
Maison >Tutoriel système >Linux >Comment utiliser les modes spéciaux BEGIN et END d'awk pour le traitement
Comment utiliser les modes spéciaux BEGIN et END d'awk pour le traitement

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-01-02 18:06:071091parcourir
Dans la huitième section de la série awk, nous avons introduit quelques puissantes fonctionnalités de commande awk, qui sont des variables, des expressions numériques et des opérateurs d'affectation.
Dans cette section, nous en apprendrons davantage sur les fonctions d'awk, à savoir les modes spéciaux d'awk : BEGIN et END.
Au fur et à mesure que nous progressons et découvrons d'autres façons de créer des opérations awk complexes, nous prouverons à quel point ces fonctionnalités spéciales d'awk sont puissantes.
Avant de commencer, passons en revue l'introduction de la série awk. Rappelez-vous que lorsque nous avons commencé cette série, j'ai souligné que la syntaxe générale de l'instruction awk est la suivante :
# awk 'script' filenames
Dans la syntaxe ci-dessus, le script awk a cette forme :
/pattern/ { actions }
Vous constaterez généralement que le modèle dans les scripts (/pattern) est une expression régulière, mais vous pouvez également utiliser les modèles spéciaux BENGIN et END ici. Par conséquent, nous pouvons également écrire une commande awk sous la forme suivante :
awk '
BEGIN { actions }
/pattern/ { actions }
/pattern/ { actions }
……….
END { actions }
' filenames
Si vous utilisez des modes spéciaux dans le script awk : BEGIN et END, voici leurs significations correspondantes :
-
Mode
- BEGIN : signifie que awk effectuera l'action spécifiée dans BEGIN immédiatement avant de lire les lignes d'entrée. Mode
- END : signifie que awk exécutera l'action spécifiée dans END avant sa sortie officielle.
Le flux d'exécution des scripts de commande awk contenant ces modes spéciaux est le suivant :
- Lorsque le modèle BEGIN est utilisé dans un script, toutes les actions dans BEGIN seront exécutées avant la lecture des lignes d'entrée.
- Ensuite, une ligne d'entrée est lue et analysée en différents segments.
- Ensuite, chaque modèle non spécial spécifié sera comparé et mis en correspondance avec la ligne d'entrée. Lorsque la correspondance est réussie, l'action correspondant au modèle sera exécutée. Répétez cette étape pour tous les modèles que vous spécifiez.
- Ensuite, répétez les étapes 2 et 3 pour toutes les lignes d'entrée.
- Une fois que toutes les lignes de saisie ont été lues et traitées, si vous spécifiez le mode END, l'action correspondante sera effectuée.
Lorsque vous utilisez des modes spéciaux, pour obtenir les meilleurs résultats des opérations awk, vous devez vous rappeler l'ordre d'exécution ci-dessus.
Pour faciliter la compréhension, utilisons l'exemple de la section 8 à des fins de démonstration. Cet exemple concerne la liste des noms de domaine appartenant à Tecmint et enregistrés dans un fichier appelé domains.txt.
news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com news.tecmint.com tecmint.com linuxsay.com tecmint.com news.tecmint.com tecmint.com linuxsay.com windows.tecmint.com tecmint.com
$ cat ~/domains.txt
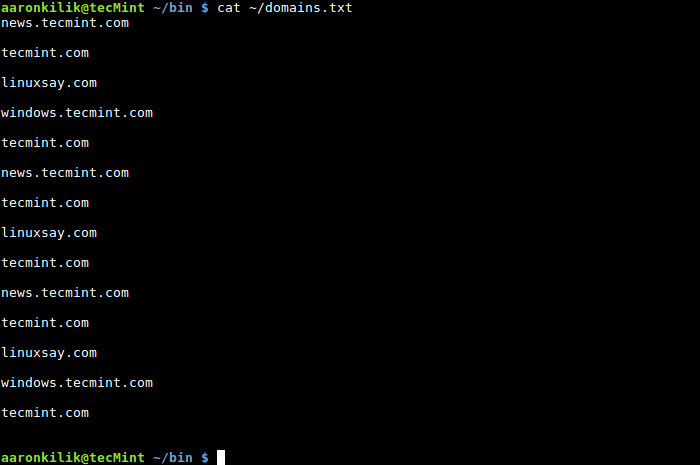
Dans cet exemple, nous voulons compter le nombre de fois que le nom de domaine tecmint.com apparaît dans le fichier domains.txt. Nous avons donc écrit un simple script shell pour nous aider à accomplir la tâche, qui utilise les idées de variables, d'expressions mathématiques et d'opérateurs d'affectation. Le contenu du script est le suivant :
.#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出一个递增的数字记录包含 tecmint.com 的行数
awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
Appliquons maintenant ces deux modes spéciaux dans la commande awk du script ci-dessus comme ci-dessous : BEGIN et END :
Nous devrions mettre le script :
awk '/^tecmint.com/ { counter+=1 ; printf "%s/n", counter ; }' $file
Changé en :
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s/n", counter ; }
' $file
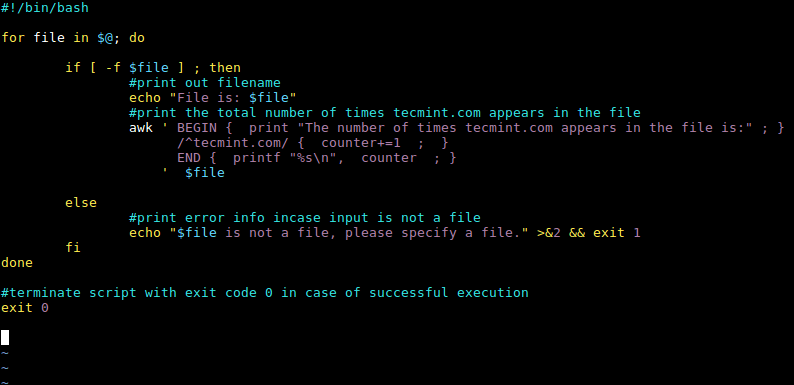
在修改了 awk 命令之后,现在完整的 shell 脚本就像下面这样:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出文件中 tecmint.com 出现的总次数
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s/n", counter ; }
' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式 BEGIN 将会在从文件读取任何行之前帮助我们输出这样的消息“文件中出现 tecmint.com 的次数是: ”。
接下来,我们的模式/^tecmint.com/ 会在每个输入行中进行比较,对应的动作{ counter+=1 ; } 会在每个匹配成功的行上执行,它会统计出 tecmint.com 在文件中出现的次数。
最终,END 模式将会输出域名 tecmint.com 在文件中出现的总次数。
$ ./script.sh ~/domains.txt

最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式 BEGIN 和 END 的概念。
正如我之前所言,这些 awk 功能将会帮助我们构建出更复杂的文本过滤操作。第十节将会给出更多的 awk 功能,我们将会学习 awk 内置变量的思想,所以,请继续保持关注。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!