
Maison >Périphériques technologiques >IA >Comment utiliser LangChain et l'API OpenAI pour l'analyse de documents
Comment utiliser LangChain et l'API OpenAI pour l'analyse de documents

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-23 11:14:461468parcourir
Le contenu qui doit être réécrit par le traducteur est :|Le contenu qui doit être réécrit est :Bugatti
Le contenu qui doit être réécrit par le réviseur est :|Le contenu qui doit à réécrire est : Chonglou
De Extraire des informationsà partir de documents et de données est essentiel pour vouspour prendre des décisions éclairées. Cependant, lorsqu'il s'agit d'informations sensibles, des problèmes de confidentialité peuvent survenir. L'utilisation combinée de LangChain et OpenAI doit être réécrite : API, vous pouvez analyser des documents locaux sans les télécharger sur Internet.
Ils font cela en conservant les données localement, en utilisant l'intégration et la vectorisation pour l'analyse et en exécutant des processus dans votre environnement. OpenAI n'utilise pas les données soumises par les clients via son API pour former des modèles ou améliorer le service.
Construireenvironnement
Créer un nouveauPythonenvironnement virtuel, Cela garantira qu'il n'y a pas de conflits de versions de bibliothèque. Exécutez ensuite les commandes de terminal suivantes pour installer les bibliothèques requises. pip需要改写的内容是:install需要改写的内容是:langchain需要改写的内容是:openai需要改写的内容是:tiktoken需要改写的内容是:faiss-cpu需要改写的内容是:pypdf
utiliser chaque bibliothèque :
- LangChain : Vous l'utiliserez pour créer et gérer les applications de traitement de texte et linguistique chaînes d’analyse. Il fournira des modules pour le chargement de documents, la segmentation de texte, l'intégration et le stockage de volumes. OpenAI
- : Vous l'utiliserez pour exécuter des requêtes , et obtenir des résultats à partir de modèles de langage. tiktoken
- : Vous l'utiliserez pour compter le nombre de token ( unité de texte ) dans un texte donné. Ce qui doit être réécrit afin de suivre le nombre de token lors de l'interaction avec OpenAI qui facture en fonction du le nombre de tokens que vous utilisez est : API . FAISS : Vous l'utiliserez pour créer et gérer des magasins de vecteurs, permettant une récupération rapide de vecteurs similaires basés sur des intégrations.
- PyPDF : Cette bibliothèque extrait le texte de
- PDF. Il aide à charger des fichiers PDF et à extraire leur texte , pour un traitement ultérieur. Après avoir installé toutes les bibliothèques, votre environnement est maintenant prêt
. Obtenir OpenAI Ce qui doit être réécrit est : API clé
Lorsque vous faites une demande à OpenAI Ce qui doit être réécrit est : API , vous devez ajoutez
APIKey dans le cadre de la demande. Cette clé permet au fournisseur API de vérifier que la demande provient d'une source légitime et que vous disposez les autorisations nécessaires pour accéder à ses fonctionnalités. Ce qui doit être réécrit pour obtenir OpenAI est : la clé API, entrez dans la Plateforme OpenAI.
en haut à droite, 
ViewAPIKey", apparaîtra APISecret page clé. Cliquez sur le bouton "Créer une nouvelle clé" .
Nommez la clé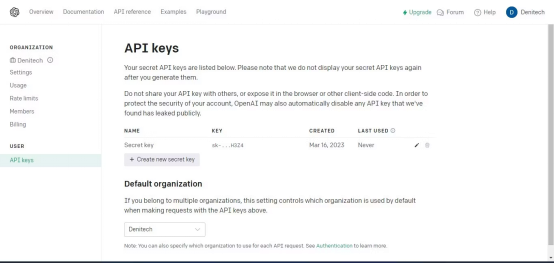
et cliquez sur "Créer une nouvelle clé". OpenAI générera une APIclé, que vous devrez copier et conserver dans un endroit sûr. Pour des raisons de sécurité, vous ne pourrez plus le consulter via votre compte OpenAI. Si vous perdez la clé, vous devez générer une nouvelle clé. 为了能够使用安装在虚拟环境中的库,您需要导入它们。 注意,您从LangChain导入了依赖项库,这让您可以使用LangChain框架的特定功能。 先创建一个含有API密钥的变量。稍后,您将在代码中使用该变量用于身份验证。 如果您打算与第三方共享您的代码,不建议对API密钥进行硬编码。对于打算分发的生产级代码,则改而使用环境变量。 接下来,创建一个加载文档的函数。该函数应该加载PDF或文本文件。如果文档既不是PDF文件,也不是文本文件,该函数会抛出值错误。 加载文档后,创建一个CharacterTextSplitter。该分割器将基于字符将已加载的文档分隔成更小的块。 需要改写的内容是: 分割文档可确保块的大小易于管理,仍与一些重叠的上下文相连接。这对于文本分析和信息检索之类的任务非常有用。 您需要一种方法来查询上传的文档,以便从中获得洞察力。为此,创建一个以查询字符串和检索器作为输入的函数。然后,它使用检索器和OpenAI语言模型的实例创建一个RetrievalQA实例。 该函数使用创建的QA实例来运行查询并输出结果。 主函数将控制整个程序流。它将接受用户输入的文档文件名并加载该文档。然后为文本嵌入创建OpenAIEmbeddings实例,并基于已加载的文档和文本嵌入构造一个向量存储。将该向量存储保存到本地文件。 接下来,从本地文件加载持久的向量存储。然后输入一个循环,用户可以在其中输入查询。主函数将这些查询与持久化向量存储的检索器一起传递给query_pdf函数。循环将继续,直到用户输入“exit”。 嵌入捕获词之间的语义关系。向量是一种可以表示一段文本的形式。 这段代码使用OpenAIEmbeddings生成的嵌入将文档中的文本数据转换成向量。然后使用FAISS对这些向量进行索引,以便高效地检索和比较相似的向量。这便于对上传的文档进行分析。 最后,如果用户独立运行程序,使用__name__需要改写的内容是:==需要改写的内容是:"__main__"构造函数来调用主函数: 这个应用程序是一个命令行应用程序。作为一个扩展,您可以使用Streamlit为该应用程序添加Web界面。 要执行文档分析,将所要分析的文档存储在项目所在的同一个文件夹中,然后运行该程序。它将询问所要分析的文档的名称。输入全名,然后输入查询,以便程序分析。 以下截图展示了对PDF进行分析的结果 Le résultat ci-dessous montre les résultats de l'analyse d'un fichier texte contenant avec le code source. Assurez-vous que le fichier que vous souhaitez analyser est au format PDF ou texte. Si vos documents sont dans d'autres formats , vous pouvez utiliser des outils en ligne pour les convertir au format PDF . Le code source complet est disponible dans le référentiel de code GitHub : https://github.com/makeuseofcode/Document-analysis-using-LangChain-and-OpenAI Titre original : Comment doit-il être être réécrit Le contenu à réécrire est : à Le contenu à réécrire est : Analyser Le contenu à réécrire est : Documents Le contenu à réécrire est : Avec Le contenu à réécrire est : LangChain Le contenu qui doit être réécrit est : et Le contenu qui doit être réécrit est : le contenu qui doit être réécrit est : le Le contenu est : OpenAI Le contenu qui doit être réécrit est : API , auteur : Denis Le contenu à réécrire est : Kuria Le contenu à réécrire est :
导入所需的库
from需要改写的内容是:langchain.document_loaders需要改写的内容是:import需要改写的内容是:PyPDFLoader,需要改写的内容是:TextLoaderfrom需要改写的内容是:langchain.text_splitter需要改写的内容是:import需要改写的内容是:CharacterTextSplitterfrom需要改写的内容是:langchain.embeddings.openai需要改写的内容是:import需要改写的内容是:OpenAIEmbeddingsfrom需要改写的内容是:langchain.vectorstores需要改写的内容是:import需要改写的内容是:FAISSfrom需要改写的内容是:langchain.chains需要改写的内容是:import需要改写的内容是:RetrievalQAfrom需要改写的内容是:langchain.llms需要改写的内容是:import需要改写的内容是:OpenAI
加载用于分析的文档
#需要改写的内容是:Hardcoded需要改写的内容是:API需要改写的内容是:keyopenai_api_key需要改写的内容是:=需要改写的内容是:"Your需要改写的内容是:API需要改写的内容是:key"
def需要改写的内容是:load_document(filename):if需要改写的内容是:filename.endswith(".pdf"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:PyPDFLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:elif需要改写的内容是:filename.endswith(".txt"):需要改写的内容是:loader需要改写的内容是:=需要改写的内容是:TextLoader(filename)需要改写的内容是:documents需要改写的内容是:=需要改写的内容是:loader.load()需要改写的内容是:else:需要改写的内容是:raise需要改写的内容是:ValueError("Invalid需要改写的内容是:file需要改写的内容是:type")
text_splitter需要改写的内容是:=需要改写的内容是:CharacterTextSplitter(chunk_size=1000,需要改写的内容是:需要改写的内容是:chunk_overlap=30,需要改写的内容是:separator="\n")需要改写的内容是:return需要改写的内容是:text_splitter.split_documents(documents=documents)
查询文档
def需要改写的内容是:query_pdf(query,需要改写的内容是:retriever):qa需要改写的内容是:=需要改写的内容是:RetrievalQA.from_chain_type(llm=OpenAI(openai_api_key=openai_api_key),需要改写的内容是:chain_type="stuff",需要改写的内容是:retriever=retriever)result需要改写的内容是:=需要改写的内容是:qa.run(query)需要改写的内容是:print(result)
创建主函数
def需要改写的内容是:main():需要改写的内容是:filename需要改写的内容是:=需要改写的内容是:input("Enter需要改写的内容是:the需要改写的内容是:name需要改写的内容是:of需要改写的内容是:the需要改写的内容是:document需要改写的内容是:(.pdf需要改写的内容是:or需要改写的内容是:.txt):\n")docs需要改写的内容是:=需要改写的内容是:load_document(filename)embeddings需要改写的内容是:=需要改写的内容是:OpenAIEmbeddings(openai_api_key=openai_api_key)vectorstore需要改写的内容是:=需要改写的内容是:FAISS.from_documents(docs,需要改写的内容是:embeddings)需要改写的内容是:vectorstore.save_local("faiss_index_constitution")persisted_vectorstore需要改写的内容是:=需要改写的内容是:FAISS.load_local("faiss_index_constitution",需要改写的内容是:embeddings)query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")while需要改写的内容是:query需要改写的内容是:!=需要改写的内容是:"exit":query_pdf(query,需要改写的内容是:persisted_vectorstore.as_retriever())query需要改写的内容是:=需要改写的内容是:input("Type需要改写的内容是:in需要改写的内容是:your需要改写的内容是:query需要改写的内容是:(type需要改写的内容是:'exit'需要改写的内容是:to需要改写的内容是:quit):\n")
if需要改写的内容是:__name__需要改写的内容是:==需要改写的内容是:"__main__":需要改写的内容是:main()
执行文件分析
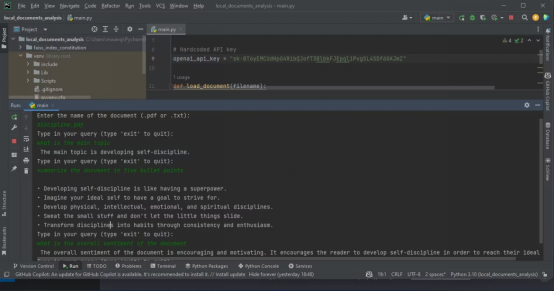
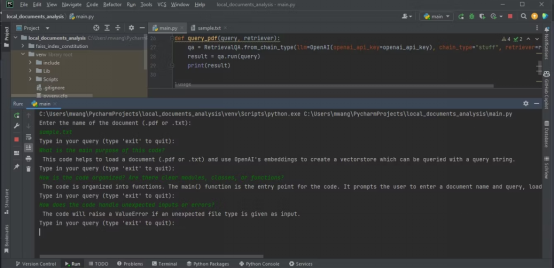
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Le meilleur expert en IA de Google rejoint OpenAI et avertit Google de ne pas utiliser les données ChatGPT pour former Bard
- 'Microsoft Teams Premium améliore la fonctionnalité GPT avec OpenAI'
- En se concentrant sur la concurrence des chatbots entre Google, Meta et OpenAI, ChatGPT place le mécontentement de LeCun au centre du sujet.
- Comment utiliser Python pour se connecter à l'API OpenAi afin d'implémenter un robot QQ intelligent
- OpenAI lance la première application mobile d'intelligence artificielle générative ChatGPT, ouvrant une nouvelle ère de communication intelligente