atteint en production une scène de niveau blockbuster américain que "Wolf Warrior 1" n'avait pas, et en même temps cela a suscité le patriotisme et a éveillé le cœur des gens.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!