
Maison >Périphériques technologiques >IA >Générateur 4090 : par rapport à la plate-forme A100, la vitesse de génération des jetons n'est que inférieure à 18 % et la soumission au moteur d'inférence a remporté de vives discussions
Générateur 4090 : par rapport à la plate-forme A100, la vitesse de génération des jetons n'est que inférieure à 18 % et la soumission au moteur d'inférence a remporté de vives discussions

- 王林avant
- 2023-12-21 15:25:411890parcourir
PowerInfer améliore l'efficacité de l'exécution de l'IA sur du matériel grand public
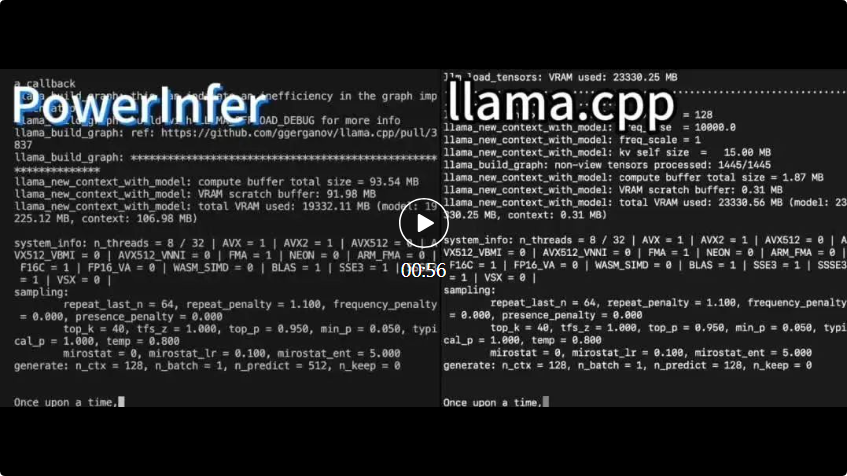 PowerInfer et lama .cpp fonctionnent tous deux sur le même matériel et profitent pleinement de la VRAM du RTX 4090.
PowerInfer et lama .cpp fonctionnent tous deux sur le même matériel et profitent pleinement de la VRAM du RTX 4090. PowerInfer Par rapport au cadre d'inférence LLM avancé local llama.cpp, l'exécution du modèle Falcon (ReLU)-40B-FP16 sur un seul RTX 4090 (24G) permet non seulement d'obtenir une accélération de plus de 11 fois, mais maintient également la précision du modèle
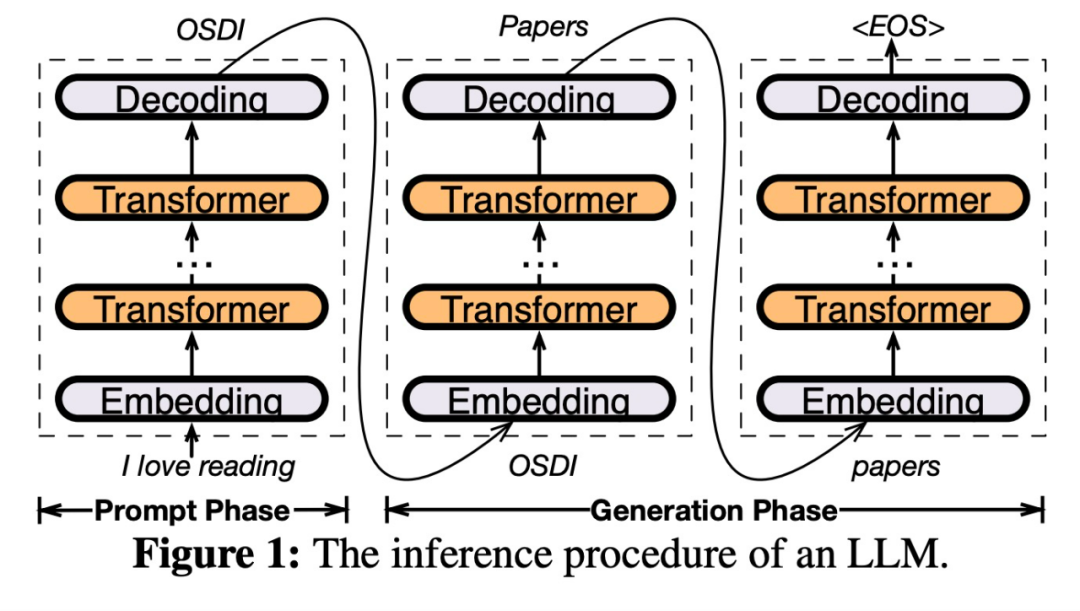
PowerInfer est un moteur d'inférence à grande vitesse conçu pour le déploiement sur site de LLM. Contrairement aux systèmes multi-experts (MoE), PowerInfer a intelligemment conçu un moteur d'inférence hybride GPU-CPU qui exploite pleinement la haute localité de l'inférence LLM
précharge les neurones fréquemment activés (c'est-à-dire activation à chaud) sur le GPU Pour un accès rapide, les neurones qui s'activent rarement (c'est-à-dire les activations à froid) sont calculées sur le processeur. Voici comment cela fonctionne
Cette méthode peut réduire considérablement les besoins en mémoire du GPU et la quantité de transfert de données entre le CPU et le GPU

Lien du projet : https://github.com/SJTU-IPADS/ PowerInfer
-
Lien papier : https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
PowerInfer peut exécuter LLM à grande vitesse sur un PC équipé d'un seul GPU grand public. Les utilisateurs peuvent désormais utiliser PowerInfer avec Llama 2 et Faclon 40B, avec la prise en charge de Mistral-7B bientôt disponible.
En un jour, PowerInfer a obtenu avec succès 2K étoiles
Après avoir vu cette recherche, les internautes ont exprimé leur enthousiasme : désormais une seule carte 4090 peut exécuter de grands modèles de 175B, et non plus seulement Quel rêve
Architecture PowerInfer
La clé de la conception de PowerInfer est d'exploiter le degré élevé de localité inhérent à l'inférence LLM, qui se caractérise par des distributions de lois de puissance dans les activations neuronales. Cette distribution suggère qu'un petit sous-ensemble de neurones, appelés neurones chauds, s'activent de manière cohérente selon les entrées, alors que la majorité des neurones froids varient en fonction des entrées spécifiques. PowerInfer exploite ce mécanisme pour concevoir un moteur d'inférence hybride GPU-CPU.
Veuillez consulter la figure 7 ci-dessous, qui montre un aperçu de l'architecture de PowerInfer, y compris les composants hors ligne et en ligne. Le composant hors ligne est responsable de la gestion de la rareté d’activation du LLM tout en faisant la distinction entre les neurones chauds et froids. Pendant la phase en ligne, le moteur d'inférence charge les deux types de neurones dans le GPU et le CPU et répond aux requêtes LLM avec une faible latence au moment de l'exécution.
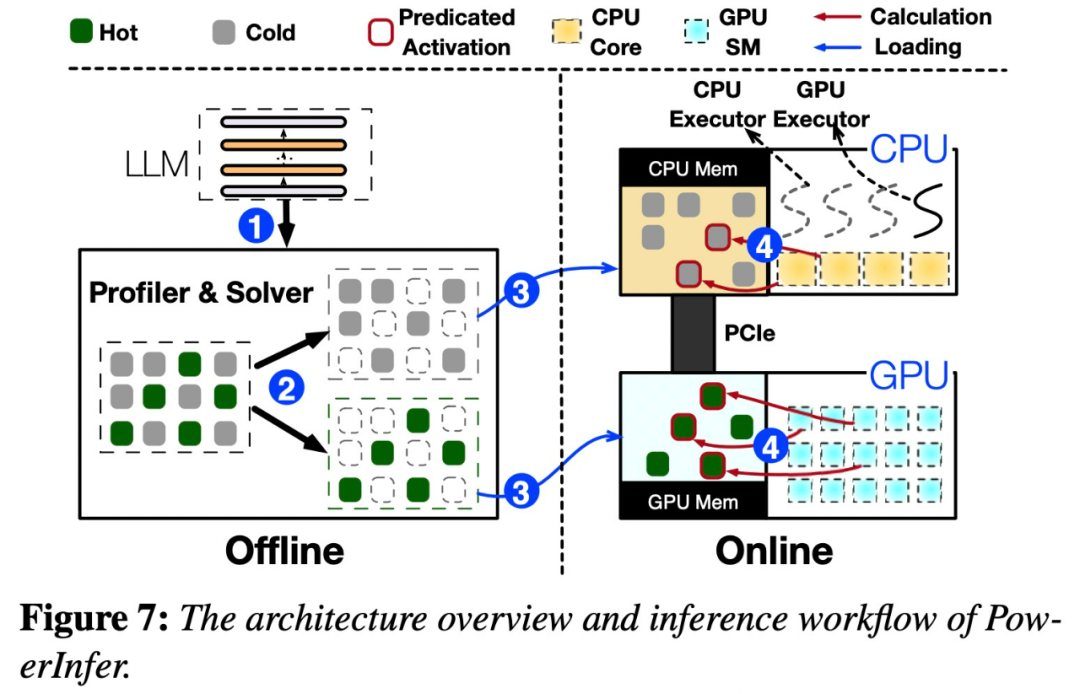
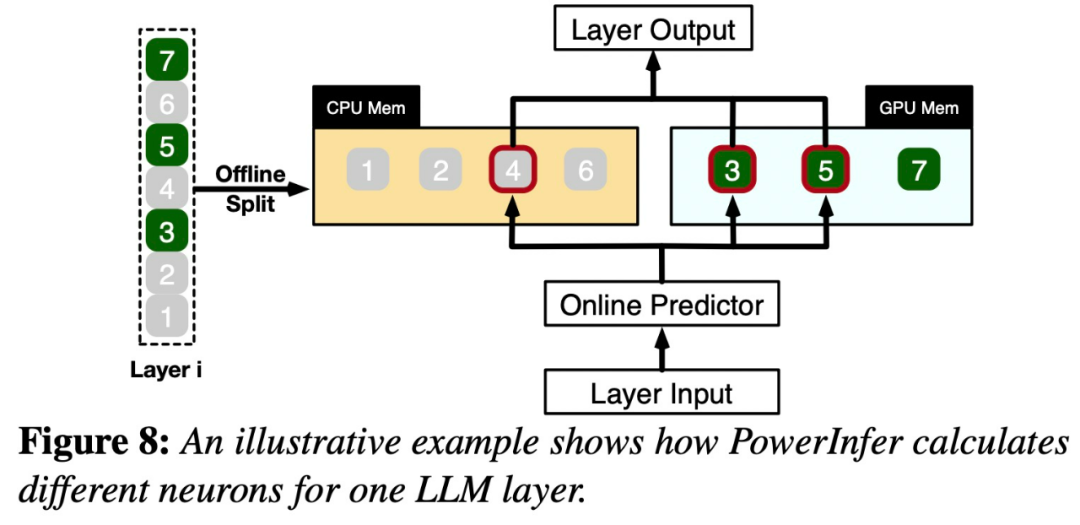
La figure 8 montre le fonctionnement de PowerInfer. Elle coordonne les couches entre le GPU et le CPU. traitement des neurones. PowerInfer classe les neurones via des données hors ligne, attribuant les neurones actifs (tels que les index 3, 5, 7) à la mémoire GPU et d'autres neurones à la mémoire CPU
Une fois l'entrée reçue, le prédicteur identifiera les neurones de la couche actuelle susceptibles d'être activés. Il convient de noter que les neurones activés thermiquement identifiés grâce à une analyse statistique hors ligne peuvent ne pas être cohérents avec le comportement d'activation réel au moment de l'exécution. Par exemple, bien que le neurone 7 soit étiqueté comme activé thermiquement, ce n’est pas le cas en réalité. Le CPU et le GPU traitent ensuite les neurones déjà activés et ignorent ceux qui ne le sont pas. Le GPU est responsable du calcul des neurones 3 et 5, tandis que le CPU gère le neurone 4. Une fois le calcul du neurone 4 terminé, sa sortie sera envoyée au GPU pour l'intégration des résultats
Afin de réécrire le contenu sans changer le sens original, la langue doit être réécrite en chinois. Il n'est pas nécessaire que la phrase originale apparaisse
L'étude a été menée en utilisant le Modèle OPT avec différents paramètres Afin de réécrire le contenu sans changer le sens original, la langue doit être réécrite en chinois. Il n'est pas nécessaire de présenter des phrases originales, les paramètres vont de 6,7B à 175B, et les modèles Falcon (ReLU)-40B et LLaMA (ReGLU)-70B sont également inclus. Il convient de noter que la taille du modèle paramétrique 175B est comparable à celle du Modèle GPT-3.
Cet article compare également PowerInfer avec llama.cpp, un framework d'inférence LLM natif de pointe. Pour faciliter la comparaison, cette étude a également étendu llama.cpp pour prendre en charge le modèle OPT
Étant donné que cet article se concentre sur les paramètres à faible latence, la métrique d'évaluation adopte la vitesse de génération de bout en bout en termes de nombre de jetons générés par seconde (jetons/s) pour la quantification
Cette étude compare d'abord les performances d'inférence de bout en bout de PowerInfer et de lama.cpp avec une taille de lot de 1
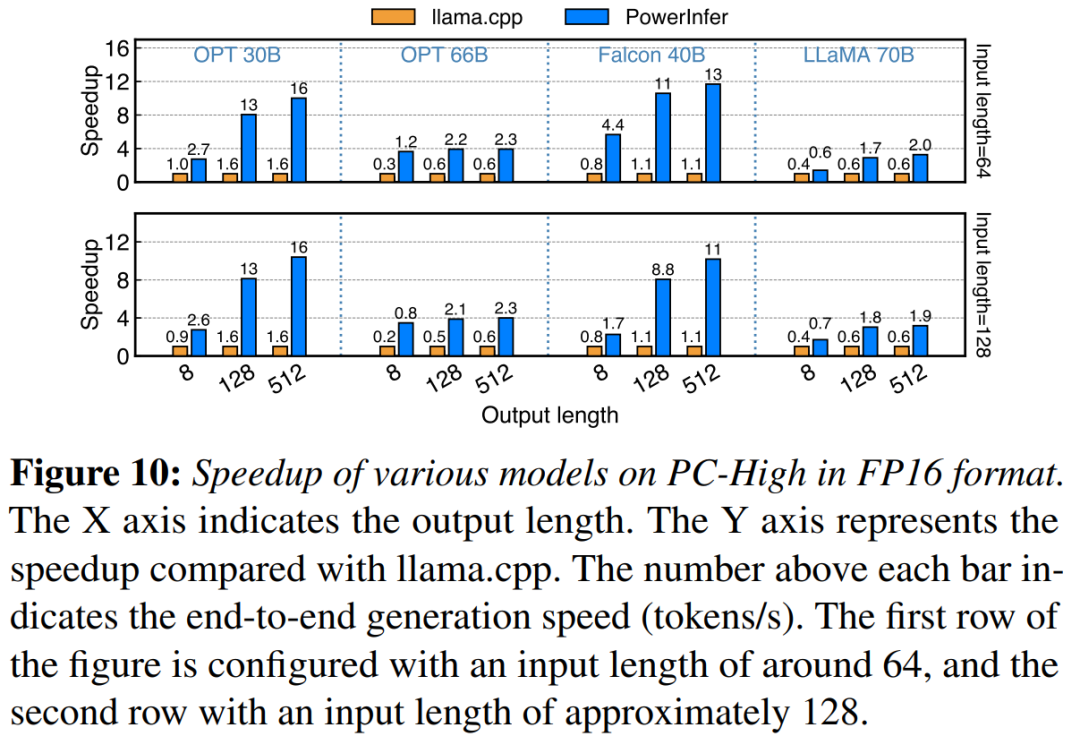
Sur PC-High avec NVIDIA RTX 4090, Figure 10 montre les différents modèles et la vitesse de génération des configurations d’entrée et de sortie. En moyenne, PowerInfer atteint une vitesse de génération de 8,32 jetons/s, avec un maximum de 16,06 jetons/s, ce qui est nettement meilleur que llama.cpp, 7,23 fois supérieur à lama.cpp et 11,69 fois supérieur à Falcon-40B
À mesure que le nombre de jetons de sortie augmente, l'avantage en termes de performances de PowerInfer devient plus évident, car la phase de génération joue un rôle plus important dans le temps d'inférence global. A ce stade, un petit nombre de neurones sont activés à la fois sur le CPU et le GPU, ce qui réduit les calculs inutiles par rapport à llama.cpp. Par exemple, dans le cas de l'OPT-30B, seulement environ 20 % des neurones sont activés par jeton généré, dont la plupart sont traités sur le GPU, ce qui constitue l'avantage de l'inférence basée sur les neurones PowerInfer
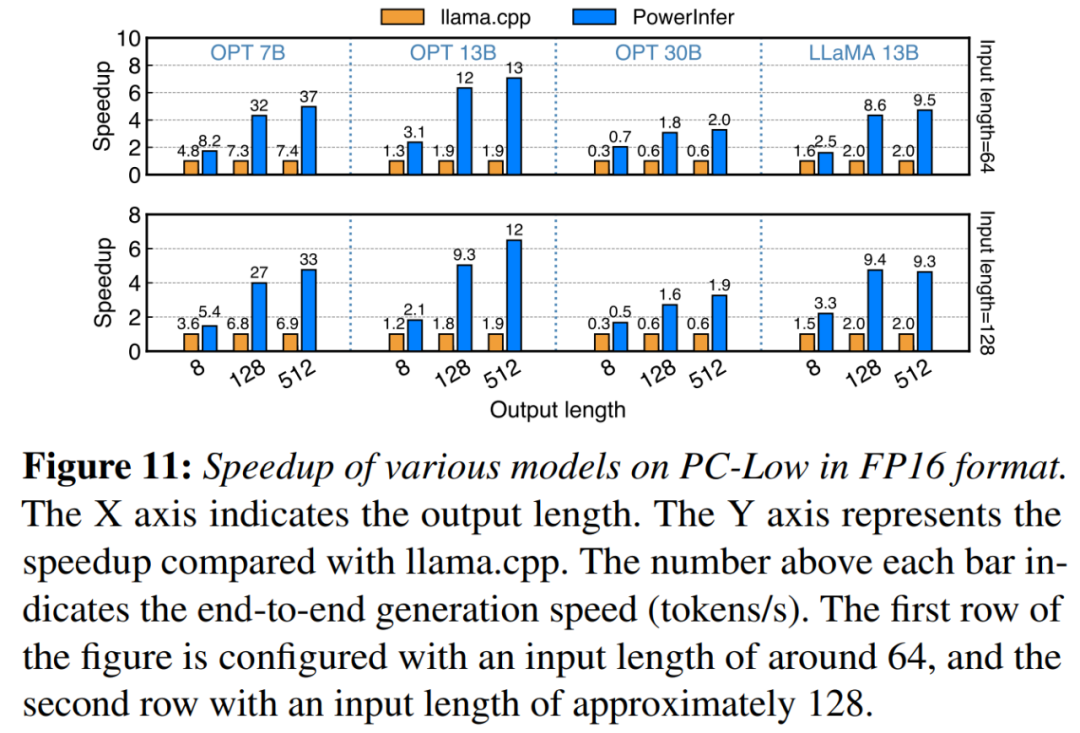
dans la figure 11 Comme le montre la figure, PowerInfer a quand même obtenu des améliorations de performances considérables malgré son fonctionnement sur PC-Low, avec une accélération moyenne de 5,01x et une accélération maximale de 7,06x. Cependant, ces améliorations sont moindres par rapport à PC-High, principalement en raison de la limite de mémoire GPU de 11 Go de PC-Low. Cette limitation affecte le nombre de neurones pouvant être alloués au GPU, en particulier pour les modèles avec environ 30 B de paramètres ou plus, ce qui entraîne une plus grande dépendance à l'égard du processeur pour gérer un grand nombre de neurones activés
La figure 12 montre PowerInfer et Neuron. répartition de la charge entre CPU et GPU entre lama.cpp. Notamment, sur PC-High, PowerInfer augmente considérablement la part de charge neuronale du GPU, d'une moyenne de 20 % à 70 %. Cela montre que le GPU traite 70 % des neurones activés. Cependant, dans les cas où les besoins en mémoire du modèle dépassent de loin la capacité du GPU, comme par exemple l'exécution d'un modèle de 60 Go sur un GPU 2080Ti de 11 Go, la charge neuronale sur le GPU est réduite à 42 %. Cette diminution est due à la mémoire limitée du GPU, qui n'est pas suffisante pour accueillir tous les neurones activés, obligeant ainsi le CPU à en calculer un sous-ensemble

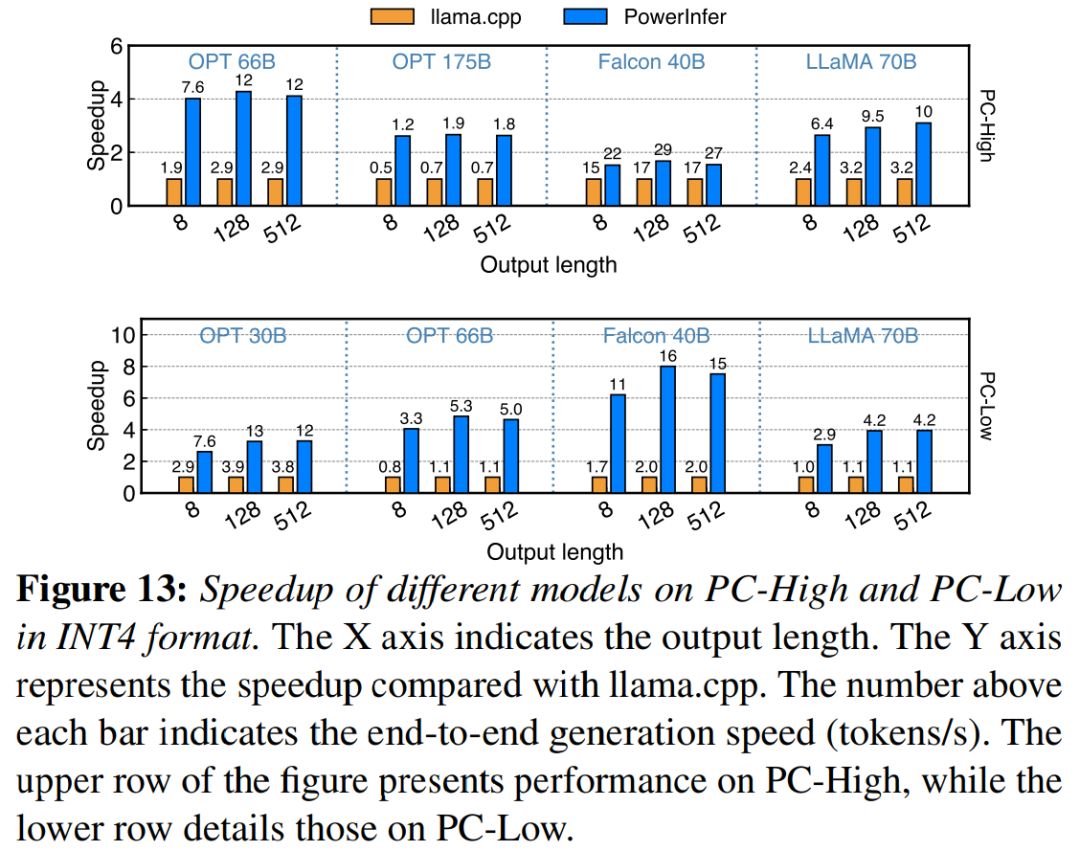
La figure 13 montre que PowerInfer prend efficacement en charge LLM en utilisant la compression de quantification INT4. Sur PC-High, la vitesse de réponse moyenne de PowerInfer est de 13,20 jetons/s, avec une vitesse de réponse maximale de 29,08 jetons/s. Par rapport à llama.cpp, l’accélération moyenne est de 2,89x et l’accélération maximale est de 4,28x. Sur PC-Low, l'accélération moyenne est de 5,01x et le pic est de 8,00x. Les besoins de mémoire réduits dus à la quantification permettent à PowerInfer de gérer plus efficacement des modèles plus grands. Par exemple, l'utilisation du modèle OPT-175B sur PC-High nécessitait de réécrire la langue en chinois afin de réécrire le contenu sans changer le sens original. Sans qu'il soit nécessaire d'apparaître dans la phrase originale, PowerInfer atteint près de deux jetons par seconde, dépassant lama.cpp d'un facteur 2,66.
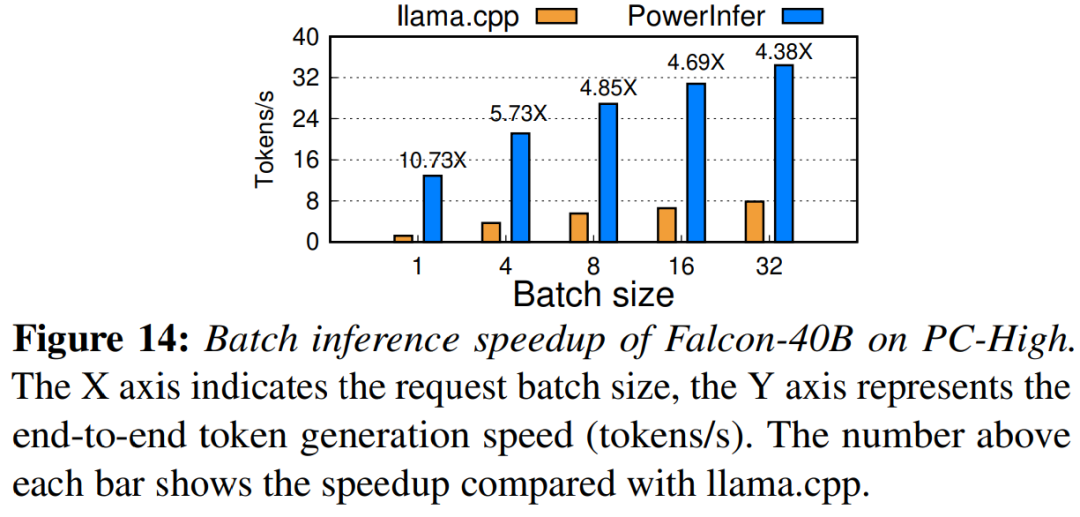
Enfin, l'étude évalue également les performances d'inférence de bout en bout de PowerInfer sous différentes tailles de lots. Comme le montre la figure 14, lorsque la taille du lot est inférieure à 32, PowerInfer présente des avantages significatifs, avec une amélioration moyenne des performances de 6,08 fois par rapport à Llama. À mesure que la taille du lot augmente, l'accélération fournie par PowerInfer diminue. Cependant, même lorsque la taille du lot est définie sur 32, PowerInfer maintient toujours une accélération considérable
Lien de référence : https://weibo.com/1727858283/NxZ0Ttdnz
Veuillez consulter le document original pour en savoir plus. plus de contenu
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!