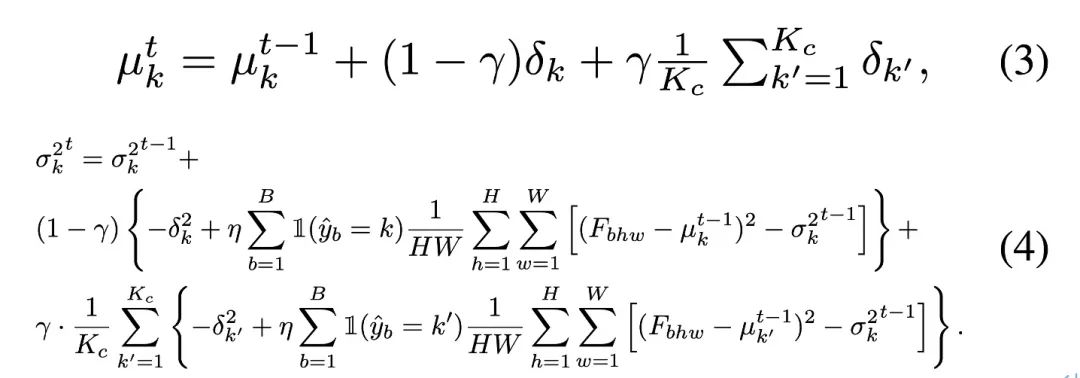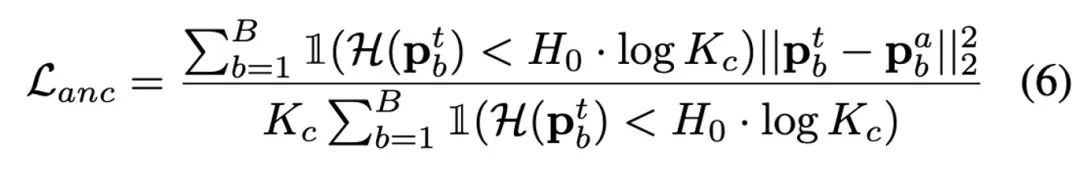Le but de l'adaptation au temps de test est d'adapter le modèle de domaine source aux données de test dans la phase d'inférence et a obtenu d'excellents résultats dans l'adaptation aux champs de dommages d'image inconnus. Cependant, de nombreuses méthodes actuelles ne prennent pas en compte le flux de données de test dans des scénarios réels, par exemple :
- Le flux de données de test doit être une distribution variable dans le temps (plutôt qu'une distribution fixe dans l'adaptation de domaine traditionnelle)
- Le flux de données de test peut avoir une corrélation de classe locale (plutôt qu'un échantillonnage complètement indépendant et distribué de manière identique)
- Le flux de données de test montre encore un déséquilibre de classe global pendant une longue période
Récemment , Université de technologie de Chine du Sud, les équipes A*STAR et CUHK-Shenzhen ont prouvé, à travers un grand nombre d'expériences, que tester les flux de données dans ces scénarios réels poserait d'énormes défis aux méthodes existantes. L’équipe estime que l’échec des méthodes de pointe est d’abord dû à l’ajustement sans discernement de la couche de normalisation sur la base de données de test déséquilibrées. À cette fin, l'équipe de recherche a proposé une couche Balanced BatchNorm innovante pour remplacer la couche de normalisation par lots conventionnelle dans l'étape d'inférence. Dans le même temps, ils ont constaté que s'appuyer uniquement sur l'auto-formation (ST) pour apprendre dans des flux de données de test inconnus peut facilement conduire à une suradaptation (déséquilibre des catégories de pseudo-étiquettes, le domaine cible n'est pas un domaine fixe), ce qui entraîne une mauvaise performance dans un domaine en évolution. Par conséquent, l'équipe recommande de régulariser les mises à jour du modèle via une perte ancrée (Anchored Loss), améliorant ainsi l'auto-formation sous transfert de domaine continu et contribuant à améliorer considérablement la robustesse du modèle. En fin de compte, le modèle TRIBE a atteint de manière stable des performances de pointe avec quatre ensembles de données et plusieurs paramètres de flux de données de test réels, et a largement surpassé les méthodes avancées existantes. Le document de recherche a été accepté par AAAI 2024. 
Lien papier : https://arxiv.org/abs/2309.14949Lien code : https://github.com/Gorilla-Lab-SCUT/TRIBEProfondeur Le succès des réseaux de neurones repose sur la généralisation du modèle formé aux hypothèses i.i.d dans le domaine de test. Cependant, dans les applications pratiques, la robustesse des données de test hors distribution, telles que les dommages visuels causés par des conditions d'éclairage différentes ou des conditions météorologiques extrêmes, constitue une préoccupation. Des recherches récentes montrent que cette perte de données peut sérieusement affecter les performances des modèles pré-entraînés. Il est important de noter que la corruption (distribution) des données de test est souvent inconnue et parfois imprévisible avant le déploiement.
Par conséquent, l'ajustement du modèle pré-entraîné pour s'adapter à la distribution des données de test dans la phase d'inférence est un nouveau sujet précieux, à savoir l'adaptation du domaine temporel de test (TTA). Auparavant, TTA était principalement mis en œuvre via l'alignement de distribution (TTAC++, TTT++), la formation auto-supervisée (AdaContrast) et l'auto-formation (Conjugate PL), qui ont apporté des améliorations significatives et robustes à une variété de données de tests de dommages visuels.
Les méthodes existantes d'adaptation de domaine temporel de test (TTA) sont généralement basées sur des hypothèses strictes en matière de données de test, telles qu'une distribution de classe stable, des échantillons obéissant à un échantillonnage indépendant et identiquement distribué et un décalage de domaine fixe. Ces hypothèses ont inspiré de nombreux chercheurs à explorer les flux de données de test du monde réel, tels que CoTTA, NOTE, SAR et RoTTA.
Récemment, des recherches TTA dans le monde réel, telles que SAR (ICLR 2023) et RoTTA (CVPR 2023), se concentrent principalement sur les défis posés par le déséquilibre des classes locales et le changement continu de domaine vers TTA. Le déséquilibre de classe local résulte généralement du fait que les données de test ne sont pas échantillonnées de manière indépendante et de manière identique. Une adaptation de domaine directe et sans discernement conduira à des estimations de distribution biaisées.
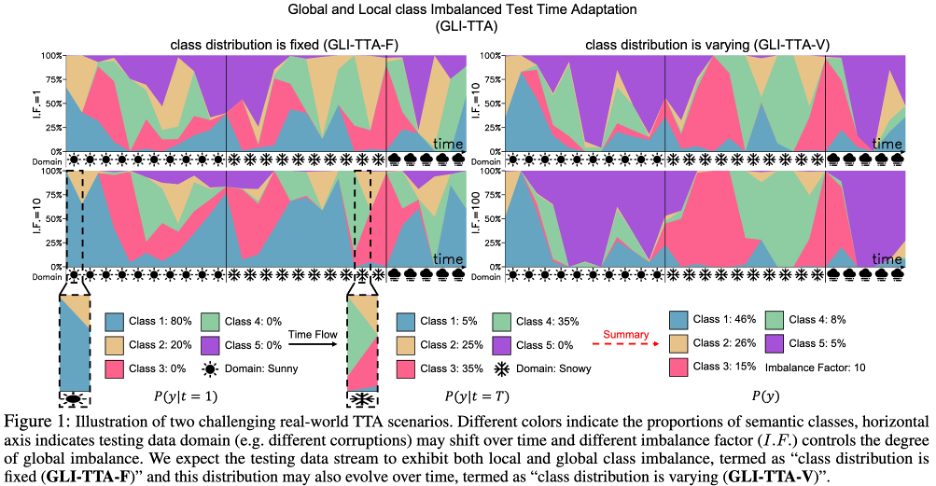
Des recherches récentes ont proposé des statistiques normalisées par lots mises à jour de manière exponentielle (RoTTA) ou des statistiques normalisées par lots mises à jour discriminantes au niveau de l'instance (NOTE) pour résoudre ce défi. L’objectif de la recherche est de transcender le défi du déséquilibre local des classes, en considérant que la répartition globale des données de test peut être gravement déséquilibrée et que la répartition des classes peut également changer au fil du temps. Un diagramme d’un scénario plus difficile peut être vu dans la figure 1 ci-dessous.
Étant donné que la prévalence de la classe dans les données de test est inconnue avant l'étape d'inférence et que le modèle peut être biaisé en faveur de la classe majoritaire via des ajustements de la durée des tests à l'aveugle, cela rend les méthodes TTA existantes inefficaces. Sur la base d'observations empiriques, ce problème devient particulièrement important pour les méthodes qui s'appuient sur le lot de données actuel pour estimer les statistiques globales nécessaires à la mise à jour de la couche de normalisation (BN, PL, TENT, CoTTA, etc.). Cela est principalement dû à : 1. Le lot de données actuel sera affecté par un déséquilibre de classe local, ce qui entraînera une estimation de la distribution globale biaisée ; 2. Sans une distribution mondiale unique, la distribution mondiale peut facilement être biaisée en faveur de la classe majoritaire, provoquant des changements de covariables internes. Afin d'éviter une normalisation par lots (BN) biaisée, l'équipe a proposé une couche de normalisation par lots équilibrée (Balanced Batch Normalization Layer), qui modélise la distribution de chaque catégorie individuelle et extrait la distribution globale de la distribution des classes. La couche de normalisation par lots équilibrés permet d'obtenir des estimations équilibrées en classes des distributions sous des flux de données de test déséquilibrés en classes localement et globalement. Le changement de domaine se produit fréquemment dans les données de test réelles au fil du temps, comme des changements progressifs dans les conditions d'éclairage/météo. Cela pose un autre défi aux méthodes TTA existantes : le modèle TTA peut devenir incohérent lors du passage du domaine A au domaine B en raison d'une suradaptation au domaine A.
Afin d'atténuer la suradaptation à un certain domaine à court terme, CoTTA restaure les paramètres de manière aléatoire et l'EATA utilise les informations des pêcheurs pour régulariser les paramètres. Néanmoins, ces méthodes ne répondent toujours pas explicitement aux défis émergents dans le domaine des données de test.
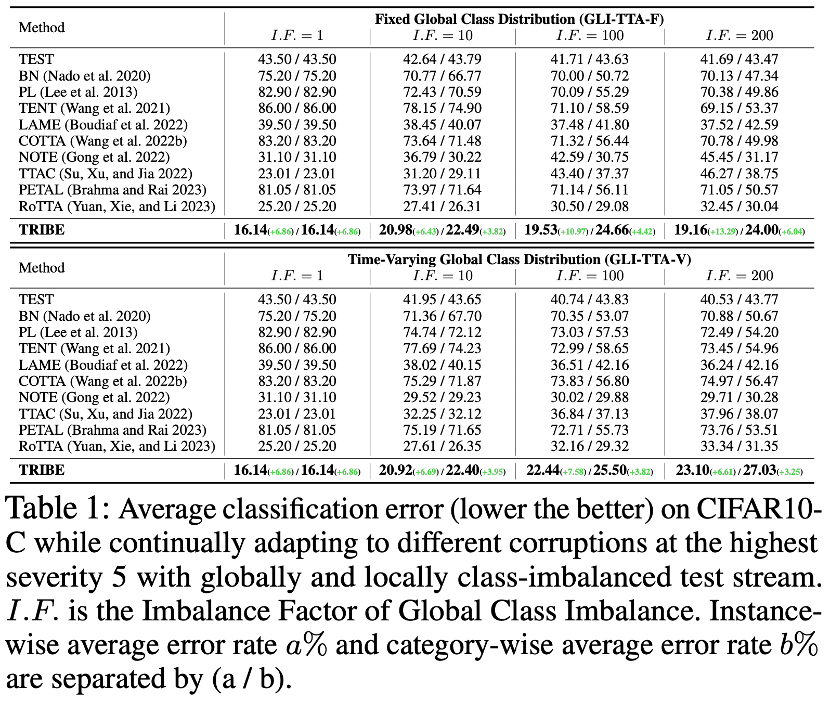
Cet article présente un réseau d'ancrage (Anchor Network) pour former un modèle d'auto-formation à trois réseaux (Tri-Net Self-Training) basé sur l'architecture d'auto-formation à deux branches. Le réseau d'ancrage est un modèle source figé mais permet d'ajuster les statistiques plutôt que les paramètres dans la couche de normalisation par lots via des échantillons de test. Et une perte d'ancrage est proposée pour utiliser la sortie du réseau d'ancrage pour régulariser la sortie du modèle d'enseignant afin d'éviter que le réseau ne s'adapte de manière excessive à la distribution locale.
Le modèle final combine un modèle d'auto-formation à trois réseaux et une couche de normalisation par lots équilibrée (auto-formation TRI-net avec normalisation BalanceEd, TRIBE) pour afficher des performances constamment supérieures dans une gamme plus large de taux d'apprentissage réglables. Il montre des améliorations substantielles des performances sous quatre ensembles de données et plusieurs flux de données du monde réel, démontrant la stabilité et la robustesse uniques.
Introduction à la méthodeLa méthode papier est divisée en trois parties :
- Introduction au protocole TTA dans le monde réel
- Normalisation des lots équilibrés ;
Trois réseaux automatique Entraîner le modèle.
Protocole TTA dans le monde réel
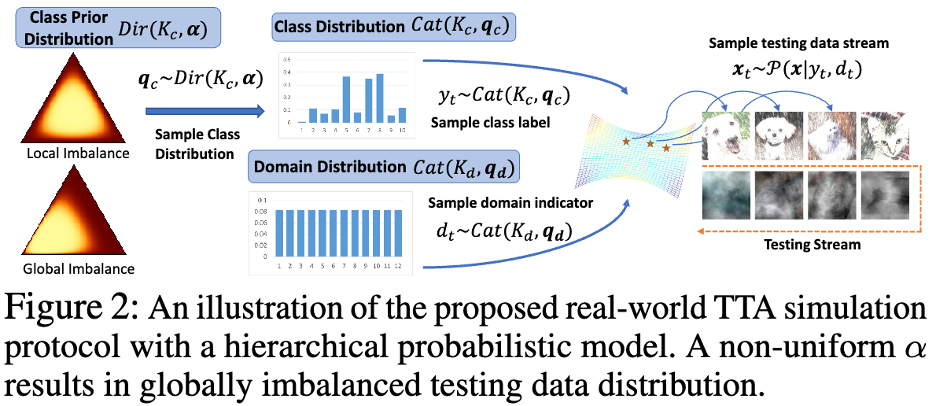
L'auteur a adopté un modèle de probabilité mathématique pour tester les flux de données avec un déséquilibre de classe local et un déséquilibre de classe global dans le monde réel, et Domain la répartition dans le temps est modélisée. Comme le montre la figure 2 ci-dessous.
Normalisation par lots équilibrés
Afin de corriger le biais estimé produit par des données de test déséquilibrées sur la statistique BN, l'auteur propose une couche de normalisation par lots équilibrée pour chaque classe sémantique. respectivement, représentés par : Afin de mettre à jour les statistiques des catégories, l'auteur applique une méthode de mise à jour itérative efficace à l'aide de la prédiction de pseudo-étiquettes, comme indiqué ci-dessous :
Les points d'échantillonnage de chaque catégorie de données sont comptés séparément via des pseudo-étiquettes, et les statistiques de distribution globale sous l'équilibre des catégories sont réobtenues via la formule suivante, de manière à aligner les espaces de fonctionnalités appris avec les données sources équilibrées par catégorie . Dans certains cas particuliers, l'auteur a constaté que lorsque le nombre de catégories est grand ou que la précision du pseudo-étiquette est faible (précision
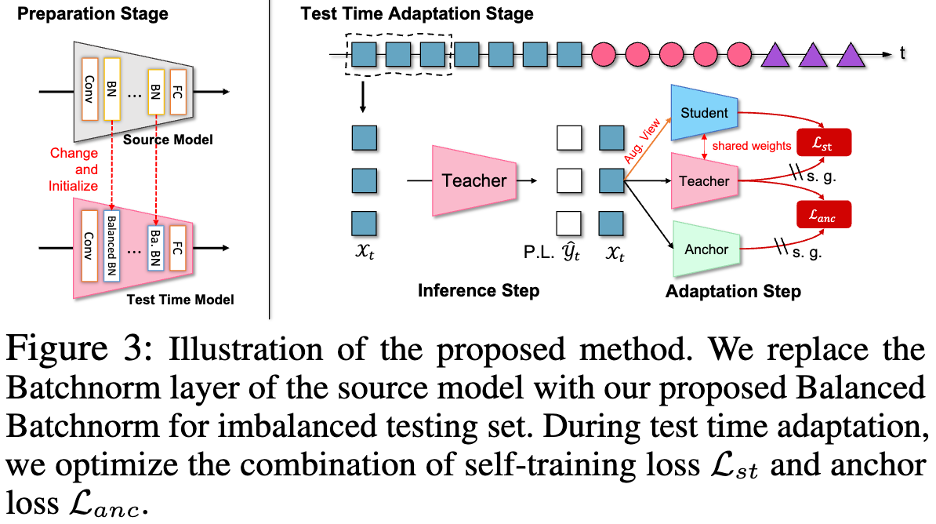
Grâce à une analyse et une observation plus approfondies, l'auteur a constaté que lorsque γ = 1, la mise à jour entière la stratégie dégénère en RoTTA La stratégie de mise à jour de RobustBN dans , lorsque γ = 0, est une stratégie de mise à jour purement indépendante de la catégorie. Par conséquent, lorsque γ prend une valeur de 0 à 1, elle peut être adaptée à diverses situations. Modèle d'auto-formation à trois réseauxBasé sur le modèle étudiant-enseignant existant, l'auteur a ajouté une branche de réseau d'ancrage et introduit une perte d'ancrage pour contraindre le réseau d'enseignants à la distribution prévue. Cette conception est inspirée de TTAC++. TTAC++ souligne que s'appuyer uniquement sur l'auto-formation sur le flux de données de test conduira facilement à l'accumulation de biais de confirmation. Ce problème est plus grave sur le flux de données de test du monde réel dans cet article. TTAC++ utilise les informations statistiques collectées à partir du domaine source pour implémenter la régularisation de l'alignement de domaine, mais pour le paramètre Fully TTA, ces informations sur le domaine source ne sont pas collectables. Dans le même temps, l'auteur a également obtenu une autre révélation. Le succès de l'alignement de domaines non supervisé repose sur l'hypothèse que les deux distributions de domaines ont un taux de chevauchement relativement élevé. Par conséquent, l'auteur a uniquement ajusté le modèle de domaine source gelé de la statistique BN pour régulariser le modèle d'enseignant afin d'éviter que la distribution prédite du modèle d'enseignant ne s'écarte trop de la distribution prédite du modèle source (cela a détruit l'expérience précédente de taux de coïncidence élevé). entre les deux distributions) observation). Un grand nombre d’expériences prouvent que les découvertes et innovations présentées dans cet article sont correctes et robustes. Voici l'expression de la perte d'ancrage :
La figure suivante montre le schéma de trame du réseau TRIBE :
L'auteur de l'article a utilisé 4 données défini sur TRIBE est vérifié à l'aide de deux protocoles TTA du monde réel comme références. Deux protocoles TTA réels sont GLI-TTA-F où la distribution globale des classes est fixe et GLI-TTA-V où la distribution globale des classes n'est pas fixe.
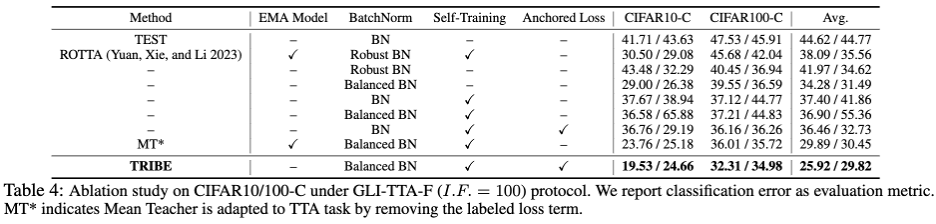
Le tableau ci-dessus montre les performances des deux protocoles dans l'ensemble de données CIFAR10-C sous différents coefficients de déséquilibre. Les conclusions suivantes peuvent être tirées : 1 Uniquement LAME, TTAC, NOTE, RoTTA et TRIBE proposés dans. le document dépasse la ligne de base des TEST, démontre la nécessité d'une méthode TTA plus robuste, sous des flux de tests réels. 2. Le déséquilibre mondial des classes a posé de grands défis aux méthodes TTA existantes. Par exemple, la précédente méthode SOTA, RoTTA, montrait un taux d'erreur de 25,20 % lorsque I.F.=1, mais le taux d'erreur est passé à 25,20 % lorsque I.F.=. 200. 32,45%, en comparaison, TRIBE peut démontrer de manière stable des performances relativement meilleures. 3. La cohérence de TRIBE a un avantage absolu, surpassant toutes les méthodes précédentes, et dépassant le précédent SOTA (TTAC) d'environ 7 % dans le cadre de l'équilibre global des classes (I.F.=1), et dans le plus difficile Dans le contexte d'un déséquilibre global des classes (IF = 200), une amélioration des performances d'environ 13 % a été obtenue. 4. De I.F.=10 à I.F.=200, d'autres méthodes TTA montrent une tendance à la baisse des performances à mesure que le degré de déséquilibre augmente. TRIBE peut maintenir des performances relativement stables. Cela est attribué à l'introduction d'une couche de normalisation par lots équilibrée qui tient mieux compte du grave déséquilibre de classe et de la perte d'ancrage, ce qui évite une adaptation excessive entre différents domaines. Pour plus de résultats sur les ensembles de données, veuillez vous référer à l'article original. De plus, le tableau 4 montre l'ablation modulaire détaillée, avec les conclusions d'observation suivantes :
1 Remplacez uniquement BN par la couche de normalisation par lots équilibrés (Balanced BN), sans mise à jour pour aucun paramètre du modèle, seule la mise à jour des statistiques du BN via forward peut entraîner une amélioration des performances de 10,24 % (44,62 -> 34,28) et dépasser le taux d'erreur du Robust BN de 41,97 %. 2. La perte ancrée combinée à l'auto-formation, que ce soit dans le cadre de la structure BN précédente ou de la dernière structure Balanced BN, a amélioré les performances et dépassé l'effet de régularisation du modèle EMA. Le reste de cet article et l'annexe de 9 pages présentent enfin 17 résultats tabulaires détaillés, démontrant la stabilité, la robustesse et la supériorité de TRIBE dans de multiples dimensions. L'annexe contient également une dérivation théorique plus détaillée et une explication de la couche de normalisation par lots équilibrés. Afin de faire face à de nombreux défis du monde réel tels que le flux de données de test non-i.i.d, le déséquilibre mondial des classes et le transfert de domaine continu, l'équipe de recherche a exploré en profondeur comment. pour améliorer la robustesse des tests des algorithmes d'adaptation dans le domaine temporel. Afin de s'adapter aux données de test déséquilibrées, l'auteur a proposé une couche Balanced Batchnorm pour obtenir une estimation impartiale des statistiques, puis a proposé un réseau qui comprend un réseau d'étudiants, un réseau d'enseignants et une structure de réseau à trois couches pour normaliser. TTA basé sur l’autoformation. Mais cet article présente encore des lacunes et des possibilités d'amélioration. Étant donné qu'un grand nombre d'expériences et de points de départ sont basés sur des tâches de classification et des modules BN, le degré d'adaptation à d'autres tâches et modèles basés sur Transformer est encore inconnu. Ces questions méritent des recherches et une exploration plus approfondies dans le cadre de travaux de suivi.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



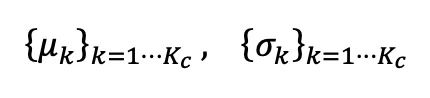 Afin de mettre à jour les statistiques des catégories, l'auteur applique une méthode de mise à jour itérative efficace à l'aide de la prédiction de pseudo-étiquettes, comme indiqué ci-dessous :
Afin de mettre à jour les statistiques des catégories, l'auteur applique une méthode de mise à jour itérative efficace à l'aide de la prédiction de pseudo-étiquettes, comme indiqué ci-dessous : 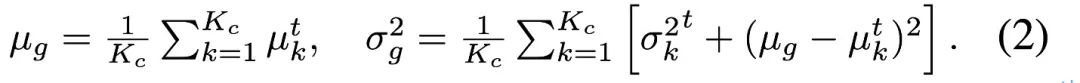
 ou que la précision du pseudo-étiquette est faible (précision
ou que la précision du pseudo-étiquette est faible (précision