
Maison >Périphériques technologiques >IA >Augmentation des données de code dans le Deep Learning : une revue de 89 recherches en 5 ans
Augmentation des données de code dans le Deep Learning : une revue de 89 recherches en 5 ans

- 王林avant
- 2023-11-23 14:33:441323parcourir
Avec le développement rapide de l'apprentissage profond et des modèles à grande échelle, la recherche de technologies innovantes continue de croître. Dans ce processus, la technologie d'augmentation des données a montré une valeur qui ne peut être ignorée
Récemment, une étude menée conjointement par l'Université Monash, l'Université de gestion de Singapour, le laboratoire Huawei Noah's Ark, l'Université Beihang et l'Université nationale australienne Basée sur 89 enquêtes de recherche connexes au cours des cinq dernières années, une étude complète sur l’application de l’amélioration des données de code dans l’apprentissage profond a été publiée.

- Adresse papier : https://arxiv.org/abs/2305.19915
- Adresse du projet : https://github.com/terryyz/DataAug4Code
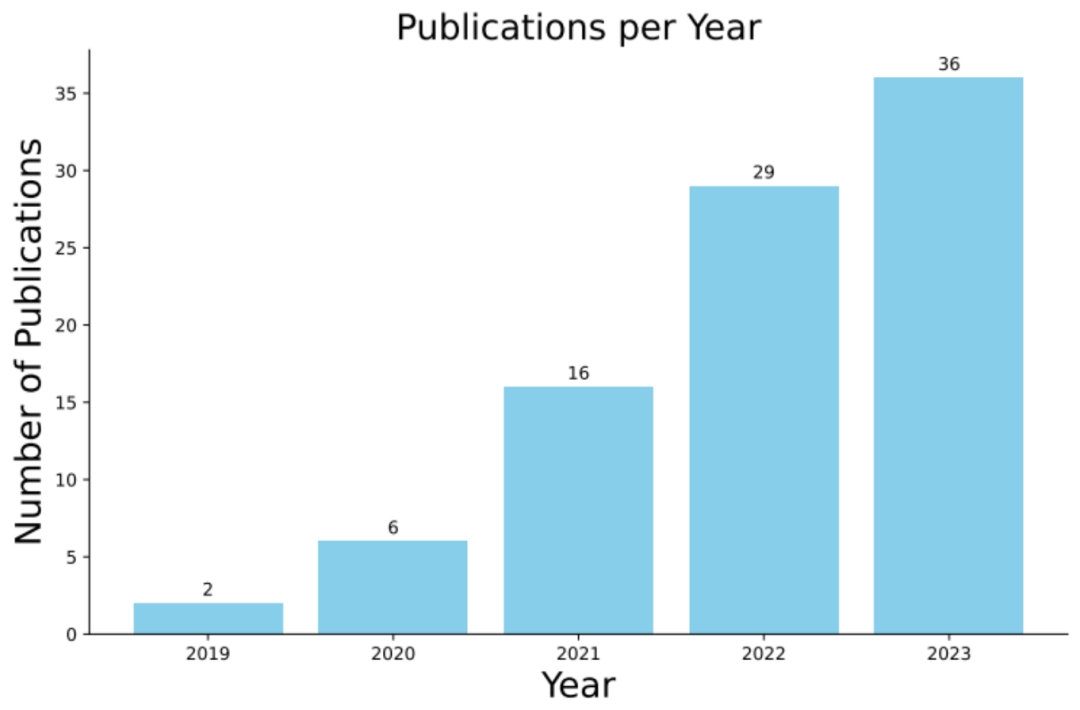
Ce rapport d'examen est publié conjointement par plusieurs institutions universitaires et industrielles de premier plan. Il révèle non seulement en profondeur les techniques d'amélioration des données de code, mais fournit également des conseils pour les recherches et applications futures. Nous pensons que cette revue incitera davantage de chercheurs à s'intéresser à l'application de l'augmentation des données de code dans l'apprentissage profond et favorisera une exploration et un développement plus approfondis dans ce domaine. Développement
: Le modèle de code est entraîné sur la base d'un vaste corpus de code source et peut simuler avec précision le contexte d'extraits de code. Depuis l'adoption précoce d'architectures d'apprentissage profond telles que LSTM et Seq2Seq jusqu'à l'incorporation ultérieure de modèles de langage pré-entraînés, ces modèles ont montré d'excellentes performances dans les tâches en aval sur plusieurs sources. Par exemple, certains modèles prennent en compte le flux de données du programme pendant la phase de pré-formation, qui constitue la structure du niveau sémantique du code et est utilisé pour capturer la relation entre les variables.
L'importance de la technologie d'augmentation des données
: La technologie d'augmentation des données augmente la diversité des échantillons d'entraînement grâce à la synthèse des données, améliorant ainsi les performances du modèle sous divers aspects (tels que la précision et la robustesse). Dans le domaine de la vision par ordinateur, par exemple, les méthodes d’augmentation des données couramment utilisées incluent le recadrage, le retournement et l’ajustement des couleurs des images. Dans le traitement du langage naturel, l'augmentation des données repose largement sur des modèles de langage capables de réécrire le contexte en remplaçant des mots ou en réécrivant des phrases.
Spécialité de l'augmentation des données de code: Contrairement aux images et au texte brut, le code source est limité par les règles de syntaxe strictes du langage de programmation, de sorte que la flexibilité d'amélioration est moindre. La plupart des méthodes d'augmentation des données pour le code doivent respecter des règles de transformation spécifiques afin de conserver la fonctionnalité et la syntaxe de l'extrait de code d'origine. Une pratique courante consiste à utiliser un analyseur pour construire un arbre syntaxique concret du code source, puis à le convertir en un arbre syntaxique abstrait, simplifiant ainsi la représentation tout en conservant les informations clés telles que les identifiants et les instructions de flux de contrôle. Ces transformations constituent la base des méthodes d'augmentation des données basées sur des règles et permettent de simuler des représentations de code plus diversifiées dans le monde réel, améliorant ainsi la robustesse des modèles de code entraînés avec des données augmentées. Une exploration approfondie des méthodes d'augmentation des données de code
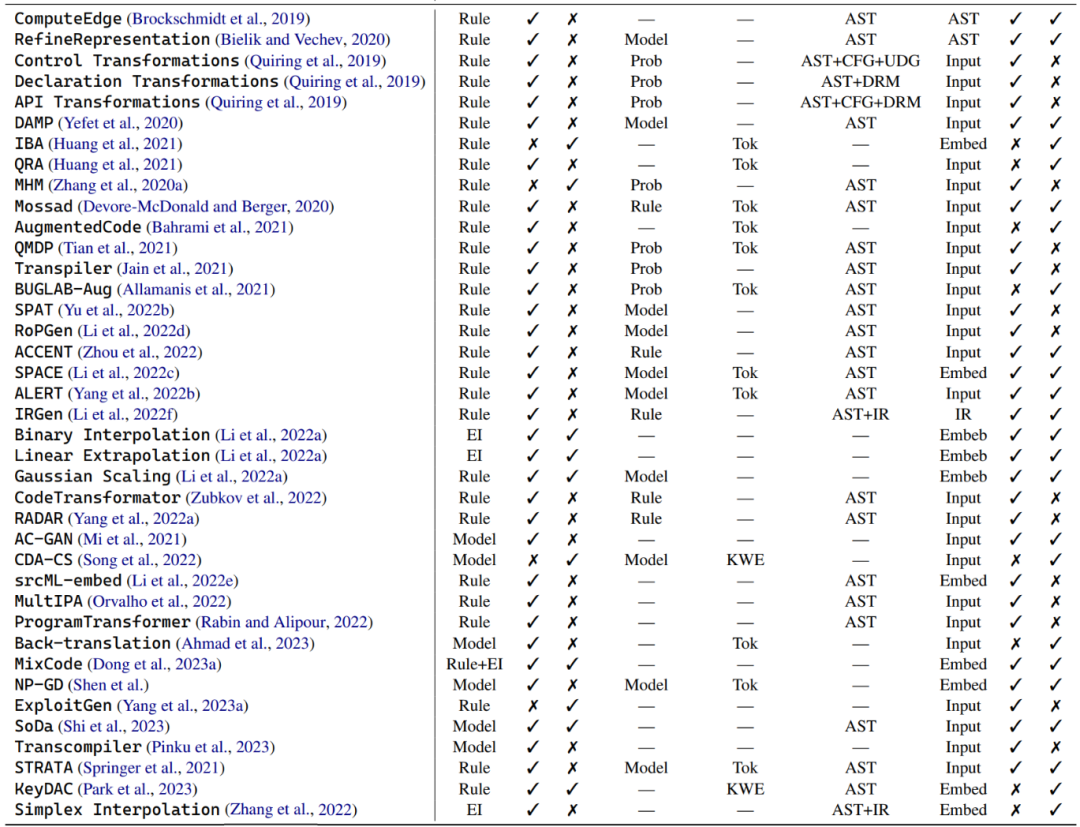
Dans une plongée approfondie dans le monde de l'augmentation des données de code, l'auteur divise ces techniques en trois catégories principales : les techniques basées sur des règles, les techniques basées sur des modèles, et des exemples de techniques d'interpolation. Ces différentes branches sont brièvement décrites ci-dessous.
Technologie basée sur des règles : De nombreuses méthodes d'augmentation des données utilisent des règles prédéterminées pour transformer les programmes tout en veillant à ne pas enfreindre les règles grammaticales et sémantiques. Ces transformations incluent des opérations telles que le remplacement des noms de variables, le renommage des noms de méthodes et l'insertion de code non valide. En plus de la syntaxe de base du programme, certaines transformations prennent en compte des informations structurelles plus profondes, telles que les graphiques de flux de contrôle et les chaînes de définition d'utilisation. Il existe un sous-ensemble de techniques d'amélioration des données basées sur des règles qui se concentrent sur l'amélioration du contexte du langage naturel dans les extraits de code, y compris les docstrings et les commentaires.
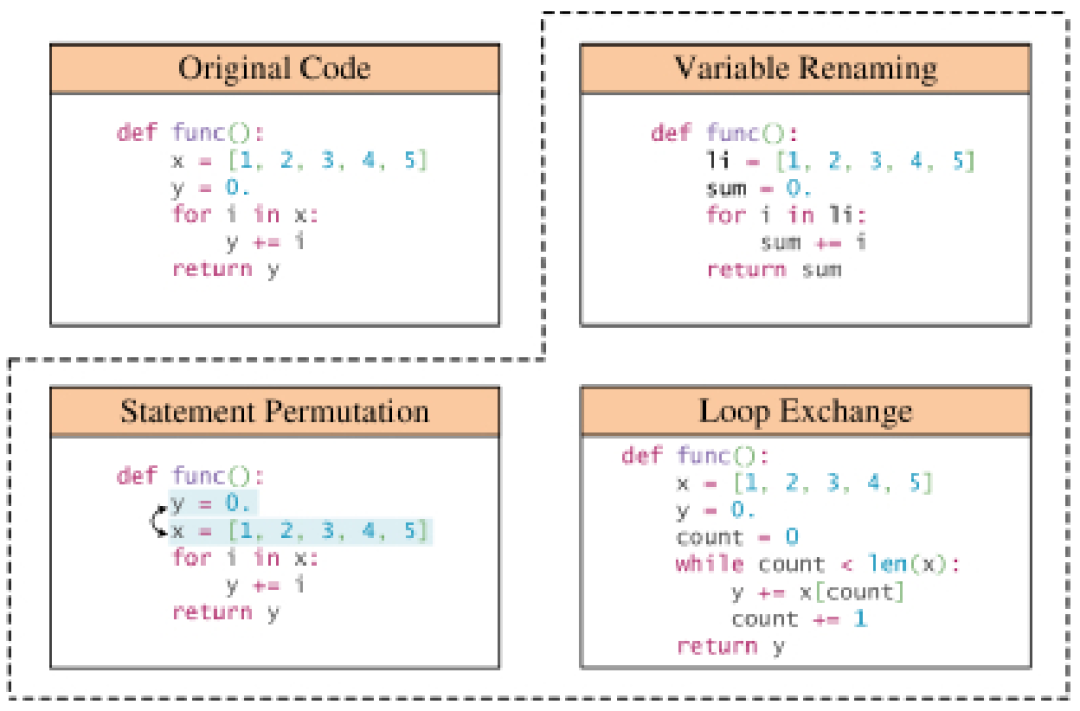
Techniques basées sur des modèles : Une série de techniques d'augmentation des données pour les modèles de code conçues pour entraîner divers modèles afin d'améliorer les données. Par exemple, certaines études utilisent les réseaux contradictoires génératifs de classification auxiliaire (ACGAN) pour générer des augmentations. D'autres études ont formé des réseaux antagonistes génératifs pour améliorer à la fois les capacités de génération et de recherche de code. Ces méthodes sont principalement conçues spécifiquement pour les modèles de code et visent à améliorer la représentation et la compréhension contextuelle du code de différentes manières.
Exemples de techniques d'interpolation : Ce type de technique d'augmentation des données provient du Mixup, qui fonctionne en interpolant l'entrée et les étiquettes de deux échantillons réels ou plus. Par exemple, étant donné une tâche de classification binaire en vision par ordinateur et deux images d'un chien et d'un chat, ces méthodes d'augmentation des données peuvent mélanger les entrées des deux images et leurs étiquettes correspondantes selon des poids sélectionnés au hasard. Cependant, dans le monde du code, l’application de ces méthodes est limitée par la syntaxe et les fonctionnalités uniques du programme. Par rapport à l'interpolation au niveau de la surface, la plupart des méthodes d'augmentation des données d'interpolation fusionnent plusieurs exemples réels en une seule entrée via l'intégration de modèles. Par exemple, des recherches sont en cours sur la combinaison de techniques basées sur des règles avec Mixup pour mélanger des extraits de code originaux et leurs représentations transformées.

Stratégie et technologie
Dans les applications pratiques, la conception et l'efficacité des techniques d'augmentation des données pour les modèles de code sont affectées par de nombreux facteurs, tels que le coût de calcul, la diversité des échantillons et le modèle robustesse. Cette section met en évidence ces facteurs, fournissant des informations et des conseils pour concevoir et optimiser des méthodes d'augmentation de données appropriées.
Méthodes d'empilement : Dans la discussion précédente, de nombreuses stratégies d'augmentation des données ont été proposées simultanément dans un seul ouvrage dans le but d'améliorer les performances du modèle. Généralement, cette combinaison comprend deux types : le même type d’augmentation des données ou un mélange de différentes méthodes d’augmentation des données. La première est généralement appliquée aux techniques d’augmentation des données basées sur des règles, où le point de départ est qu’une seule transformation de code ne peut pas représenter pleinement les divers styles de codage et implémentations dans le monde réel. Plusieurs travaux ont démontré que la fusion de plusieurs types de techniques d’augmentation des données peut améliorer les performances des modèles de code. Par exemple, un schéma de transcodage basé sur des règles et une augmentation des données basée sur un modèle sont combinés pour créer un corpus amélioré pour la formation de modèles. Tandis que d'autres recherches s'améliorent sur les langages de programmation, y compris deux techniques d'amélioration des données : l'extraction sans mot-clé basée sur des règles et le remplacement sans mot-clé basé sur un modèle.
Optimisation : Dans certains scénarios, tels que l'amélioration de la robustesse et la minimisation du coût de calcul, il est crucial de sélectionner des exemples d'amélioration spécifiques. Les auteurs appellent cette sélection de candidats axée sur un objectif l’optimisation de l’augmentation des données. L'article présente principalement trois stratégies : la sélection probabiliste, la sélection basée sur un modèle et la sélection basée sur des règles. La sélection probabiliste est optimisée en échantillonnant à partir d'une distribution de probabilité, tandis que la sélection basée sur un modèle est guidée par le modèle pour sélectionner les exemples les plus appropriés. Dans la sélection basée sur des règles, des règles ou heuristiques prédéterminées spécifiques sont utilisées pour sélectionner les exemples les plus appropriés.
Sélection probabiliste : L'auteur a spécifiquement sélectionné trois stratégies de sélection probabilistes représentatives, dont MHM, QMDP et BUGLAB-Aug. MHM utilise la méthode d'échantillonnage probabiliste Metropolis-Hastings, une technique de Monte Carlo en chaîne de Markov pour sélectionner des exemples contradictoires avec remplacement d'identifiant. QMDP utilise des méthodes Q-learning pour sélectionner et exécuter stratégiquement des transformations structurelles basées sur des règles.
Sélection basée sur un modèle : Certaines techniques d'augmentation des données qui adoptent cette stratégie utilisent les informations de gradient du modèle pour guider la sélection d'exemples d'amélioration. Une méthode typique est la méthode MP d'augmentation des données, qui optimise en fonction de la perte de modèle, sélectionne et génère des exemples contradictoires via le renommage des variables. SPACE sélectionne et perturbe les intégrations d'identifiants de code via une ascension de gradient, dans le but de maximiser l'impact sur les performances du modèle tout en conservant l'exactitude sémantique et syntaxique du langage de programmation.
Sélection basée sur des règles : La sélection basée sur des règles est une méthode puissante qui utilise des fonctions ou des règles de fitness prédéterminées. Cette approche s'appuie souvent sur des indicateurs de décision. Par exemple, IRGen utilise une technique d’optimisation basée sur un algorithme génétique et une fonction de fitness basée sur la similarité IR. Tandis que l'augmentation des données ACCENT et RA R utilise des mesures d'évaluation telles que BLEU et CodeBLEU respectivement pour guider le processus de sélection et de remplacement afin d'obtenir un impact contradictoire maximal.
Scénarios d'application
Les méthodes d'augmentation des données peuvent être directement appliquées dans plusieurs scénarios de code courants
Exemples contradictoires pour la robustesse : La robustesse est une clé et une dimension de la complexité. La conception de techniques efficaces d’augmentation des données pour générer des exemples contradictoires afin d’identifier et d’atténuer les vulnérabilités des modèles de code est devenue un point chaud de la recherche ces dernières années. Plusieurs études ont encore renforcé la robustesse du modèle de code en testant et en améliorant la robustesse du modèle à l'aide de diverses méthodes d'augmentation des données.
Champ à faibles ressources : Dans le domaine du génie logiciel, les ressources en langage de programmation sont sérieusement déséquilibrées. Les langages de programmation populaires comme Python et Java jouent un rôle majeur dans les référentiels open source, tandis que de nombreux langages comme Rust sont très pauvres en ressources. Les modèles de code sont souvent formés sur la base de référentiels et de forums open source, et des déséquilibres dans les ressources du langage de programmation peuvent nuire à leurs performances sur des langages de programmation manquant de ressources. L’application de méthodes d’augmentation des données dans des domaines à faibles ressources est un thème récurrent.
Amélioration de la récupération : Dans les domaines du traitement et du codage du langage naturel, les applications d'amélioration des données liées à l'amélioration de la récupération attirent de plus en plus d'attention. Ces cadres d'amélioration de récupération pour les modèles de code intègrent des exemples d'amélioration de récupération à partir de l'ensemble d'entraînement lors de la pré-entraînement ou du réglage fin du modèle de code. Ce procédé d'amélioration améliore l'efficacité des paramètres du modèle.
Contrastive Learning : L'apprentissage contrastif est un autre domaine d'application où les méthodes d'augmentation des données sont déployées dans des scénarios de code. Cela permet au modèle d'apprendre un espace d'intégration dans lequel les échantillons similaires sont proches les uns des autres et les échantillons dissemblables sont plus éloignés les uns des autres. Les méthodes d'augmentation des données sont utilisées pour construire des échantillons similaires aux échantillons positifs afin d'améliorer les performances du modèle dans des tâches telles que la détection de défauts, la détection de clones et la recherche de code.
Les articles suivants traitent de plusieurs tâches de codage courantes et de l'application des efforts d'augmentation des données sur les ensembles de données d'évaluation, notamment la détection de clones, la détection et la réparation de défauts, la synthèse de code, la recherche de code, la génération de code et la traduction de code
Défis et opportunités
En termes d'amélioration des données de code, l'auteur estime qu'il existe de nombreux défis majeurs. Cependant, ce sont ces défis qui apportent de nouvelles possibilités et des opportunités passionnantes dans le domaine
Discussion théorique : Actuellement, il existe une lacune évidente dans l'exploration approfondie et la compréhension théorique des méthodes d'augmentation des données dans le code . La plupart des recherches existantes se concentrent sur les domaines du traitement d’images et du langage naturel, considérant l’augmentation des données comme une méthode d’application des connaissances préexistantes sur l’invariance des données ou des tâches. Lorsqu’ils se tournent vers le code, alors que les travaux antérieurs introduisaient de nouvelles méthodes ou démontraient comment les techniques d’augmentation des données peuvent être efficaces, ils ont souvent négligé le pourquoi et le comment, notamment d’un point de vue mathématique. La nature discrète du code rend les discussions théoriques encore plus importantes. Les discussions théoriques permettent à chacun d’appréhender l’augmentation des données dans une perspective plus large qu’en termes de simples résultats expérimentaux.
Plus de recherches sur les modèles pré-entraînés : Ces dernières années, les modèles de code pré-entraînés ont été largement utilisés dans le domaine du codage, et de riches connaissances ont été accumulées grâce à l'autosupervision de corpus à grande échelle. Bien que de nombreuses études aient utilisé des modèles de code pré-entraînés pour augmenter les données, la plupart des tentatives se limitent encore au remplacement de jetons de masque ou à la génération directe après un réglage fin. L’exploitation du potentiel d’augmentation des données des modèles linguistiques à grande échelle constitue une opportunité de recherche émergente dans le monde du codage.
Différent de la manière précédente d'utiliser des modèles pré-entraînés pour l'amélioration des données, ces travaux ont ouvert l'ère de « l'amélioration des données basée sur des indices ». Cependant, l’exploration de l’augmentation des données basée sur des indices reste un domaine de recherche relativement intact dans le monde des codes. Contenu réécrit : Différent de la manière précédente d'utiliser des modèles pré-entraînés pour l'amélioration des données, ces travaux inaugurent l'ère de « l'amélioration des données basée sur des indices ». Cependant, il existe encore relativement peu d'études sur l'augmentation des données basée sur des indices dans le domaine du code
Traitement des données spécifiques au domaine : Les auteurs se concentrent sur l'étude des techniques d'augmentation des données pour les tâches courantes en aval du traitement du code. Cependant, les auteurs se rendent compte qu’il existe encore peu de recherches sur d’autres données spécifiques à des tâches dans le domaine du codage. Par exemple, la recommandation API et la génération de séquences API peuvent être considérées comme faisant partie des tâches de codage. Les auteurs ont observé un écart dans les techniques d’augmentation des données entre ces deux niveaux différents, offrant ainsi des opportunités pour de futurs travaux à explorer.
Exploration accrue du code au niveau du projet et des langages de programmation à faibles ressources : les méthodes existantes ont fait des progrès suffisants sur les extraits de code au niveau des fonctions et les langages de programmation courants. Dans le même temps, les méthodes d’amélioration des langues à faibles ressources, bien que plus demandées, sont relativement rares. L’exploration dans ces deux directions est encore limitée et les auteurs estiment qu’elles pourraient constituer des directions prometteuses.
Atténuer les préjugés sociaux : À mesure que les modèles de code progressent dans le développement de logiciels, ils peuvent être utilisés pour développer des applications centrées sur l'humain, telles que les ressources humaines et l'éducation, où des procédures biaisées peuvent susciter des préoccupations en matière de représentation. Les groupes sous-représentés rendent injuste et des décisions contraires à l’éthique. Bien que les préjugés sociaux en PNL aient été bien étudiés et puissent être atténués grâce à l’augmentation des données, les préjugés sociaux dans le code n’ont pas encore retenu l’attention.
Apprentissage sur petit échantillon : Dans un scénario sur petit échantillon, le modèle doit atteindre des performances comparables aux modèles d'apprentissage automatique traditionnels, mais les données d'entraînement sont extrêmement limitées. Les méthodes d'augmentation des données fournissent une solution simple à ce problème. Cependant, il existe peu de travaux sur l’utilisation de méthodes d’augmentation des données dans des scénarios sur de petits échantillons. Dans quelques exemples de scénarios, l’auteur estime qu’il s’agit d’une question intéressante : comment fournir au modèle des capacités de généralisation et de résolution de problèmes rapides en générant des données augmentées de haute qualité.
Applications multimodales : Il est important de noter que se concentrer uniquement sur des extraits de code au niveau des fonctions ne représente pas avec précision la complexité et les nuances des situations de programmation du monde réel. Dans ce cas, les développeurs travaillent généralement sur plusieurs fichiers et dossiers en même temps. Bien que ces applications multimodales deviennent de plus en plus populaires, aucune recherche ne leur a appliqué de méthodes d’augmentation des données. L'un des défis consiste à relier efficacement les représentations d'intégration de chaque modalité dans les modèles de code, ce qui a été étudié dans des tâches multimodales visuo-verbales.
Manque d'uniformité : La littérature actuelle sur l'augmentation des données de code présente un paysage difficile dans lequel les approches les plus populaires sont souvent qualifiées d'auxiliaires. Certaines études empiriques ont tenté de comparer les méthodes d'augmentation des données pour les modèles de code. Cependant, ces travaux n’exploitent pas la plupart des méthodes avancées d’augmentation des données existantes. Bien qu'il existe des cadres d'augmentation de données bien établis pour la vision par ordinateur (comme la bibliothèque d'augmentation par défaut dans PyTorch) et le NLP (comme NL-Augmenter), les bibliothèques correspondantes pour les techniques d'augmentation de données à usage général pour les modèles de code manquent manifestement. De plus, étant donné que les méthodes existantes d’augmentation des données sont souvent évaluées à l’aide de divers ensembles de données, il est difficile de déterminer leur efficacité. Par conséquent, les auteurs estiment que les progrès de la recherche sur l’augmentation des données seront grandement favorisés par l’établissement de tâches de référence standardisées et unifiées, ainsi que d’ensembles de données permettant de comparer et d’évaluer l’efficacité des différentes méthodes d’augmentation. Cela ouvrira la voie à une compréhension plus systématique et comparative des forces et des limites de ces méthodes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!