
Maison >Périphériques technologiques >IA >Les modèles à grande échelle peuvent déjà annoter des images avec une simple conversation ! Résultats de recherche de Tsinghua et NUS
Les modèles à grande échelle peuvent déjà annoter des images avec une simple conversation ! Résultats de recherche de Tsinghua et NUS

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-05 12:56:09779parcourir
Une fois que le grand modèle multimodal intègre le module de détection et de segmentation, la découpe d'image devient plus facile !
Notre modèle peut rapidement étiqueter les objets que vous recherchez grâce à des descriptions en langage naturel et fournir des explications textuelles pour vous aider à accomplir la tâche facilement.
Le nouveau grand modèle multimodal développé par le laboratoire NExT++ de l'Université nationale de Singapour et l'équipe de Liu Zhiyuan de l'Université Tsinghua nous apporte un soutien fort. Ce modèle a été soigneusement conçu pour fournir aux joueurs une aide et des conseils complets pendant le processus de résolution d'énigmes. Il combine des informations provenant de plusieurs modalités pour présenter aux joueurs de nouvelles méthodes et stratégies de résolution d’énigmes. L'application de ce modèle profitera aux joueurs

Avec le lancement de GPT-4v, le domaine multimodal a inauguré une série de nouveaux modèles, tels que LLaVA, BLIP-2, etc. L'émergence de ces modèles a grandement contribué à l'amélioration des performances et de l'efficacité des tâches multimodales.
Afin d'améliorer encore les capacités de compréhension régionale des grands modèles multimodaux, l'équipe de recherche a développé un modèle multimodal appelé NExT-Chat. Ce modèle a la capacité de mener simultanément le dialogue, la détection et la segmentation.
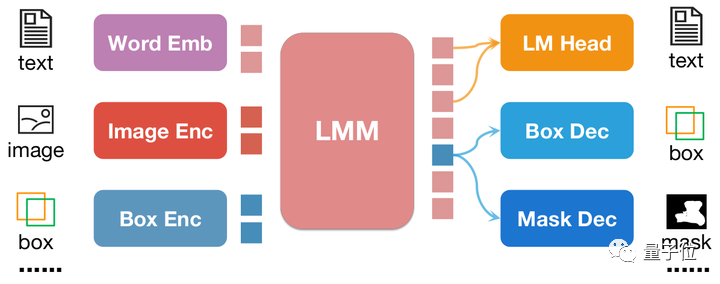
Le plus grand point fort de NExT-Chat est la possibilité d'introduire des entrées et des sorties positionnelles dans son modèle multimodal. Cette fonctionnalité permet à NExT-Chat de comprendre et de répondre plus précisément aux besoins des utilisateurs lors de l'interaction. Grâce à la saisie de la localisation, NExT-Chat peut fournir des informations et des suggestions pertinentes en fonction de la situation géographique de l'utilisateur, améliorant ainsi l'expérience utilisateur. Grâce à la sortie de localisation, NExT-Chat peut transmettre des informations pertinentes sur des emplacements géographiques spécifiques aux utilisateurs pour mieux les aider
Parmi eux, la capacité de saisie de localisation fait référence à la réponse à des questions basées sur la zone spécifiée, tandis que la capacité de sortie de localisation fait référence à la localisation. dialogue spécifique à l'objet mentionné. Ces deux capacités sont très importantes dans les jeux de réflexion.

Même les problèmes de positionnement complexes peuvent être résolus facilement :

En plus du positionnement des objets, NExT-Chat peut également décrire l'image ou une certaine partie de celle-ci :
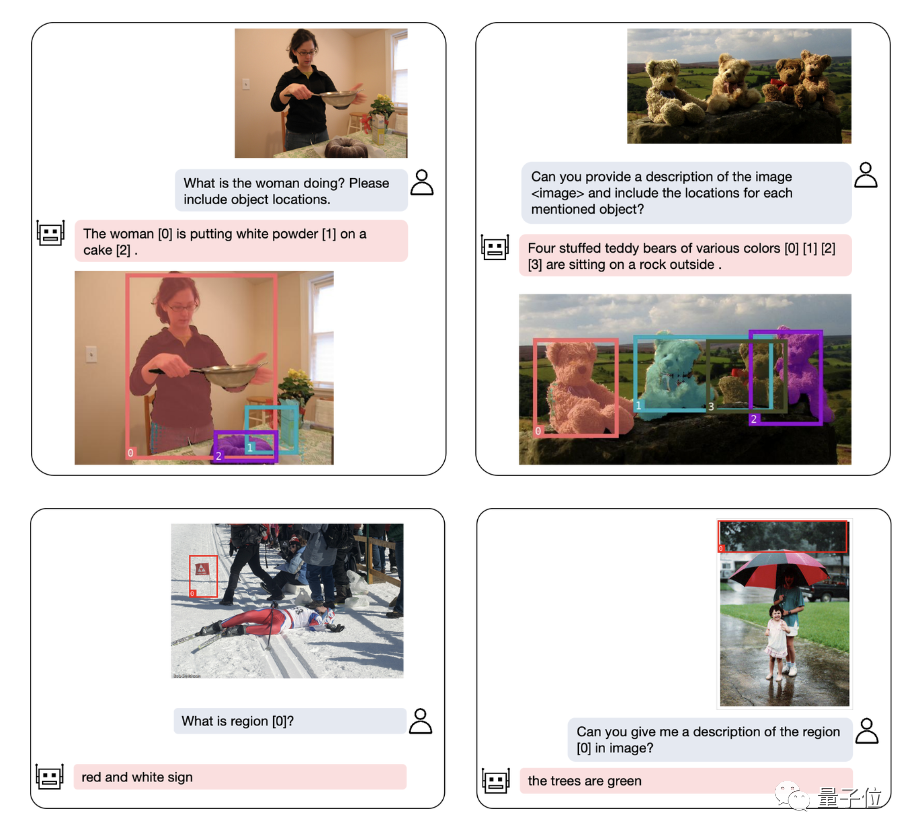
Après avoir analysé le contenu du image Ensuite, NExT-Chat peut utiliser les informations obtenues pour effectuer des inférences :

Pour évaluer avec précision les performances de NExT-Chat, l'équipe de recherche a effectué des tests sur plusieurs ensembles de données de tâches.
Obtenez SOTA sur plusieurs ensembles de données
L'auteur a d'abord montré les résultats expérimentaux de NExT-Chat sur la tâche de segmentation d'expression référentielle (RES).
Bien qu'il n'utilise qu'une très petite quantité de données de segmentation, NExT-Chat a démontré de bonnes capacités de segmentation référentielle, battant même une série de modèles supervisés (tels que MCN, VLT, etc.) et utilisant plus de 5 fois le masque de segmentation. Méthode LISA annotée.
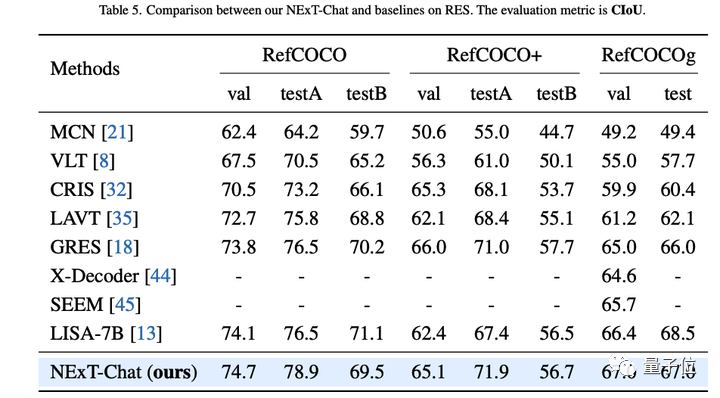
△Résultats NExT-Chat sur la tâche RES
Ensuite, l'équipe de recherche a montré les résultats expérimentaux de NExT-Chat sur la tâche REC.
Comme le montre le tableau ci-dessous, par rapport à une série de méthodes supervisées (telles que UNITER), NExT-Chat peut obtenir de meilleurs résultats.
Une découverte intéressante est que NExT-Chat est légèrement moins efficace que Shikra, qui utilise des données d'entraînement en boîte similaires.
L'auteur suppose que cela est dû au fait que la perte LM et la perte de détection dans la méthode pix2emb sont plus difficiles à équilibrer, et Shikra est plus proche de la forme de pré-entraînement du grand modèle de texte brut existant.
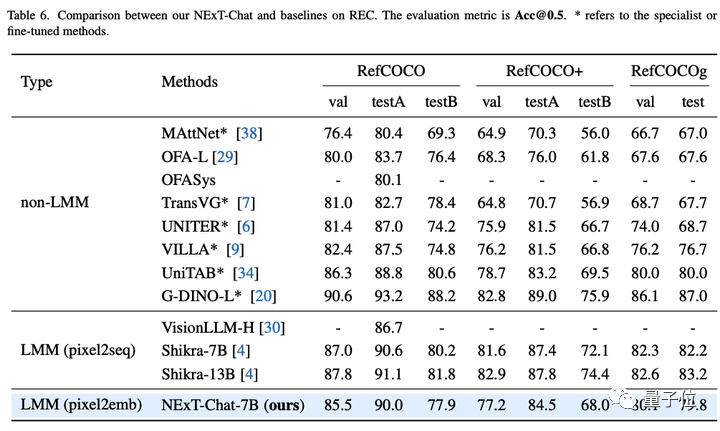
△Résultats NExT-Chat sur la tâche REC
Sur la tâche d'illusion d'image, comme le montre le tableau 3, NExT-Chat peut obtenir la meilleure précision sur les ensembles de données aléatoires et populaires.
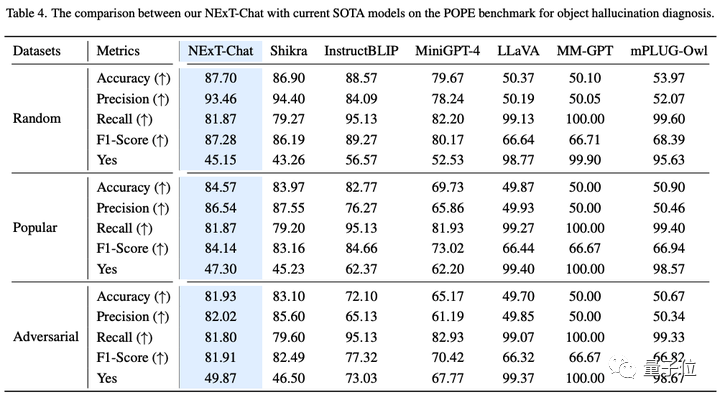
△Résultats NExT-Chat sur l'ensemble de données POPE
Dans la tâche de description de zone, NExT-Chat peut également atteindre les meilleures performances CIDEr et battre Kosmos-2 dans le cas 4 coups dans cet indicateur.
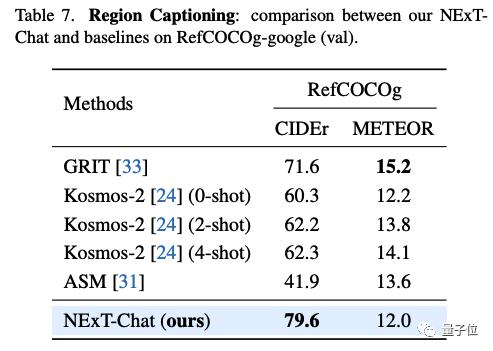
△Résultats NExT-Chat sur l'ensemble de données RefCOCOg
Alors, quelles méthodes sont utilisées derrière NExT-Chat ?
Proposer une nouvelle méthode de codage d'images
Défauts des méthodes traditionnelles
Les modèles traditionnels effectuent principalement une modélisation de position liée au LLM via pix2seq.
Par exemple, Kosmos-2 divise l'image en blocs de 32x32 et utilise l'identifiant de chaque bloc pour représenter les coordonnées du point ; Shikra convertit les coordonnées du cadre de l'objet en texte brut afin que LLM puisse comprendre les coordonnées.
Cependant, la sortie du modèle utilisant la méthode pix2seq est principalement limitée à des formats simples tels que les boîtes et les points, et il est difficile de la généraliser à d'autres formats de représentation de position plus denses, tels que le masque de segmentation.
Afin de résoudre ce problème, cet article propose une nouvelle méthode de modélisation de position basée sur l'intégration pix2emb.
Méthode pix2emb
Différent de pix2seq, toutes les informations de position de pix2emb sont codées et décodées via l'encodeur et le décodeur correspondants, plutôt que de s'appuyer sur l'en-tête de prédiction de texte de LLM lui-même.
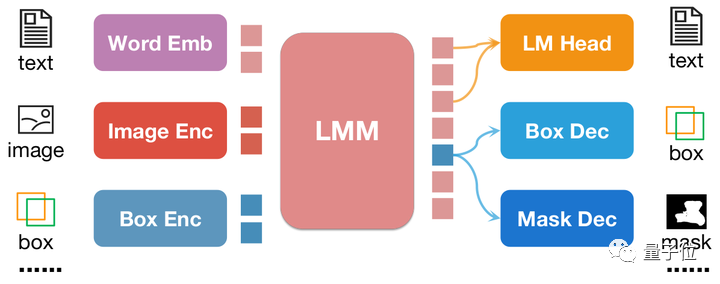
△Exemple simple de la méthode pix2emb
Comme le montre la figure ci-dessus, l'entrée de position est codée en intégration de position par l'encodeur correspondant, et l'intégration de position de sortie est convertie en boîtes et masques via Box Decoder et Mask Decoder .
Faire cela apporte deux avantages :
- Le format de sortie du modèle peut être facilement étendu à des formes plus complexes, telles que le masque de segmentation.
- Le modèle peut facilement localiser les méthodes pratiques existantes dans la tâche. Par exemple, la perte de détection dans cet article utilise la perte L1 et la perte GIoU (pix2seq ne peut utiliser que du texte pour générer une perte). SAM pour le faire.
En combinant pix2seq avec pix2emb, l'auteur a formé un nouveau modèle NExT-Chat.
Modèle NExT-Chat
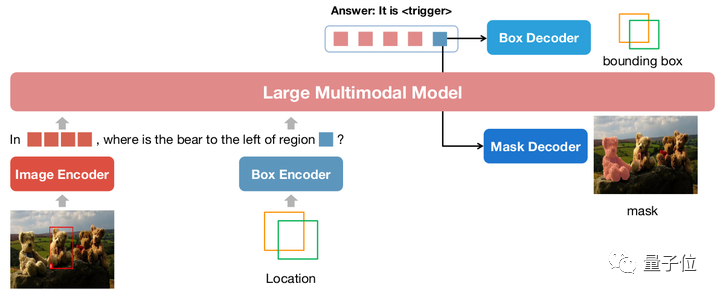
△Architecture du modèle NExT-Chat
NExT-Chat adopte l'architecture LLaVA dans son ensemble, c'est-à-dire que les informations sur l'image sont codées via Image Encoder et saisies dans LLM pour la compréhension, et sur ce Sur cette base, la correspondance est ajoutée avec un encodeur de boîte et un décodeur de sortie à deux positions.
Afin de résoudre le problème de LLM ne sachant pas quand utiliser la tête LM du langage ou le décodeur de position, NExT-Chat introduit en outre un nouveau type de jeton pour identifier les informations de position.
Si le modèle produit, l'intégration du jeton sera envoyée au décodeur de position correspondant pour décodage au lieu du décodeur de langue.
De plus, afin de maintenir la cohérence des informations de position entre l'étage d'entrée et l'étage de sortie, NExT-Chat introduit une contrainte d'alignement supplémentaire :
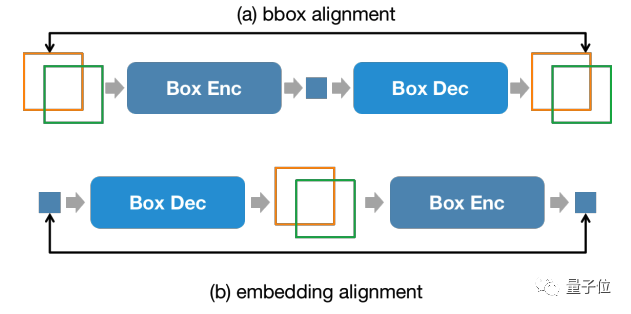
△Contraintes d'entrée et de sortie de position
Comme le montre la figure ci-dessus, l'intégration de la boîte et de la position sera combinée respectivement par le décodeur, l'encodeur ou le décodeur-encodeur, et ne doit pas changer avant et après.
L'auteur a découvert que cette méthode peut grandement favoriser la convergence des capacités de saisie de position.
La formation du modèle de NExT-Chat comprend principalement 3 étapes :
- La première étape : la formation du modèle capacités d'entrée et de sortie de base du boîtier. NExT-Chat utilise Flickr-30K, RefCOCO, VisualGenome et d'autres ensembles de données contenant des entrées et des sorties de boîtes pour la pré-formation. Pendant le processus de formation, tous les paramètres LLM seront formés.
- La deuxième étape : Ajuster les instructions du LLM en fonction des capacités. Le réglage fin des données grâce à certaines instructions Shikra-RD, LLaVA-instruct et autres permet au modèle de mieux répondre aux exigences humaines et de produire des résultats plus humains.
- La troisième étape : Donnez aux capacités de segmentation du modèle NExT-Chat. Grâce aux deux étapes de formation ci-dessus, le modèle dispose déjà de bonnes capacités de modélisation de position. L'auteur étend encore cette capacité au masque de sortie. Des expériences ont montré qu'en utilisant une très petite quantité de données d'annotation de masque et un temps de formation (environ 3 heures), NExT-Chat peut rapidement atteindre de bonnes capacités de segmentation.
L'avantage d'un tel processus de formation est que les données de la trame de détection sont riches et que la surcharge de formation est moindre.
NExT-Chat entraîne des capacités de modélisation de position de base sur des données de trame de détection abondantes, et peut ensuite rapidement s'étendre à des tâches de segmentation plus difficiles et comportant des annotations plus rares.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!