
Maison >Périphériques technologiques >IA >Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music
Système de recommandation pour la technologie de démarrage à froid NetEase Cloud Music

- PHPzavant
- 2023-11-14 08:14:101145parcourir

1. Contexte du problème : La nécessité et l'importance de la modélisation du démarrage à froid
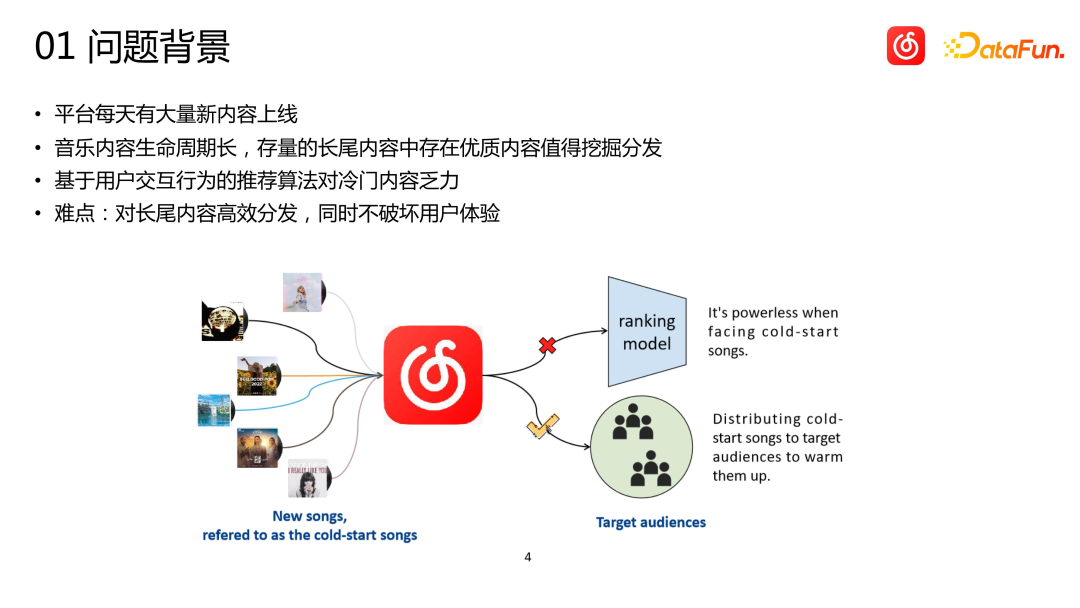
En tant que plate-forme de contenu, Cloud Music propose chaque jour une grande quantité de nouveaux contenus en ligne. Bien que la quantité de nouveau contenu sur la plateforme musicale cloud soit relativement faible par rapport à d'autres plateformes telles que les courtes vidéos, la quantité réelle peut dépasser de loin l'imagination de chacun. Dans le même temps, le contenu musical est très différent des courtes vidéos, des actualités et des recommandations de produits. Le cycle de vie de la musique s’étend sur des périodes extrêmement longues, souvent mesurées en années. Certaines chansons peuvent exploser après avoir été inactives pendant des mois ou des années, et les chansons classiques peuvent encore avoir une forte vitalité même après plus de dix ans. Par conséquent, pour le système de recommandation des plateformes musicales, il est plus important de découvrir des contenus impopulaires et de longue traîne de haute qualité et de les recommander aux bons utilisateurs que de recommander d'autres catégories
Articles impopulaires et à longue traîne (Chansons). ) En raison du manque de données sur les interactions des utilisateurs, il est très difficile pour les systèmes de recommandation qui s'appuient principalement sur des données comportementales d'obtenir une distribution précise. La situation idéale est de permettre qu’une petite partie du trafic soit utilisée pour l’exploration et la distribution, et d’accumuler des données pendant l’exploration. Cependant, le trafic en ligne est très précieux et l’exploration nuit souvent facilement à l’expérience utilisateur. En tant que rôle directement responsable des indicateurs métiers, les recommandations ne nous permettent pas de faire trop d'explorations incertaines sur ces éléments de longue traîne. Par conséquent, nous devons être en mesure de trouver les utilisateurs cibles potentiels de l'élément avec plus de précision dès le début, c'est-à-dire de démarrer l'élément à froid sans aucun enregistrement d'interaction.
Deuxièmement, les solutions techniques : sélection des fonctionnalités, modélisation du modèle
Ensuite, je partagerai les solutions techniques adoptées par Cloud Music.

Le problème principal est de savoir comment trouver des utilisateurs cibles potentiels pour les projets de démarrage à froid. Nous divisons la question en deux parties :
Dans le cas où aucun utilisateur ne clique pour jouer, quelles autres informations efficaces le projet de démarrage à froid possède-t-il et qui peuvent être utilisées comme fonctionnalités pour nous aider à distribuer ? Nous utilisons ici les fonctionnalités multimodales de la musique
Comment utiliser ces fonctionnalités pour modéliser la distribution de démarrage à froid ? Pour résoudre ce problème, nous partagerons deux solutions de modélisation principales :
- Modélisation I2I : algorithme de démarrage à froid amélioré par apprentissage contrastif autoguidé.
- Modélisation U2I : modélisation multimodale des limites d'intérêt des utilisateurs DSSM.
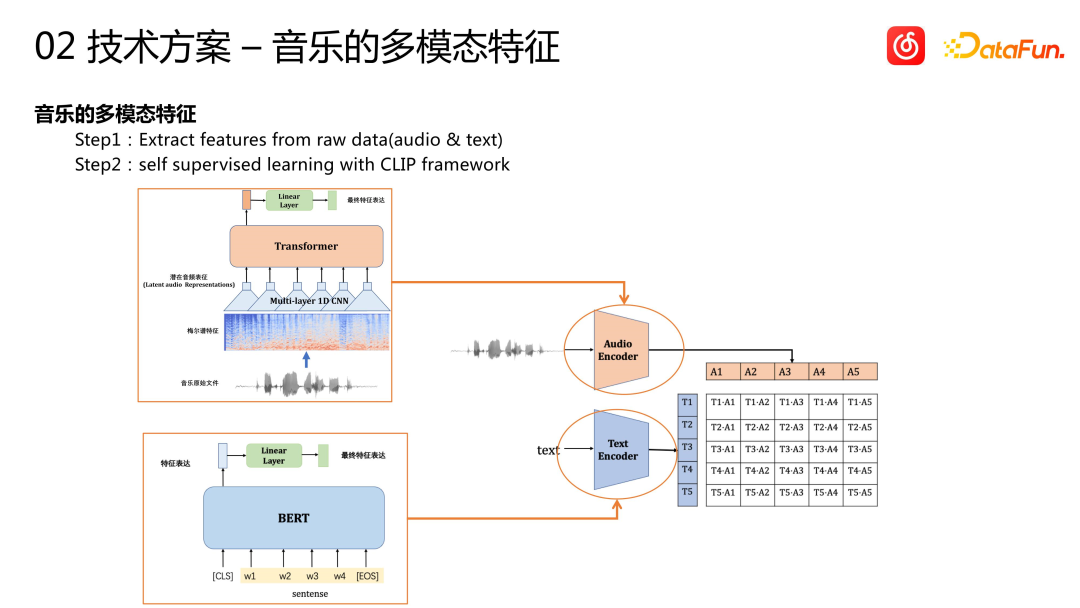
Réécrit en chinois : La chanson elle-même est une sorte d'information multimodale. En plus des informations de balise telles que la langue et le genre, l'audio et le texte de la chanson (y compris le titre et les paroles de la chanson) contiennent des informations riches. Comprendre ces informations et découvrir les corrélations entre elles et le comportement des utilisateurs est la clé d'un démarrage à froid réussi. Actuellement, la plate-forme de musique cloud utilise le framework CLIP pour obtenir une expression de fonctionnalités multimodale. Pour les fonctionnalités audio, certaines méthodes de traitement du signal audio sont d'abord utilisées pour les convertir sous la forme du domaine vidéo, puis des modèles de séquence tels que Transformer sont utilisés pour l'extraction et la modélisation des fonctionnalités, et enfin un vecteur audio est obtenu. Pour les fonctionnalités de texte, le modèle BERT est utilisé pour l'extraction de fonctionnalités. Enfin, le cadre de pré-formation auto-supervisé de CLIP est utilisé pour sérialiser ces fonctionnalités afin d'obtenir la représentation multimodale de la chanson
Pour la modélisation multimodale, il existe deux approches dans l'industrie. La première consiste à intégrer des fonctionnalités multimodales dans le modèle de recommandation commerciale pour une formation de bout en bout en une seule étape, mais cette méthode est plus coûteuse. Nous avons donc choisi une modélisation en deux étapes. Effectuez d'abord une modélisation préalable à la formation, puis saisissez ces fonctionnalités dans le modèle de rappel ou le modèle de raffinement de l'entreprise en aval pour utilisation.
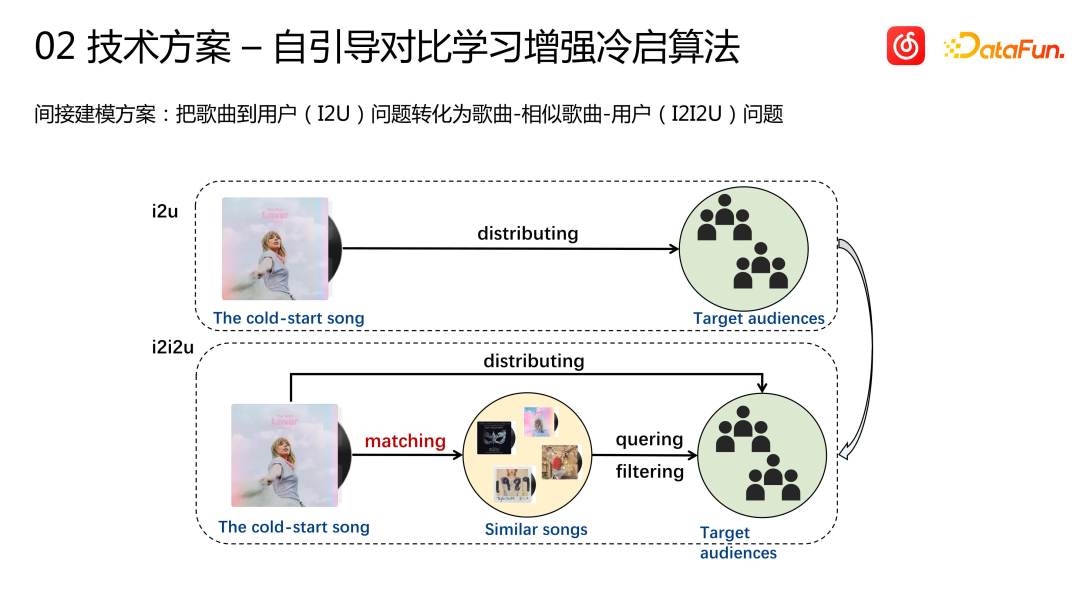
Comment distribuer une chanson aux utilisateurs sans interaction de l'utilisateur ? Nous adoptons une solution de modélisation indirecte : transformer le problème de chanson à utilisateur (I2U) en un problème de chanson à utilisateur de chanson similaire (I2I2U), c'est-à-dire qu'il faut d'abord trouver des chansons similaires à cette chanson de démarrage à froid, puis ces chansons similaires sont correspondant à l'utilisateur Il existe des enregistrements d'interaction historiques, tels que des collections et d'autres signaux relativement forts, et un groupe d'utilisateurs cibles peut être trouvé. Cette chanson de lancement à froid est ensuite distribuée à ces utilisateurs cibles.
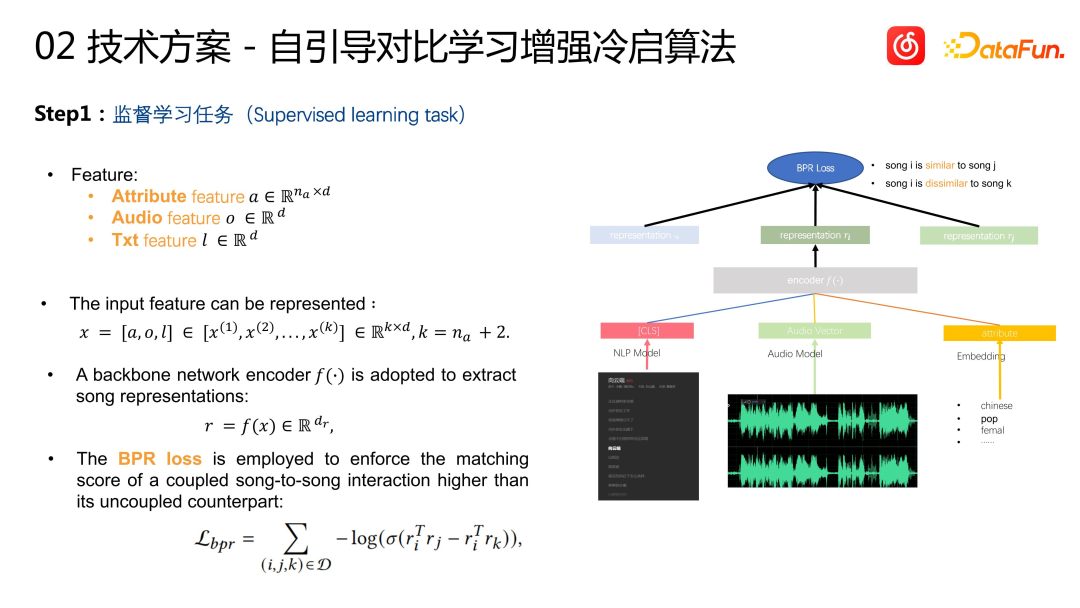
La méthode spécifique est la suivante. La première étape est la tâche d'apprentissage supervisé. En termes de fonctionnalités de chanson, en plus des informations multimodales que nous venons de mentionner, il comprend également des informations sur les balises de chanson, telles que la langue, le genre, etc., pour nous aider à réaliser une modélisation personnalisée. Nous regroupons toutes les fonctionnalités ensemble, les entrons dans un encodeur et enfin produisons des vecteurs de chanson. La similarité de chaque vecteur de chanson peut être représentée par le produit interne vectoriel. L'objectif d'apprentissage est la similarité d'I2I calculée en fonction du comportement, c'est-à-dire la similarité du filtrage collaboratif. Nous ajoutons une couche de vérification post-test basée sur les données de filtrage collaboratif, c'est-à-dire, sur la base de la recommandation I2I, l'effet des commentaires des utilisateurs. C'est mieux Une paire d'éléments est utilisée comme échantillon positif pour l'apprentissage afin de garantir l'exactitude de l'objectif d'apprentissage. Les échantillons négatifs sont construits à l’aide d’un échantillonnage aléatoire global. La fonction de perte utilise la perte BPR. Il s'agit d'une approche CB2CF très standard dans le système de recommandation, qui consiste à apprendre la similitude des chansons dans les caractéristiques de comportement des utilisateurs en fonction du contenu et des informations sur l'étiquette de la chanson
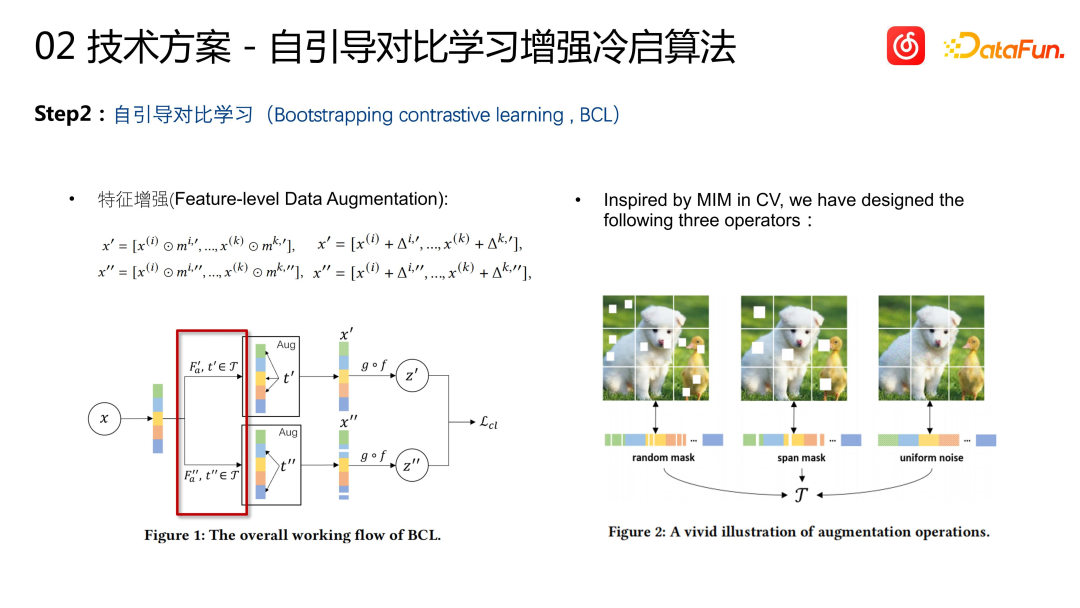
Sur la base de la méthode ci-dessus, nous avons introduit la comparaison apprentissage Comme deuxième itération. La raison pour laquelle nous avons choisi d'introduire l'apprentissage contrastif est que dans cet ensemble d'apprentissage de processus, nous utilisons toujours des données CF et devons apprendre à travers le comportement interactif de l'utilisateur. Cependant, une telle méthode d'apprentissage peut conduire à un problème, c'est-à-dire que les éléments appris auront un biais de type « les éléments les plus populaires sont appris et les éléments les moins populaires sont appris ». Bien que notre objectif soit d'apprendre du contenu multimodal des chansons aux similitudes comportementales des chansons, il a été constaté dans la formation réelle qu'il existe toujours un problème de biais populaire et impopulaire.
Par conséquent, nous avons introduit un ensemble d'algorithmes d'apprentissage contrastés. , visant à améliorer la capacité d’apprentissage des éléments impopulaires. Tout d’abord, nous devons avoir une représentation de Item, qui est apprise via l’encodeur multimodal précédent. Ensuite, deux transformations aléatoires sont effectuées sur cette représentation. Il s'agit d'une pratique courante en CV, qui consiste à masquer ou à ajouter du bruit aux caractéristiques de manière aléatoire. Deux représentations modifiées aléatoirement générées par le même élément sont considérées comme similaires, et deux représentations générées par des éléments différents sont considérées comme différentes. Ce mécanisme d'apprentissage contrastif est une amélioration des données pour l'apprentissage par démarrage à froid. Grâce à cela, la méthode génère des paires d'échantillons de base de connaissances d'apprentissage contrastif.

Sur la base de l'amélioration des fonctionnalités, nous avons également ajouté un mécanisme de regroupement d'associations
Le contenu réécrit est le suivant : Mécanisme de regroupement de corrélation : calculez d'abord la corrélation entre chaque paire de caractéristiques, c'est-à-dire maintenez une matrice de corrélation et mettez à jour la matrice pendant le processus de formation du modèle. Les caractéristiques sont ensuite divisées en deux groupes en fonction de la corrélation entre elles. L'opération spécifique consiste à sélectionner au hasard une fonctionnalité, à placer la moitié des fonctionnalités les plus pertinentes pour la fonctionnalité dans un groupe et à placer les autres dans un autre groupe. Enfin, chaque ensemble de caractéristiques est transformé de manière aléatoire pour générer des paires d'échantillons pour un apprentissage contrastif. De cette façon, N éléments dans chaque lot généreront 2N vues. Une paire de vues du même projet est utilisée comme échantillon positif pour l’apprentissage contrastif, et une paire de vues provenant de différents projets est utilisée comme échantillon négatif pour l’apprentissage contrastif. La perte d'apprentissage contrastif utilise l'entropie croisée normalisée de l'information (infoNCE) et est combinée avec la perte BPR de la partie d'apprentissage supervisée précédente comme fonction de perte finale
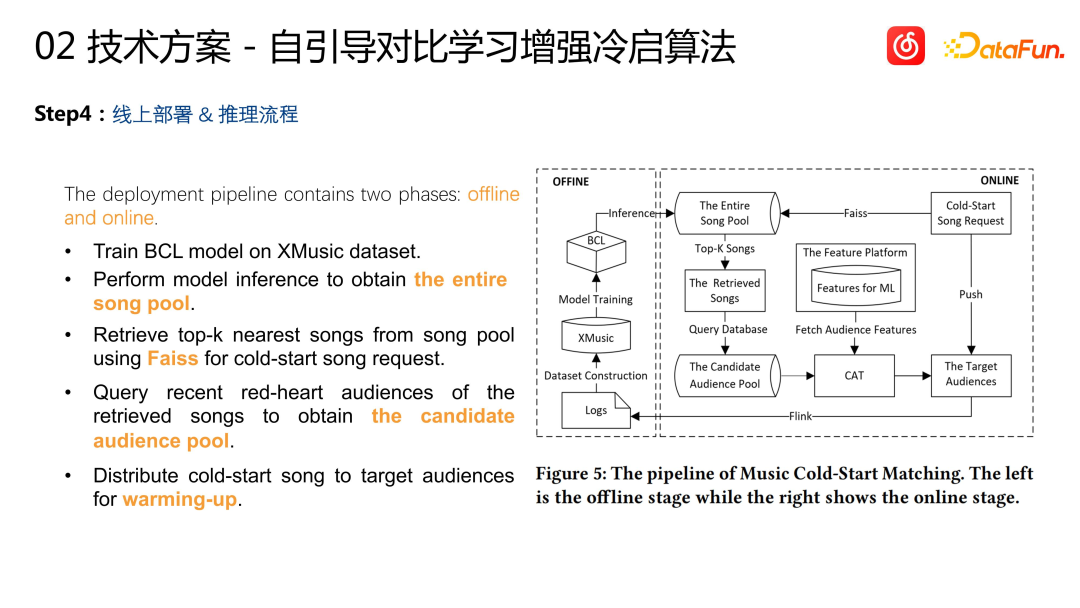
Déploiement et processus d'inférence en ligne : terminé lors d'une formation hors ligne. , un index vectoriel est construit pour toutes les chansons existantes. Pour un nouveau projet démarré à froid, son vecteur est obtenu grâce à un raisonnement de modèle, puis certains des projets les plus similaires sont récupérés à partir de l'index vectoriel. Ces projets sont des projets de stock antérieurs, il existe donc un lot d'interactions historiques avec eux. comme la lecture, la collecte, etc.) distribuez le projet qui nécessite un démarrage à froid à ce groupe d'utilisateurs pour terminer le démarrage à froid du projet
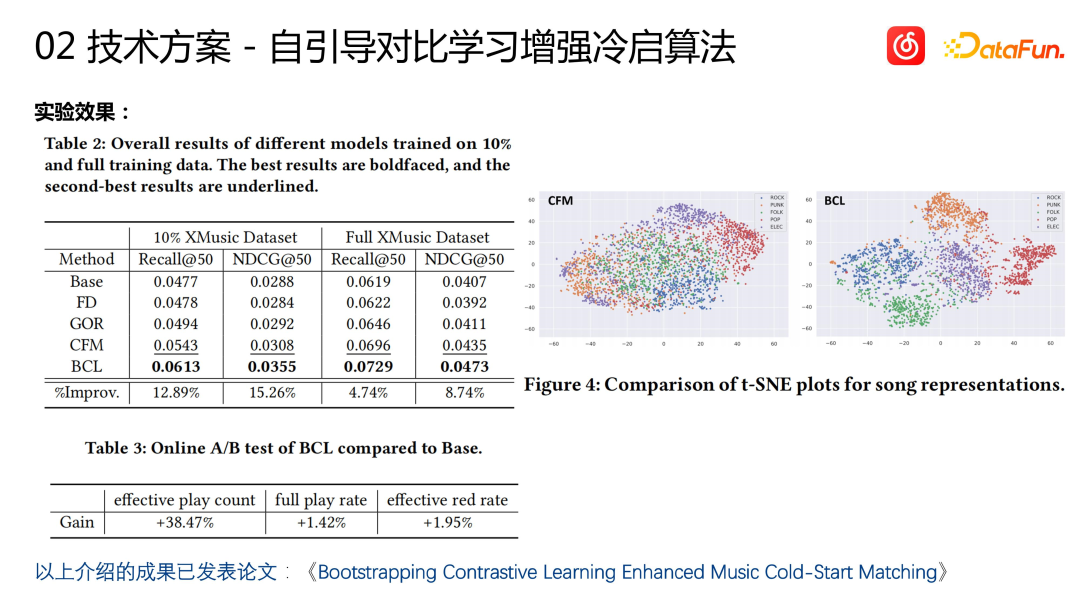
Nous avons évalué l'algorithme de démarrage à froid, y compris l'évaluation des indicateurs hors ligne et hors ligne, et avons obtenu de très bons résultats. Comme le montre la figure ci-dessus, la représentation de la chanson calculée par le modèle de démarrage à froid peut obtenir d'excellents résultats pour les chansons de différents genres. l’effet de regroupement. Certains résultats ont été publiés dans des articles publics (Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching). En ligne, tout en trouvant plus d'utilisateurs cibles potentiels (+38 %), l'algorithme de démarrage à froid a également permis d'améliorer les indicateurs commerciaux tels que le taux de collecte des articles démarrés à froid (+1,95 %) et le taux d'achèvement (+1,42 %).

Nous réfléchissons plus loin :
- Dans le schéma I2I2U ci-dessus, aucune fonctionnalité côté utilisateur n'est utilisée.
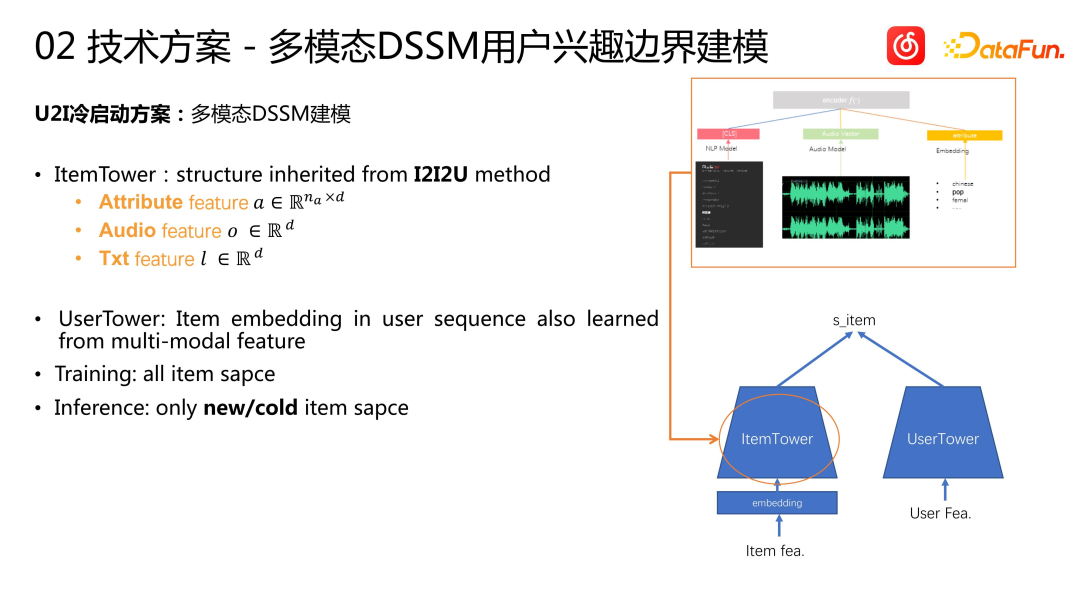
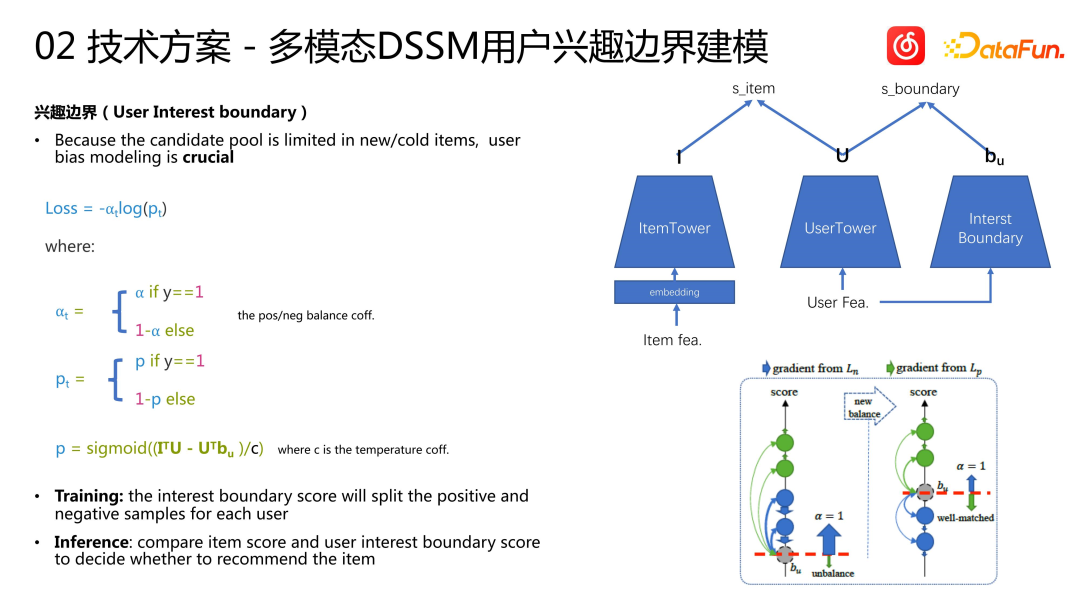
- Comment introduire des fonctionnalités utilisateur pour faciliter le démarrage à froid d'un article ? Le schéma de démarrage à froid U2I adopte la méthode de modélisation DSSM multimodale. Le modèle se compose d’une ItemTower et d’une UserTower. Nous avons hérité des fonctionnalités multimodales de la chanson précédente dans la ItemTower, User Tower, créant ainsi une User Tower classique. Nous effectuons une modélisation d'apprentissage multimodale des séquences d'utilisateurs. La formation du modèle est basée sur l'espace complet des éléments. Qu'il s'agisse de chansons impopulaires ou populaires, elles seront utilisées comme échantillons pour entraîner le modèle. Lorsque vous faites des déductions, faites uniquement des déductions sur les nouvelles chansons encerclées ou sur le pool de chansons impopulaires. Cette approche est similaire à certaines solutions précédentes à deux tours : pour les objets populaires, construisez une tour, et pour les objets nouveaux ou impopulaires, construisez une autre tour pour les gérer. Cependant, nous traitons les articles réguliers et les articles démarrés à froid de manière plus indépendante. Nous utilisons un modèle de rappel régulier pour les articles réguliers, et pour les articles impopulaires, nous utilisons un modèle DSSM spécialement construit
3.Résumé
Enfin, faites un résumé. Le travail principal de modélisation multimodale de démarrage à froid recommandé par Cloud Music comprend :
 En termes de fonctionnalités, le framework de pré-formation CLIP est utilisé pour modéliser la multi-modalité.
En termes de fonctionnalités, le framework de pré-formation CLIP est utilisé pour modéliser la multi-modalité.
- Deux schémas de modélisation sont utilisés dans le schéma de modélisation, la modélisation indirecte I2I2U et la modélisation directe DSSM multimodale à démarrage à froid.
- Perte et en termes d'objectifs d'apprentissage, le BPR et l'apprentissage contrasté sont introduits du côté de l'élément, et la limite d'intérêt du côté de l'utilisateur améliore l'apprentissage impopulaire des éléments et l'apprentissage des utilisateurs.
- Il existe deux directions principales pour une optimisation future. La première direction est la modélisation par fusion multimodale de contenu et de caractéristiques comportementales. La deuxième direction est l'optimisation full-link du rappel et du tri
4. Séance de questions et réponses
Q1 : Quels sont les principaux indicateurs du démarrage à froid de la musique ?
A1 : Nous prêterons attention à de nombreux indicateurs, dont les plus importants sont le taux de collecte et le taux d'achèvement = PV de collecte/PV joué, taux d'achèvement = PV complètement joué/PV joué.
Q2 : Les fonctionnalités multimodales sont-elles formées ou pré-formées de bout en bout ? Lors de la génération de la vue de comparaison dans la deuxième étape, quelles sont les caractéristiques spécifiques de l'entrée x ?
A2 : Notre solution actuelle consiste à pré-former sur la base du framework CLIP et à utiliser les fonctionnalités multimodales obtenues lors de la pré-formation pour prendre en charge les services de rappel et de tri en aval. Notre processus de pré-formation se déroule en deux étapes plutôt qu'une formation de bout en bout. Même si la formation de bout en bout peut être meilleure en théorie, elle nécessite également des exigences machine et des coûts plus élevés. Par conséquent, nous avons choisi la solution de pré-formation, qui est également due à des considérations de coût.
x représente les fonctionnalités originales de la chanson, y compris l'audio de la chanson, les fonctionnalités multimodales du texte et les fonctionnalités de balise telles que la langue. et genre. Ces caractéristiques sont regroupées et soumises à deux transformations aléatoires différentes F’a et F’’a pour obtenir x’ et x’’. f est l'encodeur, qui est également la structure de base du modèle. g est ajouté à une tête après la sortie de l'encodeur et n'est utilisé que pour la partie d'apprentissage contrastif
Q3 : Les couches d'intégration et le DNN des deux tours améliorées. lors d'une formation d'apprentissage contrasté, les deux sont-ils partagés ? Pourquoi l'apprentissage contrastif est-il efficace pour le démarrage à froid du contenu ? S'agit-il d'un échantillonnage spécifiquement négatif pour le contenu non démarré à froid ?
A3 : Le modèle n'a toujours qu'un seul encodeur, qui est une tour, donc il n'y a pas de problème de partage des paramètres
Quant à savoir pourquoi c'est utile pour les articles impopulaires, je le comprends de cette façon, il n'y a pas nécessité d'effectuer une charge supplémentaire sur les éléments impopulaires. Échantillonnage et autres travaux. En fait, le simple apprentissage de la représentation intégrée des chansons sur la base d'un apprentissage supervisé peut conduire à des biais, car les données apprises sont un filtrage collaboratif, ce qui entraînera le problème de la préférence des chansons populaires, et le vecteur d'intégration final sera également biaisé. En introduisant un mécanisme d'apprentissage contrastif et la perte d'apprentissage contrastif dans la fonction de perte finale, le biais dans l'apprentissage des données de filtrage collaboratif peut être corrigé. Par conséquent, grâce à l'apprentissage contrastif, la distribution des vecteurs dans l'espace peut être améliorée sans nécessiter de traitement supplémentaire d'éléments impopulaires
Q4 : Existe-t-il une modélisation multi-objectifs à la frontière d'intérêt ? Cela n’a l’air de rien. Pouvez-vous introduire les deux quantités ⍺ et p ?
A4 : La modélisation DSSM multimodale contient une ItemTower et une UserTower, puis sur la base de la UserTower, nous modélisons une tour supplémentaire pour les caractéristiques de l'utilisateur, appelée Interest Boundary Tower. Chacune de ces trois tours génère un vecteur. Pendant la formation, nous effectuons le produit interne du vecteur d'élément et du vecteur utilisateur pour obtenir le score d'élément, puis effectuons le produit interne du vecteur utilisateur et du vecteur de limite d'intérêt de l'utilisateur pour représenter le score de limite d'intérêt de l'utilisateur. Le paramètre ⍺ est un paramètre de pondération d'échantillon conventionnel utilisé pour équilibrer la proportion d'échantillons positifs et négatifs contribuant à la perte. p est le score final de l'élément, calculé en soustrayant le score de produit interne du vecteur utilisateur et du vecteur de limite d'intérêt de l'utilisateur du score de produit interne du vecteur d'élément et du vecteur utilisateur, et en calculant le score final via la fonction sigmoïde. Au cours du processus de calcul, les échantillons positifs augmenteront le score de produit interne des éléments et des utilisateurs, et réduiront le score de produit interne des utilisateurs et les limites d'intérêt des utilisateurs, tandis que les échantillons négatifs feront le contraire. Idéalement, le score de produit interne de l'utilisateur et les limites d'intérêt de l'utilisateur peuvent différencier les échantillons positifs et négatifs. Lors de l'étape de recommandation en ligne, nous utilisons la limite d'intérêt comme valeur de référence pour recommander aux utilisateurs les éléments ayant des scores plus élevés, tandis que les éléments ayant des scores inférieurs ne sont pas recommandés. Si un utilisateur n'est intéressé que par les éléments populaires, alors idéalement, le score limite de l'utilisateur, c'est-à-dire le produit interne de son vecteur utilisateur et de son vecteur limite d'intérêt, sera très élevé, voire supérieur à tous les scores des éléments démarrés à froid. , certains éléments de démarrage à froid ne seront pas recommandés à cet utilisateur
Q5 : Quelle est la différence structurelle entre la tour utilisateur (userTower) et la tour de limite d'intérêt ?
A5 : Les entrées des deux sont effectivement les mêmes, et les structures sont similaires, mais les paramètres ne sont pas partagés. La plus grande différence réside uniquement dans le calcul de la fonction de perte. La sortie de la tour utilisateur et la sortie de la tour d'éléments sont calculées en effectuant un calcul de produit interne, et le résultat est le score de l'élément. Le produit scalaire de la sortie de la tour de limite d'intérêt et de la sortie de la tour utilisateur est calculé, et le résultat est le score de limite. Lors de l'entraînement, les deux sont soustraits puis participent au calcul de la fonction de perte binaire. Lors de l'inférence, les tailles des deux sont comparées pour décider s'il faut recommander l'article à l'utilisateur
.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Une brève analyse des méthodes et techniques de mise en œuvre de systèmes de recommandation utilisant Golang
- Comment le langage Go implémente-t-il les systèmes de recherche et de recommandation dans le cloud ?
- Construire un système de recommandation à l'aide de Redis et Python : comment fournir des recommandations personnalisées
- La nouvelle frontière des recommandations personnalisées : l'application du deep learning dans les systèmes de recommandation