
Maison >Périphériques technologiques >IA >Titre réécrit : Explorer les domaines d'application de l'apprentissage semi-supervisé et ses scénarios associés
Titre réécrit : Explorer les domaines d'application de l'apprentissage semi-supervisé et ses scénarios associés

- 王林avant
- 2023-11-18 22:21:121311parcourir

Labs Introduction
Avec le développement d'Internet, les entreprises peuvent obtenir de plus en plus de données. Ces données aident les entreprises à mieux comprendre les utilisateurs, appelés profils clients, et peuvent améliorer l'expérience utilisateur. Cependant, ces données peuvent contenir une grande quantité de données non étiquetées. Si toutes les données sont étiquetées manuellement, il y aura deux problèmes. Tout d’abord, l’étiquetage manuel prend du temps et est inefficace. À mesure que la quantité de données augmente, il faudra embaucher davantage de personnes, ce qui prendra plus de temps et coûtera plus cher. Deuxièmement, à mesure que le nombre d'utilisateurs augmente, il est difficile de suivre la croissance des données grâce à l'étiquetage manuel. Partie 01,
Qu'est-ce que l'apprentissage semi-superviséL'apprentissage semi-supervisé fait référence à l'utilisation de l'existant ? labels Les données contiennent des données non étiquetées pour entraîner le modèle. L'apprentissage semi-supervisé construit généralement un espace d'attributs basé sur des données étiquetées, puis extrait des informations efficaces à partir de données non étiquetées pour remplir (ou reconstruire) l'espace d'attributs. Par conséquent, l'ensemble de formation initial de l'apprentissage semi-supervisé est généralement divisé en ensemble de données étiquetées D1 et en ensemble de données non étiquetées D2, puis le modèle d'apprentissage semi-supervisé est formé à travers des étapes de base telles que le prétraitement et l'extraction de fonctionnalités, puis le modèle entraîné. est utilisé pour l’environnement de production afin de fournir des services aux utilisateurs.
Partie 02. Hypothèses de l'apprentissage semi-supervisé 
Afin de compléter efficacement les données étiquetées avec des informations « utiles » dans les données étiquetées, certaines hypothèses sont faites sur la division des données et d'autres aspects. L'hypothèse de base de l'apprentissage semi-supervisé est que p(x) contient les informations de p(y|x), c'est-à-dire que les données non étiquetées doivent contenir des informations utiles pour la prédiction des étiquettes et qui sont différentes des données étiquetées ou qui sont difficiles à comprendre. pour obtenir à partir des données étiquetées des informations extraites des données. De plus, certaines hypothèses servent l’algorithme. Par exemple, l'hypothèse de similarité (hypothèse de douceur) signifie que dans l'espace d'attributs construit par des échantillons de données, des échantillons proches ou similaires ont la même étiquette ; l'hypothèse de séparation de faible densité signifie qu'il existe une frontière de décision qui peut distinguer différentes étiquettes là où il y a. sont quelques échantillons de données.
L'objectif principal de l'hypothèse ci-dessus est de montrer que les données étiquetées et les données non étiquetées proviennent de la même distribution de données.
Partie 03,
Classification des algorithmes d'apprentissage semi-superviséIl existe de nombreux algorithmes d'apprentissage semi-supervisé, qui peuvent être grossièrement divisés en
apprentissage transductif (apprentissage transductif) et apprentissage inductif (modèle inductif) , la différence entre les deux réside dans la sélection de l'ensemble de données de test utilisé pour l'évaluation du modèle. L'apprentissage semi-supervisé par poussée directe signifie que l'ensemble de données qui doit prédire l'étiquette est l'ensemble de données non étiquetées utilisé pour la formation. Le but de l'apprentissage est d'améliorer encore la précision des résultats de prédiction. L'apprentissage inductif prédit les étiquettes pour des ensembles de données complètement inconnus.
De plus, les étapes des algorithmes d'apprentissage semi-supervisé courants sont : la première étape consiste à entraîner un modèle sur des données étiquetées, puis à utiliser ce modèle pour étiqueter des données non étiquetées, puis à combiner les pseudo-étiquettes et le les données étiquetées sont combinées dans un nouvel ensemble de formation, un nouveau modèle est formé sur cet ensemble de formation et enfin le modèle est utilisé pour étiqueter l'ensemble de données de prédiction. 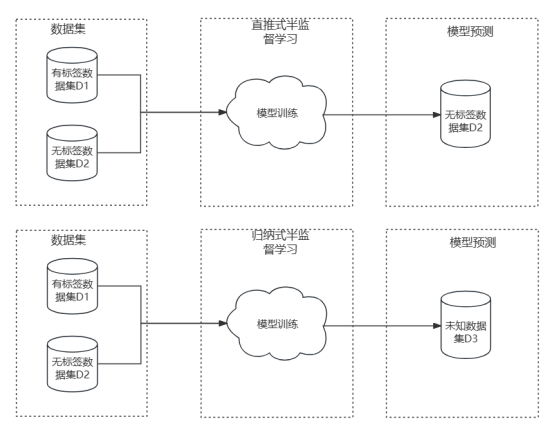
Partie 04, Résumé
Le plus gros problème de l'apprentissage semi-supervisé est que dans de nombreux cas, les performances du modèle dépendent de l'ensemble de données étiquetées et les exigences de qualité pour l'ensemble de données étiquetées sont élevées, même l'apprentissage semi-supervisé La précision de prédiction du modèle d'apprentissage supervisé n'est pas très différente des résultats du modèle supervisé basé sur l'ensemble de données étiquetées. Au contraire, le modèle semi-supervisé consommera plus de ressources afin d'extraire efficacement l'efficacité. informations à partir des données non étiquetées. Par conséquent, l’orientation du développement de l’apprentissage semi-supervisé est d’améliorer la robustesse de l’algorithme et l’efficacité de l’extraction des données.
Actuellement dans le domaine de l'apprentissage semi-supervisé, le PU-Learning (apprentissage par échantillons positifs et négatifs) est un algorithme populaire. Ce type d'algorithme est principalement appliqué aux ensembles de données contenant uniquement des échantillons positifs et des données non étiquetées. Son avantage est que dans certains scénarios, nous pouvons obtenir relativement facilement des ensembles de données d’échantillons positifs fiables et que la quantité de données est relativement importante. Par exemple, dans la détection du spam, nous pouvons facilement obtenir une grande quantité de données de courrier électronique normales
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!