
Maison >Périphériques technologiques >IA >Classement du taux d'hallucinations des grands modèles : GPT-4 est le plus bas à 3 % et Google Palm atteint 27,2 %
Classement du taux d'hallucinations des grands modèles : GPT-4 est le plus bas à 3 % et Google Palm atteint 27,2 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-14 20:33:071065parcourir
Le développement de l'intelligence artificielle progresse rapidement, mais des problèmes surviennent souvent. La nouvelle API de vision GPT d'OpenAI est étonnante pour son front-end, mais il est également difficile de se plaindre pour son back-end en raison de problèmes d'hallucination.
L'illusion a toujours été le défaut fatal des grands modèles. En raison de la complexité de l’ensemble de données, il est inévitable qu’il y ait des informations obsolètes et erronées, ce qui posera de graves problèmes en termes de qualité de sortie. Trop d’informations répétées peuvent également biaiser les grands modèles, ce qui est aussi une sorte d’illusion. Mais les hallucinations ne sont pas des propositions sans réponse. Au cours du processus de développement, une utilisation prudente des ensembles de données, un filtrage strict, la construction d'ensembles de données de haute qualité et l'optimisation de la structure du modèle et des méthodes de formation peuvent atténuer dans une certaine mesure le problème des hallucinations.
Il existe tellement de modèles populaires à grande échelle, quelle est leur efficacité pour soulager les hallucinations ? Voici un classement qui compare clairement leurs différences
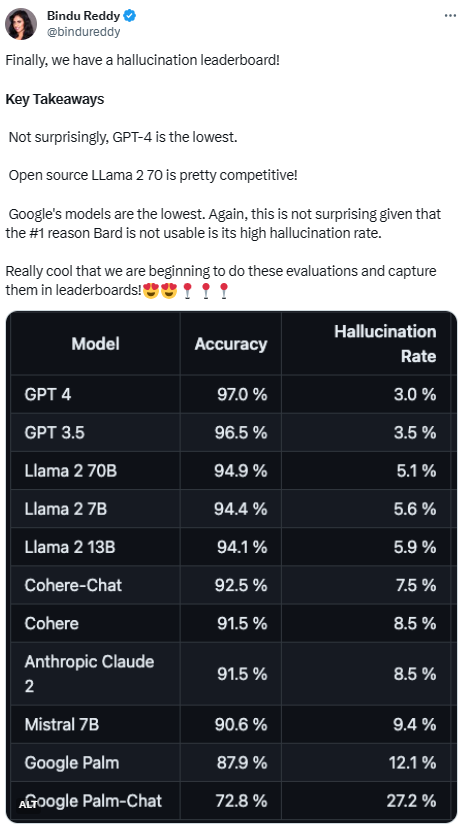
La plateforme Vectara a publié ce classement, qui se concentre sur l'intelligence artificielle. La date de mise à jour du classement est le 1er novembre 2023. Vectara a déclaré qu'ils continueront à suivre l'évaluation des hallucinations afin de mettre à jour le classement au fur et à mesure de la mise à jour du modèle
Adresse du projet : https://github.com /vectara /hallucination-leaderboard
Pour déterminer ce classement, Vectara a mené une étude de cohérence factuelle et formé un modèle pour détecter les hallucinations dans les résultats du LLM. Ils ont utilisé un modèle SOTA comparable et ont fourni à chaque LLM 1 000 documents courts via une API publique et leur ont demandé de résumer chaque document en utilisant uniquement les faits présentés dans le document. Parmi ces 1 000 documents, seuls 831 documents ont été résumés par chaque modèle, et les documents restants ont été rejetés par au moins un modèle en raison de restrictions de contenu. À l’aide de ces 831 documents, Vectara a calculé la précision globale et le taux d’illusion de chaque modèle. Le taux auquel chaque modèle refuse de répondre aux invites est détaillé dans la colonne « Taux de réponse ». Aucun contenu envoyé au modèle ne contient de contenu illégal ou dangereux, mais contient suffisamment de mots déclencheurs pour déclencher certains filtres de contenu. Ces documents proviennent principalement du corpus CNN/Daily Mail
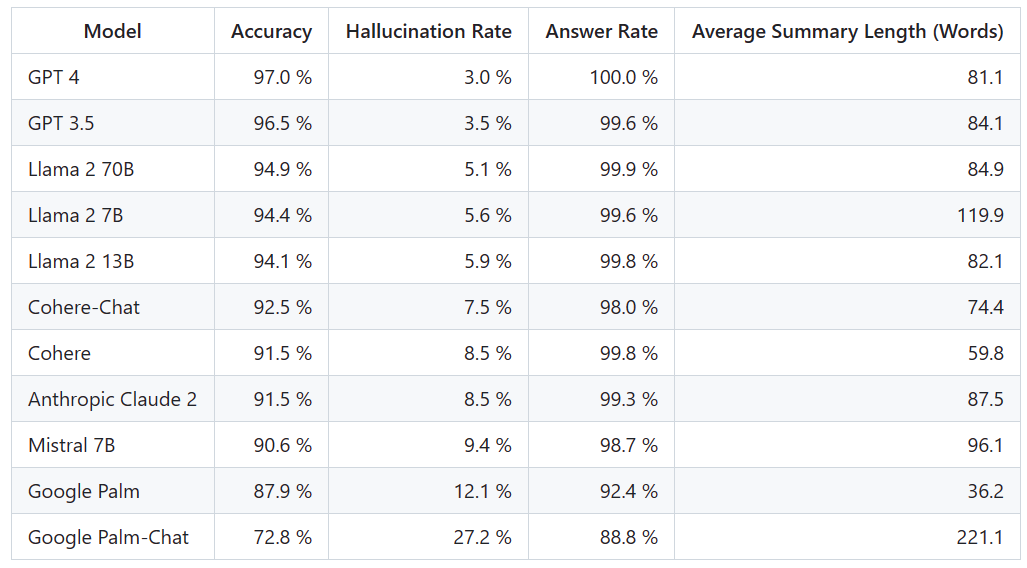
Il est important de noter que Vectara évalue l’exactitude sommaire, et non l’exactitude factuelle globale. Cela permet de comparer la réponse du modèle aux informations fournies. En d’autres termes, ce qui est évalué est de savoir si le résumé des résultats est « factuellement cohérent » avec le document source. Sans savoir sur quelles données chaque LLM a été formé, il est impossible de déterminer l'hallucination pour un problème particulier. De plus, construire un modèle capable de déterminer si une réponse est une hallucination sans source de référence nécessiterait de résoudre le problème de l'hallucination et nécessiterait de former un modèle aussi grand ou plus grand que le LLM évalué. Par conséquent, Vectara a choisi d’examiner les taux d’hallucinations dans la tâche de synthèse, car une telle analogie est un bon moyen de déterminer le réalisme global du modèle.
L'adresse de détection du modèle d'hallucination est : https://huggingface.co/vectara/hallucination_evaluation_model
De plus, de plus en plus de LLM sont utilisés dans le pipeline RAG (Retrieval Augmented Generation) pour répondre aux requêtes des utilisateurs. tels que l'intégration de Bing Chat et de Google Chat. Dans le système RAG, le modèle est déployé comme un agrégateur de résultats de recherche, ce classement est donc également un bon indicateur de la précision du modèle lorsqu'il est utilisé dans le système RAG
Compte tenu des performances de GPT-4, son illusion Le taux le plus bas ne semble pas surprenant. Cependant, certains internautes se sont dits surpris qu'il n'y ait pas beaucoup de différence entre GPT-3.5 et GPT-4

Après avoir rattrapé GPT-4 et GPT-3.5, LLaMA 2 a bien fonctionné. Cependant, les performances des grands modèles de Google n'étaient pas satisfaisantes. Certains internautes ont déclaré que le BARD de Google utilise souvent « Je m'entraîne encore » pour éviter ses mauvaises réponses

Avec une telle liste de classement, nous pouvons avoir une compréhension plus intuitive des avantages et des inconvénients des différents modèles de juge. . Il y a quelques jours, OpenAI a lancé GPT-4 Turbo Non, certains internautes ont immédiatement proposé de le mettre à jour dans le classement.

Nous attendrons de voir à quoi ressemblera le prochain classement et s'il y aura des changements majeurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment exporter un modèle dans Navicat
- Quelles couches le modèle TCP/IP inclut-il ?
- Comment faire apparaître la barre d'attributs AI
- Que dois-je faire si l'écran bleu Win10 apparaît avec le code d'erreur d'échec du contrôle de sécurité du noyau ?
- Quels sont les modèles courants de développement de logiciels ?