
Maison >Périphériques technologiques >IA >En combinant le modèle de diffusion avec NeRF, Tsinghua Wensheng a proposé une nouvelle méthode 3D pour réaliser SOTA
En combinant le modèle de diffusion avec NeRF, Tsinghua Wensheng a proposé une nouvelle méthode 3D pour réaliser SOTA

- 王林avant
- 2024-01-02 16:52:351432parcourir
Le modèle d'IA qui utilise du texte pour synthétiser des graphiques 3D a un nouveau SOTA !
Récemment, le groupe de recherche du professeur Liu Yongjin de l'Université Tsinghua a proposé une nouvelle méthode de Wensheng 3D basée sur un modèle de diffusion.
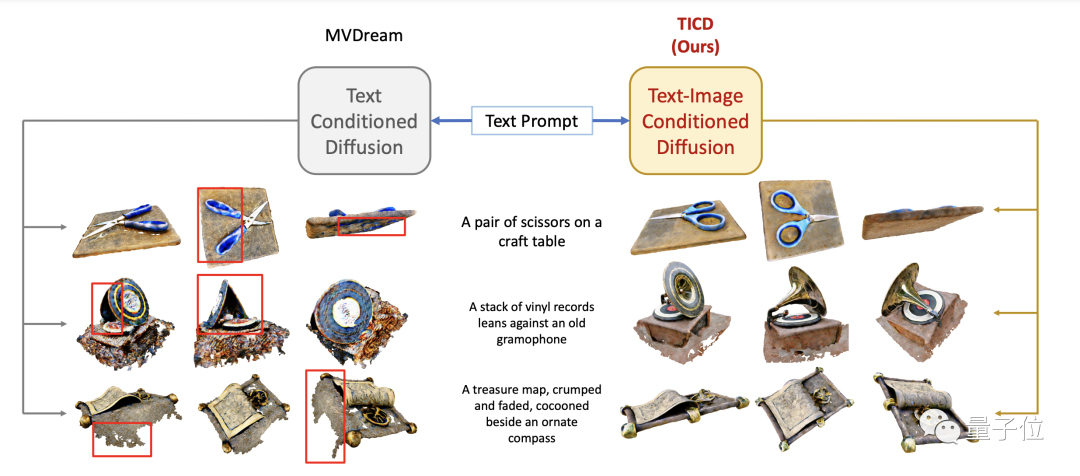
La cohérence entre les différents angles de vue et la correspondance avec les mots d'invite ont été grandement améliorées par rapport à avant.
 Photos
Photos
Vincent 3D est un contenu de recherche brûlant de 3D AIGC et a reçu une large attention de la part du monde universitaire et de l'industrie.
Le nouveau modèle proposé par l’équipe de recherche du professeur Liu Yongjin s’appelle TICD (Text-Image Conditioned Diffusion), qui a atteint le niveau SOTA sur l’ensemble de données T3Bench.
Des articles pertinents ont été publiés et le code sera bientôt open source.
Les résultats de l'évaluation ont atteint SOTA
Afin d'évaluer l'effet de la méthode TICD, l'équipe de recherche a d'abord mené des expériences qualitatives et comparé certaines meilleures méthodes précédentes.
Les résultats montrent que les graphiques 3D générés par la méthode TICD ont une meilleure qualité, des graphiques plus clairs et un degré plus élevé de correspondance avec les mots d'invite.
 Photos
Photos
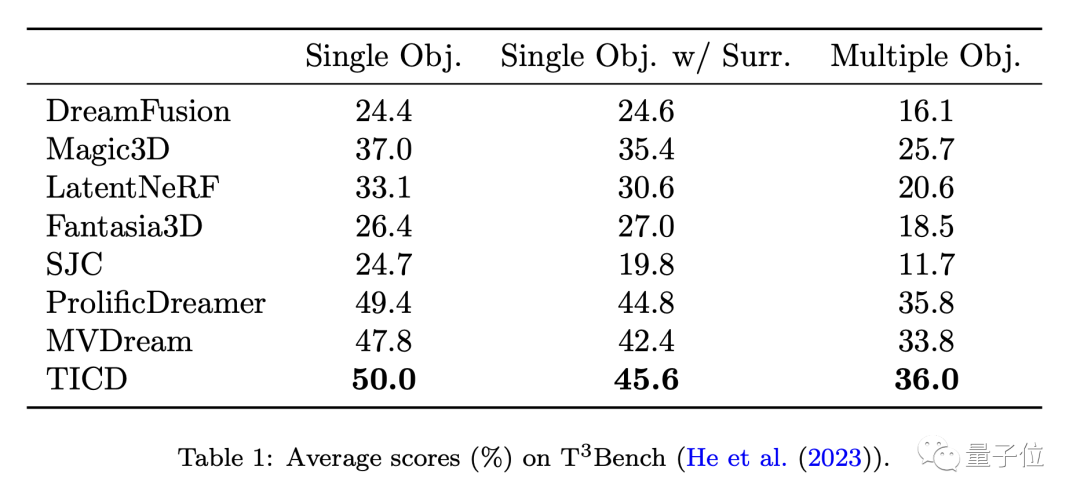
Pour évaluer davantage les performances de ces modèles, l'équipe a testé quantitativement TICD avec ces méthodes sur l'ensemble de données T3Bench.
Les résultats montrent que TICD a obtenu les meilleurs résultats dans les trois ensembles d'invites d'objet unique, d'objet unique avec arrière-plan et d'objets multiples, prouvant ainsi ses avantages globaux en termes de qualité de génération et d'alignement du texte.
 Images
Images
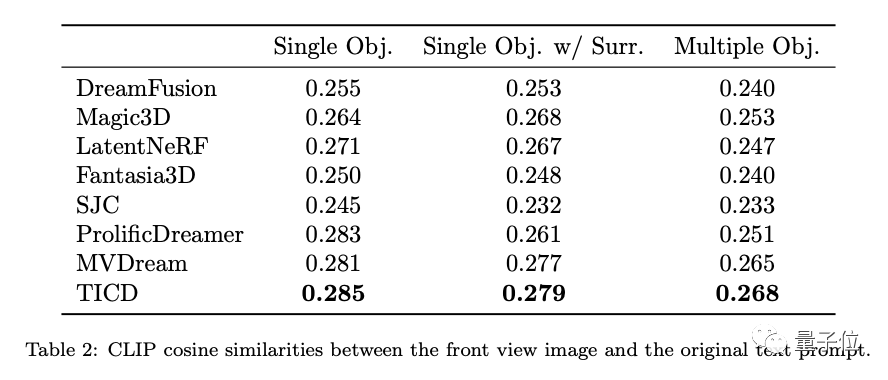
De plus, afin d'évaluer davantage l'alignement du texte de ces modèles, l'équipe de recherche a également testé la similitude cosinus CLIP entre les images rendues par l'objet 3D et les mots d'invite d'origine, et les résultats ont été toujours les performances de TICD optimales.
Alors, comment la méthode TICD parvient-elle à obtenir un tel effet ?
Incorporez préalablement la cohérence multi-vues dans la supervision NeRF
Les méthodes de génération de texte 3D actuellement courantes utilisent principalement des modèles de diffusion 2D pré-entraînés pour générer en optimisant le champ de rayonnement neuronal (NeRF) via un tout nouveau modèle 3D d'échantillonnage par distillation de score (SDS).
Cependant, la supervision fournie par ce modèle de diffusion pré-entraîné est limitée au texte d'entrée lui-même, et ne contraint pas la cohérence entre plusieurs vues, et peut causer des problèmes tels qu'une mauvaise génération de structures géométriques.
Pour introduire une cohérence multi-vues dans l'avant des modèles de diffusion, certaines études récentes affinent les modèles de diffusion 2D en utilisant des données multi-vues, mais manquent toujours d'une continuité fine entre les vues.
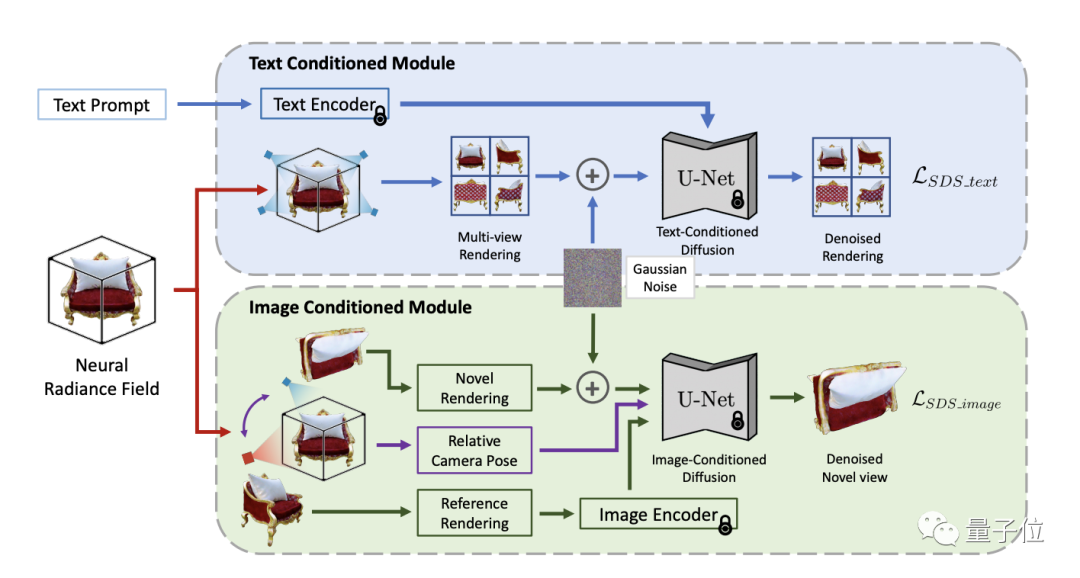
Afin de résoudre ce défi, la méthode TICD intègre des images multi-vues conditionnées en texte et en image dans le signal de supervision optimisé par NeRF, assurant respectivement l'alignement des informations 3D et des mots d'invite et la forte corrélation entre les différentes vues de Objets 3D. La cohérence améliore efficacement la qualité des modèles 3D générés.
 Images
Images
Dans le flux de travail, TICD échantillonne d'abord plusieurs ensembles de perspectives de caméra de référence orthogonales, utilise NeRF pour restituer les vues de référence correspondantes, puis applique un modèle de diffusion conditionnelle basé sur du texte à ces vues de référence pour contraindre le contenu et cohérence globale du texte.
Sur cette base, sélectionnez plusieurs ensembles de perspectives de caméra de référence et restituez une vue à partir d'une nouvelle perspective supplémentaire pour chaque perspective. Ensuite, la relation de pose entre les deux vues et perspectives est utilisée comme nouvelle condition, et un modèle de diffusion conditionnelle basé sur l'image est utilisé pour contraindre la cohérence des détails entre les différentes perspectives.
En combinant les signaux de supervision des deux modèles de diffusion, TICD peut mettre à jour les paramètres du réseau NeRF et les optimiser de manière itérative jusqu'à ce que le modèle NeRF final soit obtenu et restitue un contenu 3D de haute qualité, géométriquement clair et cohérent avec le texte.
De plus, la méthode TICD peut éliminer efficacement des problèmes tels que la disparition d'informations géométriques, la génération excessive d'informations géométriques incorrectes et la confusion des couleurs qui peuvent survenir lorsque les méthodes existantes sont confrontées à une saisie de texte spécifique.
Adresse papier : https://www.php.cn/link/8553adf92deaf5279bcc6f9813c8fdcc
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que le modèle de données relationnelles
- Comment construire un modèle mathématique en utilisant Python
- Fonctions du modèle TCP/IP à quatre couches
- Est-il prévu de remplacer Deepfake ? Révéler à quel point la technologie NeRF la plus populaire de cette année est géniale
- Obtenir un rendu urbain à très grande échelle, efficace et réaliste : en combinant la technologie NeRF et la technologie de grille de fonctionnalités