
Maison >Périphériques technologiques >IA >L'équipe PyTorch a réimplémenté le modèle « tout diviser » huit fois plus rapidement que l'implémentation d'origine.
L'équipe PyTorch a réimplémenté le modèle « tout diviser » huit fois plus rapidement que l'implémentation d'origine.

- 王林avant
- 2023-11-22 14:38:31801parcourir
Depuis le début de l’année jusqu’à aujourd’hui, l’IA générative s’est développée rapidement. Mais souvent, nous sommes confrontés à un problème difficile : comment accélérer la formation, le raisonnement, etc. de l’IA générative, notamment lors de l’utilisation de PyTorch.
Dans cet article, les chercheurs de l'équipe PyTorch nous apportent une solution. L'article se concentre sur la façon d'utiliser PyTorch natif pur pour accélérer les modèles d'IA génératifs. Il présente également de nouvelles fonctionnalités de PyTorch et des exemples pratiques sur la façon de les combiner.
Quel a été le résultat ? L'équipe PyTorch a déclaré avoir réécrit le modèle « Split Everything » (SAM) de Meta, ce qui a abouti à un code 8 fois plus rapide que l'implémentation d'origine sans perte de précision, le tout optimisé à l'aide de PyTorch natif.

Adresse du blog : https://pytorch.org/blog/accelerating-generative-ai/
Après avoir lu cet article, vous obtiendrez la compréhension suivante :
- Torch compile. : Compilateur de modèles PyTorch, PyTorch 2.0 ajoute une nouvelle fonction appelée torch.compile (), qui peut accélérer les modèles existants avec une seule ligne de code
- Quantification GPU : accélère le modèle en réduisant la précision du calcul ; (Scaled Dot Product Attention) : une implémentation d'attention économe en mémoire ; } ensemble pour regrouper des données de taille non uniforme dans un seul tenseur, telles que des images de différentes tailles ;
- Opérations personnalisées Triton : utilisez Triton Python DSL pour écrire des opérations GPU et intégrez-les facilement dans divers composants de PyTorch via un opérateur personnalisé inscription.
- Les fonctionnalités natives de PyTorch apportent un débit accru et une réduction de la surcharge de mémoire.
- Pour plus d'informations sur cette recherche, veuillez vous référer au SAM proposé par Meta. Des articles détaillés peuvent être trouvés dans "Le CV n'existe plus ? Meta publie le modèle d'IA "Split Everything", le CV pourrait inaugurer le moment GPT-3"
Ensuite, nous présenterons le processus d'optimisation de SAM, y compris les performances Analyse, identification des goulots d'étranglement et comment intégrer ces nouvelles fonctionnalités dans PyTorch pour résoudre les problèmes rencontrés par SAM. De plus, nous présenterons également quelques nouvelles fonctionnalités de PyTorch, notamment torch.compile, SDPA, les noyaux Triton, Nested Tensor et la parcimonie semi-structurée (sparsité semi-structurée)
Le contenu sera approfondi couche par couche A la fin de cet article, nous présenterons la version rapide SAM. Pour les lecteurs intéressés, vous pouvez le télécharger depuis GitHub. De plus, ces données ont été visualisées à l'aide de Perfetto UI pour démontrer la valeur d'application de diverses fonctionnalités de PyTorch
Ce projet peut être trouvé à l'adresse GitHub : https://github.com/pytorch-labs/segment-anything-fast Le code source de 
réécrit le modèle divisé tout SAM
L'étude souligne que le type de données de base SAM utilisé dans cet article est de type float32, la taille du lot est de 1 et PyTorch Profiler est utilisé pour afficher le résultats du suivi de base Comme suit :
Cet article a révélé que SAM a deux emplacements qui peuvent être optimisés :
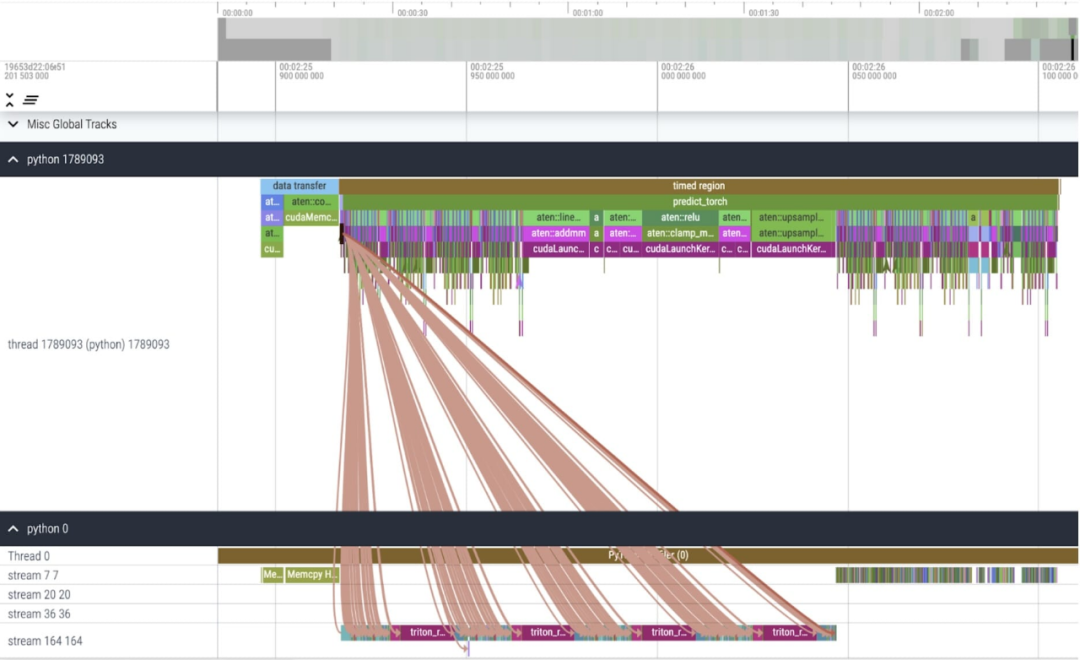
Le premier est le long appel à aten::index, qui est provoqué par le opération d'index tensoriel (telle que []) Causée par les appels sous-jacents générés. Cependant, le temps réel que le GPU passe sur aten::index est relativement faible. La raison en est que pendant le processus de démarrage de deux cœurs, aten::index bloque cudaStreamSynchronize entre les deux. Cela signifie que le CPU attend que le GPU termine le traitement jusqu'à ce que le deuxième cœur soit lancé. Par conséquent, afin d'optimiser SAM, cet article estime qu'il faut s'efforcer d'éliminer le blocage de la synchronisation GPU qui provoque des temps d'inactivité.
Le deuxième problème est que SAM passe beaucoup de temps GPU dans la multiplication matricielle (partie vert foncé comme indiqué sur l'image), ce qui est très courant dans le modèle Transformers. Si nous pouvons réduire le temps GPU du modèle SAM sur la multiplication matricielle, alors nous pouvons améliorer considérablement la vitesse de SAM
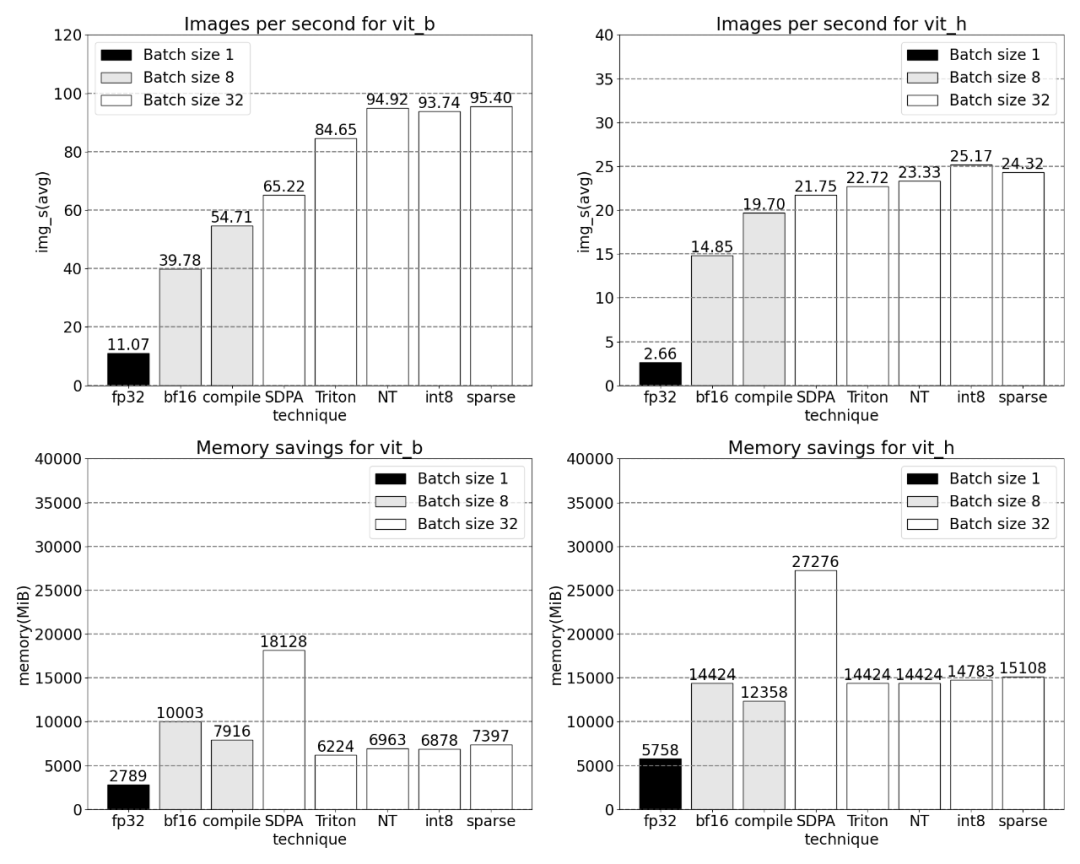
Ensuite, nous comparerons le débit (img/s) et la surcharge mémoire (GiB) de SAM Établir un ligne de base. Ensuite, il y a le processus d'optimisation
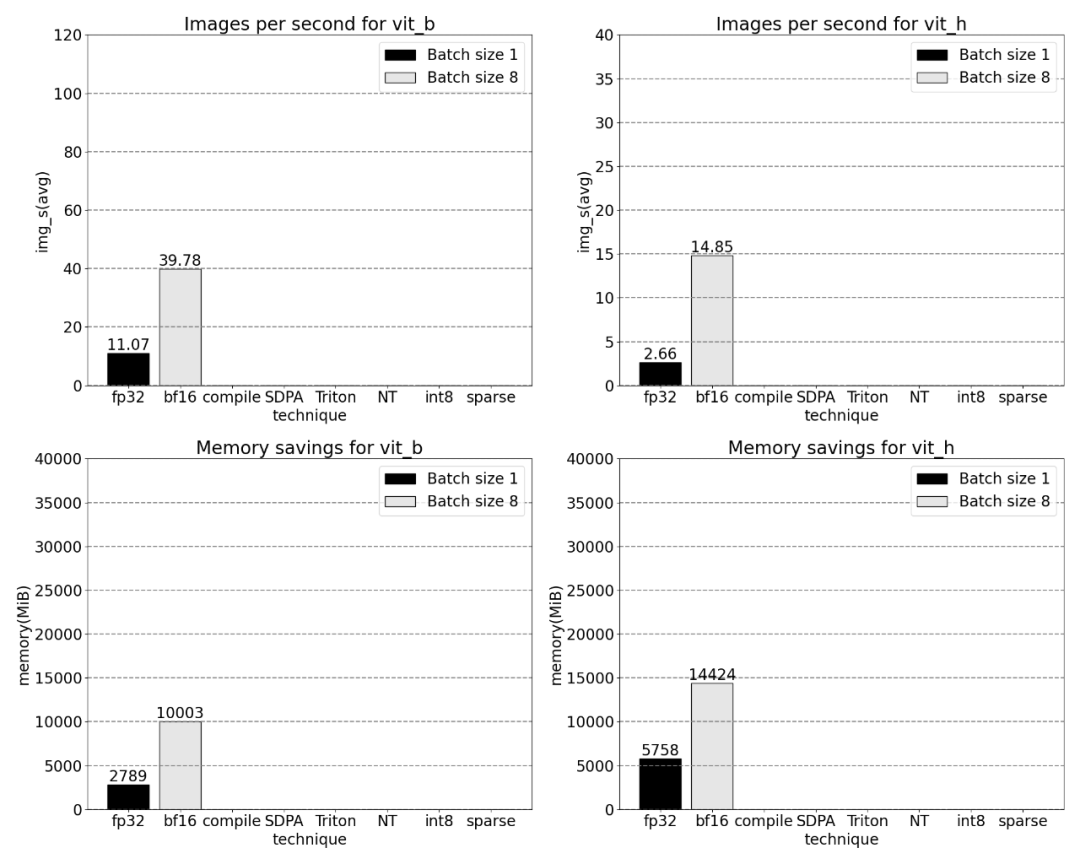
La phrase qui doit être réécrite est : Bfloat16 demi-précision (plus la synchronisation GPU et le traitement par lots)
Afin de résoudre le problème ci-dessus, cela c'est-à-dire réduire le nombre de multiplications matricielles nécessaires Temps, cet article se tourne vers bfloat16. bfloat16 est un type demi-précision couramment utilisé, qui peut économiser beaucoup de temps de calcul et de mémoire en réduisant la précision de chaque paramètre et activation

Remplacez le type de remplissage par bfloat16
In De plus, cet article a révélé qu'il existe deux endroits qui peuvent être optimisés pour supprimer la synchronisation GPU


Plus précisément, il est plus facile à comprendre sur la base de l'image ci-dessus, l'étude a révélé que dans l'encodeur d'image de SAM. Il existe deux variables q_coords et k_coords qui agissent comme des scalers de coordonnées, et ces variables sont allouées et traitées sur le CPU. Cependant, une fois ces variables utilisées pour indexer dans rel_pos_resized, l'opération d'indexation déplace automatiquement ces variables vers le GPU, provoquant des problèmes de synchronisation GPU. Pour résoudre ce problème, la recherche a souligné que cette partie peut être résolue en la réécrivant à l'aide de la fonction torch.where comme indiqué ci-dessus
Core Tracking
Après avoir appliqué ces modifications, nous avons remarqué qu'il y a un notable intervalle de temps entre les appels individuels du noyau, en particulier avec de petits lots (ici 1). Pour mieux comprendre ce phénomène, nous avons commencé l'analyse des performances de l'inférence SAM avec une taille de lot de 8
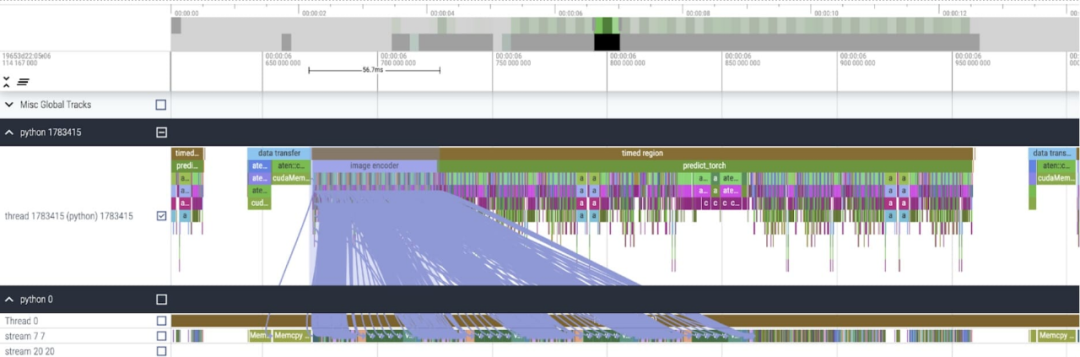
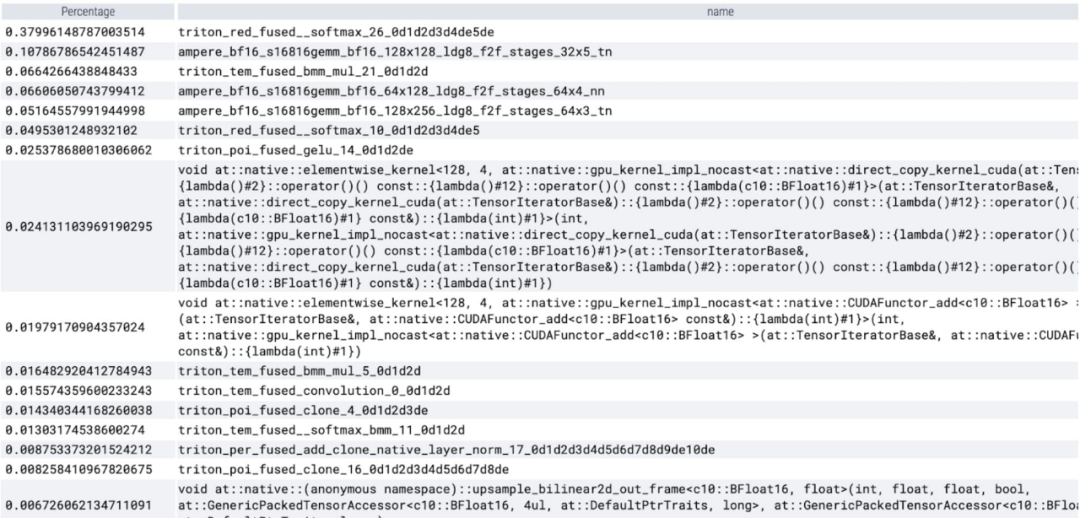
En analysant le temps passé par cœur, nous avons remarqué que la majorité des GPU pour SAM Time est dépensé en noyaux par éléments et en opérations softmax
Vous pouvez maintenant voir que la surcharge relative de la multiplication matricielle est beaucoup plus petite.
En combinant la synchronisation GPU et l'optimisation bfloat16, les performances SAM sont améliorées de 3 fois.
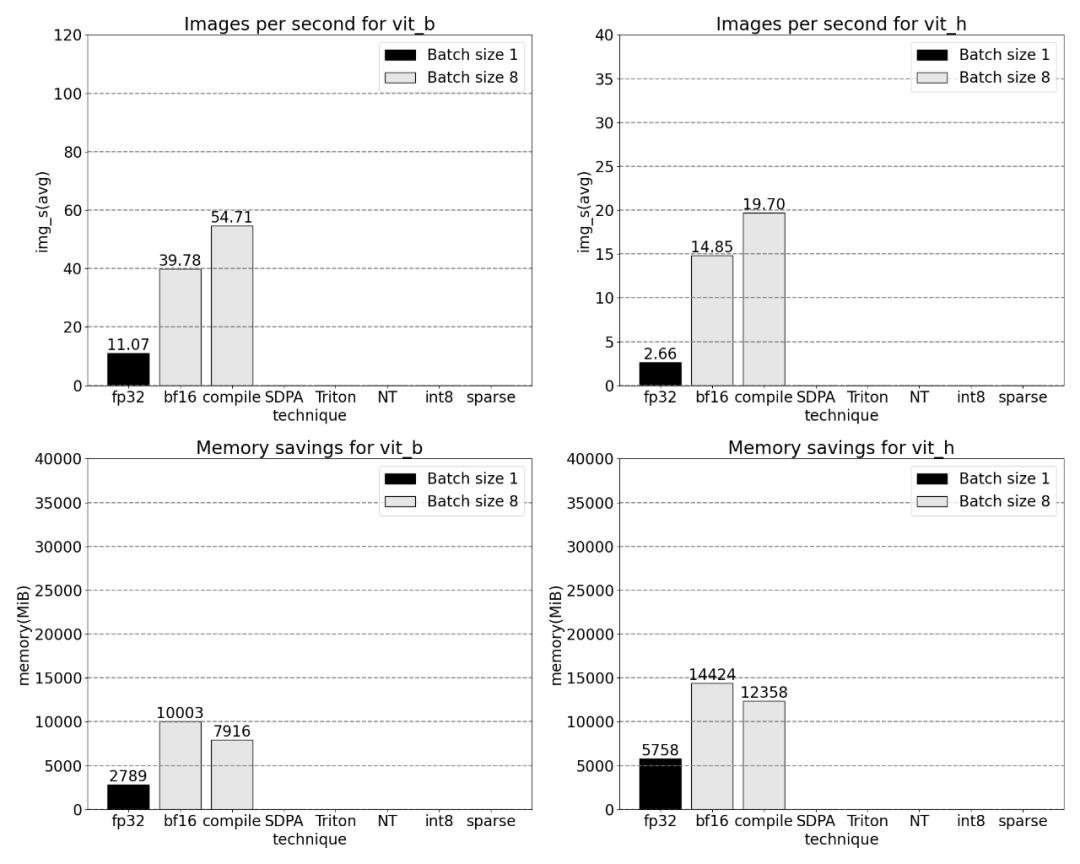
Torch.compile (+ ruptures de graphiques et graphiques CUDA)
J'ai découvert de nombreuses petites opérations lors de l'étude de SAM. Les chercheurs pensent que l'utilisation d'un compilateur pour consolider ces opérations est très bénéfique, c'est pourquoi PyTorch a apporté les optimisations suivantes à torch.compile
- Fusionner des séquences d'opérations telles que nn.LayerNorm ou nn.GELU dans un seul noyau GPU ;
- Fusionner les opérations immédiatement après le noyau de multiplication matricielle pour réduire le nombre d'appels au noyau GPU.
Grâce à ces optimisations, la recherche réduit le nombre d'allers-retours dans la mémoire globale du GPU, accélérant ainsi l'inférence. Nous pouvons maintenant essayer torch.compile sur l’encodeur d’image de SAM. Pour maximiser les performances, cet article utilise des techniques de compilation avancées :

Core tracking
Selon les résultats, torch.compile fonctionne très bien
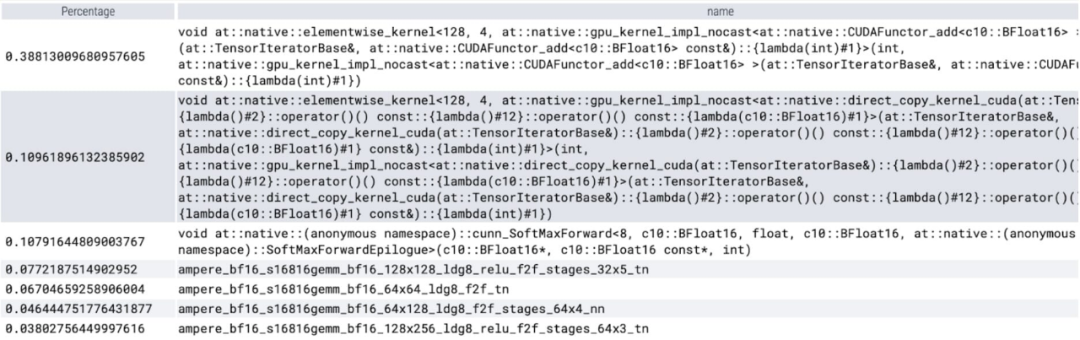
On peut observer que softmax occupe une grande partie de le temps , puis chaque variante GEMM. Les mesures suivantes concernent des lots de 8 et plus.
SDPA : scaled_dot_product_attention
Ensuite, cet article a mené des expériences sur SDPA (scaled_dot_product_attention), en se concentrant sur le mécanisme d'attention. En général, les mécanismes d’attention natifs évoluent quadratiquement avec la longueur de la séquence en temps et en mémoire. Les opérations SDPA de PyTorch reposent sur les principes d'attention économes en mémoire de Flash Attention, FlashAttentionV2 et xFormer, qui peuvent accélérer considérablement l'attention du GPU. Combinée avec torch.compile, cette opération permet d'exprimer et de fusionner un motif commun dans des variantes de MultiheadAttention. Après un petit changement, le modèle peut désormais utiliser scaled_dot_product_attention.
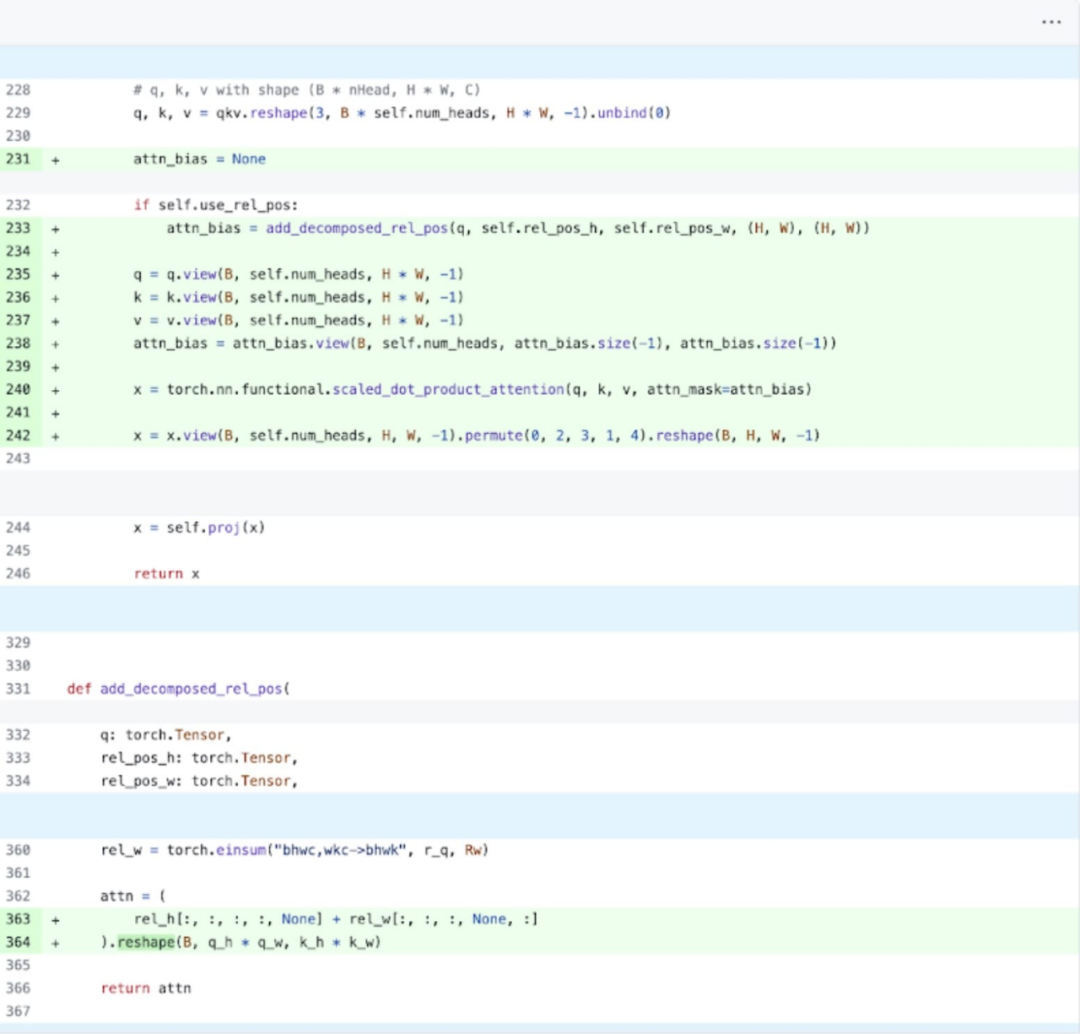
Core Tracking
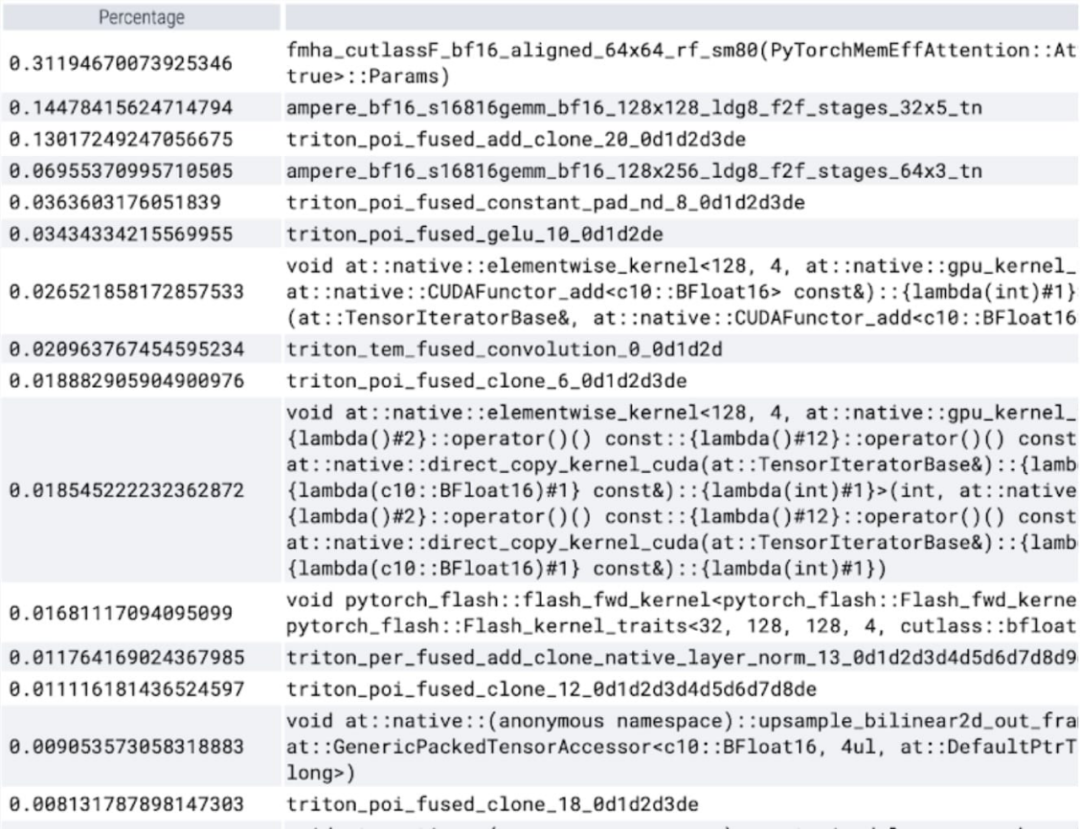
Vous pouvez maintenant voir le noyau d'attention efficace en mémoire prenant beaucoup de temps de calcul sur le GPU :
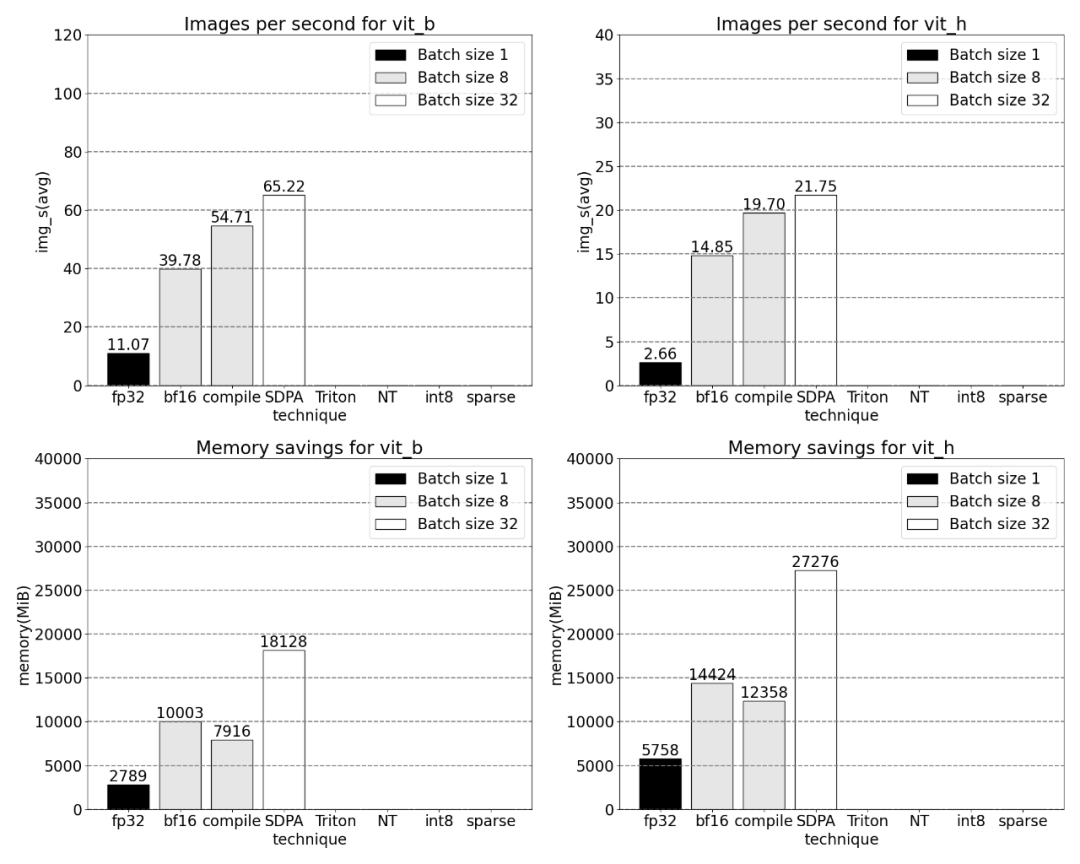
Utilisation du natif de PyTorch scaled_dot _product_attention, oui Augmente considérablement la taille du lot. Le graphique ci-dessous montre les changements pour les tailles de lots de 32 et plus.
Ensuite, l'étude a mené des expériences sur Triton, NestedTensor, batch Predict_torch, la quantification int8, la parcimonie semi-structurée (2:4) et d'autres opérations
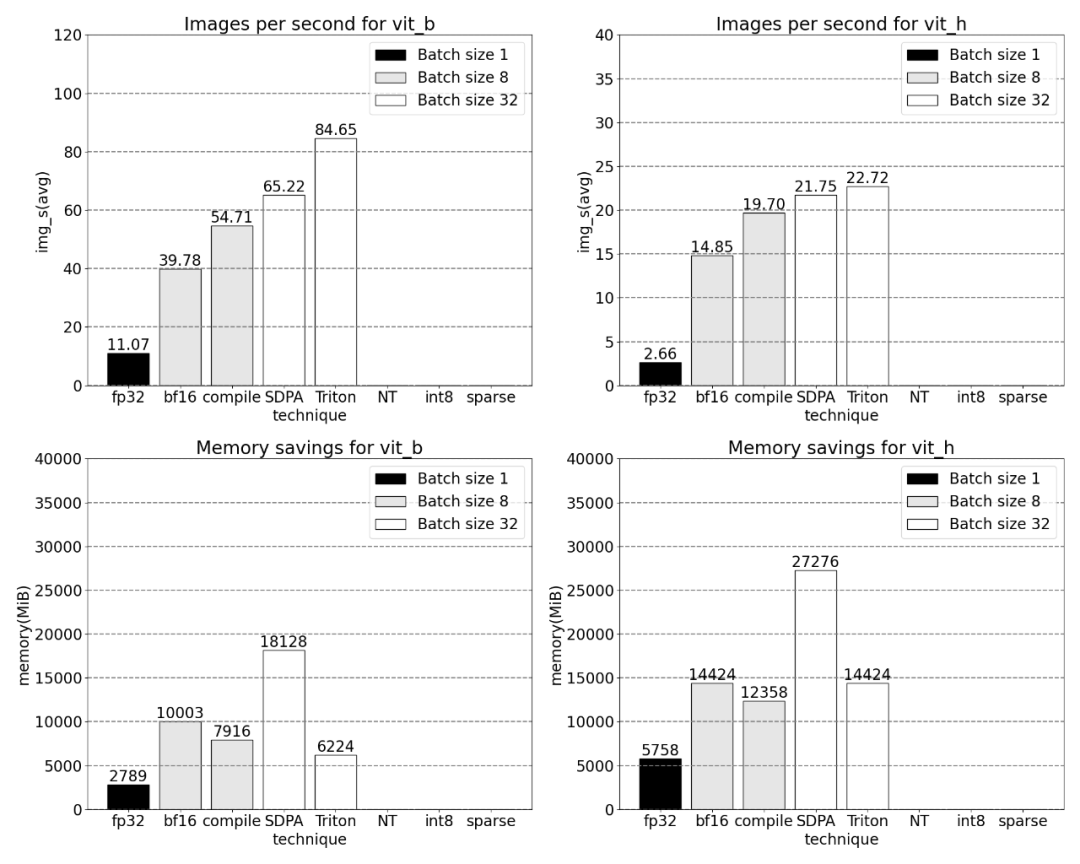
Par exemple, cet article utilise un positionnel personnalisé pour le noyau Triton, des mesures avec une taille de lot de 32 ont été observées.
Utilisation de la technologie Nested Tensor et ajustement de la taille du lot à 32 et plus
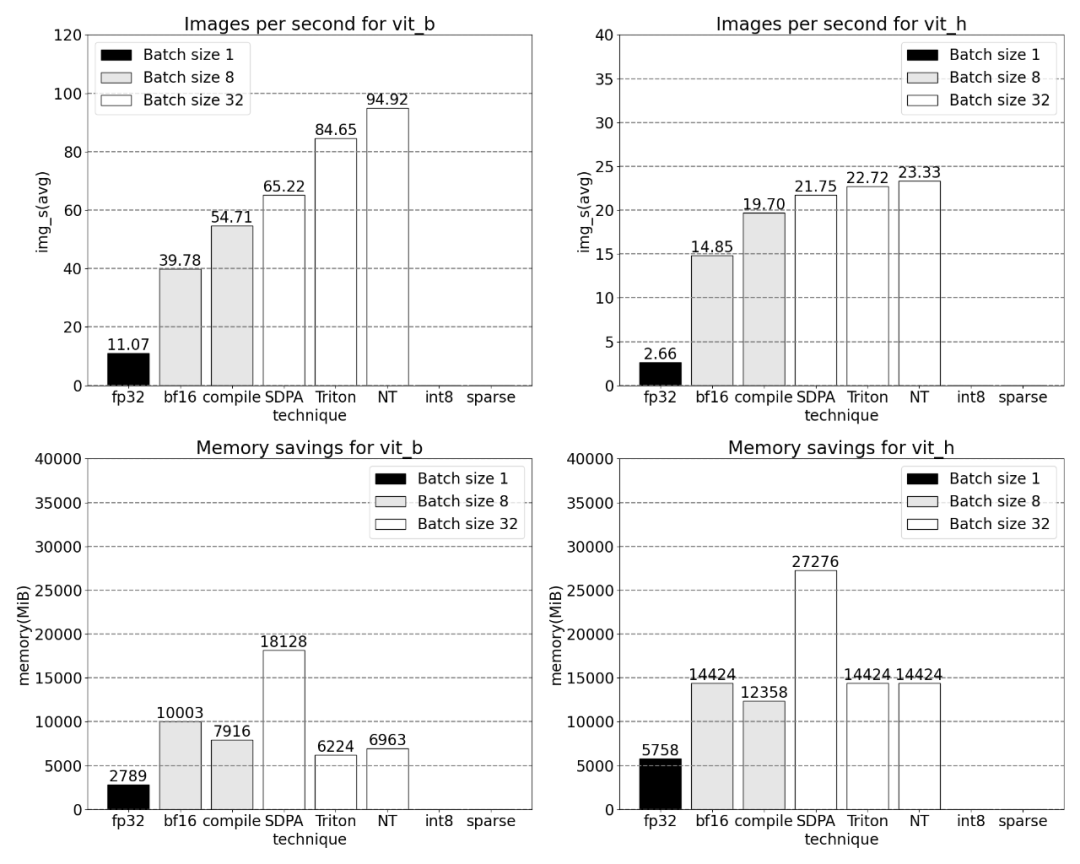
Après l'ajout de la quantification, les résultats de mesure de la taille du lot changent de 32 et plus.
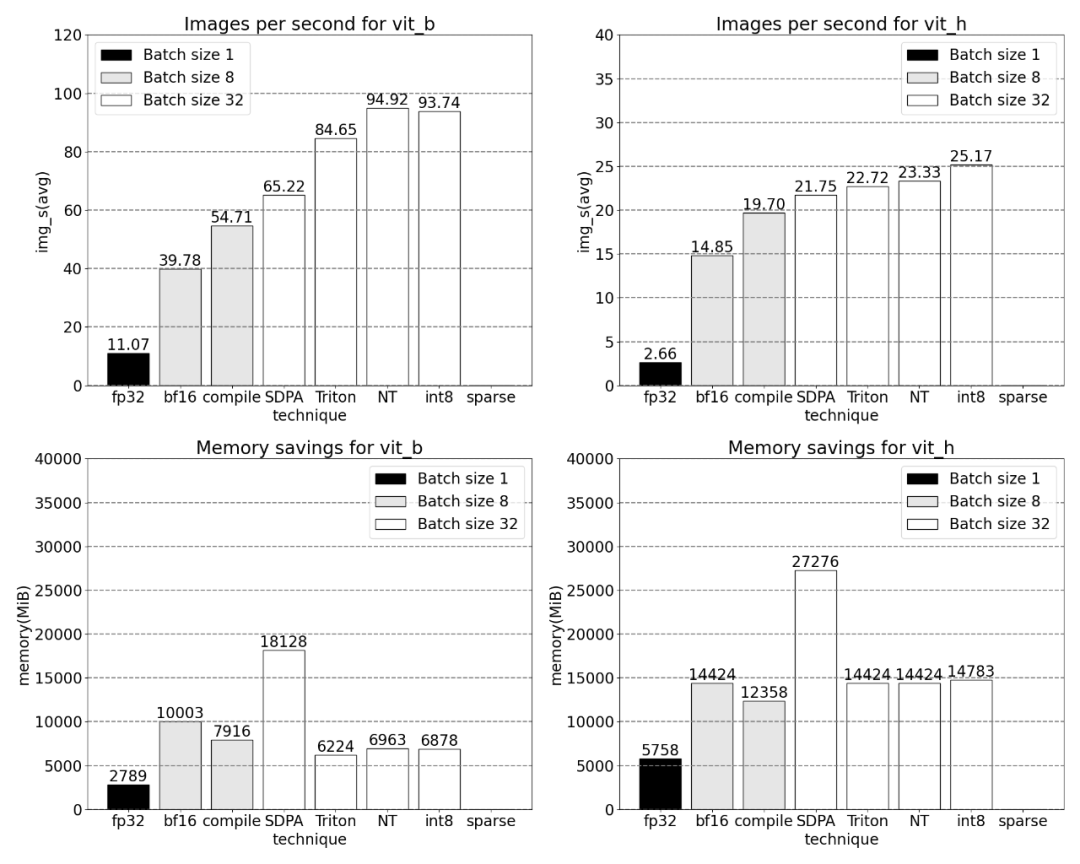
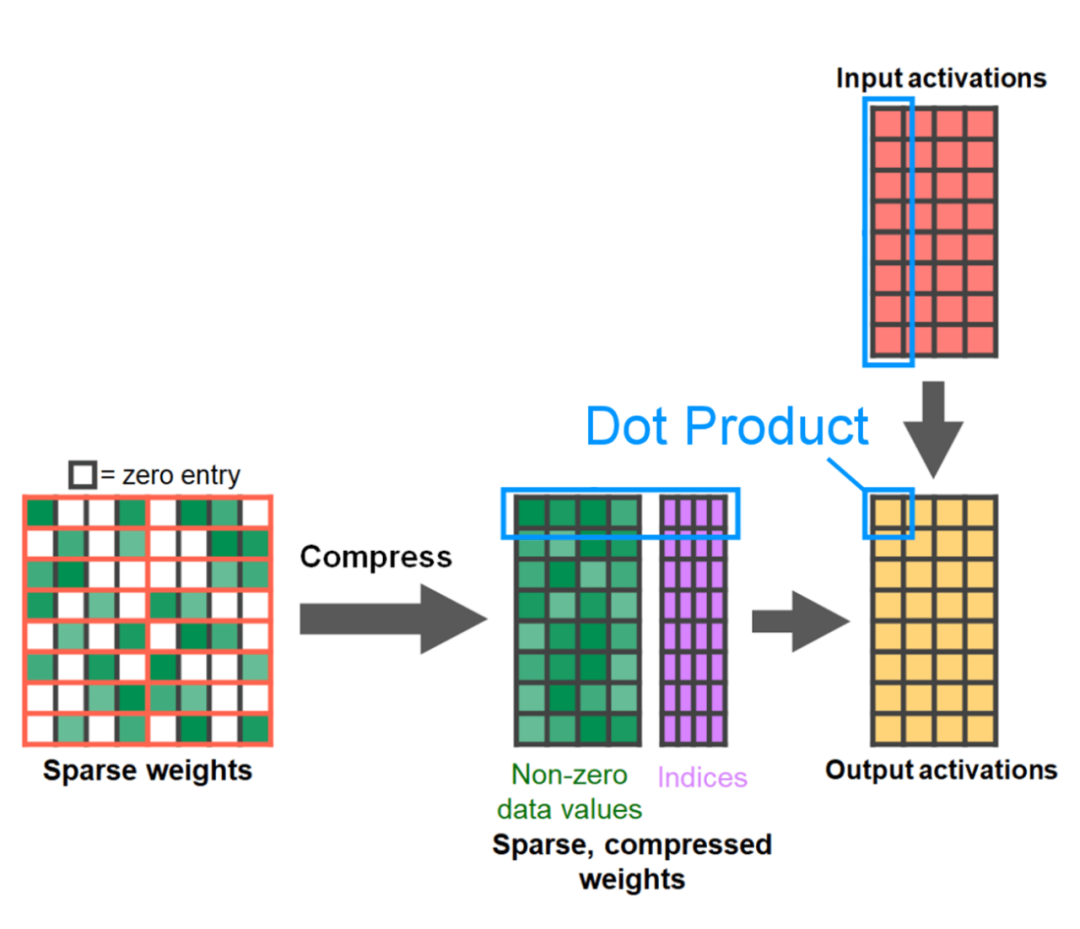
La fin de l'article est la parcimonie semi-structurée. L’étude montre que la multiplication matricielle reste un goulot d’étranglement auquel il faut faire face. La solution consiste à utiliser la sparsification pour approximer la multiplication matricielle. Grâce à des matrices clairsemées (c'est-à-dire en mettant à zéro les valeurs), moins de bits peuvent être utilisés pour stocker les poids et les tenseurs d'activation. Le processus de définition des poids dans un tenseur qui sont mis à zéro est appelé élagage. La suppression de poids plus petits peut potentiellement réduire la taille du modèle sans perte significative de précision.
Il existe de nombreuses méthodes de taille, allant de complètement non structurée à très structurée. Bien que l'élagage non structuré ait théoriquement un impact minime sur la précision, dans le cas clairsemé, le GPU peut subir une dégradation significative des performances, bien qu'il soit très efficace lors de grandes multiplications de matrices denses. Une méthode d'élagage récemment prise en charge par PyTorch est la parcimonie semi-structurée (ou 2:4), qui vise à trouver un équilibre. Cette méthode de stockage clairsemé réduit le tenseur d'origine de 50 % tout en produisant une sortie de tenseur dense. Veuillez vous référer à la figure ci-dessous pour une explication
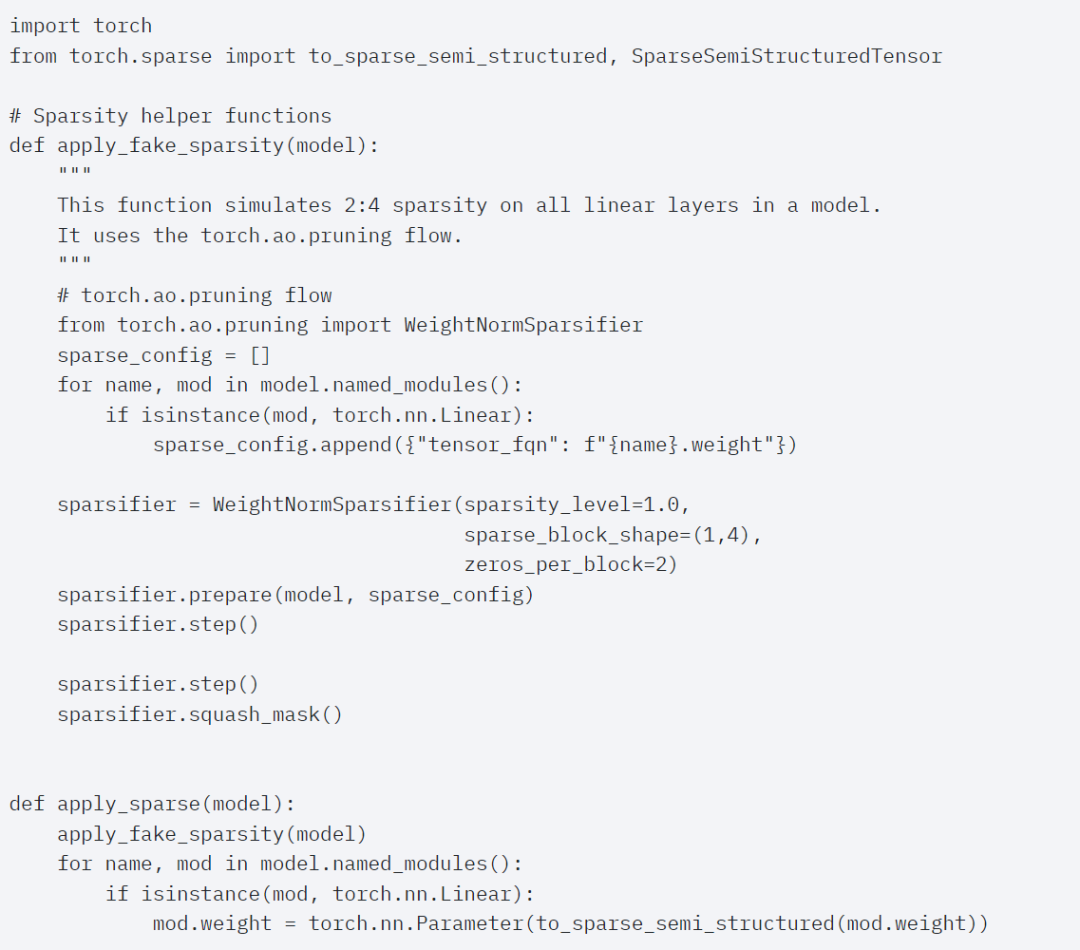
Afin d'utiliser ce format de stockage clairsemé et le noyau rapide associé, la prochaine chose à faire est d'élaguer les poids. Cet article sélectionne les deux plus petits poids pour l'élagage avec une parcimonie de 2:4. Il est facile de changer les poids de la disposition PyTorch (« stried ») par défaut vers cette nouvelle disposition clairsemée semi-structurée. Pour implémenter apply_sparse (modèle), seules 32 lignes de code Python sont requises :
Avec une parcimonie de 2:4, nous observons des performances maximales de SAM avec vit_b et une taille de lot de 32
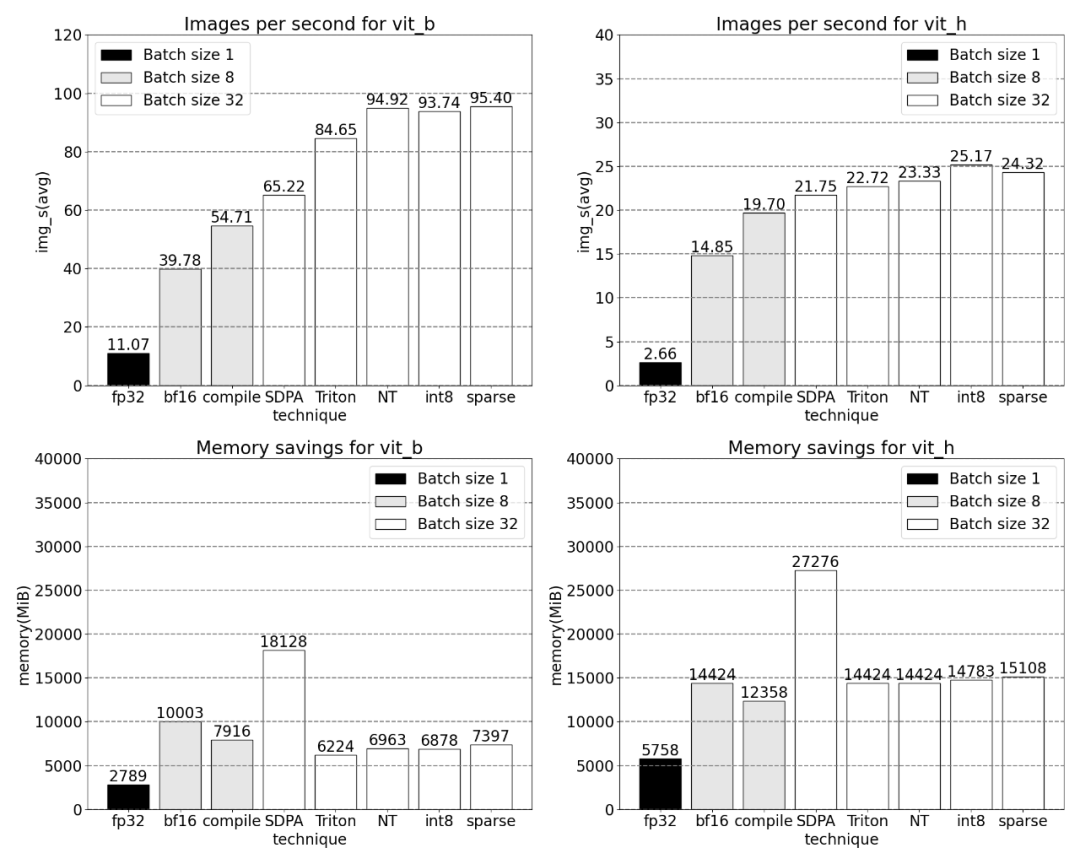
Enfin , le résumé de cet article est le suivant : Cet article présente le moyen le plus rapide d'implémenter Segment Anything sur PyTorch jusqu'à présent. Avec l'aide d'une série de nouvelles fonctionnalités officiellement publiées, cet article réécrit le SAM original en PyTorch pur, et il y a. aucune perte de précision
Pour les lecteurs intéressés, vous pouvez consulter le blog original pour plus d'informations
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser le code de balise Meta pour que le navigateur 360 utilise le mode rapide pour ouvrir les pages Web par défaut
- Qu'est-ce qu'un tas ? Quel est le domaine de la méthode ? Introduction à la zone de tas et de méthode dans le modèle de mémoire JVM
- Comment utiliser la balise en HTML
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Combien de types de modèles de boîtes CSS existe-t-il ?