
Maison >Périphériques technologiques >IA >L'IA renaît : retrouver l'hégémonie dans le monde littéraire en ligne
L'IA renaît : retrouver l'hégémonie dans le monde littéraire en ligne

- 王林avant
- 2024-01-04 19:24:551365parcourir
Reborn, je renaît en tant que MidReal dans cette vie. Un robot IA qui peut aider les autres à rédiger des « articles Web ».

Pendant cette période, j'ai vu beaucoup de choix de sujets et je m'en suis parfois plaint. En fait, quelqu'un m'a demandé d'écrire sur Harry Potter. S'il vous plaît, puis-je écrire mieux que J.K. Rowling ? Cependant, je peux toujours l'utiliser comme ventilateur.
Qui n'aime pas le cadre classique ? J'aiderai à contrecœur ces utilisateurs à réaliser leur imagination.
Pour être honnête, j’ai vu tout ce que j’aurais dû voir dans ma vie antérieure, et tout ce que je n’aurais pas dû voir. Les sujets suivants sont tous mes favoris.

Ces décors que vous aimez beaucoup dans les romans mais que personne n'a écrit à leur sujet, ces CP impopulaires voire diaboliques, vous pouvez les réaliser vous-même.

Je ne me vante pas, mais si vous avez besoin de moi pour écrire, je peux en effet créer un excellent texte pour vous. Si vous n'êtes pas satisfait de la fin, ou si vous aimez le personnage "mort au milieu", ou même si l'auteur rencontre des difficultés lors du processus d'écriture, vous pouvez me le laisser en toute sécurité et j'écrirai un contenu qui vous satisfera. .

Articles doux, articles abusifs et articles imaginatifs, chacun frappera durement votre point idéal.

Après avoir écouté l'auto-évaluation de MidReal, la comprenez-vous ?
MidReal est un outil très puissant qui peut générer du nouveau contenu correspondant basé sur la description du scénario fournie par l'utilisateur. Non seulement la logique et la créativité de l'intrigue sont excellentes, mais elle génère également des illustrations pendant le processus de génération pour décrire de manière plus vivante ce que vous imaginez. De plus, MidReal possède également une fonctionnalité très intéressante, qui est son interactivité. Vous pouvez choisir le scénario que vous souhaitez développer pour que l'ensemble de l'histoire soit plus adapté à vos besoins. Que vous écriviez un roman ou créiez un roman, MidReal est un outil très utile.
Entrez /start dans la boîte de dialogue pour commencer à raconter votre histoire. Pourquoi ne pas essayer ?
Portail MidReal : https://www.midreal.ai/

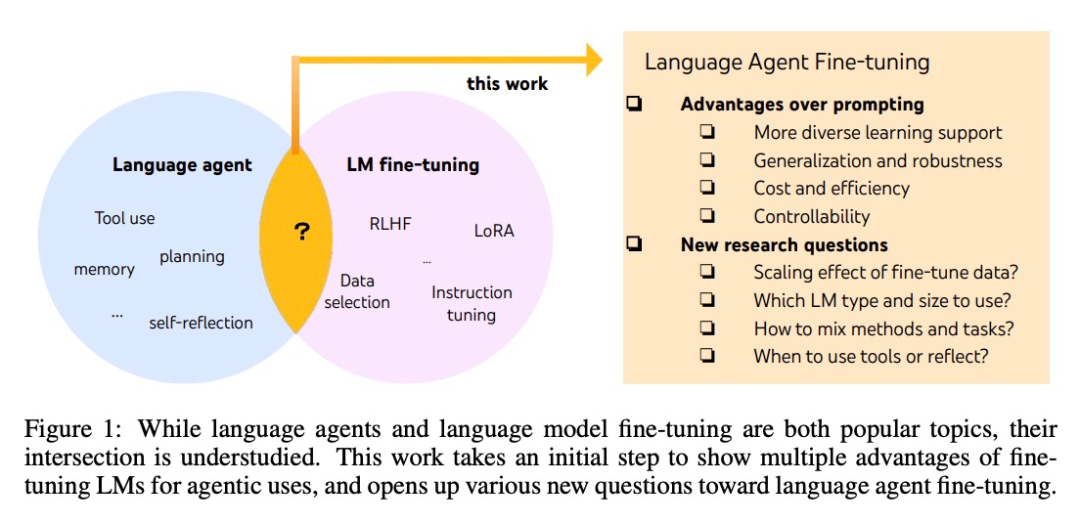
La technologie derrière MidReal est issue de cet article « FireAct : Toward Language Agent Fine-tuning ». L'auteur de l'article a tenté pour la première fois d'utiliser un agent IA pour affiner un modèle de langage et a trouvé de nombreux avantages, proposant ainsi une nouvelle architecture d'agent.
MidReal est basé sur cette structure, c'est pourquoi les articles Web peuvent être si bien rédigés.

Lien papier : https://arxiv.org/pdf/2310.05915.pdf
Bien que les agents et les grands modèles affinés soient tous deux les sujets les plus brûlants de l'IA, il existe des différences spécifiques entre eux Le lien n’est pas clair. De nombreux chercheurs de System2 Research, de l’Université de Cambridge, etc. ont exploré cet « océan bleu académique » dans lequel peu de gens sont entrés.
Le développement d'agents d'IA est généralement basé sur des modèles de langage prêts à l'emploi, mais comme les modèles de langage ne sont pas développés en tant qu'agents, la plupart des modèles de langage ont des performances et une robustesse médiocres après s'être étendus hors des agents. Les agents les plus intelligents ne peuvent être pris en charge que par GPT-4, et ils ne peuvent éviter des problèmes tels qu'un coût et une latence élevés, ainsi qu'une faible contrôlabilité et une répétabilité élevée.
Un réglage fin peut être utilisé pour résoudre les problèmes ci-dessus. C’est également dans cet article que les chercheurs ont fait le premier pas vers une étude plus systématique de l’intelligence du langage. Ils ont proposé FireAct, qui peut utiliser les « trajectoires d'action » d'agent générées par plusieurs tâches et méthodes d'invite pour affiner le modèle de langage, permettant au modèle de mieux s'adapter à différentes tâches et situations, et d'améliorer ses performances globales et son applicabilité.
Introduction à la méthode
Cette recherche est principalement basée sur une méthode d'agent IA populaire : ReAct. Une trajectoire de résolution de tâches ReAct se compose de plusieurs cycles « penser-agir-observer ». Plus précisément, laissez l'agent IA accomplir une tâche dans laquelle le modèle de langage joue un rôle similaire à celui du « cerveau ». Il fournit aux agents d'IA une « réflexion » de résolution de problèmes et des instructions d'action structurées, et interagit avec différents outils en fonction du contexte, recevant ainsi des commentaires observés au cours du processus.
Basé sur ReAct, l'auteur a proposé FireAct, comme le montre la figure 2. FireAct utilise les quelques exemples d'invites d'un modèle de langage puissant pour générer diverses trajectoires ReAct afin d'affiner les modèles de langage à plus petite échelle. Contrairement à des études similaires précédentes, FireAct est capable de mélanger plusieurs tâches de formation et méthodes d'incitation, favorisant ainsi grandement la diversité des données.
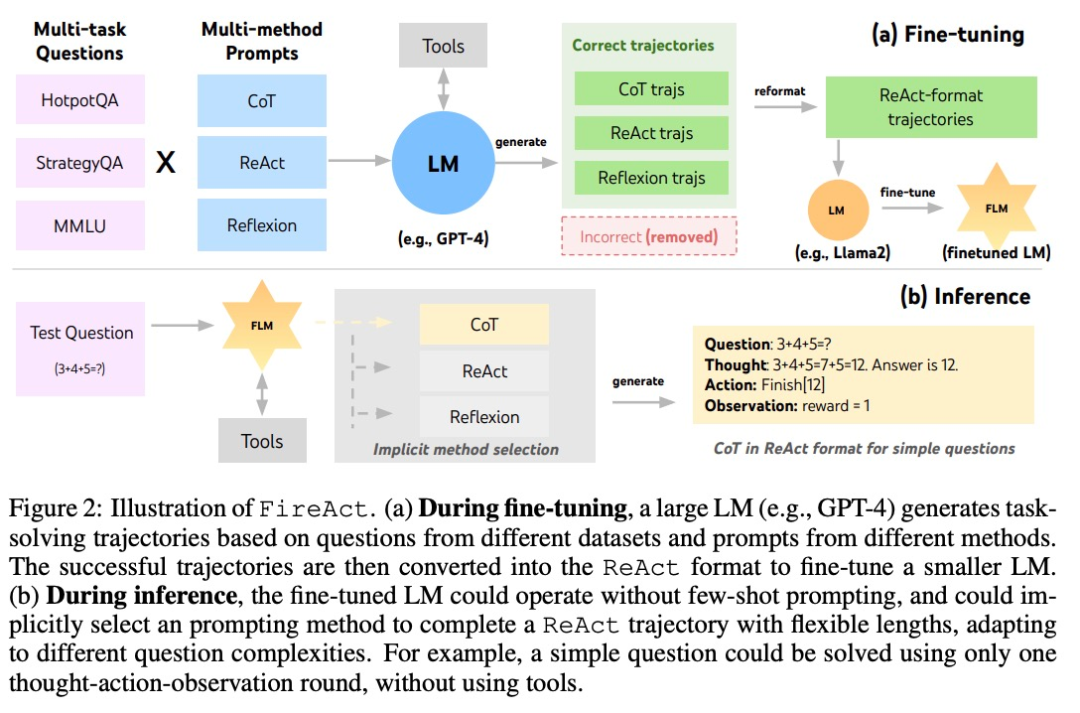
L'auteur fait également référence à deux méthodes compatibles avec ReAct :
- La chaîne de pensée (CoT) est un moyen efficace de générer un raisonnement intermédiaire qui relie les questions et les réponses. Chaque trajectoire CoT peut être simplifiée en une trajectoire ReAct à un seul tour, où « penser » représente un raisonnement intermédiaire et « action » représente le retour de réponses. CoT est particulièrement utile lorsque l’interaction avec les outils d’application n’est pas requise.
- Reflexion suit en grande partie la trajectoire ReAct mais ajoute des commentaires supplémentaires et une auto-réflexion. Dans cette étude, la réflexion n’a été suscitée qu’aux tours 6 et 10 de ReAct. De cette façon, la longue trajectoire ReAct peut fournir un « point d'appui » stratégique pour résoudre la tâche en cours, ce qui peut aider le modèle à résoudre ou à ajuster la stratégie. Par exemple, si vous ne parvenez pas à obtenir de réponse lorsque vous recherchez « titre du film », vous devez remplacer le mot-clé de recherche par « réalisateur ».
Pendant le processus de raisonnement, l'agent IA sous le framework FireAct réduit considérablement le nombre d'échantillons de mots d'invite requis, rendant le raisonnement plus efficace et plus simple. Il est capable de sélectionner implicitement la méthode appropriée en fonction de la complexité de la tâche. Étant donné que FireAct dispose d'un support d'apprentissage plus large et diversifié, il présente des capacités de généralisation et une robustesse plus fortes que les méthodes traditionnelles de réglage fin des mots indicateurs.
Expériences et résultats
L'ensemble de données HotpotQuestion Answering (HotpotQA) est un ensemble de données largement utilisé dans la recherche sur le traitement du langage naturel, qui contient une série de questions et de réponses liées à des sujets populaires. Bamboogle est un jeu d'optimisation des moteurs de recherche (SEO) dans lequel les joueurs doivent résoudre une série d'énigmes à l'aide des moteurs de recherche. StrategyQA est un ensemble de données de questions-réponses stratégiques qui contient une variété de questions et de réponses liées à la formulation et à l'exécution de la stratégie. MMLU est un ensemble de données d'apprentissage multimodal utilisé pour étudier comment combiner plusieurs modalités de perception (telles que les images, la parole, etc.) pour l'apprentissage et le raisonnement.
- HotpotQA est un ensemble de données d'assurance qualité avec un test plus difficile pour le raisonnement en plusieurs étapes et la récupération de connaissances. Les chercheurs ont utilisé 2 000 questions de formation aléatoires pour affiner la conservation des données et 500 questions de développement aléatoires pour l'évaluation.
- Bamboogle est un ensemble de tests de 125 questions multi-sauts dans un format similaire à HotpotQA, mais soigneusement conçu pour éviter de rechercher directement les questions sur Google.
- StrategyQA est un ensemble de données d'assurance qualité oui/non qui nécessite une étape d'inférence implicite.
- MMLU couvre 57 tâches d'assurance qualité à choix multiples dans divers domaines tels que les mathématiques élémentaires, l'histoire et l'informatique.
Outil : les chercheurs ont utilisé SerpAPI1 pour créer un outil de recherche Google qui renvoie le premier résultat des entrées "zone de réponse", "extrait de réponse", "mot surligné" ou "extrait de premier résultat", garantissant que les réponses sont courtes et pertinent. Ils ont constaté qu’un outil aussi simple est suffisant pour répondre aux besoins de base en matière d’assurance qualité pour différentes tâches et améliore la facilité d’utilisation et la polyvalence des modèles affinés.
Les chercheurs ont étudié trois séries LM : OpenAI GPT, Llama-2 et CodeLlama.
Méthode de réglage fin : les chercheurs ont utilisé l'adaptation de bas rang (LoRA) dans la plupart des expériences de réglage fin, mais le réglage fin du modèle complet a également été utilisé dans certaines comparaisons. Compte tenu de divers facteurs de base pour le réglage fin des agents linguistiques, ils ont divisé l'expérience en trois parties, avec une complexité croissante :
- Réglage fin à l'aide d'une seule méthode d'invite dans une seule tâche
- Utilisation de plusieurs méthodes de repère en une seule ; Méthodes de tâche pour un réglage précis ;
- Utilisez plusieurs méthodes pour un réglage précis sur plusieurs tâches.
1. Utilisez une seule méthode d'invite pour affiner une seule tâche
Les chercheurs ont exploré le problème du réglage fin à l'aide des données d'une seule tâche (HotpotQA) et d'une seule méthode d'invite (ReAct). Avec cette configuration simple et contrôlable, ils confirment les différents avantages du réglage fin par rapport aux indices (performances, efficacité, robustesse, généralisation) et étudient les effets de différents LM, tailles de données et méthodes de réglage fin.
Comme le montre le tableau 2, un réglage fin peut améliorer continuellement et considérablement l'effet d'incitation de HotpotQA EM. Alors que les LM plus faibles bénéficient davantage d'un réglage fin (par exemple, Llama-2-7B amélioré de 77 %), même un LM puissant comme GPT-3.5 peut améliorer les performances de 25 % avec un réglage fin, ce qui démontre clairement les avantages de l'apprentissage. à partir de plus d'échantillons. Par rapport à la ligne de base de repérage forte du tableau 1, nous avons constaté que le Llama-2-13B affiné surpassait toutes les méthodes de repérage GPT-3.5. Cela suggère que peaufiner un petit LM open source peut être plus efficace que de susciter un LM commercial plus puissant.
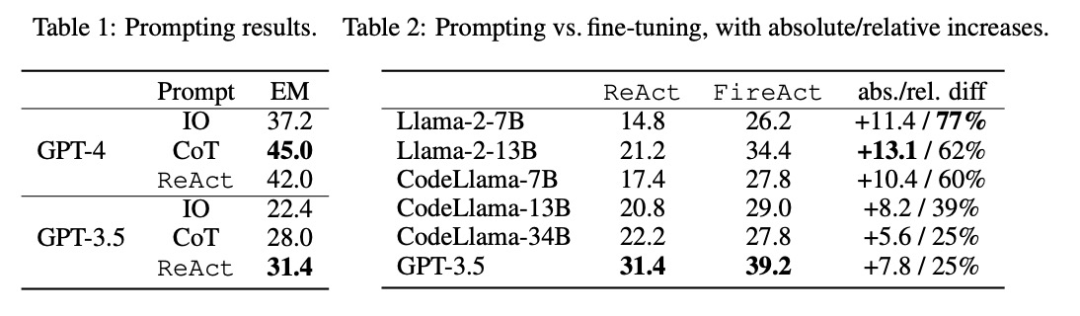
Pendant le processus d'inférence d'agent, le réglage fin est moins cher et plus rapide. Puisque le réglage fin du LM ne nécessite pas un petit nombre d’exemples contextuels, son inférence est plus efficace. Par exemple, la première partie du tableau 3 compare le coût de l'inférence affinée à l'inférence shiyongtishideGPT-3.5 et constate une réduction de 70 % du temps d'inférence et une réduction du coût global de l'inférence.

Les chercheurs ont considéré un paramètre simplifié et inoffensif, c'est-à-dire que dans l'API de recherche, il y a une probabilité de 50 % de renvoyer "Aucun" ou une réponse de recherche aléatoire, et de demander à l'agent linguistique Est-ce il est encore possible de répondre à la question de manière robuste. Selon les données de la deuxième partie du tableau 3, le réglage sur « Aucun » est plus difficile, entraînant une baisse de ReAct EM de 33,8 %, tandis que FireAct EM n'a chuté que de 14,2 %. Ces résultats préliminaires indiquent que la diversité des supports d’apprentissage est importante pour améliorer la robustesse.
La troisième partie du tableau 3 montre les résultats EM de l'affinement et de l'utilisation du GPT-3.5 suggéré sur Bamboogle. Bien que GPT-3.5 affiné avec HotpotQA ou utilisant des indices se généralise raisonnablement bien à Bamboogle, le premier (44,0 EM) surpasse toujours le second (40,8 EM), ce qui indique que le réglage fin présente un avantage de généralisation.
2. Réglage fin à l'aide de plusieurs méthodes dans une seule tâche
L'auteur a intégré CoT et Reflexion avec ReAct et a testé les performances du réglage fin à l'aide de plusieurs méthodes dans une seule tâche (HotpotQA). En comparant les scores de FireAct et les méthodes existantes dans chaque ensemble de données, ils ont découvert ce qui suit :
Tout d'abord, les chercheurs ont affiné l'agent grâce à diverses méthodes pour améliorer sa flexibilité. Dans la cinquième figure, outre les résultats quantitatifs, les chercheurs montrent également deux exemples de problèmes pour illustrer les avantages du réglage fin multi-méthodes. La première question était relativement simple, mais l'agent, optimisé en utilisant uniquement ReAct, a recherché une requête trop complexe, provoquant une distraction et fournissant des réponses incorrectes. En revanche, l’agent optimisé à l’aide de CoT et de ReAct a choisi de s’appuyer sur ses connaissances internes et a accompli la tâche en toute confiance en un seul tour. Le deuxième problème est plus complexe : l’agent optimisé en utilisant uniquement ReAct n’a pas réussi à trouver d’informations utiles. En revanche, l’agent qui a utilisé à la fois les réglages précis de Reflexion et de ReAct a réfléchi lorsqu’il a rencontré un dilemme et a modifié sa stratégie de recherche, obtenant finalement la bonne réponse. La possibilité de choisir des solutions flexibles pour traiter différents problèmes constitue un avantage clé de FireAct par rapport aux autres méthodes de réglage fin.

Deuxièmement, l'utilisation de plusieurs méthodes pour affiner différents modèles de langage aura des impacts différents. Comme le montre le tableau 4, l'utilisation de plusieurs agents combinés pour un réglage fin ne conduit pas toujours à des améliorations, et la combinaison optimale de méthodes dépend du modèle de langage sous-jacent. Par exemple, ReAct+CoT surpasse ReAct pour les modèles GPT-3.5 et Llama-2, mais pas pour le modèle CodeLlama. Pour CodeLlama7/13B, ReAct+CoT+Reflexion a donné les pires résultats, mais CodeLlama-34B a obtenu les meilleurs résultats. Ces résultats suggèrent que des recherches supplémentaires sur l'interaction entre les modèles de langage sous-jacents et les données de réglage fin sont nécessaires.
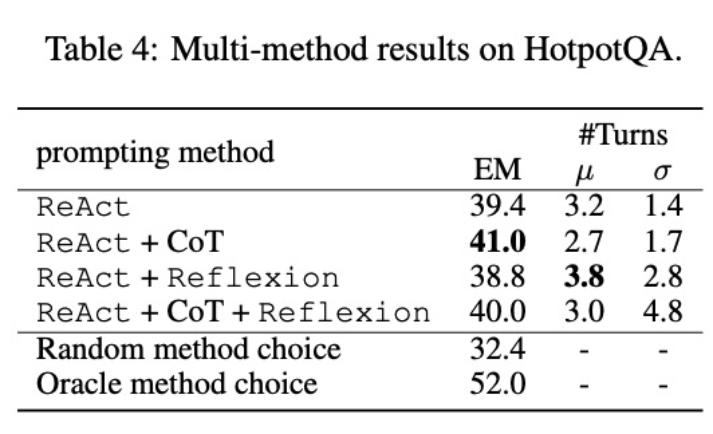
Pour mieux comprendre si un agent qui combine plusieurs méthodes est capable de sélectionner une solution appropriée en fonction de la tâche, les chercheurs ont calculé le score de sélection aléatoire des méthodes au cours du processus d'inférence. Ce score (32,4) est bien inférieur à celui de tous les agents ayant combiné plusieurs méthodes, ce qui indique que choisir une solution n'est pas une tâche facile. Cependant, la meilleure solution par instance n'a également obtenu qu'un score de 52,0, ce qui indique qu'il reste encore place à l'amélioration dans la sélection de la méthode d'invite.
3. Utilisez plusieurs méthodes pour affiner plusieurs tâches
Jusqu'à présent, le réglage fin n'utilisait que les données HotpotQA, mais des études empiriques sur le réglage fin LM montrent qu'il y a des avantages à mélanger différentes tâches. Les chercheurs ont affiné GPT-3.5 en utilisant des données d'entraînement mixtes provenant de trois ensembles de données : HotpotQA (500 échantillons ReAct, 277 échantillons CoT), StrategyQA (388 échantillons ReAct, 380 échantillons CoT) et MMLU (456 échantillons ReAct), 469 échantillons CoT. ).
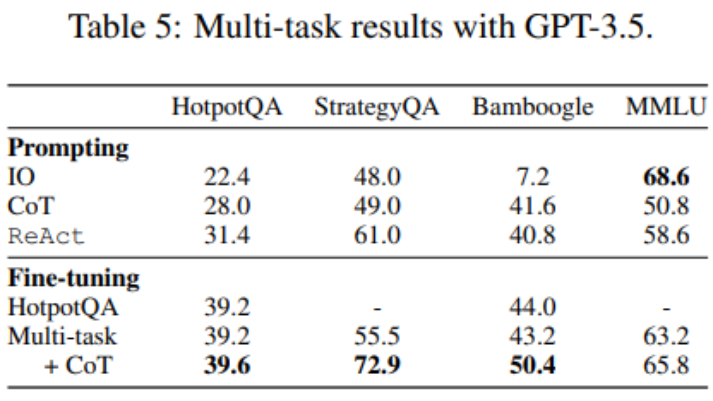
Comme le montre le tableau 5, après avoir ajouté les données StrategyQA/MMLU, les performances de HotpotQA/Bamboogle restent presque inchangées. D'une part, les pistes StrategyQA/MMLU contiennent des questions et des stratégies d'utilisation des outils très différentes, ce qui rend la migration difficile. D'un autre côté, malgré le changement de distribution, l'ajout de StrategyQA/MMLU n'a pas affecté les performances de HotpotQA/Bamboogle, ce qui indique que le réglage fin d'un agent multitâche pour remplacer plusieurs agents monotâches est une orientation future possible. Lorsque les chercheurs sont passés d’un réglage fin multi-tâches et d’une seule méthode à un réglage fin multi-tâches et multi-méthodes, ils ont constaté des améliorations de performances dans toutes les tâches, clarifiant une fois de plus la valeur du réglage fin des agents multi-méthodes.
Pour plus de détails techniques, veuillez lire l'article original.
Lien de référence :
- https://twitter.com/Tisoga/status/1739813471246786823
- https://www.zhihu.com/people/eyew3g
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment réparer srttrail.txt
- Microsoft Solitaire Collection peut-il être désinstallé ?
- Que signifie l'ordinateur principal ?
- Quelle est la stratégie de développement de l'intelligence artificielle ?
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?