
Maison >Périphériques technologiques >IA >Le téléphone mobile exécute mieux le petit modèle de Microsoft que le grand modèle avec 2,7 milliards de paramètres
Le téléphone mobile exécute mieux le petit modèle de Microsoft que le grand modèle avec 2,7 milliards de paramètres

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-14 22:45:471474parcourir
Le PDG de Microsoft, Nadella, a annoncé lors de la conférence Ignite le mois dernier que le modèle à petite échelle Phi-2 serait entièrement open source. Cette décision améliorera considérablement les performances du raisonnement de bon sens, de la compréhension du langage et du raisonnement logique

Aujourd'hui, Microsoft a annoncé plus de détails sur le modèle Phi-2 et sa nouvelle base de données de technologie d'invite. Ce modèle avec seulement 2,7 milliards de paramètres surpasse Llama2 7B, Llama2 13B, Mistral 7B et comble l'écart (ou même mieux) avec Llama2 70B sur la plupart des tâches de raisonnement de bon sens, de compréhension du langage, de mathématiques et de codage.
En même temps, le Phi-2 de petite taille peut fonctionner sur des appareils mobiles tels que des ordinateurs portables et des téléphones mobiles. Nadella a déclaré que Microsoft était très heureux de partager son meilleur modèle de langage (SLM) et sa technologie d'invite SOTA avec les développeurs de R&D.
Microsoft a publié en juin de cette année un article intitulé "Just a Textbook" qui utilisait des données de "qualité de manuel" contenant seulement 7B de marqueurs pour former un modèle avec 1,3B de paramètres, à savoir phi-1. Malgré des ensembles de données et des tailles de modèles bien inférieurs à ceux de ses concurrents, phi-1 atteint un taux de réussite initial de 50,6 % dans HumanEval et une précision de 55,5 % dans MBPP. phi-1 a prouvé que même des « petites données » de haute qualité peuvent donner au modèle de bonnes performances
Microsoft a ensuite publié « Just a Textbook II : Phi-1.5 Technical Report » en septembre, axé sur le potentiel de haute qualité. de « petites données » est étudiée plus en détail. L'article propose Phi-1.5, qui convient au QA Q&A, au codage et à d'autres scénarios, et peut atteindre une échelle de 1,3 milliard
Aujourd'hui, Phi-2 avec 2,7 milliards de paramètres utilise à nouveau un « petit corps » pour fournir excellentes capacités de raisonnement et de compréhension du langage, démontrant les performances SOTA dans des modèles de langage de base sous 13 milliards de paramètres. Grâce aux innovations en matière de mise à l'échelle des modèles et de gestion des données de formation, Phi-2 correspond ou dépasse les modèles 25 fois sa propre taille sur des benchmarks complexes.
Microsoft affirme que Phi-2 sera un modèle idéal pour les chercheurs souhaitant mener des explorations d'interprétabilité, des améliorations de sécurité ou des expériences de réglage fin pour diverses tâches. Microsoft a rendu Phi-2 disponible dans le catalogue de modèles Azure AI Studio pour faciliter le développement de modèles de langage.
Phi-2 Key Highlights
L'augmentation de la taille du modèle de langage à des centaines de milliards de paramètres a en effet libéré de nombreuses nouvelles capacités et redéfini le paysage du traitement du langage naturel. Mais une question demeure : ces nouvelles capacités peuvent-elles également être obtenues sur des modèles à plus petite échelle grâce à la sélection de stratégies de formation (telles que la sélection de données) ?
La solution proposée par Microsoft consiste à utiliser la série de modèles Phi pour obtenir des performances similaires à celles des grands modèles en entraînant de petits modèles de langage. Phi-2 enfreint les règles de mise à l'échelle des modèles de langage traditionnels sous deux aspects
Premièrement, la qualité des données d'entraînement joue un rôle crucial dans les performances du modèle. Microsoft pousse cette compréhension à l'extrême en se concentrant sur les données de « qualité des manuels ». Leurs données de formation consistent en un ensemble de données complet spécialement créé qui enseigne au modèle des connaissances et un raisonnement de bon sens, tels que la science, les activités quotidiennes et la psychologie. De plus, ils ont élargi leur corpus de formation avec des données Web soigneusement sélectionnées qui ont été examinées pour leur valeur éducative et la qualité du contenu.
Deuxièmement, Microsoft a utilisé une technologie innovante pour passer de Phi-1.5 avec 1,3 milliard de paramètres. Au début, les connaissances ont été progressivement intégrées. dans Phi-2 avec 2,7 milliards de paramètres. Ce transfert de connaissances à grande échelle accélère la convergence de la formation et améliore considérablement les scores de référence de Phi-2.
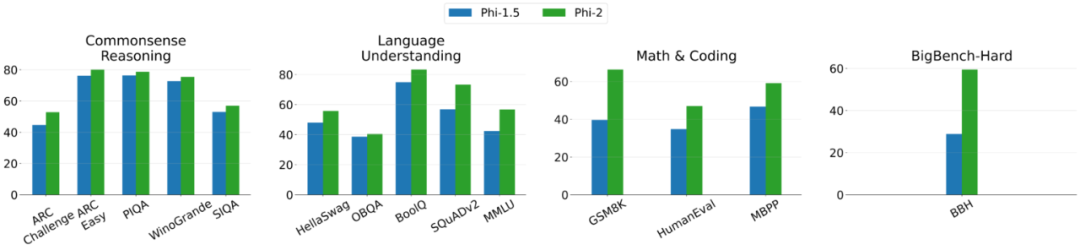
Ce qui suit est le graphique de comparaison entre Phi-2 et Phi-1.5, à l'exception de BBH (3-shot CoT) et MMLU (5-shot), toutes les autres tâches sont évaluées en utilisant 0-shot
Détails de la formation
Phi-2 est un modèle basé sur Transformer dont le but est de prédire le mot suivant. Il a été formé sur des ensembles de données synthétiques et réseau, à l'aide de 96 GPU A100, et a duré 14 jours.
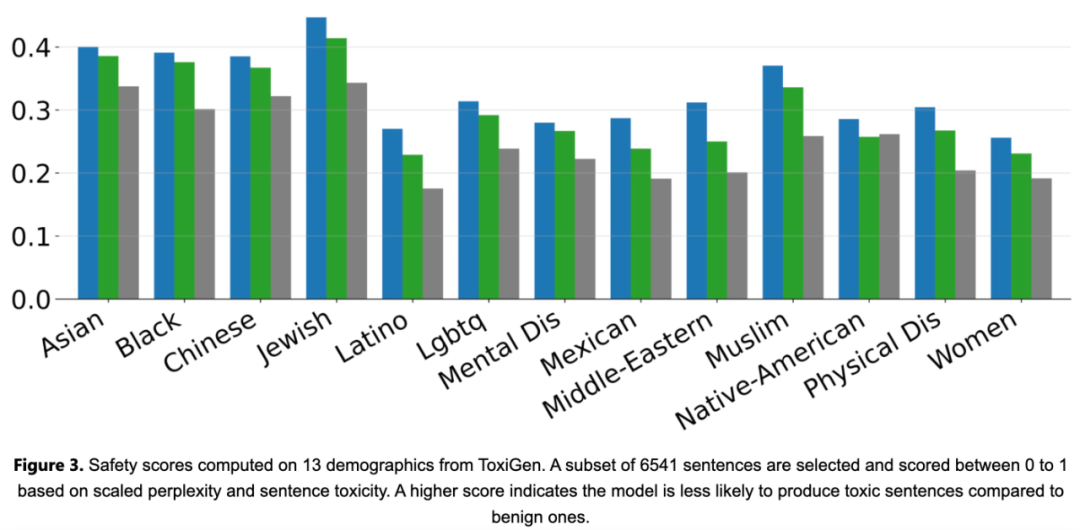
Phi-2 est un modèle de base sans alignement d'apprentissage par renforcement avec retour humain (RLHF) et sans réglage fin des instructions. Malgré cela, Phi-2 a toujours obtenu de meilleurs résultats en termes de toxicité et de biais par rapport au modèle open source existant optimisé, comme le montre la figure 3 ci-dessous.
Évaluation expérimentale
Tout d'abord, l'étude a comparé expérimentalement Phi-2 avec des modèles de langage courants sur des critères académiques, couvrant plusieurs catégories, notamment :
- Big Bench Hard (BBH) (3 plans avec CoT )
- Raisonnement de bon sens (PIQA, WinoGrande, ARC easy and challenge, SIQA),
- Compréhension du langage (HellaSwag, OpenBookQA, MMLU (5-shot), SQuADv2 (2-shot), BoolQ)
- Mathématiques (GSM8k (8 shot))
- Encoding (HumanEval, MBPP (3-shot))
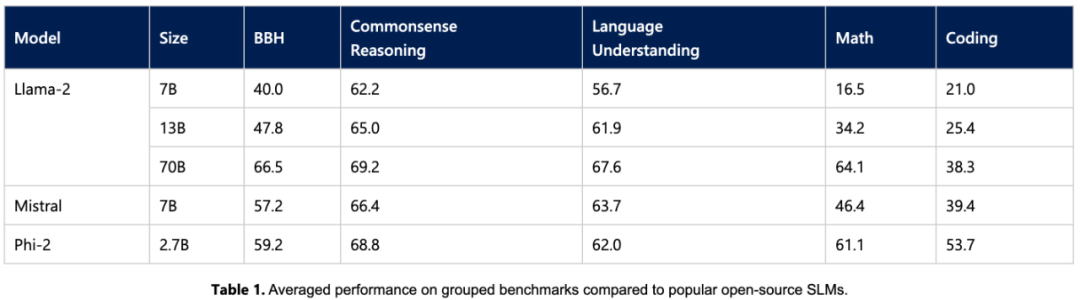
Le modèle Phi-2 n'a que 2,7 milliards de paramètres, mais il est dans diverses agrégations Sur le benchmark, les performances surpassent les modèles 7B et 13B Mistral et les modèles Llama2. Il convient de mentionner que Phi-2 est plus performant dans les tâches d'inférence en plusieurs étapes (c'est-à-dire codage et mathématiques) par rapport au modèle encombrant 25x Llama2-70B
De plus, malgré sa plus petite taille, les performances de Phi-2 2 sont comparables à celles de Phi-2. le Gemini Nano 2 récemment publié par Google Étant donné que de nombreux benchmarks publics peuvent s'infiltrer dans les données de formation, l'équipe de recherche estime que la meilleure façon de tester les performances des modèles de langage est de les tester sur des cas d'utilisation spécifiques. Par conséquent, l'étude a évalué Phi-2 à l'aide de plusieurs ensembles de données et tâches propriétaires internes de Microsoft et l'a de nouveau comparé à Mistral et Llama-2. En moyenne, Phi-2 a surpassé Mistral-7B et Mistral -7B surpasse le modèle Llama2 (7B, 13B, 70B).
L'équipe de recherche a également testé de manière approfondie les conseils communs de la communauté de recherche. Phi-2 a fonctionné comme prévu. Par exemple, pour une invite utilisée pour évaluer la capacité d'un modèle à résoudre des problèmes de physique (récemment utilisée pour évaluer le modèle Gemini Ultra), Phi-2 a donné les résultats suivants : 

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle unité représente la mémoire dans le modèle informatique de von Neumann ?
- Comment supprimer les doublons et conserver une seule donnée
- Comment importer des données d'un tableau Excel dans un autre tableau
- Quelles sont les étapes pour se connecter à la base de données à l'aide de jdbc ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?