
Maison >Périphériques technologiques >IA >Zhiyuan et d'autres institutions ont publié la stratégie de gouvernance multi-compétences du modèle LM-Cocktail.
Zhiyuan et d'autres institutions ont publié la stratégie de gouvernance multi-compétences du modèle LM-Cocktail.

- PHPzavant
- 2023-12-14 18:31:021007parcourir
Avec le développement et la mise en œuvre de la technologie des grands modèles, la « gouvernance des modèles » est devenue une proposition qui retient actuellement une attention majeure. Cependant, dans la pratique, les chercheurs sont souvent confrontés à de multiples défis.
D'une part, afin d'améliorer ses performances sur la tâche cible, les chercheurs collecteront et construiront des ensembles de données sur la tâche cible et affineront le grand modèle de langage (LLM), mais cette approche conduit généralement à d'autres problèmes que la tâche cible. L'exécution des tâches générales est considérablement réduite, ce qui endommage les capacités générales d'origine du LLM.
D'un autre côté, le nombre de modèles dans la communauté open source augmente progressivement, et les grands développeurs de modèles peuvent également accumuler de plus en plus de modèles dans plusieurs formations. Chaque modèle a ses propres avantages. pour l'exécution de la tâche ou un réglage plus précis devient plutôt un problème.
Récemment, le groupe de recherche d'informations et de calcul des connaissances de l'Intelligent Source Research Institute a publié la stratégie de gouvernance du modèle LM-Cocktail, visant à fournir aux grands développeurs de modèles un moyen peu coûteux d'améliorer continuellement les performances des modèles : la fusion informatique via un petit nombre d'échantillons Poids, utilisez la technologie de fusion de modèles pour combiner les avantages du modèle affiné et du modèle original afin d'obtenir une utilisation efficace des « ressources du modèle ».

- Technical Rapport: https://arxiv.org/abs/2311.13534
- code: https://github.com/flagopen/fagembedding/tree/master/lm_cocktail
La technologie de fusion de modèles peut améliorer les performances d'un seul modèle en fusionnant plusieurs modèles. Inspirée par cela, la stratégie LM-Cocktail calcule en outre l'importance des différents modèles pour la tâche cible, attribue des poids différents aux différents modèles et effectue une fusion de modèles sur cette base. Tout en améliorant les performances sur la tâche cible, elle reste globale. tâche. capacité puissante.
La stratégie LM-Cocktail s'apparente à la réalisation d'un cocktail. Elle permet d'agréger les avantages et les capacités de chaque modèle et de créer un modèle "multi-talentueux" avec plusieurs spécialités en déployant différents modèles
Méthode. Innovation
Plus précisément, LM-Cocktail peut fusionner des modèles existants pour générer un nouveau modèle en sélectionnant manuellement le rapport du modèle ou en saisissant un petit nombre d'échantillons pour calculer automatiquement les poids. Ce processus ne nécessite pas de remodélisation. des modèles pouvant s'adapter à diverses structures, comme le grand modèle de langage Llama, le modèle vectoriel sémantique BGE, etc.
Si les développeurs manquent de données d'étiquette pour certaines tâches cibles ou manquent de ressources informatiques pour le réglage fin du modèle, ils peuvent utiliser la stratégie LM-Cocktail pour éliminer l'étape de réglage fin du modèle. Il vous suffit de construire une très petite quantité d'échantillons de données et vous pouvez fusionner des modèles de langage à grande échelle existants dans la communauté open source pour préparer votre propre « cocktail LM »

Comme le montre la figure ci-dessus, Affiner Llama sur une tâche cible spécifique peut améliorer considérablement la précision de la tâche cible, mais nuit à la capacité générale sur d'autres tâches. L'adoption de LM-Cocktail peut résoudre ce problème.
Le cœur de LM-Cocktail est de fusionner le modèle affiné avec les paramètres de plusieurs autres modèles, intégrant les avantages de plusieurs modèles, améliorant la précision sur la tâche cible tout en conservant les capacités générales sur d'autres tâches. La forme spécifique est la suivante : étant donné une tâche cible, un modèle de base et un modèle obtenu en affinant le modèle de base sur la tâche, tout en collectant des modèles de la communauté open source ou des modèles préalablement formés pour former une collection. Calculez le poids de fusion de chaque modèle à travers un petit nombre d'échantillons sur la tâche cible, et effectuez une somme pondérée des paramètres de ces modèles pour obtenir un nouveau modèle (pour le processus spécifique, veuillez vous référer au papier ou au code open source) . S'il n'existe pas d'autres modèles dans la communauté open source, le modèle de base et le modèle affiné peuvent également être directement intégrés pour améliorer les performances des tâches en aval sans réduire les capacités générales.
Dans les scénarios d'application réels, en raison des limitations des données et des ressources, les utilisateurs peuvent ne pas être en mesure d'affiner les tâches en aval, c'est-à-dire qu'aucun modèle n'a été affiné pour la tâche cible. Dans ce cas, les utilisateurs peuvent construire une très petite quantité d'échantillons de données et intégrer de grands modèles de langage existants dans la communauté pour générer un modèle pour de nouvelles tâches et améliorer la précision de la tâche cible sans entraîner le modèle.
Résultats expérimentaux
1. Ajustement flexible pour maintenir les capacités générales
🎜.
Comme vous pouvez le voir sur la figure ci-dessus, après avoir affiné une certaine tâche cible, le modèle affiné a considérablement amélioré la précision de cette tâche, mais la précision des autres tâches générales a diminué. Par exemple, après avoir peaufiné l'ensemble de formation d'AG News, la précision de Llama sur l'ensemble de tests d'AG News est passée de 40,80 % à 94,42 %, mais sa précision sur d'autres tâches a chuté de 46,80 % à 38,58 %.
Cependant, en fusionnant simplement les paramètres du modèle affiné et du modèle original, une performance compétitive de 94,46 % est obtenue sur la tâche cible, ce qui est comparable au modèle affiné, tandis que la précision est de 47,73. % sur d'autres tâches, même légèrement plus fortes que les performances du modèle original. Sous certaines tâches, comme Helleswag, le modèle fusionné peut même surpasser le modèle affiné sur cette tâche de réglage fin, et surpasser le modèle général d'origine sur d'autres tâches, tout en héritant des avantages du modèle affiné et. Le modèle original, il les surpasse. On peut voir que le calcul du taux de fusion via LM-Cocktail et l'intégration ultérieure d'autres modèles affinés peuvent encore améliorer les performances générales sur d'autres tâches tout en garantissant la précision de la tâche cible.
2. Mélanger les modèles existants pour gérer de nouvelles tâches

Le contenu après la réécriture : Le graphique montre la tâche cible du modèle de langage MMLU
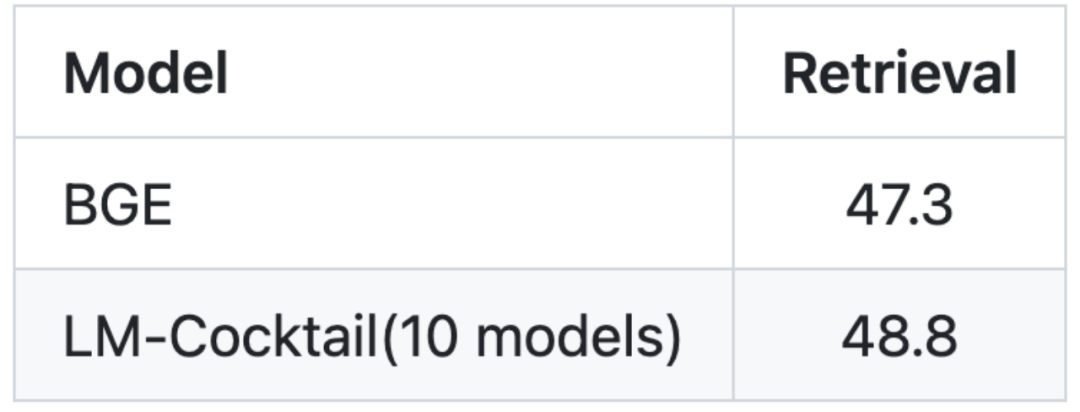
Le contenu après la réécriture : Image : La tâche cible du modèle vectoriel est la récupération (récupération d'informations)
Le réglage fin du modèle nécessite une grande quantité de données et une grande quantité de ressources informatiques, en particulier le réglage fin de grands modèles de langage, ce qui peut ne pas être possible dans situations réelles. Lorsque la tâche cible ne peut pas être affinée, LM-Cocktail peut atteindre de nouvelles capacités en mélangeant des modèles existants (provenant de la communauté open source ou de sa propre accumulation de formation historique).
En donnant seulement 5 exemples de données, LM-Cocktail calcule automatiquement les poids de fusion, filtre les modèles existants puis les fusionne pour obtenir un nouveau modèle sans utiliser une grande quantité de données pour la formation. Des expériences ont montré que le nouveau modèle généré peut atteindre une plus grande précision sur de nouvelles tâches. Par exemple, pour Llama, LM-Cocktail est utilisé pour fusionner 10 modèles existants (dont les tâches de formation ne sont pas liées à la liste MMLU), ce qui peut apporter des améliorations significatives, et est supérieur au modèle Llama qui utilise 5 exemples de données pour apprentissage du contexte.
Veuillez essayer d'utiliser LM-Cocktail, nous apprécions vos commentaires et suggestions via le numéro GitHub : https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!