
Maison >Périphériques technologiques >IA >Parlons de l'extraction de connaissances. L'avez-vous appris ?
Parlons de l'extraction de connaissances. L'avez-vous appris ?

- PHPzavant
- 2023-11-13 20:13:02791parcourir
1. Introduction
L'extraction de connaissances fait généralement référence à l'extraction d'informations structurées à partir de texte non structuré, telles que des balises et des phrases contenant des informations sémantiques riches. Ceci est largement utilisé dans des scénarios tels que la compréhension du contenu et la compréhension des produits dans l'industrie. En extrayant des balises précieuses à partir d'informations textuelles générées par l'utilisateur, il est appliqué au contenu ou aux produits. L'extraction des connaissances s'accompagne généralement de l'extraction de balises ou d'expressions extraites. La classification est généralement modélisée comme une tâche de reconnaissance d'entité nommée. Une tâche courante de reconnaissance d'entité nommée consiste à identifier les composants d'entité nommée et à classer les composants en noms de lieux, noms de personnes, noms d'organisations, etc., l'extraction de mots de balise liés au domaine identifie et combine les balises ; mots. Divisez en catégories définies par domaine, telles que la série (Air Force One, Sonic 9), la marque (Nike, Li Ning), le type (chaussures, vêtements, numérique), le style (style INS, style rétro, style nordique), etc.
Pour faciliter la description, les balises ou expressions riches en informations seront collectivement appelées mots-étiquettes ci-dessous
2. Classification de l'extraction de connaissances
Cet article présente la méthode classique d'extraction de connaissances sous deux perspectives : l'exploration de mots-étiquettes et classification des mots-clés. Les méthodes d'exploration de mots-clés sont divisées en méthodes non supervisées, méthodes supervisées et méthodes de supervision à distance, comme le montre la figure 1. L'exploration de mots-étiquettes sélectionne les mots-étiquettes les plus performants en deux étapes : l'exploration des mots candidats et la classification des mots-étiquettes modélisent généralement conjointement l'extraction et la classification des mots-étiquettes, et les transforment en une tâche d'annotation de séquence pour la reconnaissance d'entités nommées.
Figure 1 Classification des méthodes d'extraction de connaissances 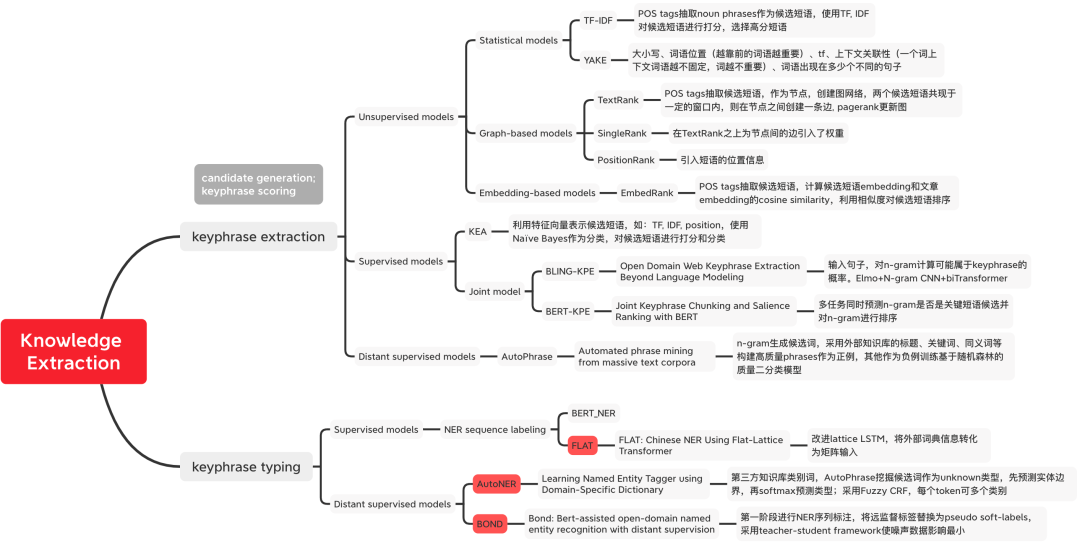 3. Tag word mining
3. Tag word mining
Méthode non supervisée
Méthode basée sur les statistiques
Segmentez d'abord le document ou segmentez les mots N- combinaisons de grammes comme mots candidats, puis notez les mots candidats en fonction de caractéristiques statistiques.
- Contenu réécrit : Méthode de calcul : tfidf(t, d, D) = tf(t, d) * idf(t, D), où tf(t, d) = log(1 + freq(t) , d )), freq(t,d) représente le nombre de fois où le mot candidat t apparaît dans le document actuel d, idf(t,D) = log(N/count(d∈D:t∈D)) représente le mot candidat t Dans combien de documents apparaît-il ? Il est utilisé pour indiquer la rareté d'un mot. Si un mot n'apparaît que dans un seul document, cela signifie que le mot est rare et contient des informations plus riches. Dans des scénarios commerciaux spécifiques, des outils externes peuvent être utilisés. pour analyser les mots candidats. Effectuez d’abord une série de sélections, par exemple en utilisant des marqueurs de parties du discours pour filtrer les noms.
Modèle basé sur un graphique
TextRank[2] : effectuez d'abord une segmentation de mots et un marquage de partie de discours sur le texte, puis filtrez les mots vides, ne laissant que les mots avec une partie de discours spécifiée. pour construire un graphique. Chaque nœud est un mot et les bords représentent des relations entre les mots, qui sont construites en définissant la cooccurrence de mots dans une fenêtre mobile d'une taille prédéterminée. Utilisez le PageRank pour mettre à jour le poids des nœuds jusqu'à convergence ; triez les poids des nœuds dans l'ordre inverse pour obtenir les k mots les plus importants comme mots-clés candidats ; marquez les mots candidats dans le texte original, et s'ils forment des phrases adjacentes, combinez-les en plusieurs mots-clés. phrases pour phrases.Méthode basée sur la représentation Modèle basé sur l'intégration
La méthode basée sur la représentation classe les mots candidats en calculant la similarité vectorielle entre les mots candidats et les documents.
EmbedRank[3] : sélectionnez les mots candidats grâce à la segmentation des mots et au marquage de parties du discours, utilisez Doc2Vec et Sent2vec pré-entraînés comme représentations vectorielles des mots et documents candidats, et calculez la similarité cosinus pour classer les mots candidats. De même, KeyBERT[4] remplace la représentation vectorielle d'EmbedRank par BERT.- Méthode de supervision
- Première sélection des mots candidats, puis utilisation de la classification des mots-clés : le modèle classique KEA[5] utilise Naive Bayes comme classificateur pour noter les mots candidats N-gram à l'aide de quatre fonctionnalités conçues.
- Formation conjointe sur la sélection des mots candidats et la reconnaissance des mots-clés : BLING-KPE[6] prend la phrase originale en entrée, utilise CNN et Transformer pour encoder la phrase N-gramme de la phrase et calcule la probabilité que la phrase soit un mot-étiquette, et s'il s'agit d'un mot d'étiquette. Les mots d'étiquette sont étiquetés manuellement. BERT-KPE[7] Basé sur l'idée de BLING-KPE, ELMO est remplacé par BERT pour mieux représenter le vecteur de la phrase.
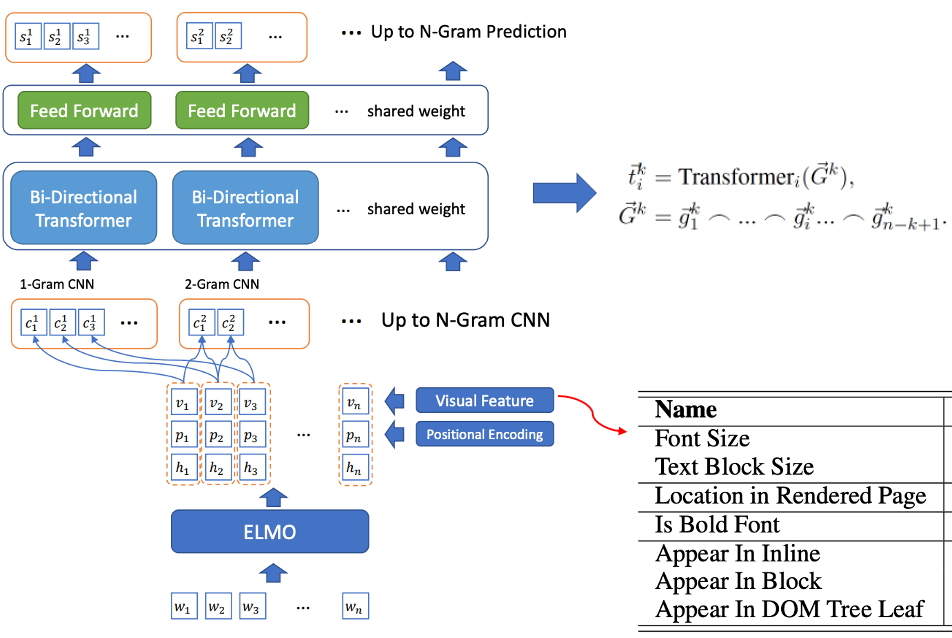 Figure 2 Structure du modèle BLING-KPE
Figure 2 Structure du modèle BLING-KPE
Méthode de supervision à distance
AutoPhrase
Dans cet article, nous définissons les expressions de haute qualité comme des mots ayant une sémantique complète, lorsque les quatre conditions suivantes sont remplies en même temps
- Popularité : la fréquence d'apparition dans le document est suffisamment élevée
- Concordance : La collocation des jetons apparaît La fréquence de est beaucoup plus élevée que les autres collocations après remplacement, c'est-à-dire la fréquence de co-occurrence
- Caractère informatif : informatif et clairement indicatif, comme « c'est » est un exemple négatif sans information ; : phrase et ses sous-caractères Les phrases doivent être complètes.
- Le processus d'extraction de balises AutoPhrase est illustré à la figure 3. Premièrement, nous utilisons le marquage de parties du discours pour filtrer les mots N-gram à haute fréquence comme candidats. Ensuite, nous classons les mots candidats grâce à une supervision à distance. Enfin, nous utilisons les quatre conditions ci-dessus pour filtrer les phrases de haute qualité (ré-estimation de la qualité des phrases)
Figure 3 Processus d'exploration de balises AutoPhrase 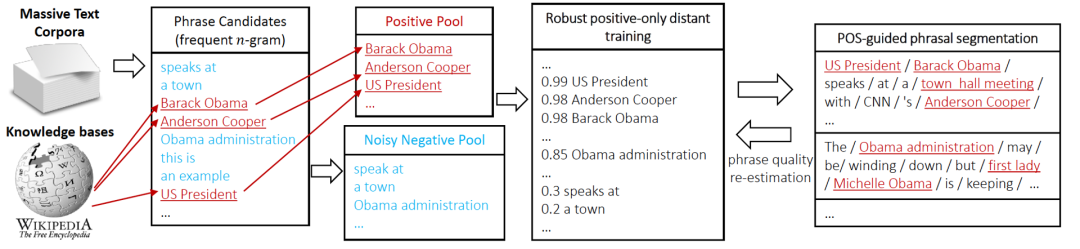 Obtenez des phrases de haute qualité à partir de la base de connaissances externe en tant que Positive Pool, et autres phrases comme pool négatif Par exemple, selon les statistiques expérimentales de l'article, il y a 10 % d'expressions de haute qualité dans le pool d'exemples négatifs car elles ne sont pas classées en exemples négatifs dans la base de connaissances. Par conséquent, l'article utilise un. classificateur d'ensemble forestier aléatoire comme le montre la figure 4 pour réduire les paires de bruit L'impact de la classification. Dans les applications industrielles, la formation des classificateurs peut également utiliser la méthode de deux classifications des tâches de relation inter-phrases basée sur le modèle de pré-formation BERT [13].
Obtenez des phrases de haute qualité à partir de la base de connaissances externe en tant que Positive Pool, et autres phrases comme pool négatif Par exemple, selon les statistiques expérimentales de l'article, il y a 10 % d'expressions de haute qualité dans le pool d'exemples négatifs car elles ne sont pas classées en exemples négatifs dans la base de connaissances. Par conséquent, l'article utilise un. classificateur d'ensemble forestier aléatoire comme le montre la figure 4 pour réduire les paires de bruit L'impact de la classification. Dans les applications industrielles, la formation des classificateurs peut également utiliser la méthode de deux classifications des tâches de relation inter-phrases basée sur le modèle de pré-formation BERT [13].
Figure 4 Méthode de classification des mots-clés AutoPhrase 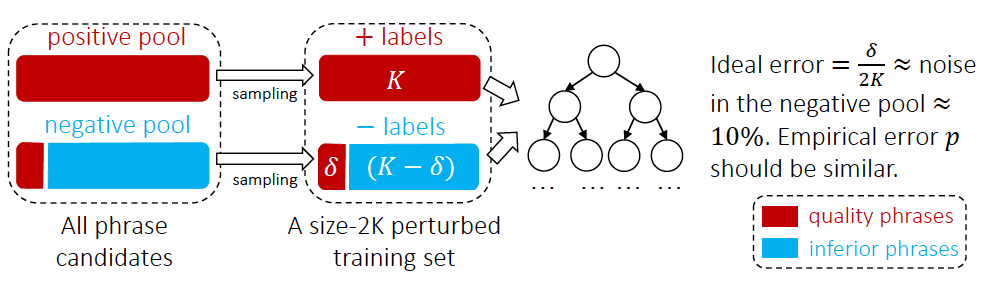 IV. Classification des mots-clés
IV. Classification des mots-clés
Méthode supervisée
Modèle d'annotation de séquence NER
Lattice LSTM[8] est le premier ouvrage à introduire des informations de vocabulaire pour les tâches chinoises NER. Lattice est un graphe acyclique orienté Les caractères de début et de fin du vocabulaire déterminent la position de la grille lors de la correspondance d'une phrase grâce aux informations de vocabulaire (dictionnaire). , une structure de type treillis peut être obtenue, comme le montre la figure 5 (a). La structure Lattice LSTM fusionne les informations de vocabulaire dans le LSTM natif, comme indiqué en 5(b). Pour le caractère actuel, toutes les informations du dictionnaire externe se terminant par ce caractère sont fusionnées. Par exemple, « magasin » fusionne « personnes et pharmacies » et. Informations "Pharmacie". Pour chaque caractère, Lattice LSTM utilise un mécanisme d'attention pour fusionner un nombre variable d'unités de mots. Bien que Lattice-LSTM améliore efficacement les performances des tâches NER, la structure RNN ne peut pas capturer les dépendances longue distance, et l'introduction d'informations lexicales entraîne des pertes. Dans le même temps, la structure dynamique Lattice ne peut pas réaliser pleinement le parallélisme GPU. a effectivement amélioré ces deux questions. Comme le montre la figure 5 (c), le modèle Flat capture les dépendances longue distance via la structure Transformer et conçoit un codage de position pour intégrer la structure Lattice. Après avoir fusionné les mots correspondant aux caractères en phrases, chaque caractère et mot est construit en deux. L'encodage de la position de la tête et l'encodage de la position de la queue aplatissent la structure de treillis d'un graphe acyclique dirigé à une structure de transformateur à treillis plat plate.
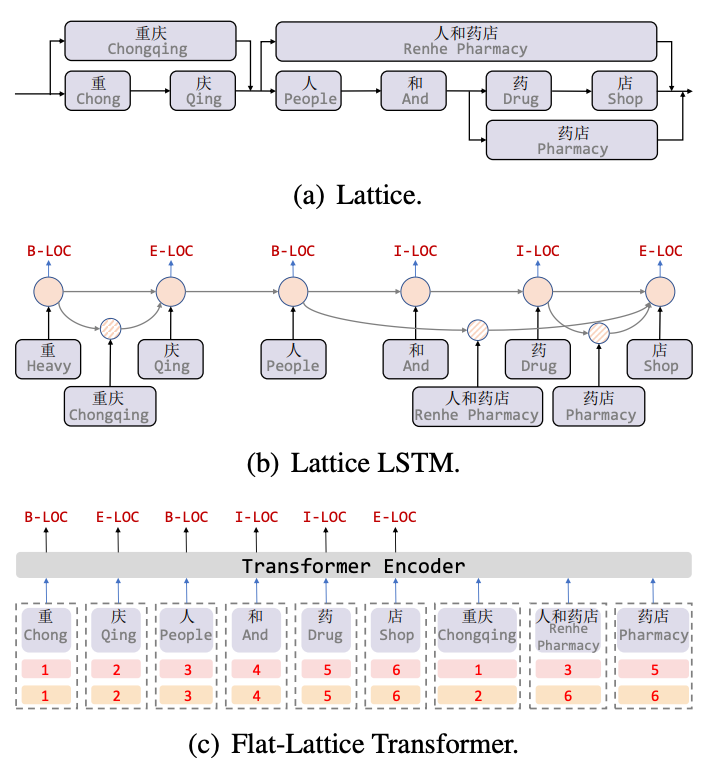 Figure 5 Modèle NER introduisant des informations de vocabulaire
Figure 5 Modèle NER introduisant des informations de vocabulaire
Méthode supervisée à distance
AutoNER
Afin de résoudre le problème du bruit en supervision à distance, nous utilisons le schéma d'identification des limites d'entité de Tie or Break pour remplacer la méthode d'étiquetage BIOE. Parmi eux, Tie signifie que le mot actuel et le mot précédent appartiennent à la même entité, et Break signifie que le mot actuel et le mot précédent ne sont plus dans la même entité. Dans la phase de classification des entités, Fuzzy CRF est utilisé pour traiter. avec les multiples caractéristiques d'une entité. Différents types de situations
Figure 6 Diagramme de structure du modèle AutoNER 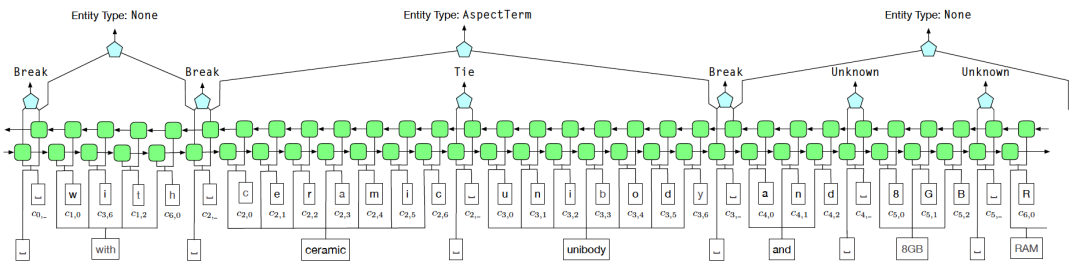
BOND
BOND [12] est un modèle de reconnaissance d'entité en deux étapes basé sur l'apprentissage supervisé à distance. Dans la première étape, des étiquettes longue distance sont utilisées pour adapter le modèle linguistique pré-entraîné à la tâche NER ; dans la deuxième étape, le modèle Étudiant et le modèle Enseignant sont d'abord initialisés avec le modèle formé à l'étape 1, puis le pseudo -les étiquettes générées par le modèle Enseignant sont utilisées pour associer le modèle Étudiant. Mener une formation pour minimiser l'impact des problèmes de bruit causés par la supervision à distance.
Images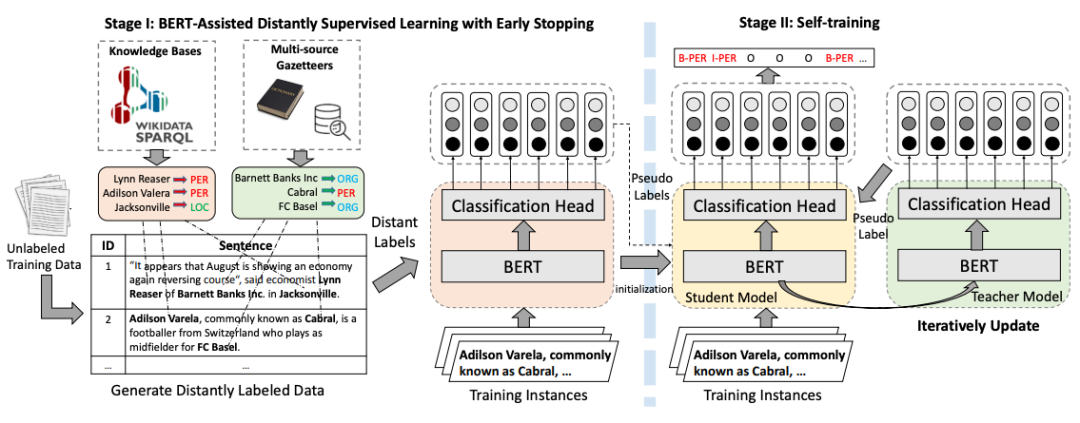 Le contenu qui doit être réécrit est : Figure 7 Organigramme de la formation BOND
Le contenu qui doit être réécrit est : Figure 7 Organigramme de la formation BOND
V Résumé
Cet article présente les méthodes classiques d'extraction de connaissances sous les deux perspectives de l'exploration de mots-clés et des mots-clés. classification, y compris les méthodes classiques non supervisées et supervisées à distance TF-IDF et TextRank qui s'appuient sur des données annotées manuellement, AutoPhrase, AutoNER, etc., qui sont largement utilisées dans l'industrie, peuvent fournir des références pour la compréhension du contenu de l'industrie, la construction de dictionnaires et NER pour la compréhension des requêtes.
【1】Campos R, Mangaravite V, Pasquali A, et al Yake ! Extracteur automatique de mots-clés indépendant de la collection[C]//Advances in Information Retrieval : 40th European Conference on IR Research, ECIR. 2018, Grenoble, France, 26-29 mars 2018, Actes 40. Springer International Publishing, 2018 : 806-810 https://github.com/LIAAD/yake
.【2】Mihalcea R, Tarau P. Textrank : Mettre de l'ordre dans le texte[C]//Actes de la conférence de 2004 sur les méthodes empiriques dans le traitement du langage naturel.
【3】Bennani-Smires K, Musat C, Hossmann A, et al. Extraction simple de phrases clés non supervisées à l'aide d'incorporations de phrases [J]. 】Witten I H, Paynter G W, Frank E, et al. KEA : Extraction automatique pratique de phrases clés[C]//Actes de la quatrième conférence ACM sur les bibliothèques numériques 1999 : 254-255.
Contenu de la traduction :【6】Xiong L. , Hu C, Xiong C et al. Extraction de mots clés Web de domaine ouvert au-delà des modèles linguistiques [J]. Préimpression arXiv arXiv : 1911.02671, 2019
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z. et Bao, J. (2020). Classement conjoint des phrases clés et de la saillance avec BERT. Préimpression arXiv arXiv:2004.13639.
Le contenu qui doit être réécrit est : [8] Zhang Y, Yang J. Reconnaissance d'entités nommées chinoises à l'aide du treillis LSTM[C]. ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT : NER chinois utilisant un transformateur à réseau plat [C].
【10】Shang J, Liu J, Jiang M, et al. Exploration automatisée de phrases à partir de corpus de textes massifs [J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10) : 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. . Apprentissage du marqueur d'entités nommées à l'aide d'un dictionnaire spécifique au domaine[C].
【12】Liang C, Yu Y, Jiang H, et al. C] //Actes de la 26e conférence internationale ACM SIGKDD sur la découverte des connaissances et l'exploration de données 2020 : 1054-1064.
【13】Exploration et pratique de la technologie NER dans Meituan Search, https://zhuanlan.zhihu.com/. p/163256192
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!