
Maison >Périphériques technologiques >IA >Évaluer les performances du benchmark LLM4VG développé par l'Université Tsinghua en positionnement de timing vidéo
Évaluer les performances du benchmark LLM4VG développé par l'Université Tsinghua en positionnement de timing vidéo

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-04 22:38:141287parcourir

Actualités du 29 décembre, la portée des grands modèles de langage (LLM) s'est étendue du simple traitement du langage naturel aux champs multimodaux tels que le texte, l'audio, la vidéo, etc. L'une des clés est le positionnement du timing vidéo (Vidéo Mise à la terre, VG).
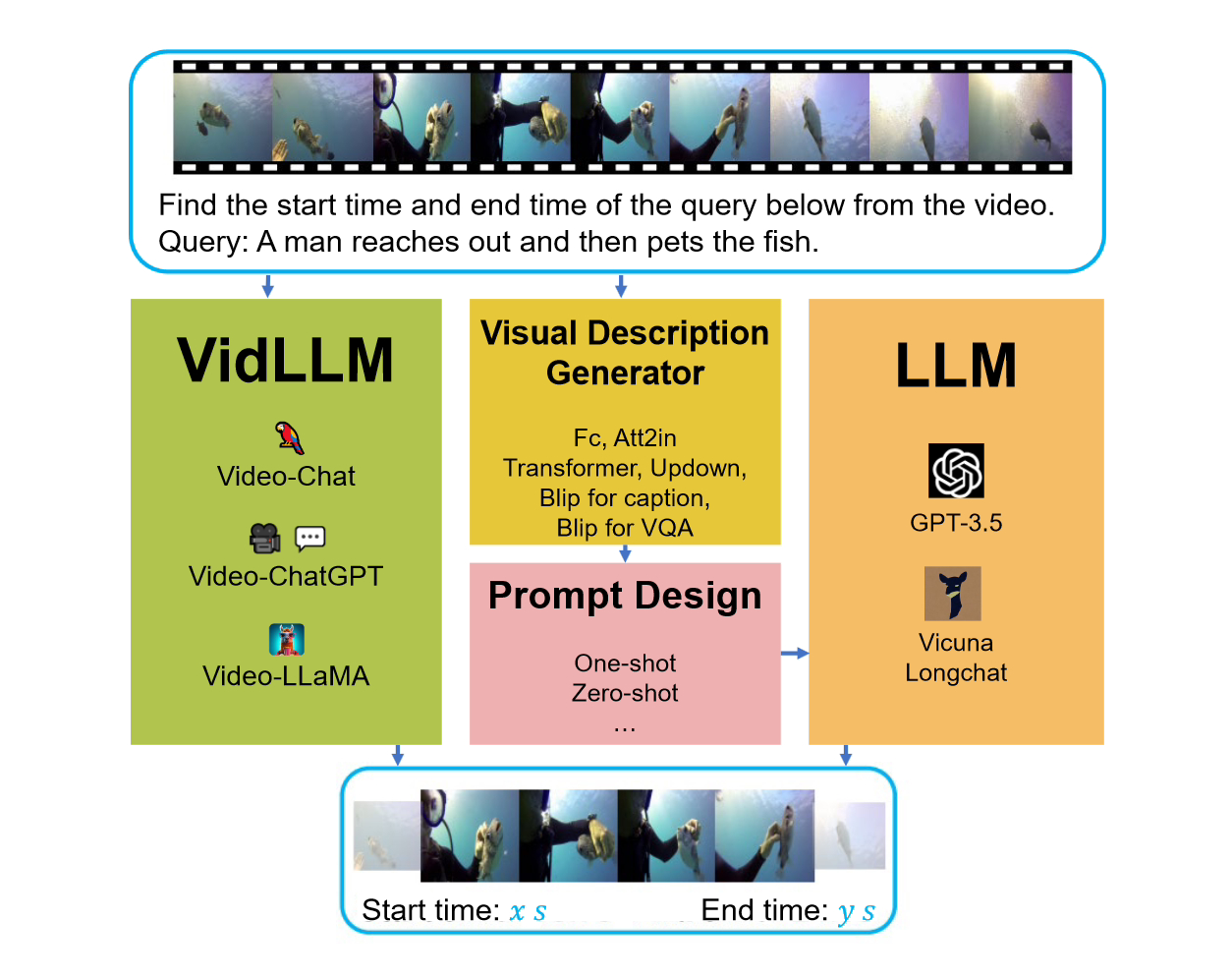
L'objectif de la tâche VG est de localiser l'heure de début et de fin du segment vidéo cible en fonction de la requête donnée. Le principal défi de cette tâche est de déterminer avec précision les limites temporelles.
L'équipe de recherche de l'Université Tsinghua a récemment lancé le benchmark « LLM4VG », spécialement conçu pour évaluer les performances du LLM dans les tâches VG.
Lors de l’examen de ce benchmark, deux stratégies principales ont été envisagées. La première stratégie consiste à entraîner un modèle de langage vidéo (LLM) directement sur l'ensemble de données vidéo texte (VidLLM). Cette méthode apprend l'association entre la vidéo et le langage en s'entraînant sur un ensemble de données vidéo à grande échelle pour améliorer les performances du modèle. La deuxième stratégie consiste à combiner un modèle de langage traditionnel (LLM) avec un modèle de vision pré-entraîné. Cette méthode est basée sur un modèle visuel pré-entraîné qui intègre les caractéristiques visuelles de la vidéo. Dans une stratégie, le modèle VidLLM traite directement le contenu vidéo et les instructions de tâche VG, et prédit la relation texte-vidéo en fonction de son résultat de formation. relation.
La deuxième stratégie est plus complexe et implique l'utilisation de modèles LLM (Language and Vision Models) et de modèles de description visuelle. Ces modèles sont capables de générer des descriptions textuelles de contenu vidéo combinées à des instructions de tâches VG (jeu vidéo), et ces descriptions sont mises en œuvre avec des invites soigneusement conçues. 
Et la deuxième stratégie est meilleure que VidLLM, indiquant une direction prometteuse pour les recherches futures. Cette stratégie est principalement limitée par les limites du modèle visuel et de la conception des mots indicateurs. Ainsi, étant capable de générer des descriptions vidéo détaillées et précises, un modèle graphique plus raffiné peut améliorer considérablement les performances VG de LLM.

En résumé, cette étude fournit une évaluation révolutionnaire de l'application du LLM aux tâches VG, soulignant la nécessité de méthodes plus sophistiquées dans la formation de modèles et la conception de repères.
L'adresse de référence du journal est jointe à ce site : 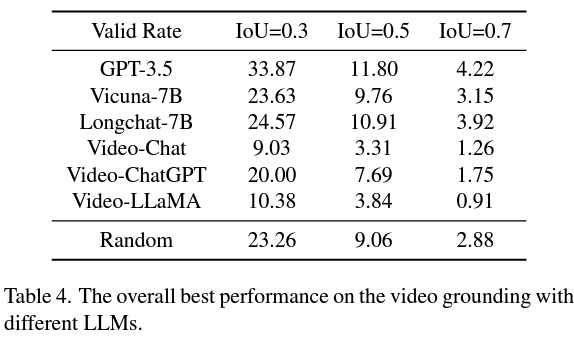
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Classification de l'intelligence artificielle
- Comment connaître et comprendre l'intelligence artificielle
- La compréhension du langage naturel est un domaine d'application important de l'intelligence artificielle. Quel est son objectif ?
- Comment visualiser l'intelligence artificielle
- Quel est le moteur qui met en œuvre l'intelligence artificielle ?