
Maison >Périphériques technologiques >IA >La carte graphique NVIDIA RTX accélère l'inférence de l'IA de 5 fois ! RTX PC gère facilement les grands modèles localement
La carte graphique NVIDIA RTX accélère l'inférence de l'IA de 5 fois ! RTX PC gère facilement les grands modèles localement

- 王林avant
- 2023-11-17 23:05:431421parcourir
Lors de la conférence technologique mondiale Microsoft Iginte, Microsoft a publié une série de nouveaux modèles d'optimisation et de ressources d'outils de développement liés à l'IA, dans le but d'aider les développeurs à utiliser pleinement les performances du matériel et à élargir les domaines d'application de l'IA
Surtout pour NVIDIA, qui occupe actuellement une position dominante absolue dans le domaine de l'IA, Microsoft a cette fois envoyé un gros cadeau, Qu'il s'agisse de l'interface de packaging TensorRT-LLM pour l'API OpenAI Chat ou de l'amélioration des performances du pilote RTX DirectML pour Llama 2, ainsi que d'autres modèles de langage étendus (LLM) populaires, peuvent obtenir une meilleure accélération et une meilleure application sur le matériel NVIDIA.
Parmi eux, TensorRT-LLM est une bibliothèque utilisée pour accélérer l'inférence LLM, ce qui peut considérablement améliorer les performances d'inférence de l'IA. Elle est constamment mise à jour pour prendre en charge de plus en plus de modèles de langage, et elle est également open source.
NVIDIA a publié TensorRT-LLM pour la plate-forme Windows en octobre. Pour les ordinateurs de bureau et les ordinateurs portables équipés de cartes graphiques GPU de la série RTX 30/40, tant que la mémoire graphique atteint 8 Go ou plus, il sera plus facile d'effectuer des charges de travail d'IA exigeantes
Maintenant, Tensor RT-LLM pour Windows peut être compatible avec l'API de chat populaire d'OpenAI via une nouvelle interface de packaging, de sorte que diverses applications associées peuvent être exécutées directement localement sans avoir besoin de se connecter au cloud, ce qui est propice à la rétention sur PC. Données privées et propriétaires pour éviter les fuites de confidentialité.
Tant qu'il s'agit d'un grand modèle de langage optimisé par TensorRT-LLM, il peut être utilisé avec cette interface de package, notamment Llama 2, Mistral, NV LLM, etc.
Pour les développeurs, il n'y a pas besoin de réécriture et de portage fastidieux du code Modifiez simplement une ou deux lignes de code et l'application d'IA peut être exécutée rapidement localement.

↑↑↑Plug-in de code Microsoft Visual Studio basé sur TensorRT-LLM - Assistant de codage Continue.dev
TensorRT-LLM v0.6.0 sera mis à jour à la fin de ce mois, ce qui améliorera jusqu'à 5 fois les performances d'inférence sur le GPU RTX et prendra en charge des LLM plus populaires, y compris le nouveau paramètre de 7 milliards Mistral, The 8 milliard de paramètres Nemotron-3 permet aux ordinateurs de bureau et portables d'exécuter LLM localement à tout moment, rapidement et avec précision.
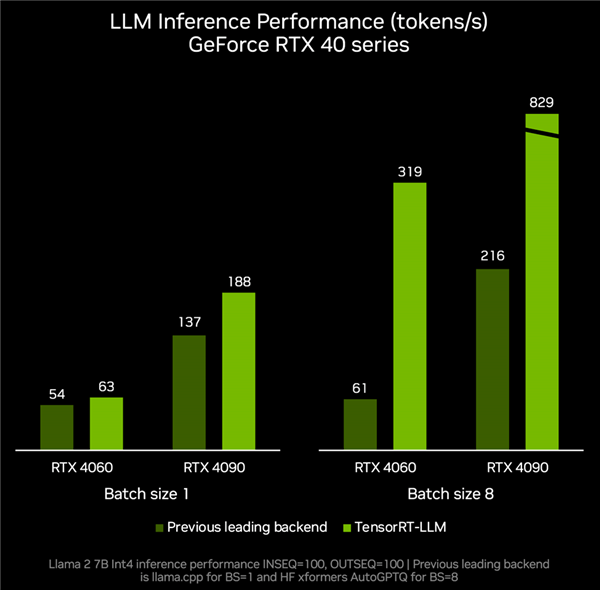
Selon les données de mesure réelles, la carte graphique RTX 4060 associée à TenroRT-LLM, les performances d'inférence peuvent atteindre 319 jetons par seconde, soit 4,2 fois plus rapides que les 61 jetons par seconde des autres backends.
RTX 4090 peut accélérer de jetons par seconde à 829 jetons par seconde, soit une augmentation de 2,8 fois.
Avec ses puissantes performances matérielles, son riche écosystème de développement et son large éventail de scénarios d'application, NVIDIA RTX devient un assistant indispensable et puissant pour l'IA locale. Dans le même temps, avec l'enrichissement continu de l'optimisation, des modèles et des ressources, la popularité des fonctions d'IA sur des centaines de millions de PC RTX s'accélère également
Actuellement, plus de 400 partenaires ont publié des applications et des jeux d'IA prenant en charge l'accélération GPU RTX. À mesure que la facilité d'utilisation des modèles continue de s'améliorer, je pense que de plus en plus de fonctions AIGC apparaîtront sur la plate-forme PC Windows.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI