
Maison >Périphériques technologiques >IA >Une compréhension plus approfondie du transformateur visuel, analyse du transformateur visuel
Une compréhension plus approfondie du transformateur visuel, analyse du transformateur visuel

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-15 11:17:371261parcourir
Cet article est réimprimé avec l'autorisation du compte public Autonomous Driving Heart. Veuillez contacter la source lors de la réimpression
Écrire devant&&Compréhension personnelle de l'auteur
Actuellement, les modèles d'algorithmes basés sur la structure Transformer ont été largement utilisés dans Le domaine de la vision par ordinateur (CV) a eu un grand impact. Ils surpassent les précédents modèles d’algorithmes de réseaux neuronaux convolutifs (CNN) sur de nombreuses tâches de base de vision par ordinateur. Ce qui suit est le dernier classement de la liste LeaderBoard des différentes tâches de vision par ordinateur de base que j'ai trouvées Grâce à LeaderBoard, nous pouvons voir la domination du modèle d'algorithme Transformer dans diverses tâches de vision par ordinateur
- Tâche de classification d'images
Premier sur ImageNet LeaderBoard, il ressort de la liste que parmi les cinq premiers, chaque modèle utilise la structure Transformer, tandis que la structure CNN n'est que partiellement utilisée, ou combinée avec le Transformer.

LeaderBoard pour la tâche de classification d'images
- Tâche de détection de cible
Le suivant est LeaderBoard sur COCO test-dev. On peut voir dans la liste que plus de la moitié des cinq premiers sont basés sur DETR The. la structure de type algorithme est étendue.
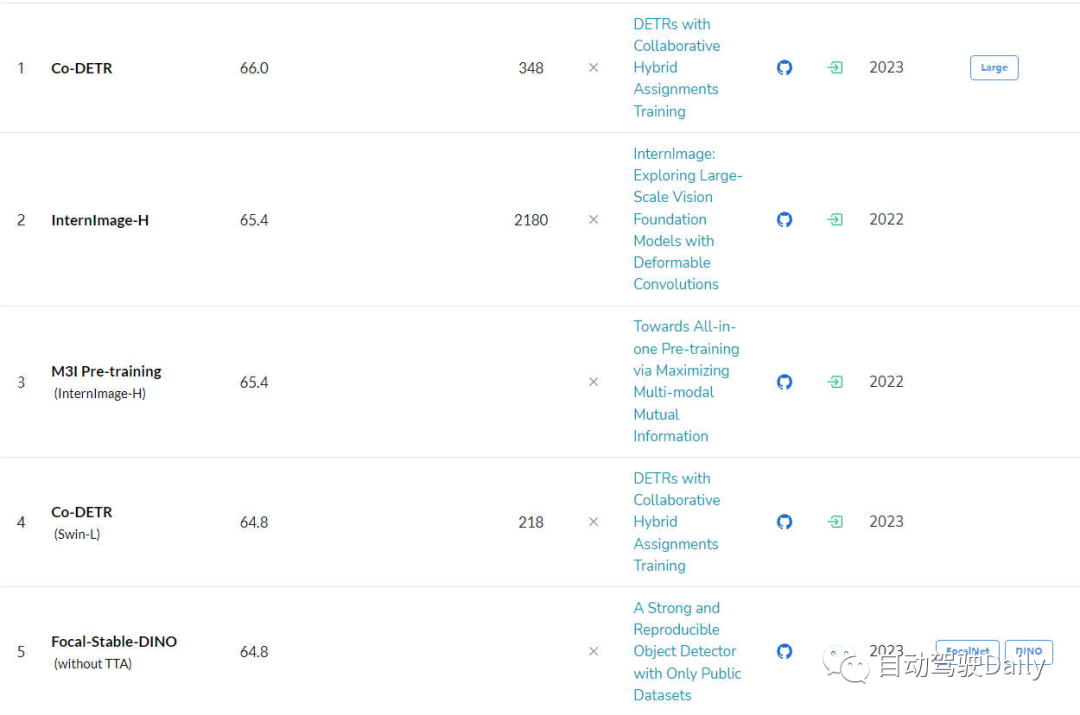 LeaderBoard pour la tâche de détection de cible
LeaderBoard pour la tâche de détection de cible
- Tâche de segmentation sémantique
Le dernier est LeaderBoard sur ADE20K val. On peut également voir dans la liste que parmi les premières de la liste, la structure Transformer occupe toujours l'actuelle. position. La force principale.
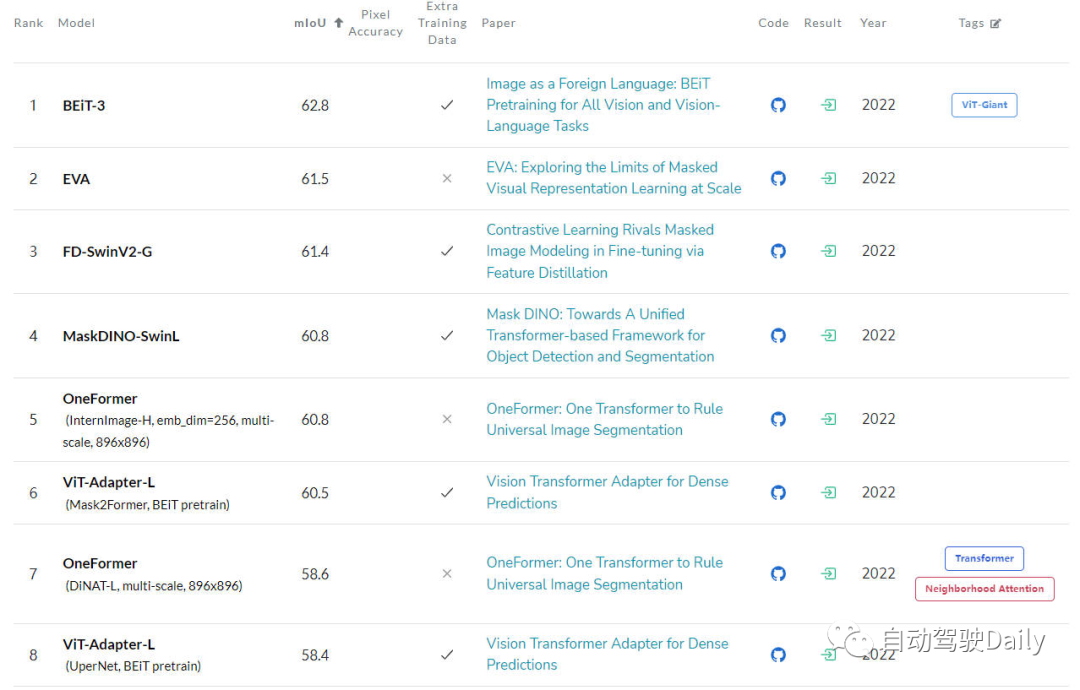 LeaderBoard pour les tâches de segmentation sémantique
LeaderBoard pour les tâches de segmentation sémantique
Bien que Transformer présente actuellement un grand potentiel de développement en Chine, la communauté actuelle de vision par ordinateur n'a pas pleinement compris le fonctionnement interne de Vision Transformer, ni sa prise de décision (résultats de prédiction de sortie)), donc le le besoin de son interprétabilité s’est progressivement fait sentir. Ce n'est qu'en comprenant comment ces modèles prennent des décisions que nous pourrons améliorer leurs performances et renforcer la confiance dans les systèmes d'intelligence artificielle
L'objectif principal de cet article est d'étudier différentes méthodes d'interprétabilité de Vision Transformer et sur la base des motivations de recherche de différents algorithmes, types de structures et les scénarios d'application sont classés pour former un article de synthèse
Analyse de Vision Transformer
Car comme mentionné tout à l'heure, la structure de Vision Transformer a obtenu de très bons résultats dans diverses tâches de vision par ordinateur de base. De nombreuses méthodes ont émergé dans la communauté de la vision par ordinateur pour améliorer son interprétabilité. Dans cet article, nous nous concentrons principalement sur les tâches de classification et sélectionnons les plus récentes et les plus récentes parmi cinq aspects : Méthodes d'attribution communes, Méthodes basées sur l'attention, Méthodes basées sur l'élagage, Méthodes intrinsèquement explicables, Autre Tâches Le travail classique est introduit. Voici la carte mentale qui apparaît dans l'article. Vous pouvez la lire plus en détail en fonction de ce qui vous intéresse ~
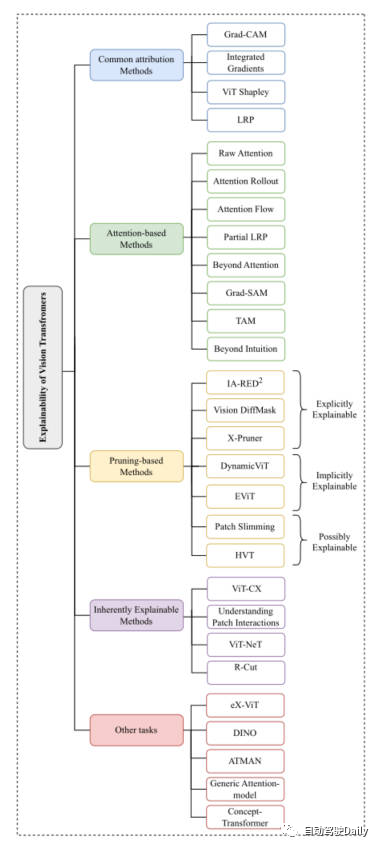
Carte mentale de cet article
Méthodes d'attribution courantes
Les explications basées sur les méthodes d'attribut commencent généralement. à partir du modèle Commençons par expliquer le processus par lequel les fonctionnalités d'entrée obtiennent progressivement le résultat de sortie final. Ce type de méthode est principalement utilisé pour mesurer la corrélation entre les résultats de prédiction du modèle et les caractéristiques d'entrée, telles que les algorithmes
Grad-CAMet Integrated Gradients sont directement appliqués aux algorithmes basés sur Visual Transformer. Certaines autres méthodes telles que SHAP et Layer-Wise Relevance Propagation (LRP) ont été utilisées pour explorer les architectures basées sur ViT. Cependant, en raison du coût de calcul très élevé de méthodes telles que SHAP, le récent algorithme ViT Shapely a été conçu pour s'adapter à la recherche d'applications liée au ViT. Méthodes basées sur l'attention
Vision Transformer a acquis de puissantes capacités d'extraction de fonctionnalités grâce à son mécanisme d'attention. Parmi les méthodes d’interprétabilité basées sur l’attention, la visualisation des résultats du poids d’attention est une méthode très efficace. Cet article présentera plusieurs techniques de visualisation
- Attention brute : Comme son nom l'indique, cette méthode consiste à visualiser la carte de poids d'attention obtenue à partir de la couche intermédiaire du modèle de réseau, afin d'analyser l'effet du modèle.
- Déploiement de l'attention : Cette technologie suit le transfert d'informations des jetons d'entrée vers les intégrations intermédiaires en élargissant les poids d'attention dans différentes couches du réseau.
- Attention Flow : Cette méthode traite la carte d'attention comme un réseau de flux et utilise l'algorithme de flux maximum pour calculer la valeur de flux maximale depuis l'intégration intermédiaire jusqu'au jeton d'entrée.
- partialLRP : Cette méthode est proposée pour visualiser le mécanisme d'attention multi-têtes dans Vision Transformer, tout en considérant également l'importance de chaque tête d'attention.
- Grad-SAM : Cette méthode est utilisée pour atténuer les limites liées au fait de s'appuyer uniquement sur la matrice d'attention d'origine pour expliquer les prédictions du modèle, incitant les chercheurs à utiliser des gradients dans les poids d'attention d'origine.
- Au-delà de l'intuition : Cette méthode est également une méthode d'explication de l'attention, comprenant deux étapes de perception de l'attention et de retour de raisonnement.
Enfin, voici un diagramme de visualisation de l'attention des différentes méthodes d'interprétabilité. Vous pouvez ressentir par vous-même la différence entre les différentes méthodes de visualisation.

Comparaison des cartes d'attention de différentes méthodes de visualisation
Méthodes basées sur l'élagage
L'élagage est une méthode très efficace qui est largement utilisée pour optimiser l'efficacité et la complexité de la structure du transformateur. La méthode d'élagage réduit le nombre de paramètres et la complexité de calcul du modèle en supprimant les informations redondantes ou inutiles. Bien que les algorithmes d’élagage se concentrent sur l’amélioration de l’efficacité de calcul du modèle, ce type d’algorithme peut toujours assurer l’interprétabilité du modèle.
Les méthodes d'élagage basées sur Vision-Transformer dans cet article peuvent être grossièrement divisées en trois catégories : explicitement explicable (explicitement explicable), implicitement explicable (implicitement explicable), éventuellement explicable (éventuellement explicable) expliquer).
-
Explicitement explicable
Parmi les méthodes basées sur l'élagage, il existe plusieurs types de méthodes qui peuvent fournir des modèles plus simples et plus explicables.
- IA-RED^2 : Le but de cette méthode est d'atteindre un équilibre optimal entre l'efficacité de calcul et l'interprétabilité du modèle d'algorithme. Et dans ce processus, la flexibilité du modèle d’algorithme ViT original est conservée.
- X-Pruner : Cette méthode est une méthode d'élagage des unités de saillance en créant un masque perceptuel interprétable qui mesure la contribution de chaque unité prévisible dans la prédiction d'une classe spécifique.
- Vision DiffMask : Cette méthode d'élagage comprend l'ajout d'un mécanisme de déclenchement à chaque couche ViT. Grâce au mécanisme de déclenchement, la sortie du modèle peut être maintenue tout en protégeant l'entrée. Au-delà de cela, le modèle algorithmique peut clairement déclencher un sous-ensemble des images restantes, permettant ainsi une meilleure compréhension des prédictions du modèle.
-
Implicitement explicable
Parmi les méthodes basées sur l'élagage, il existe également des méthodes classiques qui peuvent être divisées dans la catégorie des modèles d'explicabilité implicite. - Dynamic ViT : Cette méthode utilise un module de prédiction léger pour estimer l'importance de chaque jeton en fonction des caractéristiques actuelles. Ce module léger est ensuite ajouté à différentes couches de ViT pour élaguer les jetons redondants de manière hiérarchique. Plus important encore, cette méthode améliore l’interprétabilité en localisant progressivement les parties clés de l’image qui contribuent le plus à la classification.
- Efficient Vision Transformer (EViT) : L'idée principale de cette méthode est d'accélérer l'EViT en réorganisant les jetons. En calculant les scores d'attention, EViT conserve les jetons les plus pertinents tout en fusionnant les jetons les moins pertinents en jetons supplémentaires. Dans le même temps, afin d'évaluer l'interprétabilité d'EViT, l'auteur de l'article a visualisé le processus de reconnaissance de jetons sur plusieurs images d'entrée.
-
Peut-être explicable
Bien que ce type de méthode n'ait pas été conçu à l'origine pour améliorer l'interprétabilité de ViT, ce type de méthode offre un grand potentiel pour des recherches plus approfondies sur l'interprétabilité du modèle.
- Patch Minceur : Accélérez ViT en vous concentrant sur les correctifs redondants dans les images grâce à une approche descendante. L'algorithme conserve de manière sélective la capacité des correctifs clés à mettre en évidence des caractéristiques visuelles importantes, améliorant ainsi l'interprétabilité.
- Hierarchical Visual Transformer (HVT) : Cette méthode est introduite pour améliorer l'évolutivité et les performances de ViT. À mesure que la profondeur du modèle augmente, la longueur de la séquence diminue progressivement. De plus, en divisant les blocs ViT en plusieurs étapes et en appliquant des opérations de pooling à chaque étape, l'efficacité des calculs est considérablement améliorée. Compte tenu de la concentration progressive sur les composants les plus importants du modèle, il existe une opportunité d'explorer son impact potentiel sur l'amélioration de l'interprétabilité et de l'interprétabilité.
Méthodes intrinsèquement explicables
Parmi les différentes méthodes interprétables, il existe une classe de méthodes qui développent principalement des modèles algorithmiques capables de les expliquer intrinsèquement. Cependant, ces modèles ont souvent du mal à atteindre le même niveau de précision que les boîtes noires plus complexes. modèles. Par conséquent, un équilibre minutieux doit être considéré entre interprétabilité et performance. Ensuite, quelques œuvres classiques sont brièvement présentées.
- ViT-CX : Cette méthode est une méthode d'interprétation basée sur un masque personnalisée pour le modèle ViT. Cette approche repose sur l'intégration de correctifs et son impact sur les résultats du modèle, plutôt que de se concentrer sur eux. Cette méthode comprend deux étapes : la génération de masques et l'agrégation de masques, fournissant ainsi une carte de saillance plus significative.
- ViT-NeT : Cette méthode est un nouveau décodeur d'arbre neuronal qui décrit le processus de prise de décision à travers des structures arborescentes et des prototypes. Dans le même temps, l’algorithme permet également une interprétation visuelle des résultats.
- R-Cut : Cette méthode améliore l'interprétabilité de ViT grâce à la relation pondérée et coupée. Cette méthode comprend deux modules, à savoir les modules Relation Weighted Out et Cut. Le premier se concentre sur l’extraction de classes spécifiques d’informations de la couche intermédiaire, en mettant l’accent sur les caractéristiques pertinentes. Ce dernier effectue une décomposition fine des caractéristiques. En intégrant les deux modules, des cartes d'interprétabilité denses spécifiques à la classe peuvent être générées.
Autres tâches
L'architecture basée sur ViT doit encore être expliquée pour d'autres tâches de vision par ordinateur dans l'exploration. Certaines méthodes d'interprétabilité ont été proposées spécifiquement pour d'autres tâches, et les derniers travaux dans des domaines connexes seront présentés ci-dessous
- eX-ViT : Cet algorithme est un nouveau transformateur visuel interprétable basé sur une segmentation sémantique faiblement supervisée. De plus, afin d'améliorer l'interprétabilité, un module de perte orienté attribut est introduit, qui contient trois pertes : la perte orientée attribut au niveau mondial, la perte de discriminabilité des attributs au niveau local et la perte de diversité des attributs. Le premier utilise des cartes d’attention pour créer des caractéristiques interprétables, tandis que les deux derniers améliorent l’apprentissage des attributs.
- DINO : Cette méthode est une méthode simple auto-supervisée et une méthode d'autodistillation sans étiquettes. La carte d'attention finale apprise peut conserver efficacement les régions sémantiques de l'image, atteignant ainsi des objectifs interprétables.
- Generic Attention-model : Cette méthode est un modèle d'algorithme de prédiction basé sur l'architecture Transformer. La méthode est appliquée aux trois architectures les plus couramment utilisées, à savoir l’attention personnelle pure, l’attention personnelle combinée à une attention conjointe et l’attention codeur-décodeur. Pour tester l'interprétabilité du modèle, les auteurs ont utilisé une tâche de réponse visuelle aux questions, cependant, elle est également applicable à d'autres tâches CV telles que la détection d'objets et la segmentation d'images.
- ATMAN : Il s'agit d'une méthode de perturbation indépendante des modalités qui utilise un mécanisme d'attention pour générer une carte de corrélation de l'entrée par rapport à la prédiction de sortie. Cette approche tente de comprendre la prédiction des déformations grâce à des opérations d’attention efficaces en mémoire.
- Concept-Transformer : cet algorithme génère des explications sur les sorties du modèle en mettant en évidence les scores d'attention pour les concepts de haut niveau définis par l'utilisateur, garantissant ainsi la fiabilité et la fiabilité.
Future Outlook
Actuellement, les modèles d'algorithmes basés sur l'architecture Transformer ont obtenu des résultats exceptionnels dans diverses tâches de vision par ordinateur. Cependant, il y a actuellement un manque de recherche évidente sur la manière d'utiliser les méthodes d'interprétabilité pour promouvoir le débogage et l'amélioration des modèles, et améliorer l'équité et la fiabilité des modèles, en particulier dans les applications ViT.
Cet article vise à utiliser des tâches de classification d'images pour améliorer l'équité et la fiabilité. de modèles. Les modèles d'algorithme d'interprétabilité de Vision Transformer sont classés et organisés pour aider les lecteurs à mieux comprendre l'architecture de ces modèles. J'espère que cela sera utile à tout le monde

Ce qui doit être réécrit est : Lien original : https : // mp.weixin.qq.com/s/URkobeRNB8dEYzrECaC7tQ
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!