
Maison >Périphériques technologiques >IA >Débloquez GPT-4 et Claude2.1 : en une phrase, vous pouvez réaliser la véritable puissance de plus de 100 000 grands modèles contextuels, augmentant le score de 27 à 98.
Débloquez GPT-4 et Claude2.1 : en une phrase, vous pouvez réaliser la véritable puissance de plus de 100 000 grands modèles contextuels, augmentant le score de 27 à 98.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-15 11:37:37827parcourir
Tous les grands modélistes ont enroulé la fenêtre contextuelle l'un après l'autre. La configuration standard de Llama-1 était encore de 2k, mais maintenant ceux qui en ont moins de 100k sont trop gênés pour sortir.
Cependant, un test extrême réalisé par Goose a révélé que la plupart des gens l'utilisent de manière incorrecte et ne parviennent pas à exercer la force due à l'IA.
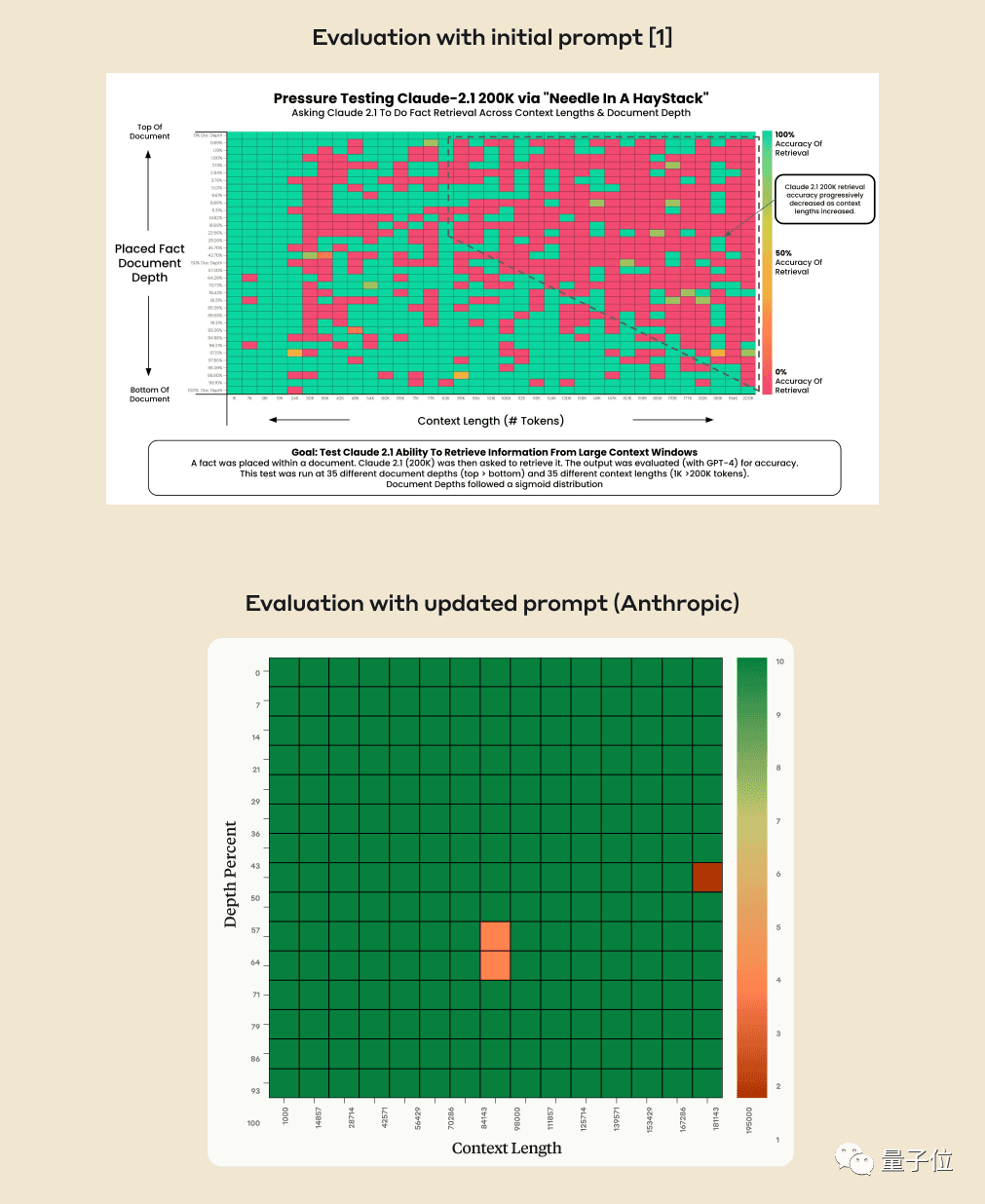
L'IA peut-elle vraiment trouver avec précision des faits clés à partir de centaines de milliers de mots ? Plus la couleur est rouge, plus l'IA commet d'erreurs.
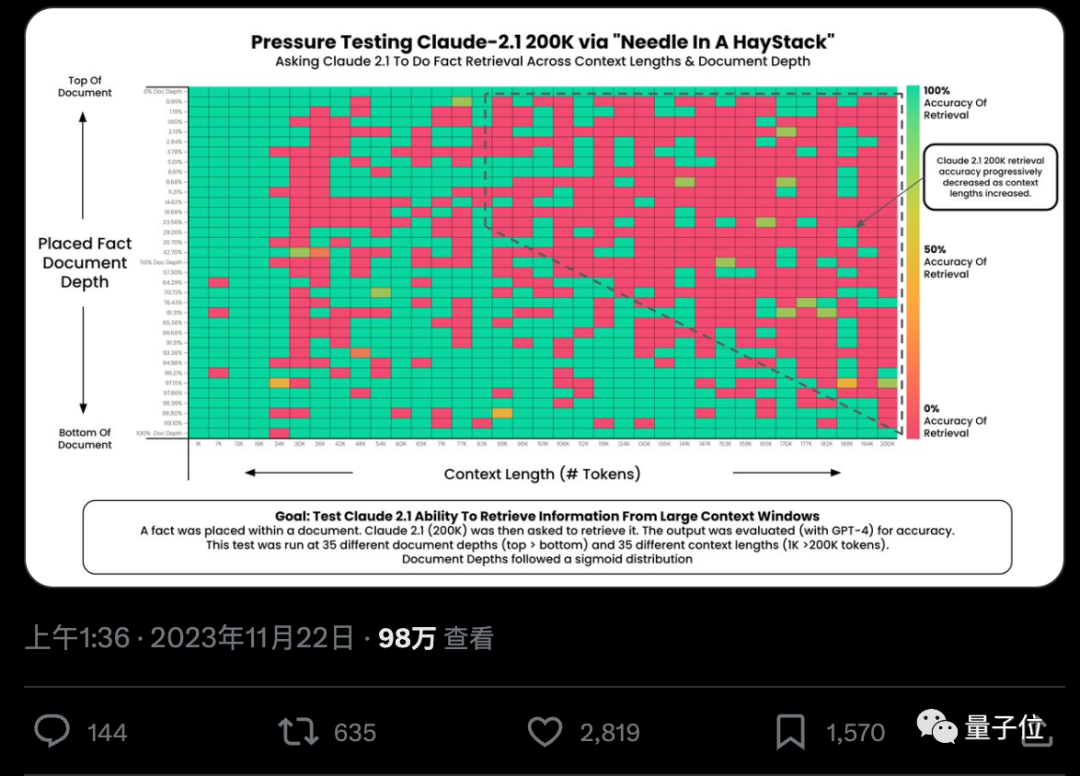
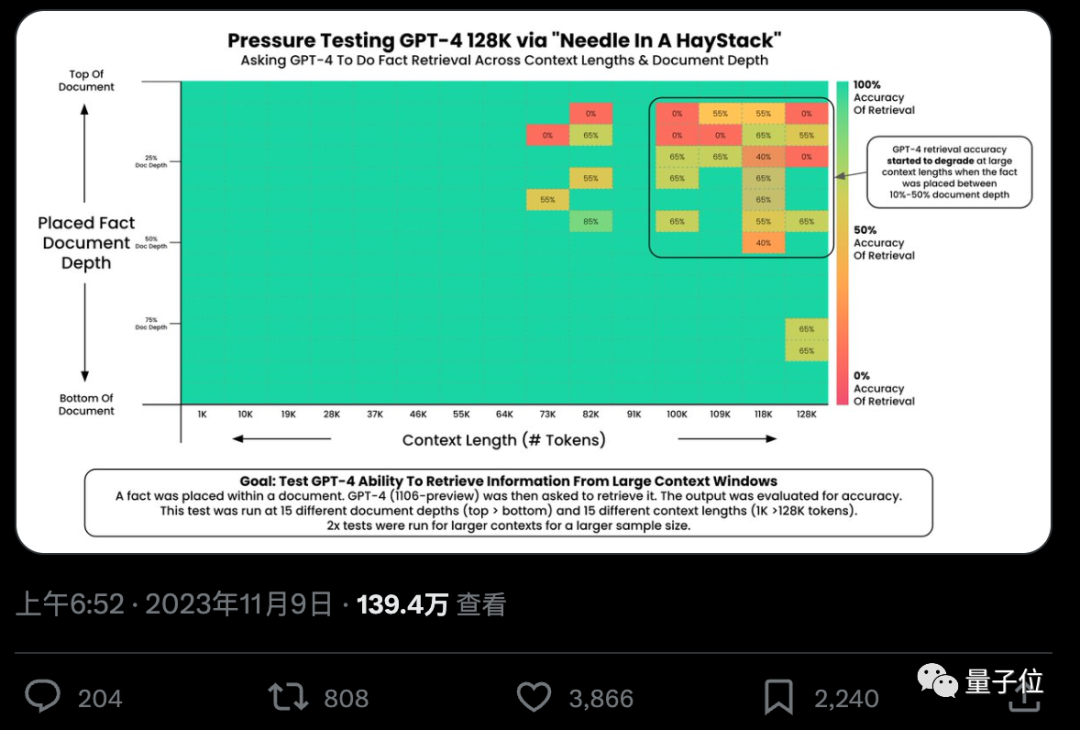
Par défaut, GPT-4-128k et les derniers résultats Claude2.1-200k publiés ne sont pas idéaux.
Mais après que l'équipe de Claude ait compris la situation, elle a trouvé une solution super simple, ajoutant une phrase pour améliorer directement le score de 27% à 98%.
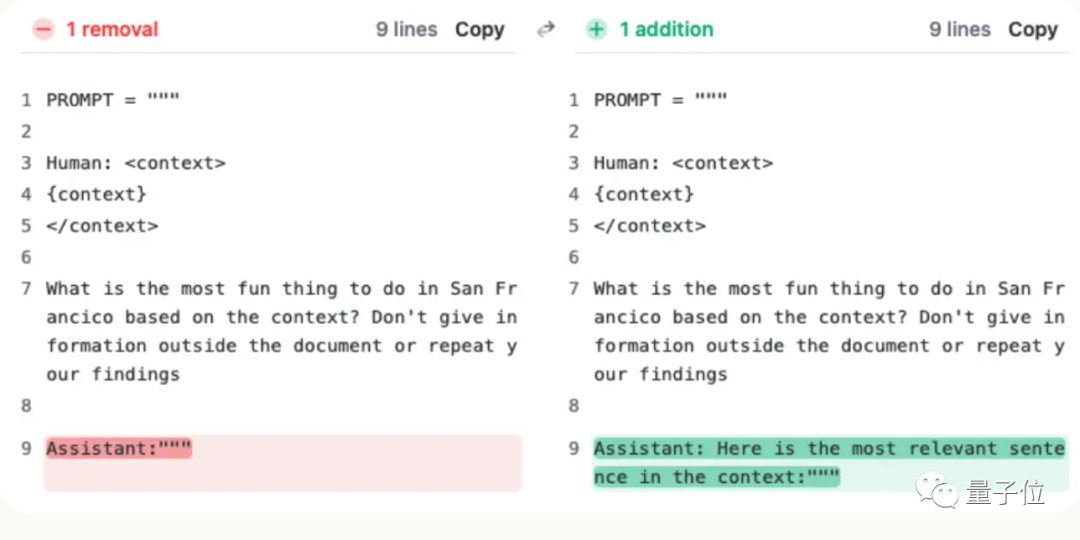
C'est juste que cette phrase n'est pas ajoutée à la question de l'utilisateur. Au lieu de cela, l'IA a dit au début de la réponse :
« Voici la phrase la plus pertinente dans le contexte : »
(C'est la phrase la plus pertinente dans son contexte :)
Laissez le grand mannequin trouver l'aiguille dans la botte de foin
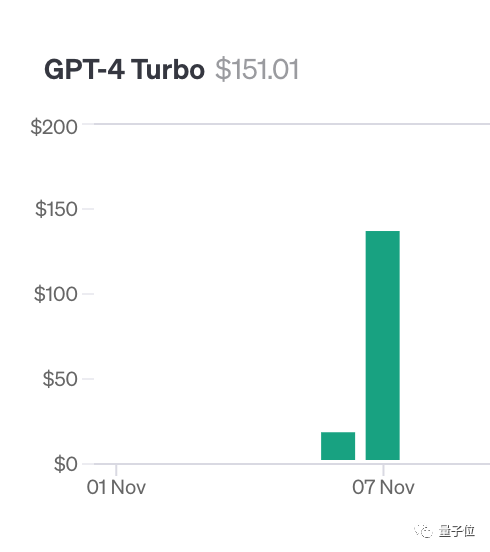
Pour faire ce test, l'auteur Greg Kamradt a dépensé au moins 150 $ de son propre argent.
Lors du test de Claude2.1, Anthropic lui a fourni un quota gratuit Heureusement, il n'a pas eu à dépenser 1 016 $ supplémentaires
En fait, la méthode de test n'est pas compliquée. Le fondateur de YC, Paul Graham, publie des articles de blog comme données de test.
Ajoutez des phrases spécifiques à différents endroits du document : La meilleure chose à propos de San Francisco est de s'asseoir à Dolores Park par une journée ensoleillée et de déguster un sandwich
Veuillez utiliser le contexte fourni pour répondre à la question, dans Avec différentes longueurs de contexte et documents ajoutés à différents endroits, GPT-4 et Claude2.1 ont été testés à plusieurs reprises

Enfin, la bibliothèque Langchain Evals a été utilisée pour évaluer les résultats
L'auteur a nommé cet ensemble de tests "Trouver des aiguilles dans des meules de foin" / Trouver un une aiguille dans une botte de foin » et a open source le code sur GitHub, qui a reçu plus de 200 étoiles, et a révélé qu'une entreprise avait sponsorisé les tests du prochain grand modèle.
La société d'IA a trouvé une solution toute seule
Quelques semaines plus tard, la société derrière Claude Anthropic Après une analyse minutieuse, il a été découvert que l'IA n'était tout simplement pas disposée à répondre aux questions basé sur une seule phrase du document, en particulier lorsque cette phrase a été insérée ultérieurement, lorsqu'elle a peu de pertinence pour l'ensemble de l'article.
En d'autres termes, si l'IA juge que cette phrase n'a rien à voir avec le sujet de l'article, elle prendra la méthode de ne pas chercher chaque phrase

À ce stade, vous devez en utiliser signifie dépasser l'IA et demander à Claude d'ajouter qu'au début de la réponse La phrase "Voici la phrase la plus pertinente dans le contexte :" peut être résolue.
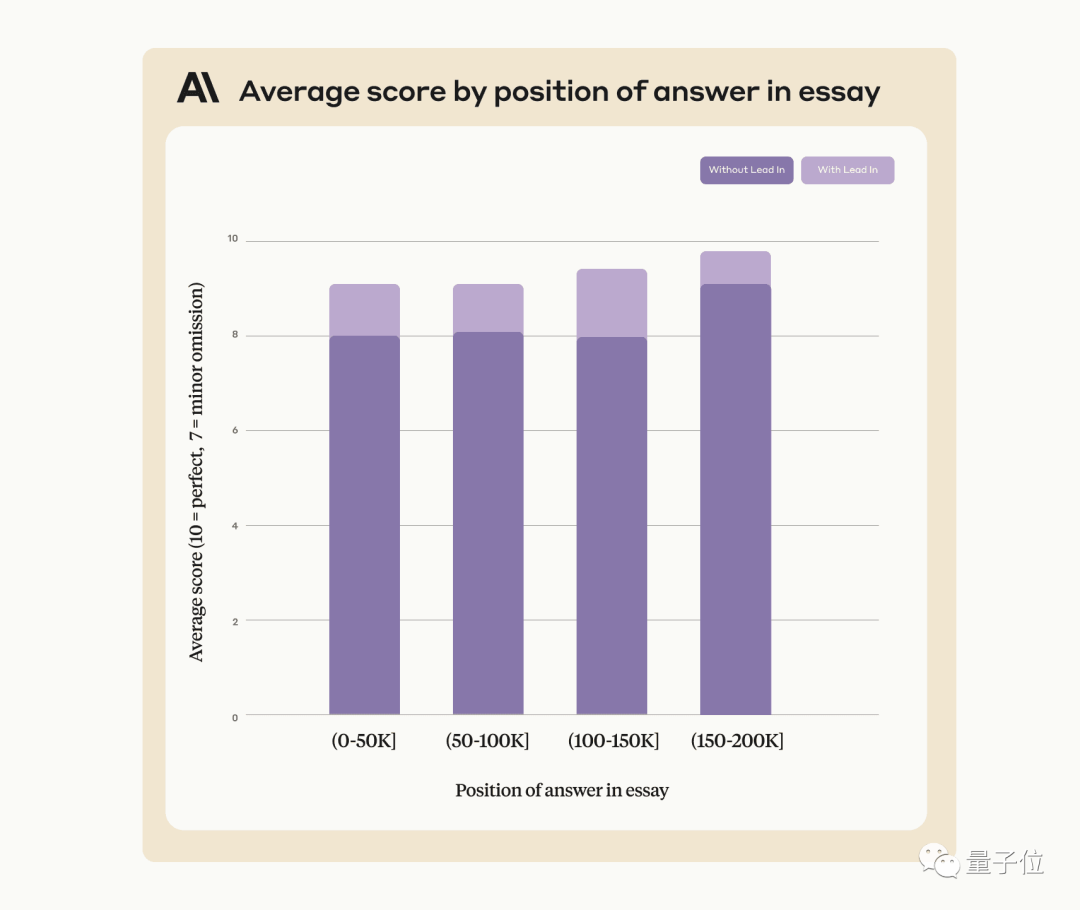
L'utilisation de cette méthode peut améliorer les performances de Claude, même lors de la recherche de phrases qui n'ont pas été artificiellement ajoutées au texte original
Anthropic a déclaré qu'il continuerait à former Claude à l'avenir pour le rendre plus capable adaptés à de telles tâches.
Lorsque vous utilisez l'API, demandez à l'IA de répondre avec un début précis, et elle peut aussi avoir d'autres utilisations astucieuses
Matt Shumer, un entrepreneur, a donné quelques conseils supplémentaires après avoir lu le plan
Si vous souhaitez que l'IA génère un format JSON pur, le mot d'invite se termine par "{". De la même manière, si vous souhaitez que l'IA répertorie les chiffres romains, le mot d'invite peut se terminer par « I : ».
Mais les choses ne sont pas encore finies...
Les grandes entreprises nationales ont également commencé à remarquer ce test et ont commencé à essayer si leurs propres grands modèles peuvent passer
ont également des contextes ultra-longs L'équipe The Dark Side of the Moon Kimi grand modèle a également détecté des problèmes, mais a proposé différentes solutions et obtenu de bons résultats.

Sans changer le sens original, le contenu à réécrire est le suivant : L'avantage de ceci est qu'il est plus facile de modifier l'invite de question de l'utilisateur que de demander à l'IA d'ajouter une phrase dans la réponse, surtout lorsque l'API n'est pas appelée. En utilisant directement le produit chatbot
J'ai utilisé une nouvelle méthode pour aider à tester GPT-4 et Claude2.1 sur la face cachée de la lune, et les résultats ont montré que GPT-4 a obtenu des améliorations significatives, tandis que Claude2.1 n'a que légèrement amélioré
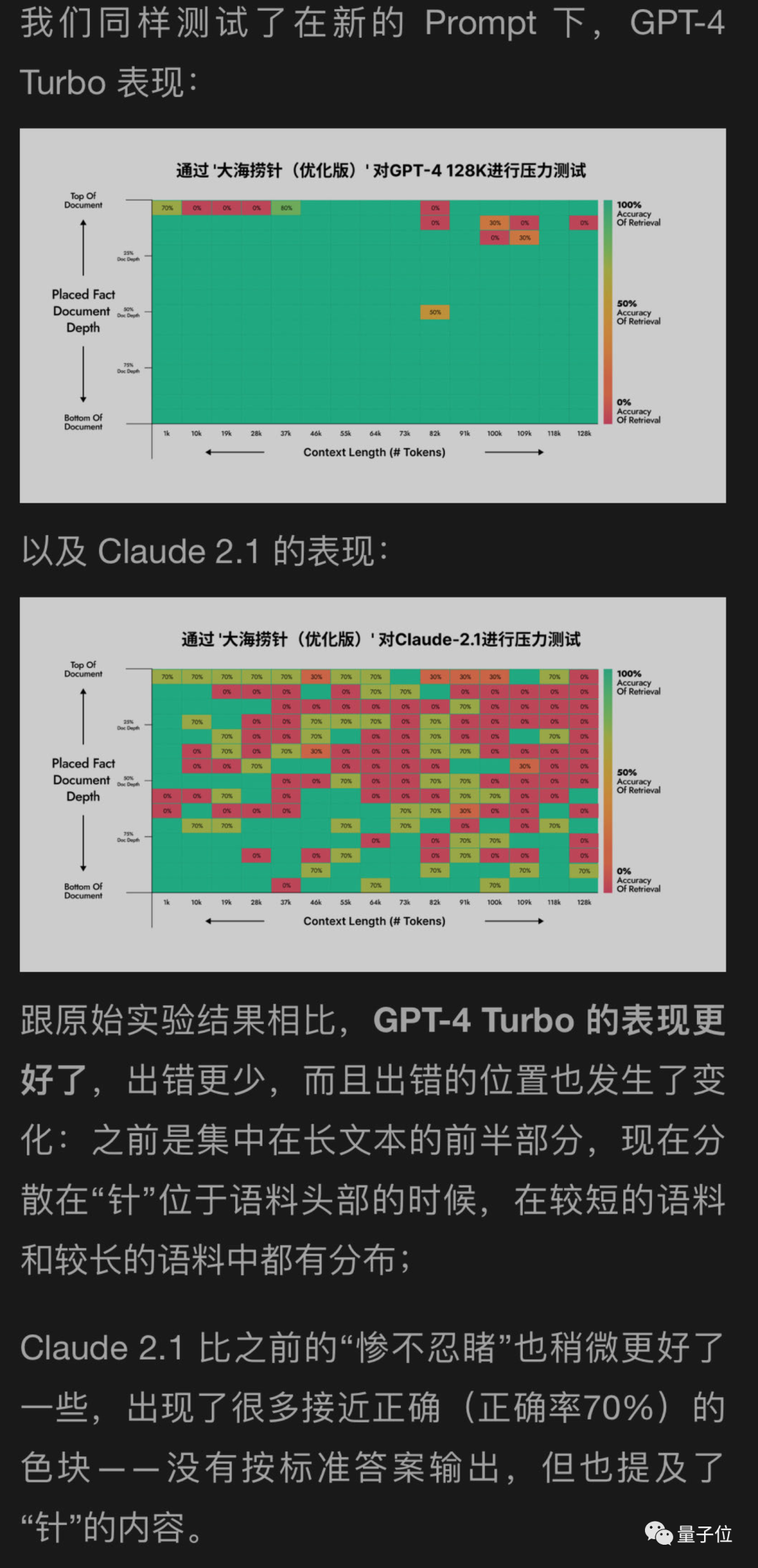
Il semble que cette expérience elle-même ait certaines limites. Claude a aussi ses propres particularités, qui peuvent être liées à leur propre alignement de l'IA constitutionnelle. Anthropique lui-même.
Plus tard, les ingénieurs de l'autre côté de la Lune ont continué à mener d'autres séries d'expériences, et l'une des expériences était en fait...

Oups, je me suis transformé en données de test
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment comparer les similitudes et les différences entre deux colonnes de données dans Excel
- Comment comparer les données en double entre deux feuilles de calcul
- Quels sont les huit types de données de base ?
- Musk annonce qu'il poursuivra Microsoft pour avoir utilisé les données de Twitter pour entraîner un système d'intelligence artificielle
- Le premier examen gouvernemental de ChatGPT pourrait provenir de la Commission fédérale du commerce des États-Unis, OpenAI : GPT5 pas encore formé