
Maison >Périphériques technologiques >IA >NVIDIA gifle AMD en plein visage : avec le support logiciel, les performances de l'IA du H100 sont 47 % plus rapides que celles du MI300X !
NVIDIA gifle AMD en plein visage : avec le support logiciel, les performances de l'IA du H100 sont 47 % plus rapides que celles du MI300X !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-15 18:15:121420parcourir

Selon les informations du 14 décembre, AMD a lancé sa puce IA la plus puissante, Instinct MI300X, plus tôt ce mois-ci. Les performances IA de son serveur à 8 GPU sont 60 % supérieures à celles du NVIDIA H100 8-GPU. À cet égard, NVIDIA a récemment publié un ensemble de dernières données de comparaison des performances entre le H100 et le MI300X, montrant comment le H100 peut utiliser le bon logiciel pour fournir des performances d'IA plus rapides que le MI300X.
Selon les données précédemment publiées par AMD, les performances FP8/FP16 du MI300X ont atteint 1,3 fois celles du NVIDIA H100, et la vitesse d'exécution des modèles Llama 2 70B et FlashAttention 2 est 20 % plus rapide que celle du H100. Sur le serveur 8v8, lors de l'exécution du modèle Llama 2 70B, le MI300X est 40 % plus rapide que le H100 ; lors de l'exécution du modèle Bloom 176B, le MI300X est 60 % plus rapide que le H100.
Cependant, il convient de souligner que lorsque AMD a comparé le MI300X avec NVIDIA H100, AMD a utilisé la bibliothèque d'optimisation de la dernière suite ROCm 6.0 (qui peut prendre en charge les derniers formats informatiques, tels que FP16, Bf16 et FP8, y compris Sparsity, etc. ), pour obtenir ces chiffres. En revanche, le NVIDIA H100 n'a pas été testé sans l'utilisation d'un logiciel d'optimisation tel que TensorRT-LLM de NVIDIA.
La déclaration implicite d'AMD sur le test NVIDIA H100 montre qu'en utilisant le logiciel d'inférence vLLM v.02.2.2 et le système NVIDIA DGX H100, la requête Llama 2 70B a une longueur de séquence d'entrée de 2048 et une longueur de séquence de sortie de 128
Les derniers résultats de tests publiés par NVIDIA pour le DGX H100 (avec 8 GPU NVIDIA H100 Tensor Core, avec 80 Go HBM3) montrent que le logiciel public NVIDIA TensorRT LLM est utilisé, dont la v0.5.0 est utilisée pour les tests Batch-1, la v0 .6.1 pour les mesures de seuil de latence. Les détails de la charge de travail du test sont les mêmes que ceux du test AMD précédent
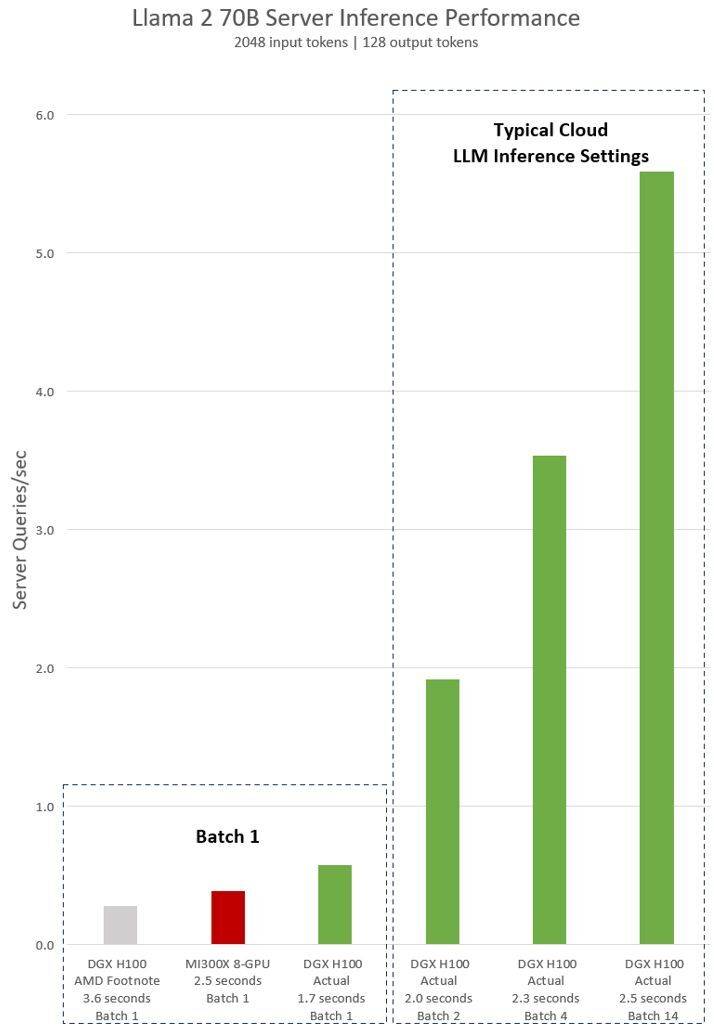
Selon les résultats, après avoir utilisé un logiciel optimisé, les performances du serveur NVIDIA DGX H100 ont augmenté de plus de 2 fois et sont 47 % plus rapides que celles du serveur MI300X 8-GPU démontré par AMD
DGX H100 peut gérer une seule tâche d'inférence en 1,7 seconde. Afin d'optimiser le temps de réponse et le débit du centre de données, les services cloud définissent des temps de réponse fixes pour des services spécifiques. Cela leur permet de combiner plusieurs requêtes d'inférence en « lots » plus grands, augmentant ainsi le nombre global d'inférences par seconde sur le serveur. Les références standards de l'industrie telles que MLPerf utilisent également cette mesure de temps de réponse fixe pour mesurer les performances
De légers compromis dans le temps de réponse peuvent créer une incertitude quant au nombre de requêtes d'inférence que le serveur peut traiter en temps réel. Grâce à un budget de temps de réponse fixe de 2,5 secondes, le serveur NVIDIA DGX H100 peut gérer plus de 5 inférences Llama 2 70B par seconde, tandis que Batch-1 en gère moins d'une par seconde.
Évidemment, il est relativement juste que Nvidia utilise ces nouveaux benchmarks. Après tout, AMD utilise également son logiciel optimisé pour évaluer les performances de ses GPU, alors pourquoi ne pas faire de même lors des tests du Nvidia H100 ?
Vous devez savoir que la pile logicielle de NVIDIA tourne autour de l'écosystème CUDA et occupe une position très forte sur le marché de l'intelligence artificielle après des années de travail acharné et de développement, tandis que le ROCm 6.0 d'AMD est nouveau et n'a pas encore été testé dans des scénarios réels.
Selon les informations précédemment divulguées par AMD, elle a conclu une grande partie de l'accord avec de grandes entreprises telles que Microsoft et Meta, qui considèrent son GPU MI300X comme un remplacement de la solution H100 de Nvidia.
Le dernier Instinct MI300X d'AMD devrait être expédié en grande quantité au premier semestre 2024. Cependant, le GPU H200 plus puissant de NVIDIA sera également expédié d'ici là, et NVIDIA lancera également une nouvelle génération de Blackwell B100 au second semestre 2024. . De plus, Intel lancera également sa puce IA de nouvelle génération Gaudi 3. Ensuite, la concurrence dans le domaine de l’intelligence artificielle semble s’intensifier.
Éditeur : Épée Xinzhixun-Ruruuni
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les 5 meilleurs processeurs et plus pour Windows 11, quels processeurs [AMD/Intel] devriez-vous choisir ?
- Apple Mac Pro est alimenté par le GPU AMD Radeon Pro W6600X, équipé de 2048 processeurs de flux et de 8 Go de mémoire
- Correctif : erreur de pilote graphique AMD non installé dans Windows 11
- AMD prévoit de lancer les nouveaux processeurs Ryzen série 8000 en 2024, une énorme mise à niveau menée par l'architecture Zen5