
Maison >Périphériques technologiques >IA >Sparse4D v3 est là ! Faire progresser la détection et le suivi 3D de bout en bout
Sparse4D v3 est là ! Faire progresser la détection et le suivi 3D de bout en bout

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-24 11:21:35878parcourir
Nouveau titre : Sparse4D v3 : Avancement de la technologie de détection et de suivi 3D de bout en bout
Lien papier : https://arxiv.org/pdf/2311.11722.pdf
Le contenu qui doit être réécrit est : Lien de code : https:// github.com/linxuewu/Sparse4D
Contenu réécrit : L'affiliation de l'auteur est Horizon Corporation

Idée de thèse :
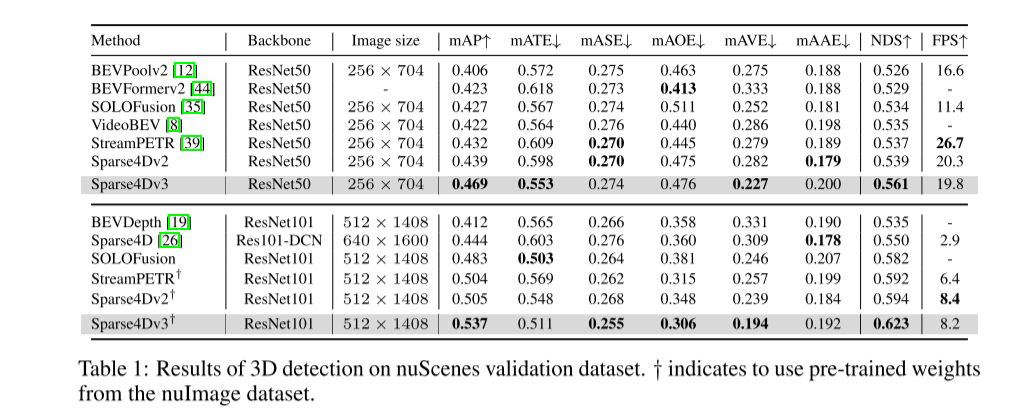
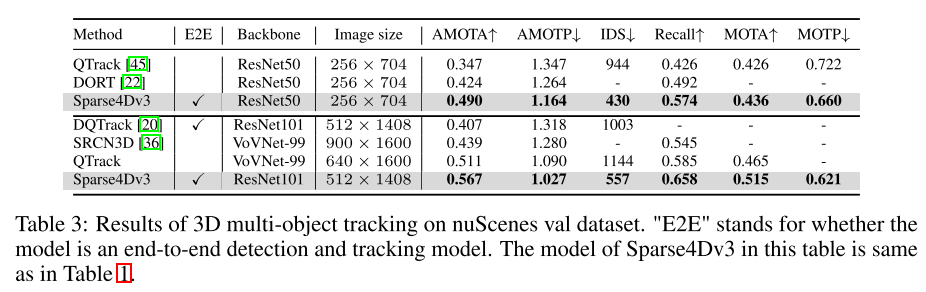
Dans le système de perception de la conduite autonome, la détection et le suivi 3D sont deux tâches de base. Cet article examine plus en profondeur ce domaine en s'appuyant sur le framework Sparse4D. Cet article présente deux tâches de formation auxiliaires (débruitage d'instance temporelle et estimation de la qualité) et propose une attention découplée pour améliorer la structure, améliorant ainsi considérablement les performances de détection. De plus, cet article étend le détecteur au tracker en utilisant une méthode simple qui attribue des identifiants d'instance lors de l'inférence, soulignant ainsi les avantages des algorithmes basés sur des requêtes. Des expériences approfondies sur le benchmark nuScenes valident l'efficacité des améliorations proposées. En utilisant ResNet50 comme épine dorsale, mAP, NDS et AMOTA ont augmenté respectivement de 3,0 %, 2,2 % et 7,6 %, atteignant respectivement 46,9 %, 56,1 % et 49,0 %. Le meilleur modèle de cet article a obtenu 71,9 % de NDS et 67,7 % d'AMOTA sur l'ensemble de tests nuScenes
Principales contributions :
Sparse4D-v3 est un puissant framework de perception 3D qui propose trois stratégies efficaces : Instances de séries temporelles Débruitage, qualité estimation et découplage de l'attention
Cet article étend Sparse4D dans un modèle de suivi de bout en bout.
Cet article démontre l'efficacité des améliorations de nuScenes, atteignant des performances de pointe dans les tâches de détection et de suivi.
Conception du réseau :
Tout d'abord, on observe que les algorithmes clairsemés sont confrontés à de plus grands défis de convergence par rapport aux algorithmes denses, affectant ainsi les performances finales. Ce problème a été bien étudié dans le domaine de la détection 2D [17, 48, 53], principalement parce que les algorithmes clairsemés utilisent une correspondance d'échantillons positifs un à un. Cette méthode d'appariement est instable dans les premiers stades de la formation, et par rapport à la correspondance un-à-plusieurs, le nombre d'échantillons positifs est limité, réduisant ainsi l'efficacité de la formation du décodeur. De plus, Sparse4D utilise un échantillonnage de caractéristiques clairsemées au lieu d'une attention croisée globale, ce qui entrave encore davantage la convergence de l'encodeur en raison de la rareté des échantillons positifs. Dans Sparse4Dv2, une supervision profonde et dense est introduite pour atténuer partiellement ces problèmes de convergence rencontrés par les encodeurs d’images. L'objectif principal de cet article est d'améliorer les performances du modèle en se concentrant sur la stabilité de la formation du décodeur. Cet article utilise la tâche de débruitage comme supervision auxiliaire et étend la technologie de débruitage de la détection d'image unique 2D à la détection de séries temporelles 3D. Cela garantit non seulement une correspondance stable des échantillons positifs, mais augmente également considérablement le nombre d’échantillons positifs. En outre, cet article introduit également une tâche d'évaluation de la qualité en tant que supervision auxiliaire. Cela rend le score de confiance de sortie plus raisonnable, améliore la précision du classement des résultats de détection et obtient ainsi des indicateurs d'évaluation plus élevés. De plus, cet article améliore la structure des modules d'instance d'auto-attention et d'attention croisée temporelle dans Sparse4D, et introduit un mécanisme d'attention découplé visant à réduire l'interférence des caractéristiques dans le processus de calcul du poids d'attention. En utilisant des intégrations d'ancres et des caractéristiques d'instance comme entrées dans le calcul de l'attention, les instances présentant des valeurs aberrantes dans les pondérations d'attention peuvent être réduites. Cela peut refléter plus précisément la corrélation entre les fonctionnalités cibles, obtenant ainsi une agrégation correcte des fonctionnalités. Cet article utilise des connexions plutôt que des mécanismes d’attention pour réduire considérablement cette erreur. Cette méthode d'augmentation présente des similitudes avec le DETR conditionnel, mais la principale différence est que cet article met l'accent sur l'attention entre les requêtes, tandis que le DETR conditionnel se concentre sur l'attention croisée entre les requêtes et les caractéristiques de l'image. De plus, cet article implique également une méthode d'encodage unique
Afin d'améliorer les capacités de bout en bout du système de perception, cet article étudie la méthode d'intégration de tâches de suivi multi-cibles 3D dans le framework Sparse4D pour sortir directement le trajectoire de mouvement de la cible. Contrairement aux méthodes de suivi basées sur la détection, cet article intègre toutes les fonctions de suivi dans le détecteur en éliminant le besoin d'association et de filtrage des données. De plus, contrairement aux méthodes existantes de détection et de suivi des articulations, notre tracker ne nécessite pas de modification ou d'ajustement de la fonction de perte pendant l'entraînement. Il ne nécessite pas de fournir des identifiants de vérité terrain, mais implémente une régression instance-to-track prédéfinie. L'implémentation du suivi de cet article intègre entièrement le détecteur et le tracker, sans modifier le processus de formation du détecteur, et ne nécessite pas de réglage supplémentaire
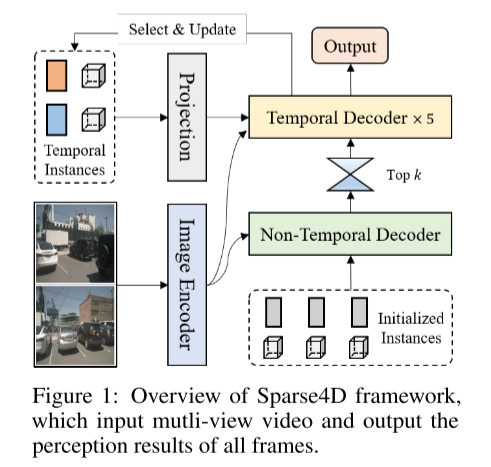
Il s'agit de la figure 1 sur la vue d'ensemble du framework Sparse4D. est une vidéo multi-vues et la sortie est constituée de tous les résultats perceptuels des images
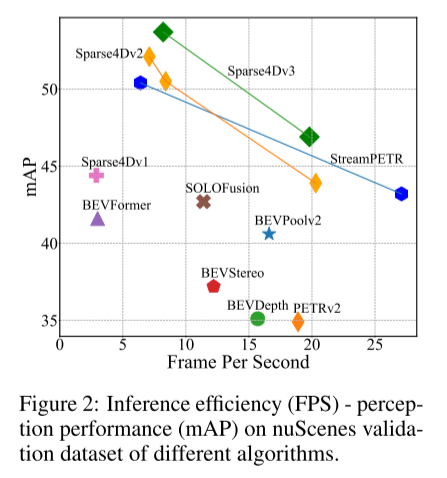
Figure 2 : Efficacité d'inférence (FPS) - performances perceptuelles (mAP) sur l'ensemble de données de validation nuScenes de différents algorithmes.

Figure 3 : Visualisation des poids d'attention en cas d'auto-attention : 1) La première ligne montre les poids d'attention en cas d'auto-attention ordinaire, où le piéton dans le cercle rouge montre un accident avec le véhicule cible (case verte) Pertinence. 2) La deuxième ligne montre le poids de l’attention en attention découplée, ce qui résout efficacement ce problème.
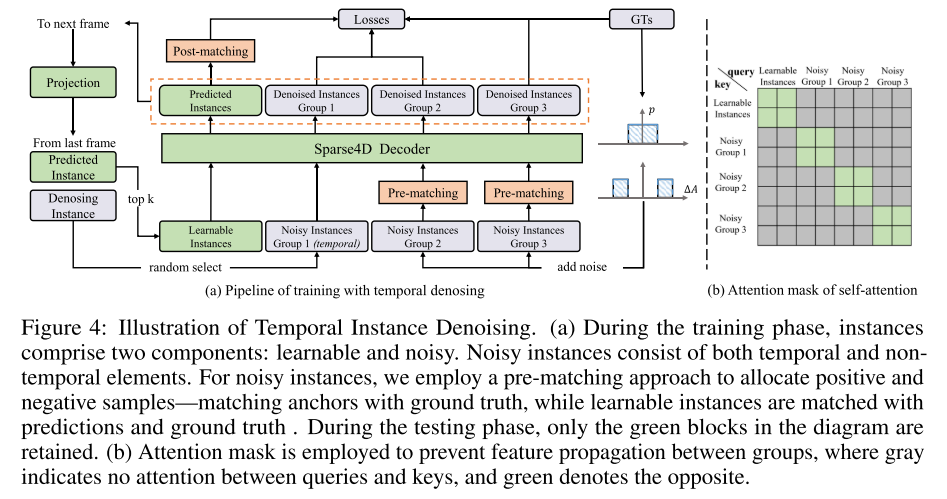
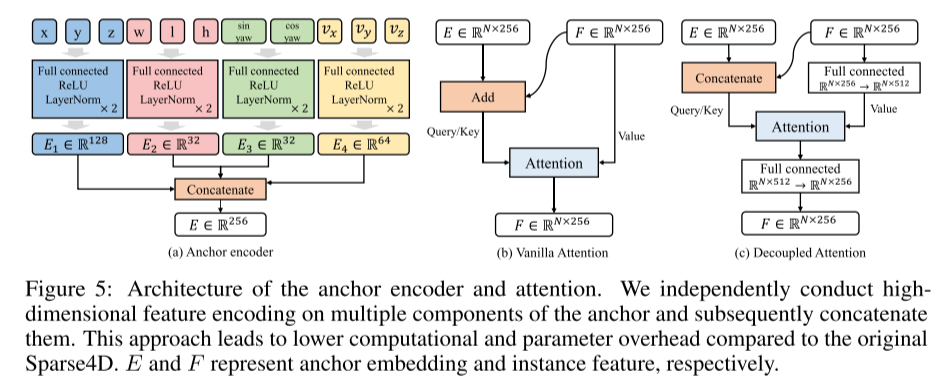
La quatrième image montre un exemple de débruitage d'instance de série chronologique. Pendant la phase de formation, les instances se composent de deux parties : apprenable et bruyante. Les instances de bruit sont composées d'éléments temporels et non temporels. Cet article adopte une méthode de pré-appariement pour allouer des échantillons positifs et négatifs, c'est-à-dire faire correspondre les ancres avec la vérité terrain, tandis que les instances apprenables sont mises en correspondance avec les prédictions et la vérité terrain. Pendant la phase de test, seuls les blocs verts restent. Pour empêcher les fonctionnalités de se propager entre les groupes, un masque d'attention est utilisé. Le gris signifie qu'il n'y a pas d'attention entre les requêtes et les clés, le vert signifie le contraire. Veuillez consulter la Figure 5 : Architecture de l'encodeur d'ancrage et de l'attention. Cet article code indépendamment les caractéristiques de grande dimension de plusieurs composants d’ancres, puis les concatène. Cette approche réduit la surcharge de calcul et de paramètres par rapport au Sparse4D original. E et F représentent respectivement l'intégration d'ancres et les fonctionnalités d'instance.

Citation :
 Lin, X., Pei, Z., Lin, T., Huang, L. et Su, Z. (2023 : Faire progresser la détection et le suivi 3D de bout en bout). .
Lin, X., Pei, Z., Lin, T., Huang, L. et Su, Z. (2023 : Faire progresser la détection et le suivi 3D de bout en bout). .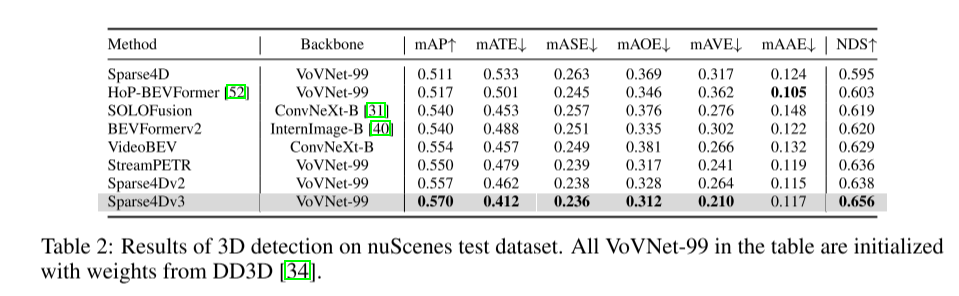
 ArXiv./abs/2311.11722
ArXiv./abs/2311.11722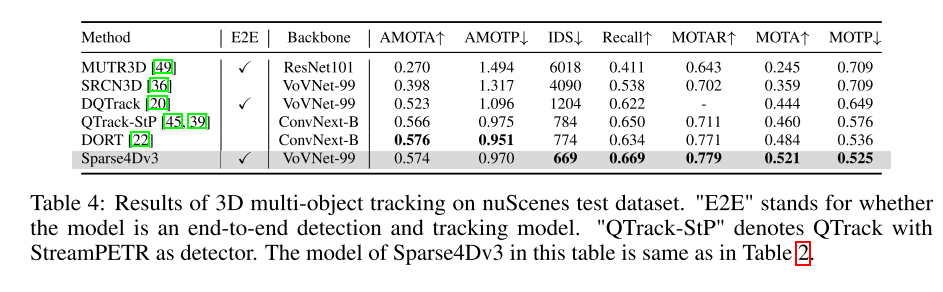
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Bard a été formé sur les données ChatGPT ? Les meilleurs scientifiques de Google ont protesté en vain et ont quitté OpenAI
- Le meilleur expert en IA de Google rejoint OpenAI et avertit Google de ne pas utiliser les données ChatGPT pour former Bard
- Explorer la future technologie de conduite autonome : radar à ondes millimétriques 4D
- Google propose un NAS sans données, qui ne nécessite qu'un seul modèle pré-entraîné pour la recherche sur le Web
- Comment utiliser PyTorch pour la formation aux réseaux neuronaux