
Maison >Périphériques technologiques >IA >SDXL Turbo et LCM ouvrent l'ère de la génération en temps réel de dessins IA : aussi rapides que la saisie, et les images apparaissent instantanément
SDXL Turbo et LCM ouvrent l'ère de la génération en temps réel de dessins IA : aussi rapides que la saisie, et les images apparaissent instantanément

- PHPzavant
- 2023-11-30 14:14:501821parcourir
Stability AI a lancé mardi une nouvelle génération de modèle de synthèse d'image - Stable Diffusion XL Turbo, qui a suscité une réponse enthousiaste de la part du public. De nombreuses personnes ont dit qu'utiliser ce modèle pour la génération d'image en texte n'a jamais été aussi simple
Entrez vos idées dans la zone de saisie, SDXL Turbo répondra rapidement et générera le contenu correspondant sans aucune autre opération. Peu importe que vous saisissiez plus ou moins de contenu, cela n'affectera pas sa vitesse


Vous pouvez utiliser des images existantes pour compléter votre création plus en détail. Prenez simplement un morceau de papier blanc et dites à SDXL Turbo que vous voulez un chat blanc. Avant de finir de taper, le petit chat blanc est déjà apparu entre vos mains
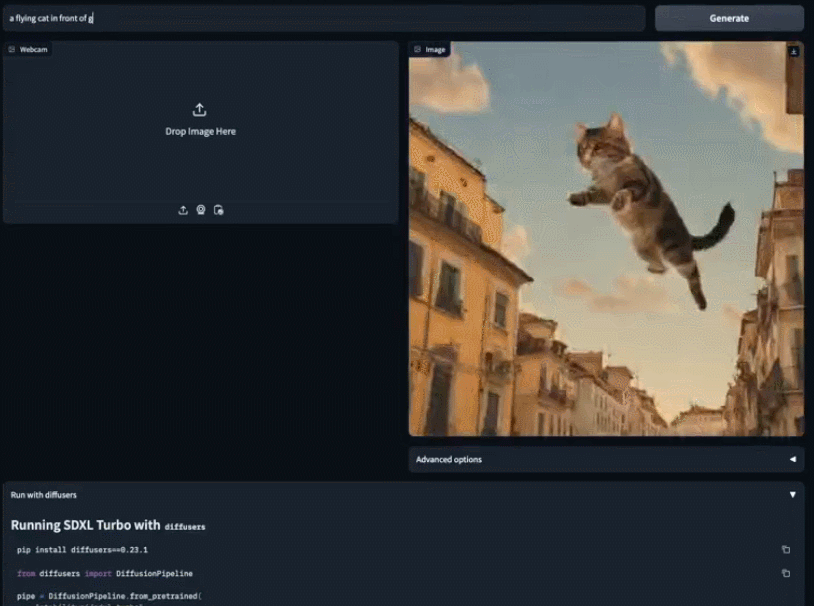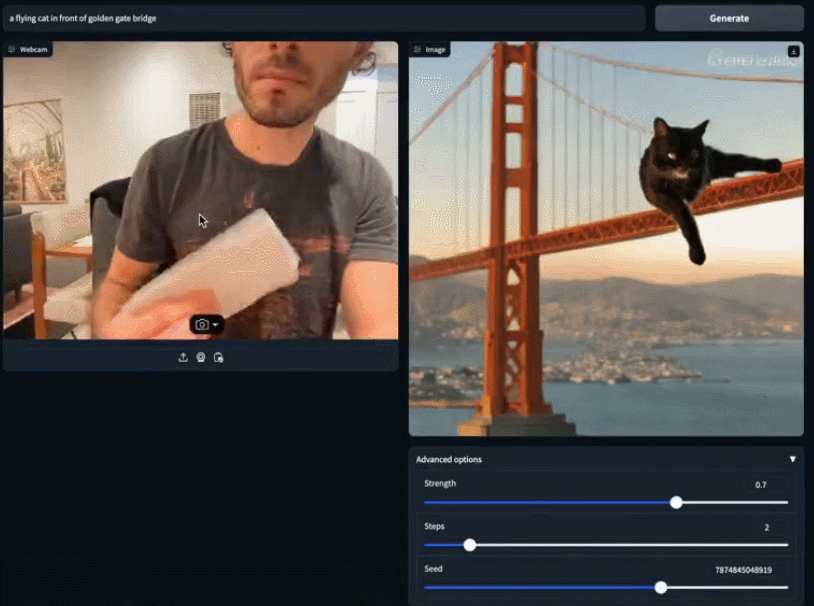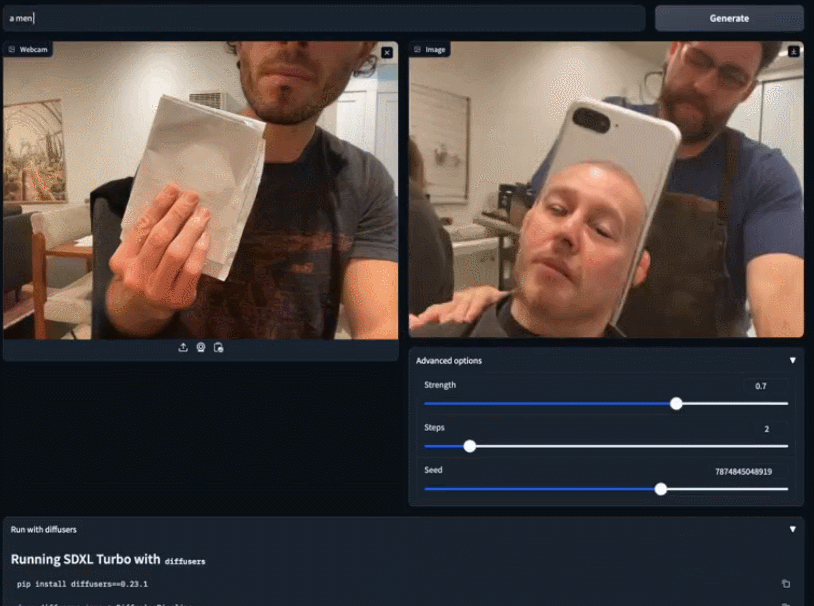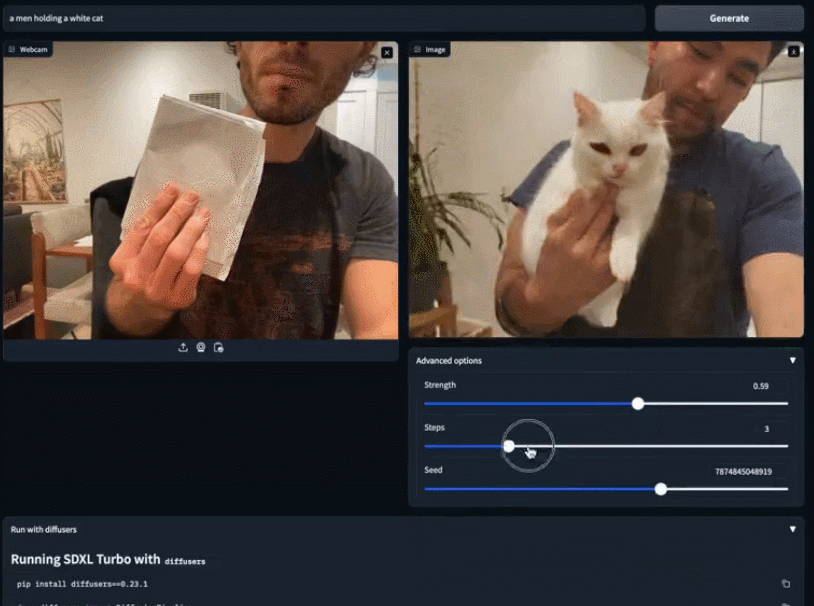
La vitesse du modèle SDXL Turbo atteint C'est. presque « en temps réel », et les gens ne peuvent s'empêcher de se demander : le modèle de génération d'images peut-il être utilisé à d'autres fins ? Quelqu'un directement connecté au jeu et ayant obtenu un écran de transfert de style 2fps :
D'après le officiel Selon le blog, sur l'A100, SDXL Turbo peut générer une image 512x512 en 207 millisecondes (codage à la volée + étape de débruitage unique + décodage, fp16), dont une seule évaluation directe UNet prend 67 millisecondes. 
On peut ainsi juger que Vincent Picture est entré dans l'ère du "temps réel".
Une telle efficacité de « génération instantanée » ressemble quelque peu au modèle Tsinghua LCM qui est devenu populaire il n'y a pas si longtemps, mais le contenu technique derrière eux est différent. Stability a détaillé le fonctionnement interne du modèle dans un document de recherche publié au même moment. La recherche se concentre sur une technologie appelée Distillation par diffusion contradictoire (ADD). L'un des avantages revendiqués de SDXL Turbo est sa similitude avec les réseaux contradictoires génératifs (GAN), en particulier dans la génération de sorties d'images en une seule étape.
Adresse papier : https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1701197769659/adversarial_diffusion_distillation. pdf 
Détails papier
En bref, la distillation par diffusion contradictoire est une méthode générale qui peut réduire le nombre d'étapes d'inférence d'un modèle de diffusion pré-entraîné à 1 à 4 étapes d'échantillonnage tout en maintenant une fidélité d'échantillonnage élevée et en améliorant potentiellement encore les performances globales du modèle.
À cette fin, les chercheurs ont introduit une combinaison de deux objectifs de formation : (i) la perte contradictoire et (ii) la perte de distillation correspondant au SDS. La perte contradictoire oblige le modèle à générer directement des échantillons qui se trouvent sur le collecteur d’images réelles à chaque passage avant, évitant ainsi le flou et d’autres artefacts courants dans d’autres méthodes de distillation. La perte de distillation utilise un autre modèle de diffusion pré-entraîné (et fixe) comme enseignant, exploitant efficacement ses connaissances approfondies et conservant la forte compositionnalité observée dans les grands modèles de diffusion. Au cours du processus d’inférence, les chercheurs n’ont pas utilisé de guidage sans classificateur, réduisant ainsi les besoins en mémoire. Ils conservent la capacité du modèle à améliorer les résultats grâce à un raffinement itératif, un avantage par rapport aux précédentes approches basées sur le GAN en une seule étape.
Les étapes de formation sont présentées dans la figure 2 :
Le tableau 1 montre les résultats de l'expérience d'ablation. Voici les principales conclusions : 
.
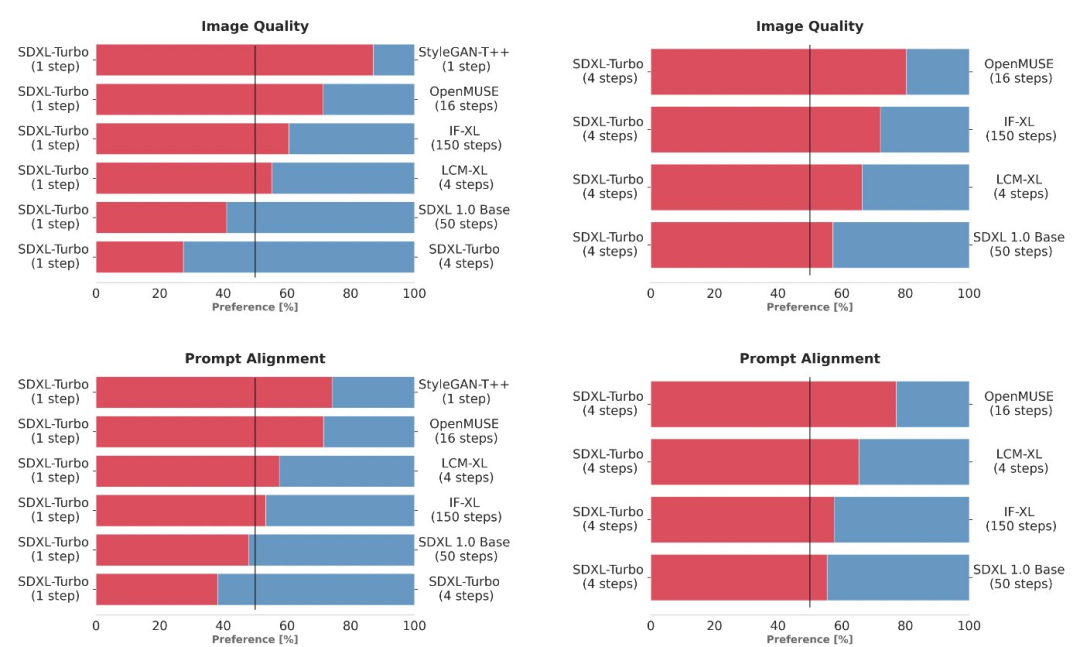
Ce qui suit est une comparaison avec d'autres modèles SOTA. Ici, les chercheurs n'ont pas utilisé d'indicateurs automatisés, mais ont choisi une méthode d'évaluation des préférences des utilisateurs plus fiable, l'objectif étant d'évaluer la conformité rapide et l'image globale.
Pour comparer plusieurs variantes de modèles différentes (StyleGAN-T++, OpenMUSE, IF-XL, SDXL et LCM-XL), l'expérience utilise la même invite pour générer la sortie. Lors de tests à l'aveugle, le SDXL Turbo a battu la configuration en 4 étapes du LCM-XL en une seule étape, et a battu la configuration en 50 étapes du SDXL en seulement 4 étapes. À partir de ces résultats, on peut voir que SDXL Turbo surpasse les modèles multi-étapes de pointe tout en réduisant considérablement les besoins de calcul sans sacrifier la qualité de l'image. tracé des scores
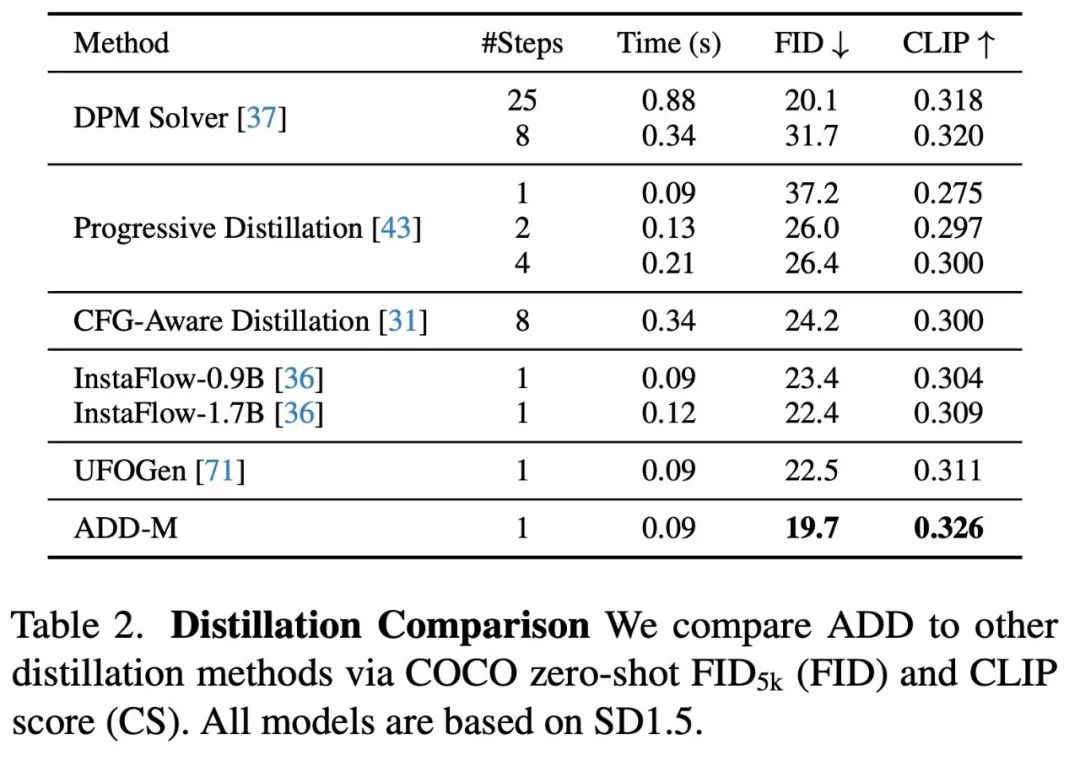
Dans le tableau 2, une comparaison de différentes méthodes d'échantillonnage et de distillation en quelques étapes utilisant le même modèle de base est effectuée. Les résultats montrent que la méthode ADD surpasse toutes les autres méthodes, y compris le solveur DPM standard en 8 étapes

En complément des résultats expérimentaux quantitatifs, l'article montre également des résultats expérimentaux qualitatifs, montrant ADD- Capacité de XL à améliorer les échantillons initiaux. La figure 3 compare ADD-XL (1 étape) avec la meilleure référence actuelle dans les schémas en quelques étapes. La figure 4 décrit le processus d'échantillonnage itératif d'ADD-XL. La figure 8 fournit une comparaison directe d'ADD-XL avec son modèle d'enseignant, SDXL-Base. Comme le montrent les études d'utilisateurs, ADD-XL surpasse le modèle enseignant en termes de qualité et d'alignement rapide.

 Pour plus de détails sur la recherche, veuillez vous référer à l'article original
Pour plus de détails sur la recherche, veuillez vous référer à l'article original
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comprendre le modèle de boîte CSS : Comprendre ce qu'est le modèle de boîte CSS en 5 minutes ?
- Comment supprimer une table dans la base de données dans MySQL
- Comment supprimer des modèles redondants dans ZBrush
- Décrivez brièvement quelle est l'unité de stockage des données dans un ordinateur ?
- Quel est le processus de conversion d'un diagramme e-r en un modèle de données relationnel ?