
Maison >Tutoriel système >Linux >Conseils de récupération de données MySQL à l'aide de fichiers ibd ?
Conseils de récupération de données MySQL à l'aide de fichiers ibd ?

- PHPzavant
- 2024-01-02 10:42:091649parcourir
| Présentation | Les secteurs de disque défectueux, les pannes de courant et autres accidents ne sont pas normaux, mais si vous les rencontrez, ils suffiront à vous « exciter » ! Que dois-je faire si les données sont perdues en raison d'un dommage à la base de données et que Binlog n'est plus disponible ? Afin de restaurer les données sans perte en peu de temps afin d'assurer la stabilité de l'entreprise, en plus d'utiliser binlog, nous avons également mis en pratique une nouvelle compétence de récupération ! |
Vous vous souvenez de ce que nous avons écrit précédemment : « Juste une astuce pour que la R&D incontrôlable tombe amoureuse de vous » ? Comme mentionné précédemment, les deux méthodes de récupération de bases de données que nous utilisons le plus au quotidien sont :
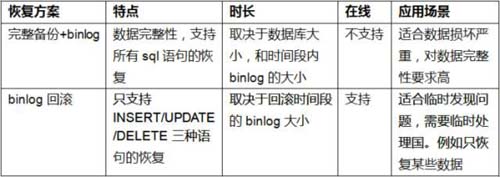
Les deux méthodes ci-dessus peuvent réaliser une restauration en temps réel, mais pensez-vous qu'avoir ces deux compétences est suffisant ?
Non….!
Dans cette architecture en ligne complexe, il existe en réalité de nombreuses raisons inconnues que nous ne pouvons pas prédire. Par exemple :
La durée de vie du disque due à un travail acharné développe des secteurs défectueux, endommageant la base de données. Et cela a endommagé le fichier ibdata et le fichier binlog. Donc, si vous réfléchissez toujours à la solution de sauvegarde planifiée + récupération du journal binaire, c'est impossible. Pouvez-vous utiliser uniquement une sauvegarde à virgule fixe pour restaurer ? Après mûre réflexion, en tant que personnel d'exploitation et de maintenance, nous ne mettrons jamais en œuvre une restauration avec perte en dernier recours, car cela aura un impact important sur l'entreprise, mais que pouvons-nous faire d'autre ? Ensuite, nous allons sortir un grand mouvement ! ! !
Vérifiez d'abord l'environnement de la base de données pour voir si l'espace table indépendant est activé. S'il a été activé, félicitations, il y a de grandes chances que toutes les données puissent être récupérées. Nous pouvons compter sur les fichiers frm et ibd dans chaque répertoire de base de données pour réaliser la récupération des données. De manière générale, si InnoDB est utilisé mais que l'espace table indépendant n'est pas activé, toutes les informations et métadonnées des tables de base de données seront écrites dans le fichier ibdata. pendant une longue période. S'il est exécuté, le fichier ibdata deviendra de plus en plus volumineux et les performances de la base de données diminueront. InnoDB fournit le paramètre permettant d'activer un espace table indépendant, ce qui permet de stocker les données indépendamment. De cette manière, le fichier ibdata n'est utilisé que pour stocker certaines informations d'index liées au moteur, et les données réelles sont écrites dans des fichiers frm et ibd indépendants.
D'accord, avec les fichiers frm et ibd, nous pouvons commencer à essayer la récupération de données. Le processus est plus passionnant et intéressant que la restauration de binlog ! Tout d’abord, jetons un coup d’œil aux instructions concernant ibd et frm :
Fichier.frm : Enregistre les métadonnées de chaque table, y compris la définition de la structure de la table, etc. Ce fichier n'a rien à voir avec le moteur de base de données.
Fichier .ibd : Le fichier généré par le moteur InnoDB lorsque l'espace table indépendant est activé (innodb_file_per_table = 1 est configuré dans my.ini) pour stocker les données et les index de la table.
Nous savons tous que pour la base de données InnoDB, si vous ne copiez pas l'intégralité du répertoire de données, mais copiez uniquement le répertoire de base de données spécifié dans la nouvelle instance, la base de données ne sera pas reconnue. Alors comment restaurer la base de données à partir de ces deux fichiers ?
Idées de récupération :Étant donné que certaines informations d'index sur le moteur sont stockées dans le fichier ibdata, le fichier ibdata est endommagé, entraînant la perte de l'index du nom de table et l'impossibilité de démarrer. Ensuite, nous pouvons d'abord renommer l'intégralité de l'ancien répertoire de données et le sauvegarder, puis réinitialiser la base de données pour générer un nouveau fichier ibdata, puis recréer la base de données d'origine et les tables correspondantes, et enfin modifier le numéro d'ID de l'espace table de sauvegarde en numéro d'ID du nouvel espace table (le fichier ibdata contient un ID d'index d'espace table unique pour chaque table, qui est incrémenté du nombre de nouvelles tables créées), afin que la base de données d'origine puisse être restaurée.
Par exemple :
Nom de la bibliothèque : test_restore
Structure du tableau : db_struc.sql
Fichiers de table : G_RESTORE.ibd, G_RESTORE.frm
#mysql -uroot –p**** -e « créer une base de données test_restore »
#mysql -uroot –p**** test_restore 2. Affichez et modifiez l'identifiant de la table dans la bibliothèque test_restore dans la nouvelle instance
#vim -b /data/database/mysql/test_restore/G_RESTORE.ibd
Ouvrez-le directement sous forme de caractères tronqués et convertissez-le en hexadécimal pour le visualiser. Exécutez :%!xxd dans Vi pour convertir en hexadécimal. Le résultat est :
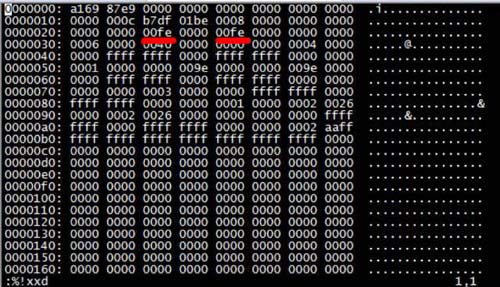 Comme le montre l’image. L'identifiant de la table G_RESTORE dans la base de données MySQL est 00fe.
Comme le montre l’image. L'identifiant de la table G_RESTORE dans la base de données MySQL est 00fe.
Modifiez le fichier G_RESTORE.ibd sauvegardé. L'opération est la même que ci-dessus, mais notez que vous devez d'abord sauvegarder.
#cp G_RESTORE.ibd{,_back}
#vim -v G_RESTORE.ibd
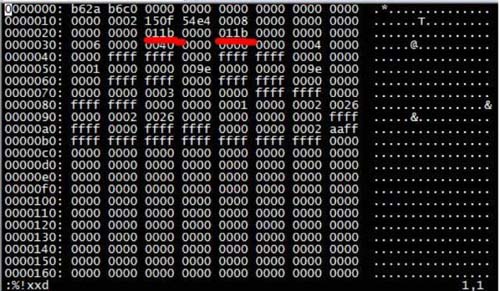 Changez 011b en 00fe. Avis. Une fois la modification terminée, vous devez d'abord l'exécuter dans vim : %!xxd -r
Changez 011b en 00fe. Avis. Une fois la modification terminée, vous devez d'abord l'exécuter dans vim : %!xxd -r
Wq à nouveau pour enregistrer et quitter le fichier. Sinon, le résultat enregistré est la vue hexadécimale.
Enregistrez les résultats comme suit :
Remplacez le fichier G_RESTORE.ibd modifié par le fichier G_RESTORE.ibd dans la nouvelle base de données.
Explication sur l'identifiant de la table ibdata :
参考官方文档解释,每个表空间分配了4个字节存储了表空间id信息,最后偏移量地址为38。还有一组预留的表空间id,同样是4个字节,最后偏移量地址为42。
3. 验证并还原mysql数据关闭mysql。修改my.conf。
innodb_force_recovery=6 innodb_purge_threads=0
启动数据库。如果不修改。数据库会认为G_RESTORE已被损坏。
Select 一下,即可查看到还原结果,但此时插入数据会报错,应尽快将数据dump出来 ,导回原来的实例中。
导出数据,再导入数据,恢复完毕!
#mysqldump -uroot –p****** test_restore > test_restore.sql
#mysql -uroot –p****** test_restore
<p>说明:变更了新的space id后的.ibd表文件,启动数据库后只能认出数据,但不能写入,这是因为原ibdata文件不仅保存了space id索引,还同时保存了一些其它的元数据。为了使元数据补全,所以采取导出、再导入的操作。</p>
<p>以上举例为单个库表的恢复过程,看到这里大家一定会产生另一个疑问吧?线上的场景不可能是只有一个表的,数据库表很多的情况下,这样一个个表的修改,速度无疑是太慢了。那么存在大量表的情况下如何恢复呢?思路是,取得备份的ibd文件的id值,按id值顺序来建表,中间跨度随便建表语句来凑够数(每个表空间索引id由创建新表的数量依次递增)。实现方式如下:</p>
<p><span style="color: #339966;"><strong>1. 获取备份数据库ibd文件的space id号,并排序。</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/
生成的ibd.txt文件,格式如下:(库名–表名–SpaceId)
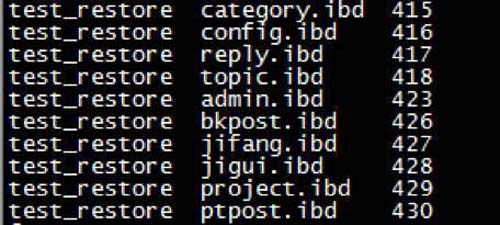
2. 新建表,查看当前表空间id(假设space id为10)
#mysql -uroot –p****** -e”create table test.tt(a bool)”
#hexdump -C mysql/test/tt.ibd |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’
3. 先创建所有库,准备所有表结构,写脚本,依据space id号自动创建新表
准备好数据库表结构,可以从备份文件里取出来(我们备份方式是把结构和数据分开备份的),或者从其他有相同表结构的服务器上备份再拷贝过来。
参考备份语句:
mysqldump -uroot –p****** -d ${db} –T /data/backup/${db}/
创建原有的数据库:
mysql -uroot –p****** -e “create database ${db}”
恢复表id创建表脚本:
#!/bin/bash
#因为前面假设为10,所以从11开始创建
oid=11
#打开前面生成的ibd.txt文件,按行读取”库名–表名–SpaceId”
cat /tmp/ibd.txt | while read db tb id ;do
#假如我们需要恢复catetory表,他的id为415,基于id是创表自增的原则,即415-11=404,
#我们还需要循环创建404个表后,才真正导入catetory表结构。
for ((oid;oid<id do mysql table test.t bool echo ok done let oid="oid+1">
<p><span style="color: #339966;"><strong>4. 检查表空间id 和备份的是否一致</strong></span></p>
<pre class="brush:php;toolbar:false">for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/ibd2.txt
确认一致后,拷贝备份的.ibd文件到新数据库实例目录下,修改my.cnf
innodb_force_recovery=6
innodb_purge_threads=0
启动数据库。后续步骤如同单表恢复,直接导出恢复到原来实例中即可。
当然,这种方式是在数据库出现极端情况下,不得不采取的一种方式,线上最重要的还是做好主从同步和定时备份,从而规避此类风险。
关于InnoDB引擎独立表空间说明:使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构、表索引、表数据空间。我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作。然而当你使用InnoDB的时候,一切都变了。
InnoDB默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。通常只能将数据使用mysqldump导出,然后再导入解决这个问题。
但是可以通过修改MySQL配置文件[mysqld]部分中innodb_file_per_table的参数来开启独立表空间模式,每个数据库的每个表都会生成一个数据空间。
优点:1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
Inconvénients :La table unique est trop grande, par exemple plus de 100 G.
Conclusion :Les espaces de table partagés présentent peu d'avantages dans les opérations d'insertion. D'autres ne fonctionnent pas aussi bien que les espaces table indépendants. Lorsque vous activez des espaces table indépendants, veuillez effectuer les ajustements appropriés : innodb_open_files.
Méthode de configuration :
1.paramètre innodb_file_per_table. Comment l'activer :
Défini sous [mysqld] dans my.cnf
innodb_file_per_table=1
2. Vérifiez s'il est activé :
mysql> affiche des variables comme '%per_table%';
3. Fermez l'espace table exclusif
innodb_file_per_table=0 désactive l'espace table indépendant
mysql> affiche des variables comme « %per_table% » ;
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!