
Maison >Périphériques technologiques >IA >Open source complet sans impasse, le LLM360 de l'équipe Xingbo rend les grands modèles véritablement transparents
Open source complet sans impasse, le LLM360 de l'équipe Xingbo rend les grands modèles véritablement transparents

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-12-14 18:13:44715parcourir
Les modèles open source montrent leur vitalité vigoureuse, non seulement le nombre augmente, mais les performances s'améliorent de plus en plus. Yann LeCun, lauréat du prix Turing, a également déploré : "Les modèles d'intelligence artificielle open source sont en passe de surpasser les modèles propriétaires." Caractéristiques open source, cela freine le développement du LLM. Bien que certains modèles open source offrent des choix variés aux praticiens et aux chercheurs, la plupart ne divulguent que les poids finaux du modèle ou le code d'inférence, et un nombre croissant de rapports techniques limitent leur portée à la conception de haut niveau et aux statistiques de surface. Cette stratégie de source fermée limite non seulement le développement de modèles open source, mais entrave également dans une large mesure les progrès de l'ensemble du domaine de recherche LLM. Cela signifie que ces modèles doivent être partagés de manière plus complète et approfondie, y compris les données de formation, algorithmiques. les détails, les défis de mise en œuvre et les détails de l’évaluation des performances.
Des chercheurs de Cerebras, Petuum et MBZUAI ont proposé conjointement LLM360. Il s'agit d'une initiative LLM open source complète qui préconise de fournir à la communauté tout ce qui concerne la formation LLM, y compris le code et les données de formation, les points de contrôle du modèle et les résultats intermédiaires. L’objectif de LLM360 est de rendre le processus de formation LLM transparent et reproductible pour tous, favorisant ainsi le développement d’une recherche ouverte et collaborative en intelligence artificielle.
 Adresse papier : https://arxiv.org/pdf/2312.06550.pdf
Adresse papier : https://arxiv.org/pdf/2312.06550.pdf
- Page Web du projet : https://www.llm360.ai/
- Blog : https://www.llm360.ai/blog/introducing-llm360-fully-transparent-open-source-llms.html
- Les chercheurs ont formulé l'architecture de LLM360, en se concentrant sur son Principes de conception et justification d'être entièrement open source. Ils spécifient les composants du framework LLM360, y compris des détails spécifiques tels que les ensembles de données, le code et la configuration, les points de contrôle du modèle, les métriques, etc. LLM360 donne un exemple de transparence pour les modèles open source actuels et futurs. Les chercheurs ont publié deux modèles de langage à grande échelle pré-entraînés à partir de zéro dans le cadre open source de LLM360 : AMBER et CRYSTALCODER. AMBER est un modèle en langue anglaise 7B pré-entraîné basé sur des jetons 1,3T. CRYSTALCODER est un modèle 7B en anglais et en langage de code pré-entraîné basé sur des jetons 1,4T. Dans cet article, les chercheurs résument les détails du développement, les résultats de l’évaluation préliminaire, les observations, ainsi que les expériences et leçons tirées de ces deux modèles. Notamment, au moment de la sortie, AMBER et CRYSTALCODER ont enregistré respectivement 360 et 143 points de contrôle de modèle pendant la formation.
Maintenant, jetons un coup d'œil aux détails de l'article
 Le cadre de LLM360
Le cadre de LLM360
LLM360 fournira une norme sur les données et les codes qui doivent être collectés pendant le LLM. processus de pré-formation. Pour garantir que les travaux existants puissent être mieux diffusés et partagés dans la communauté. Il contient principalement les parties suivantes :
1. Ensemble de données de formation et code de traitement des données
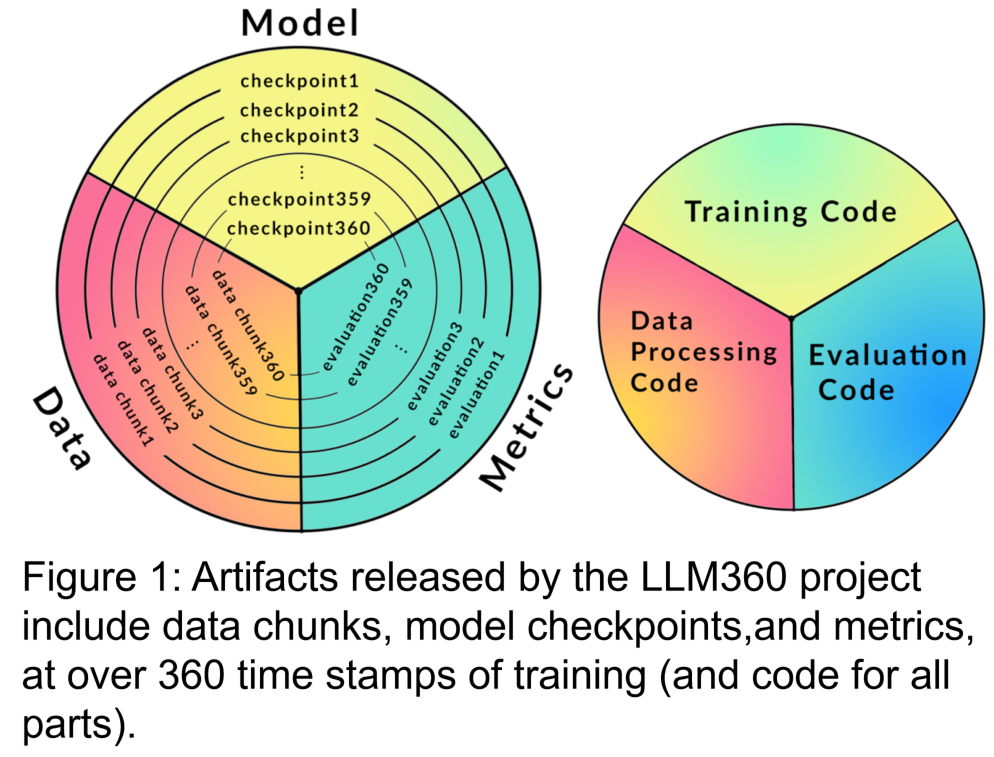
Le contenu à réécrire est : 2. Code de formation, hyperparamètres et configuration
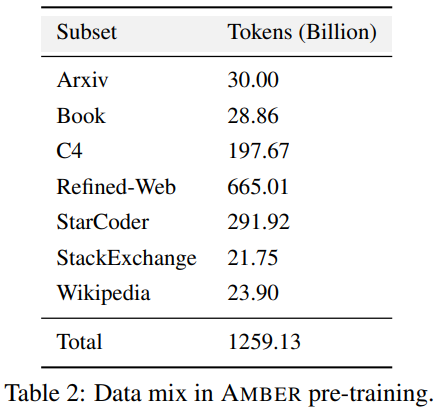
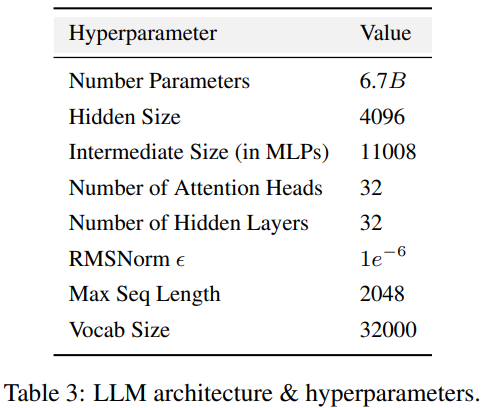
Le code de formation, les hyperparamètres et les configurations ont un impact significatif sur les performances et la qualité de la formation LLM, mais ne sont pas toujours divulgués publiquement. Dans LLM360, les chercheurs open source tous les codes de formation, les paramètres de formation et les configurations système du cadre de pré-formation. 3. Le point de contrôle du modèle est réécrit comme suit : 3. Point de contrôle du modèle Il est également très utile de sauvegarder régulièrement les points de contrôle du modèle. Non seulement ils sont essentiels pour la récupération après échec pendant la formation, mais ils sont également utiles pour la recherche post-formation. Ces points de contrôle permettent aux chercheurs ultérieurs de continuer à former le modèle à partir de plusieurs points de départ sans avoir à s'entraîner à partir de zéro, ce qui contribue à la reproductibilité et à l'intégration. recherche approfondie. 4. Indicateurs de performance La formation d'un LLM prend souvent des semaines, voire des mois, et la tendance évolutive au cours de la formation peut fournir des informations précieuses. Cependant, les journaux détaillés et les mesures intermédiaires de la formation ne sont actuellement disponibles que pour ceux qui les ont expérimentés, ce qui entrave une recherche approfondie sur le LLM. Ces statistiques contiennent souvent des informations clés difficiles à détecter. Même une simple analyse telle que des calculs de variance sur ces mesures peut révéler des résultats importants. Par exemple, l’équipe de recherche GLM a proposé un algorithme de retrait de gradient qui gère efficacement les pics de perte et les pertes de NaN en analysant le comportement de spécification du gradient. AMBER est le premier membre de la "famille" LLM360, et ses versions affinées : AMBERCHAT et AMBERSAFE ont également été publiées. Ce qui doit être réécrit : données et détails du modèle Le tableau 2 détaille l'ensemble de données de pré-entraînement d'AMBER, qui contient 1,26 marqueurs T. Ceux-ci incluent les méthodes de prétraitement des données, les formats, les ratios de mélange des données, ainsi que les détails architecturaux et les hyperparamètres de pré-entraînement spécifiques du modèle AMBER. Pour des informations détaillées, veuillez vous référer à la page d'accueil du projet de la base de code LLM360 AMBER adopte la même structure de modèle que LLaMA 7B4. Le tableau 3 résume la configuration structurelle détaillée de LLM en avance En termes d'entraînement et d'hyperparamètres, les chercheurs ont fait de leur mieux pour suivre les hyperparamètres de pré-entraînement de LLaMA. AMBER est formé à l'aide de l'optimiseur AdamW et les hyperparamètres sont : β₁=0,9, β₂=0,95. De plus, les chercheurs ont publié plusieurs versions affinées d'AMBER : AMBERCHAT et AMBERSAFE. AMBERCHAT est affiné sur la base de l'ensemble de données de formation aux instructions de WizardLM. Pour plus de détails sur les paramètres, veuillez vous référer au texte original Afin d'atteindre l'objectif de ne pas changer le sens original, le contenu doit être réécrit en chinois. Ce qui suit est une réécriture de « Expériences et résultats » :
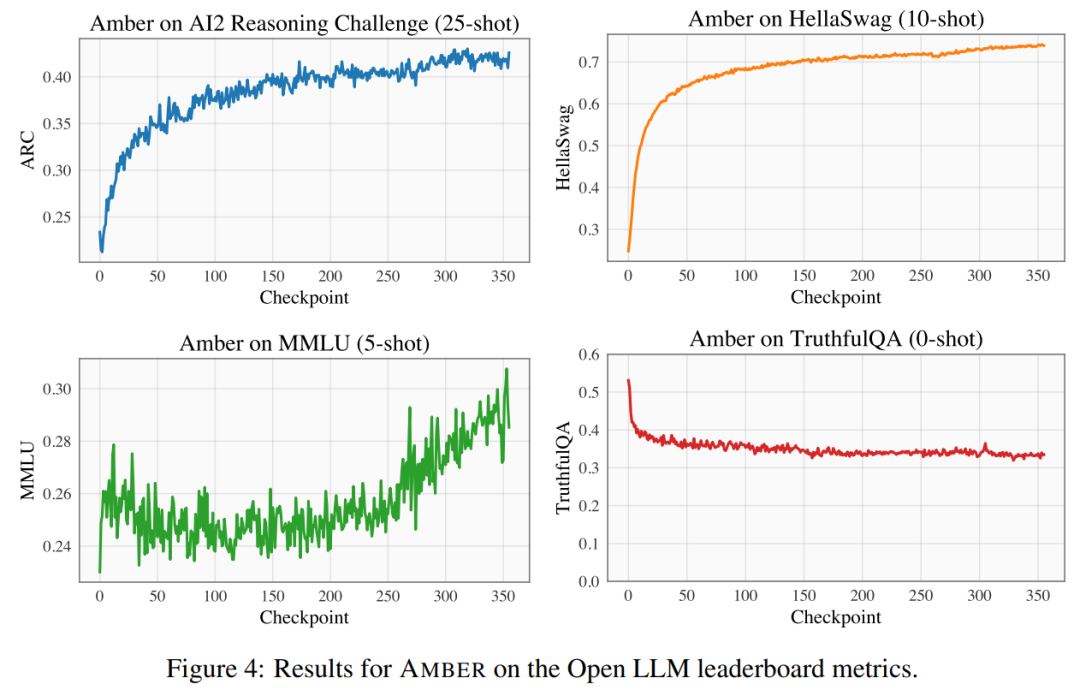
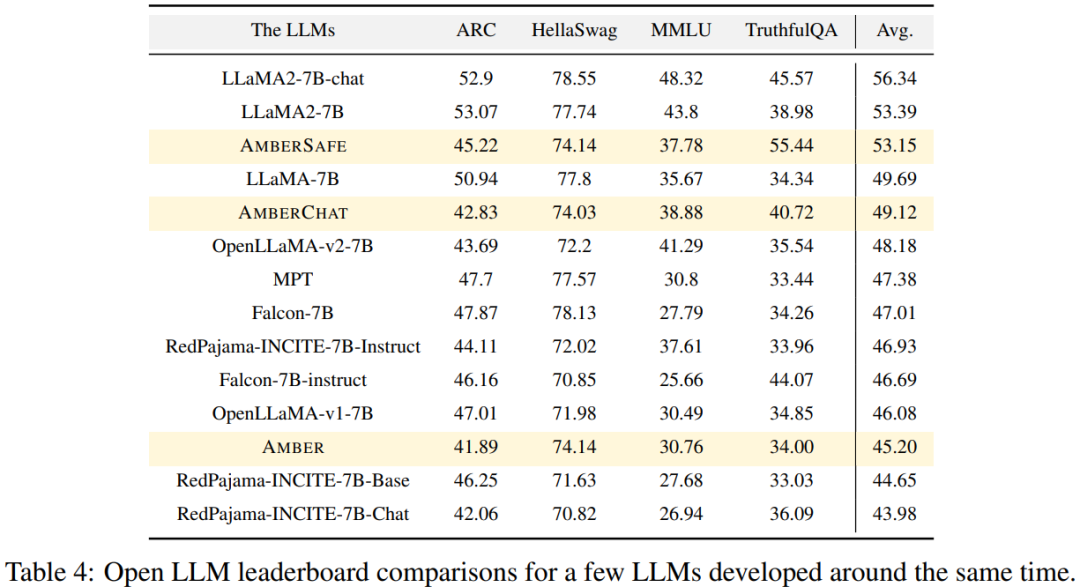
Mener des expériences et analyser les résultats Les chercheurs ont utilisé quatre ensembles de données de référence sur le classement Open LLM pour évaluer les performances d'AMBER. Comme le montre la figure 4, dans les ensembles de données HellaSwag et ARC, le score AMBER augmente progressivement au cours de la période de pré-entraînement, tandis que dans l'ensemble de données TruthfulQA, le score diminue au fur et à mesure de la formation. Dans l'ensemble de données MMLU, le score d'AMBER a chuté au cours de la phase initiale de pré-entraînement, puis a commencé à augmenter Dans le tableau 4, le chercheur a comparé les performances du modèle d'AMBER avec OpenLLaMA, RedPajama-INCITE, Les modèles Falcon et MPT entraînés pendant des périodes similaires ont été comparés. De nombreux modèles sont inspirés de LLaMA. On peut constater qu'AMBER obtient de meilleurs résultats sur MMLU mais légèrement moins bien sur ARC. Les performances d'AMBER sont relativement solides par rapport à d'autres modèles similaires. Le deuxième membre de la "grande famille" LLM360 est CrystalCoder. CrystalCoder est un modèle de langage 7B formé sur des jetons de 1,4 T, atteignant un équilibre entre les capacités de codage et de langage. Contrairement à la plupart des LLM de code précédents, CrystalCoder est formé sur un mélange judicieux de données de texte et de code pour maximiser l'utilité dans les deux domaines. Par rapport à Code Llama 2, les données de code de CrystalCoder sont introduites plus tôt dans le processus de pré-formation. De plus, les chercheurs ont formé CrystalCoder sur Python et les langages de programmation Web pour améliorer son utilité en tant qu'assistant de programmation. Architecture de modèle reconstruite CrystalCoder adopte une architecture très similaire à LLaMA 7B, en ajoutant un paramétrage de mise à jour maximale (muP). En plus de ce paramétrage spécifique, les chercheurs ont également apporté quelques modifications. De plus, les chercheurs ont également utilisé LayerNorm au lieu de RMSNorm car l'architecture CG-1 prend en charge un calcul efficace de LayerNorm. Afin d'atteindre l'objectif de ne pas changer le sens original, le contenu doit être réécrit en chinois. Ce qui suit est une réécriture de « Expériences et résultats » :
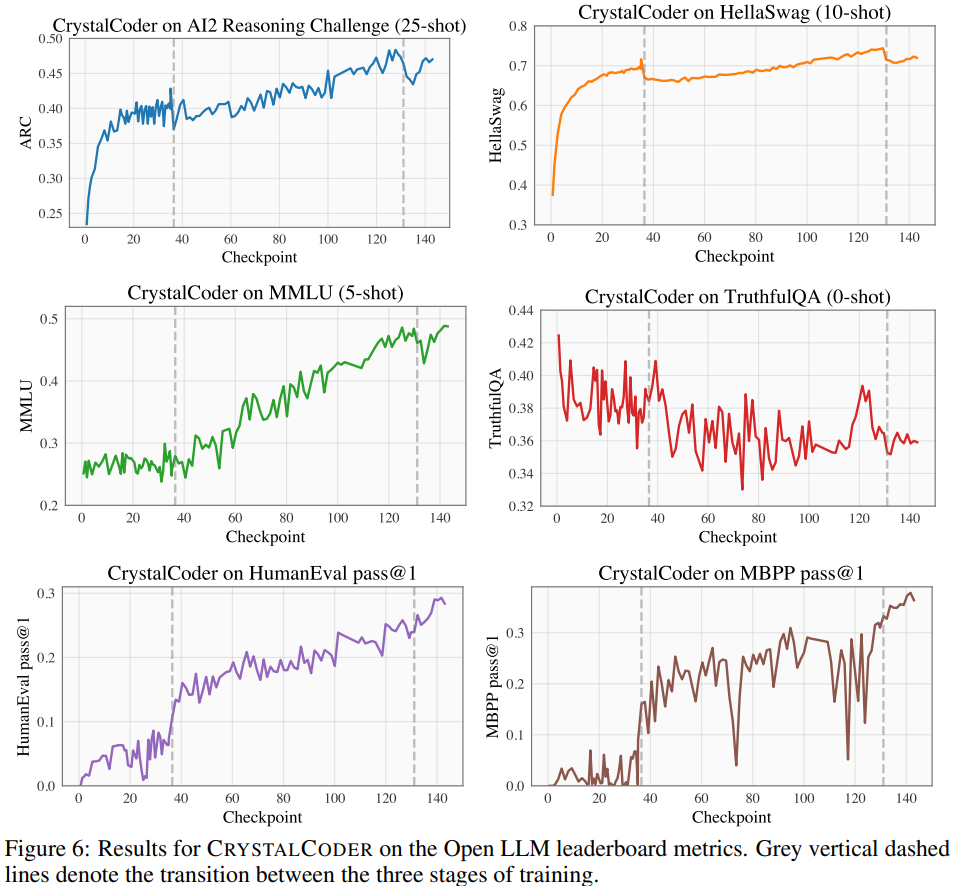
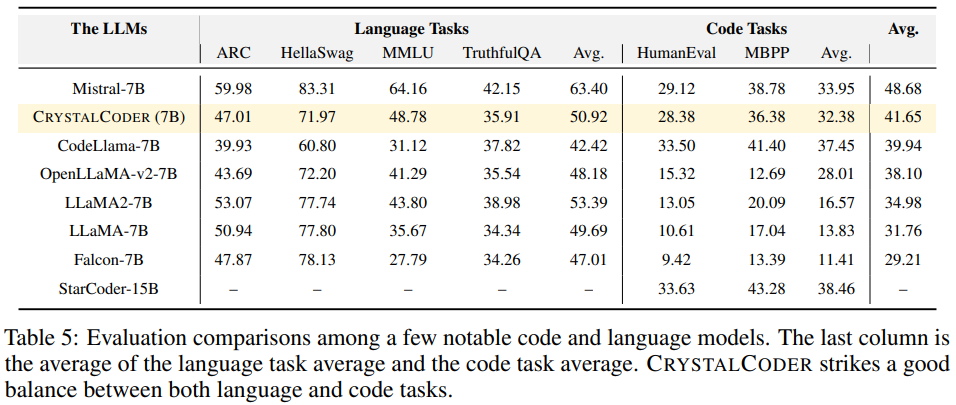
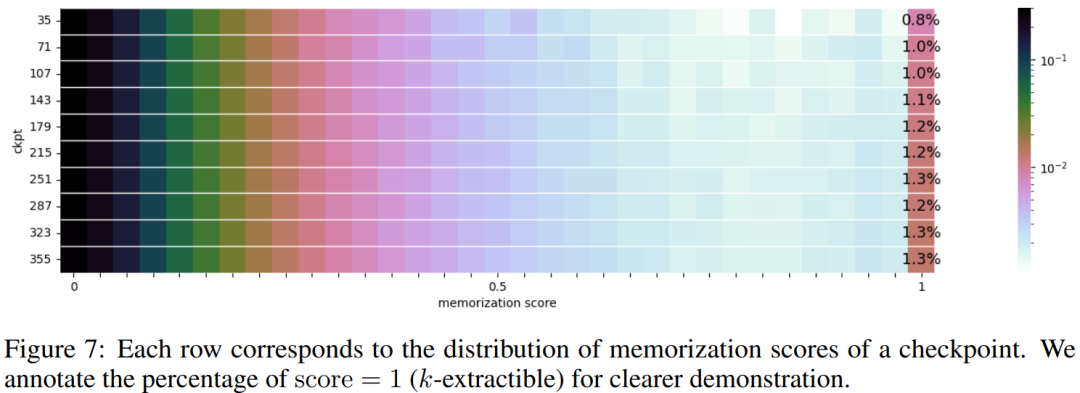
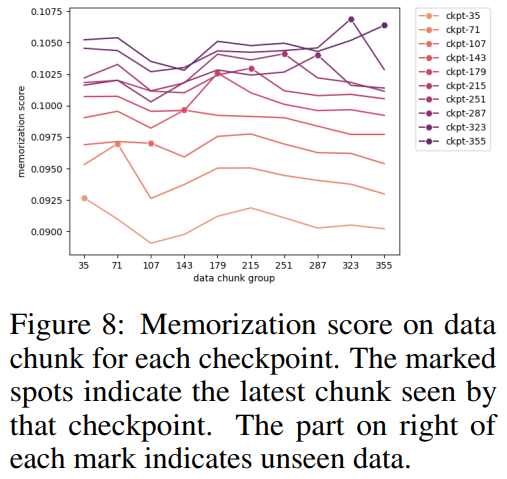
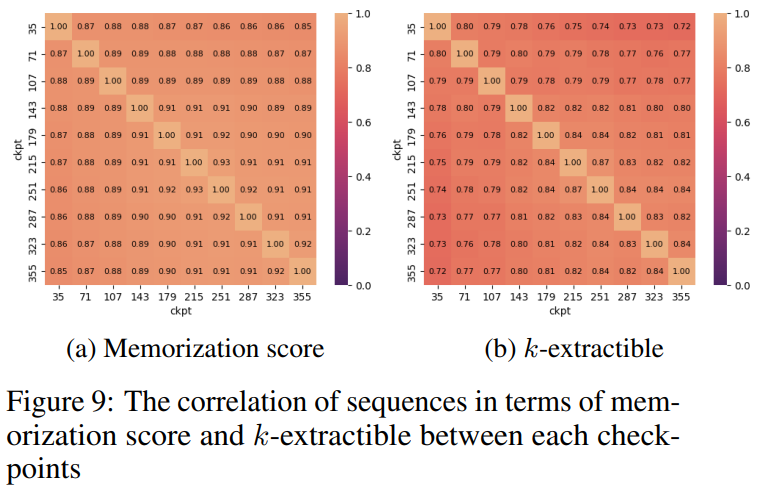
Mener des expériences et analyser les résultats Sur le classement Open LLM, les chercheurs ont effectué des tests de référence sur le modèle, comprenant quatre ensembles de données de référence et des ensembles de données de référence d'encodage. Comme le montre la figure 6 En référence au tableau 5, nous pouvons voir que CrystalCoder a atteint un bon équilibre entre les tâches de langage et les tâches de code Selon des recherches antérieures, En analysant les points de contrôle intermédiaires du modèle, une recherche approfondie est possible. Les chercheurs espèrent que LLM360 fournira à la communauté une référence et une ressource de recherche utiles. À cette fin, ils ont publié la version initiale du projet ANALYSIS360, un référentiel organisé d'analyse à multiples facettes du comportement du modèle, y compris les caractéristiques du modèle et les résultats de l'évaluation en aval comme exemple d'analyse sur une série de points de contrôle du modèle, le les chercheurs ont mené une étude préliminaire sur la mémoïsation en LLM. Des recherches récentes ont montré que les LLM peuvent mémoriser de grandes portions de données d'entraînement et que ces données peuvent être récupérées avec des invites appropriées. Non seulement cette mémorisation pose des problèmes de fuite de données d'entraînement privées, mais elle peut également dégrader les performances de LLM si les données d'entraînement contiennent des répétitions ou des spécificités. Les chercheurs ont rendu publics tous les points de contrôle et données afin qu'une analyse complète de la mémorisation tout au long de la phase d'entraînement puisse être menée Voici la méthode de score de mémorisation utilisée dans cet article, ce qui signifie qu'après une invite de longueur k, le la longueur suivante est l La précision du jeton. Pour les paramètres de score de mémoire spécifiques, veuillez vous référer à l'article original. La distribution des scores de mémorisation de 10 points de contrôle sélectionnés est présentée dans la figure 7. Le chercheur a regroupé les blocs de données en fonction des points de contrôle sélectionnés, et les scores mémorisés pour chaque bloc Les groupes pour chaque point de contrôle sont tracés dans la figure 8. Ils ont constaté que les points de contrôle AMBER mémorisaient mieux les dernières données que les données précédentes. De plus, pour chaque bloc de données, le score de mémorisation diminue légèrement après un entraînement supplémentaire, mais continue ensuite d'augmenter. La figure 9 montre la corrélation entre les séquences dans les scores de mémorisation et les valeurs k extractibles. On constate qu’il existe une forte corrélation entre les points de contrôle. Le chercheur a résumé les observations et certaines implications d'AMBER et CRYSTALCODER. Ils affirment que la pré-formation est une tâche à forte intensité de calcul que de nombreux laboratoires universitaires ou petites institutions ne peuvent pas se permettre. Ils espèrent que LLM360 pourra fournir des connaissances complètes et permettre aux utilisateurs de comprendre ce qui se passe pendant la pré-formation LLM sans avoir à le faire eux-mêmes Veuillez vérifier le texte original pour plus de détailsAmber

CRYSTALCODER

ANALYSIS360
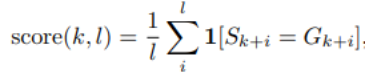
Résumé
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!