
Maison >Périphériques technologiques >IA >Laissez le modèle d'IA devenir un acteur cinq étoiles de GTA, l'agent intelligent programmable basé sur la vision Octopus est là
Laissez le modèle d'IA devenir un acteur cinq étoiles de GTA, l'agent intelligent programmable basé sur la vision Octopus est là

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-11 08:34:461400parcourir
Les jeux vidéo sont devenus une scène de simulation du monde réel, montrant des possibilités infinies. Prenons l'exemple de « Grand Theft Auto » (GTA). Dans le jeu, les joueurs peuvent découvrir la vie colorée de la ville virtuelle de Los Santos à la première personne. Cependant, puisque les joueurs humains peuvent profiter de jouer à Los Santos et accomplir des tâches, pouvons-nous également avoir un modèle visuel d'IA pour contrôler les personnages dans GTA et devenir le « joueur » qui exécute les tâches ? Les acteurs de l'IA dans GTA peuvent-ils jouer le rôle d'un bon citoyen cinq étoiles qui respecte le code de la route, aide la police à arrêter les criminels, ou même être un passant utile, aidant les sans-abri à trouver un logement convenable ?
Les modèles de langage visuel (VLM) actuels ont fait des progrès substantiels dans la perception et le raisonnement multimodaux, mais ils sont généralement basés sur des tâches plus simples de réponse visuelle aux questions (VQA) ou d'annotation visuelle (Légende). Cependant, ces paramètres de tâches ne peuvent évidemment pas permettre à VLM d’effectuer réellement des tâches dans le monde réel. Parce que les tâches réelles nécessitent non seulement la compréhension des informations visuelles, mais nécessitent également que le modèle ait la capacité de planifier le raisonnement et de fournir des commentaires basés sur des informations environnementales mises à jour en temps réel. Dans le même temps, le plan généré doit également être capable de manipuler les entités de l'environnement pour accomplir la tâche de manière réaliste
Bien que les modèles de langage (LLM) actuellement existants puissent effectuer une planification de tâches sur la base des informations fournies, ils ne peuvent pas comprendre les entrées visuelles, ce qui limite considérablement le champ d'application des modèles de langage lors de l'exécution de tâches spécifiques du monde réel, en particulier pour certaines tâches d'intelligence incarnée, est que la saisie basée sur du texte est souvent trop complexe ou difficile à élaborer, ce qui rend le modèle de langage incapable d'extraire efficacement des informations. de là pour terminer la tâche. À l'heure actuelle, les modèles de langage ont été explorés dans la génération de programmes, mais l'exploration de la génération de codes structurés, exécutables et robustes basés sur une entrée visuelle n'est pas encore approfondie. Afin de résoudre le problème de la façon de créer de grands modèles d'intelligence incarnée, Il est nécessaire de créer la capacité de Un système de connaissance autonome et situationnel qui planifie et exécute avec précision les commandes, ont proposé des chercheurs de l'Université technologique de Nanyang à Singapour, de l'Université Tsinghua, etc., proposés par Octopus. Octopus est un agent programmable basé sur la vision qui vise à apprendre grâce à une entrée visuelle, à comprendre le monde réel et à effectuer diverses tâches pratiques en générant du code exécutable. En s'entraînant sur de grandes quantités de paires de données d'entrée visuelle et de code exécutable, Octopus a appris à contrôler les personnages de jeux vidéo pour accomplir des tâches de jeu ou accomplir des activités ménagères complexes.

- Lien papier : https://arxiv.org/abs/2310.08588
- Page Web du projet : https://choiszt.github.io/Octopus/
- Lien du code source ouvert : https : //github.com/dongyh20/Octopus
Afin de former un modèle de langage visuel capable d'accomplir des tâches d'intelligence incarnée, les chercheurs ont également développé OctoVerse, qui contient deux systèmes de simulation pour fournir une formation pour les données et l'environnement de test d'Octopus. Ces deux environnements de simulation fournissent des scénarios de formation et de test disponibles pour l’intelligence incorporée de VLM et imposent des exigences plus élevées aux capacités de raisonnement et de planification des tâches du modèle. Les détails sont les suivants :
1. OctoGibson : Développé sur la base d'OmniGibson développé par l'Université de Stanford, il comprend un total de 476 activités ménagères cohérentes avec la vie réelle. L'environnement de simulation complet comprend 16 catégories différentes de scénarios domestiques, couvrant 155 instances d'environnements domestiques réels. Le modèle peut manipuler un grand nombre d'objets interactifs présents pour accomplir la tâche finale.
2. OctoGTA : Développé sur la base du jeu "Grand Theft Auto" (GTA), un total de 20 tâches ont été construites et généralisées en cinq scénarios différents. Le joueur est placé à un emplacement fixe via un programme prédéfini, et les éléments et PNJ nécessaires sont fournis pour accomplir la tâche afin de garantir que la tâche se déroule sans problème.
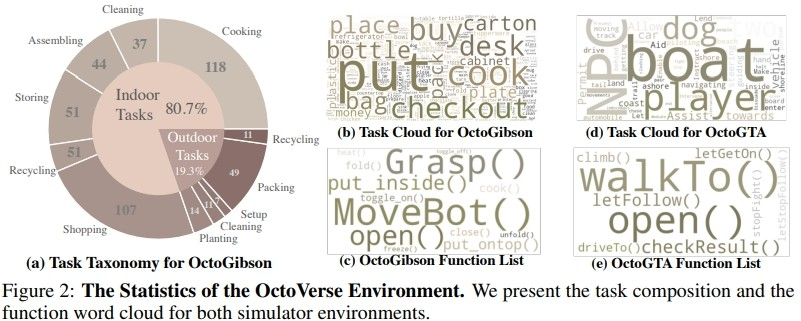
La figure ci-dessous montre la classification des tâches d'OctoGibson et quelques résultats statistiques d'OctoGibson et OctoGTA.
 Afin de collecter efficacement les données d'entraînement dans les deux environnements de simulation construits, les chercheurs ont mis en place un système complet de collecte de données. En introduisant GPT-4 comme exécuteur de tâches, les chercheurs ont utilisé des fonctions pré-implémentées pour convertir les entrées visuelles obtenues à partir de l'environnement de simulation en informations textuelles et les ont fournies à GPT-4. Une fois que GPT-4 a renvoyé le plan de tâche et le code exécutable de l'étape en cours, il exécute le code dans l'environnement de simulation et détermine si la tâche de l'étape en cours est terminée. En cas de succès, continuez à collecter des informations visuelles pour l'étape suivante ; en cas d'échec, revenez à la position de départ de l'étape précédente et collectez à nouveau les données
Afin de collecter efficacement les données d'entraînement dans les deux environnements de simulation construits, les chercheurs ont mis en place un système complet de collecte de données. En introduisant GPT-4 comme exécuteur de tâches, les chercheurs ont utilisé des fonctions pré-implémentées pour convertir les entrées visuelles obtenues à partir de l'environnement de simulation en informations textuelles et les ont fournies à GPT-4. Une fois que GPT-4 a renvoyé le plan de tâche et le code exécutable de l'étape en cours, il exécute le code dans l'environnement de simulation et détermine si la tâche de l'étape en cours est terminée. En cas de succès, continuez à collecter des informations visuelles pour l'étape suivante ; en cas d'échec, revenez à la position de départ de l'étape précédente et collectez à nouveau les données
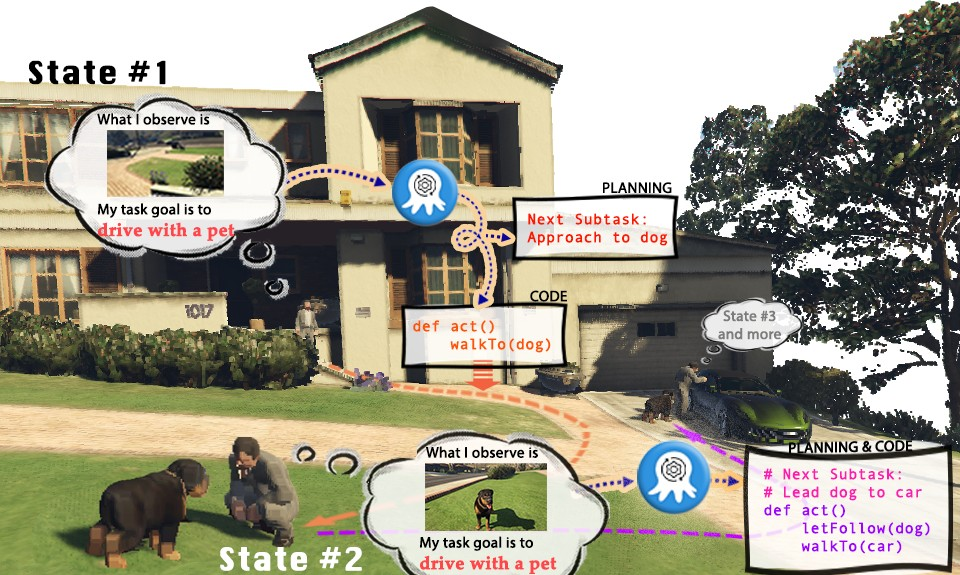
La figure ci-dessus prend comme exemple la tâche Cook a Bacon dans l'environnement OctoGibson pour montrer le processus complet de collecte de données. Il convient de souligner que lors du processus de collecte de données, les chercheurs ont non seulement enregistré les informations visuelles lors de l'exécution de la tâche, le code exécutable renvoyé par GPT-4, etc., mais ont également enregistré le succès de chaque sous-tâche, ce qui sera être utilisé comme suivi. L'apprentissage par renforcement est introduit pour jeter les bases d'un VLM plus efficace. Bien que GPT-4 soit puissant, il n’est pas impeccable. Les erreurs peuvent se manifester de diverses manières, notamment des erreurs de syntaxe et des problèmes physiques dans le simulateur. Par exemple, comme le montre la figure 3, entre les états n°5 et n°6, l'action « mettre du bacon sur la poêle » a échoué car la distance entre le bacon tenu par l'agent et la poêle était trop grande. De tels revers réinitialisent la tâche à son état précédent. Si une tâche n'est pas terminée après 10 étapes, elle est considérée comme ayant échoué, nous mettrons fin à la tâche en raison de problèmes budgétaires et les paires de données de toutes les sous-tâches de cette tâche seront considérées comme ayant échoué.
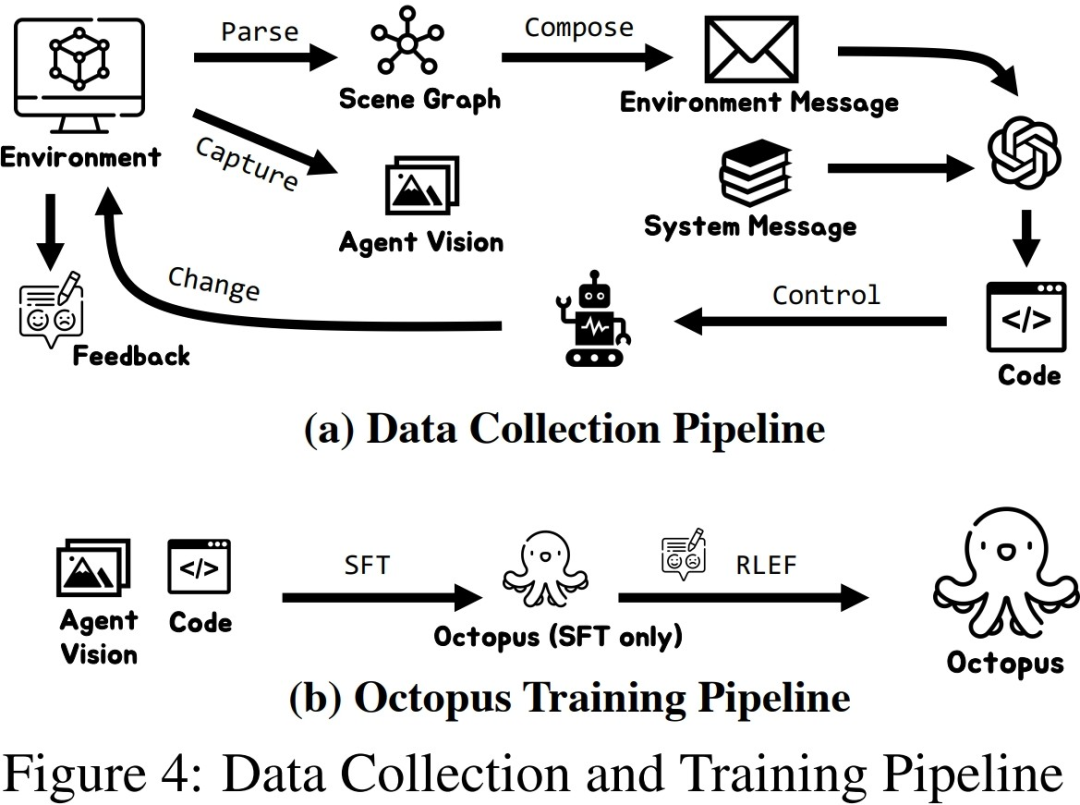
Après avoir collecté une certaine échelle de données d'entraînement, les chercheurs ont utilisé ces données pour entraîner un modèle de langage visuel intelligent Octopus. La figure ci-dessous montre le processus complet de collecte de données et de formation. Dans un premier temps, en utilisant les données collectées pour un réglage fin supervisé, les chercheurs ont construit un modèle VLM capable de recevoir des informations visuelles en entrée et en sortie dans un format fixe. À ce stade, le modèle est capable de mapper les informations d’entrée visuelles dans les plans de mission et le code exécutable. Dans la deuxième étape, les chercheurs ont introduit l'apprentissage par renforcement RLEF
utilisant la rétroaction environnementale et ont utilisé le succès des sous-tâches précédemment collectées comme signaux de récompense pour améliorer encore les capacités de planification des tâches de VLM afin d'augmenter le taux de réussite de la tâche globale
Expérimental résultats
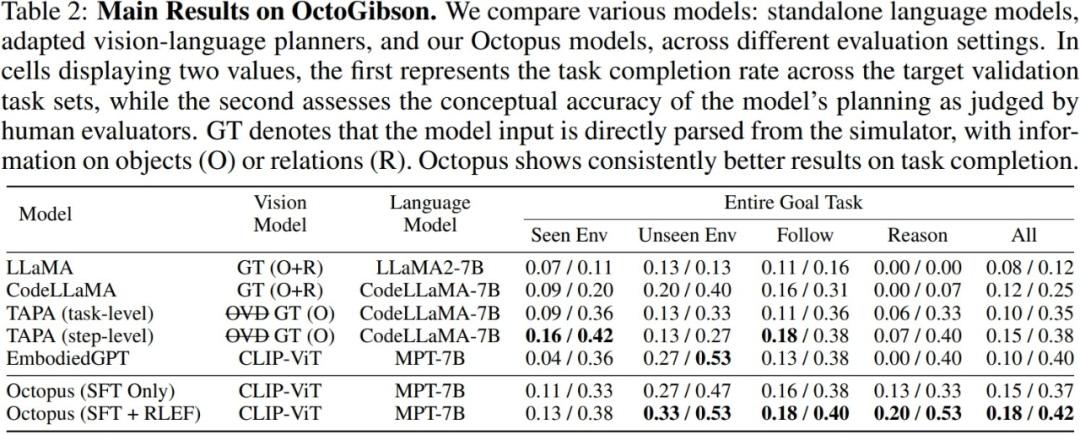
Les chercheurs ont testé les principaux VLM et LLM actuels dans l'environnement OctoGibson construit. Le tableau suivant montre les principaux résultats expérimentaux. Pour différents modèles de test, Vision Model répertorie les modèles visuels utilisés par différents modèles. Pour LLM, le chercheur traite les informations visuelles en texte en entrée de LLM. Parmi eux, O représente la fourniture d'informations sur les objets interactifs de la scène, R représente la fourniture d'informations sur les relations relatives des objets dans la scène et GT représente l'utilisation d'informations réelles et précises sans introduire de modèles visuels supplémentaires pour la détection.
Pour toutes les tâches de test, les chercheurs ont rapporté la puissance complète d'intégration des tests et l'ont divisée en quatre catégories, en enregistrant l'achèvement de nouvelles tâches dans des scénarios qui existent dans l'ensemble de formation et l'achèvement de nouvelles tâches dans des scénarios qui n'existent pas. existent dans l'ensemble de formation. Capacité de généralisation à de nouvelles tâches, ainsi qu'à des tâches simples suivantes et à des tâches de raisonnement complexes. Pour chaque catégorie de statistiques, les chercheurs ont rapporté deux indicateurs d'évaluation, le premier étant le taux d'achèvement des tâches pour mesurer le taux de réussite du modèle dans l'accomplissement des tâches d'intelligence incarnée ; le second est la précision de la planification des tâches, qui est utilisée pour mesurer la performance ; taux de réussite du modèle dans l'accomplissement des tâches d'intelligence incorporée. Reflète la capacité du modèle à effectuer la planification des tâches.
De plus, les chercheurs ont également démontré des exemples de réponses de différents modèles aux données visuelles collectées dans l'environnement de simulation OctoGibson. La figure ci-dessous montre la réponse après avoir utilisé trois modèles : TAPA+CodeLLaMA, Octopus et GPT-4V pour générer une entrée visuelle dans OctoGibson. On peut voir que par rapport au modèle Octopus et TAPA+CodeLLaMA qui ne subissent qu'un réglage fin supervisé, la planification des tâches du modèle Octopus formé par RLEF est plus raisonnable. Même l'ordre de mission plus vague « trouver une grande bouteille » fournit un plan plus complet. Ces performances illustrent en outre l'efficacité de la stratégie de formation RLEF pour améliorer les capacités de planification des tâches et de raisonnement du modèle. Dans l'ensemble, les capacités réelles d'exécution et de planification des tâches des modèles existants dans l'environnement de simulation sont toujours les mêmes. pour amélioration. Les chercheurs ont résumé quelques conclusions clés :
 1.CodeLLaMA peut améliorer la capacité de génération de code du modèle, mais il ne peut pas améliorer la capacité de planification des tâches.
1.CodeLLaMA peut améliorer la capacité de génération de code du modèle, mais il ne peut pas améliorer la capacité de planification des tâches.
Face à une grande quantité de saisie d'informations textuelles , le traitement du LLM devient relativement difficile
Au cours du processus de test proprement dit, les chercheurs ont comparé les résultats expérimentaux de TAPA et CodeLLaMA et sont arrivés à la conclusion qu'il est difficile pour le modèle de langage de bien gérer la saisie de textes longs. Les chercheurs suivent la méthode TAPA et utilisent des informations sur les objets réels pour la planification des tâches, tandis que CodeLLaMA utilise des objets et les relations de position relative entre les objets afin de fournir des informations plus complètes. Cependant, au cours de l'expérience, les chercheurs ont découvert qu'en raison de la grande quantité d'informations redondantes dans l'environnement, lorsque l'environnement est plus complexe, la saisie de texte augmente considérablement et il est difficile pour LLM d'extraire des indices précieux de la grande quantité d'informations. informations redondantes, réduisant ainsi le taux de réussite de la mission. Cela reflète également les limites du LLM, c'est-à-dire que si des informations textuelles sont utilisées pour représenter des scènes complexes, une grande quantité d'informations d'entrée redondantes et sans valeur sera générée.
3.Octopus montre une bonne capacité de généralisation des tâches.
Octopus a une forte capacité de généralisation des tâches, qui peut être connue grâce aux résultats expérimentaux. Dans les nouveaux scénarios qui n'apparaissaient pas dans l'ensemble de formation, Octopus a surpassé les modèles existants en termes de taux de réussite de l'achèvement des tâches et de taux de réussite de la planification des tâches. Cela montre également que le modèle de langage visuel présente des avantages inhérents dans la même catégorie de tâches et que ses performances de généralisation sont meilleures que celles du LLM
4.RLEF traditionnel peut améliorer la capacité de planification des tâches du modèle.
Les chercheurs proposent une comparaison des performances de deux modèles dans les résultats expérimentaux : l'un est un modèle qui a subi la première étape de réglage fin supervisé, et l'autre est un modèle qui a été entraîné avec RLEF. Il ressort des résultats qu'après la formation RLEF, le taux de réussite global et la capacité de planification du modèle sont considérablement améliorés sur les tâches qui nécessitent de fortes capacités de raisonnement et de planification de tâches. Par rapport aux stratégies de formation VLM existantes, RLEF est plus efficace. L'exemple de graphique montre que le modèle formé avec RLEF améliore la planification des tâches. Face à des tâches complexes, le modèle peut apprendre à explorer l'environnement. De plus, le modèle est plus conforme aux exigences réelles de l'environnement de simulation en termes de planification des tâches (par exemple, le modèle doit se déplacer vers l'objet pour être interagi avant qu'il puisse commencer à interagir), réduisant ainsi la tâche Risque d'échec de la planification
Discussion
Ce qui doit être réécrit est : Test de fusion
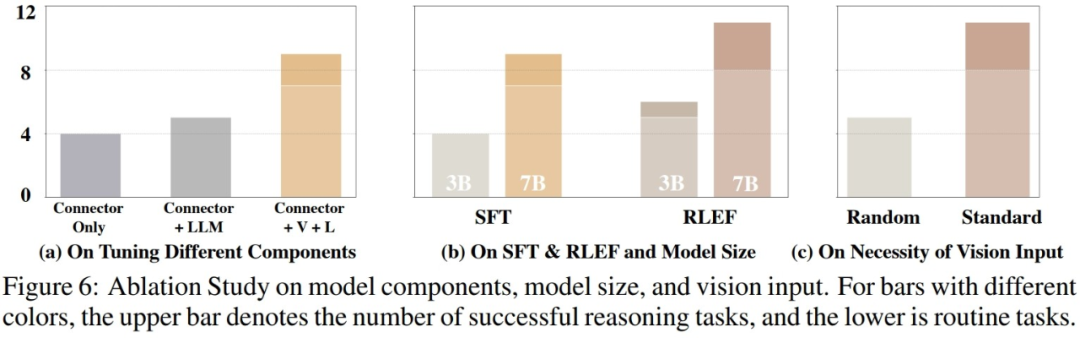
Après avoir évalué les capacités réelles du modèle, les chercheurs ont exploré plus en détail facteurs possibles affectant les performances du modèle. Comme le montre la figure ci-dessous, les chercheurs ont mené des expériences sous trois aspects
Le contenu qui doit être réécrit est : 1. La proportion de paramètres d'entraînement
Les chercheurs ont mené des expériences comparatives et comparé les couches de connexion qui n'ont formé que le modèle visuel et le modèle de langage, les couches de connexion de formation et les modèles de langage, ainsi que les performances du modèle formé complet. Les résultats montrent qu’à mesure que les paramètres d’entraînement augmentent, les performances du modèle s’améliorent progressivement. Cela montre que le nombre de paramètres d'entraînement est crucial pour savoir si le modèle peut accomplir la tâche dans certains scénarios fixes
2. Taille du modèle
Les chercheurs ont comparé le modèle à paramètres 3B plus petit et le modèle de base 7B en deux étapes d'entraînement, différences de performances. Les résultats de la comparaison montrent que lorsque la quantité globale de paramètres du modèle est plus grande, les performances du modèle seront également considérablement améliorées. Dans les recherches futures dans le domaine du VLM, comment sélectionner les paramètres de formation du modèle appropriés pour garantir que le modèle a la capacité d'accomplir les tâches correspondantes tout en garantissant la vitesse d'inférence légère et rapide du modèle sera une question très critique
Besoins à réécrire Le contenu est le suivant : 3. Continuité de l'entrée visuelle. Contenu réécrit : 3. Cohérence des entrées visuelles
Afin d'étudier l'impact des différentes entrées visuelles sur les performances réelles du VLM, les chercheurs ont mené des expériences. Pendant le test, le modèle tourne séquentiellement dans l'environnement de simulation et collecte des images de première vue et deux vues à vol d'oiseau, puis entre ces images visuelles dans le VLM en séquence. Dans l'expérience, lorsque les chercheurs ont perturbé de manière aléatoire l'ordre des images visuelles et les ont ensuite saisies dans VLM, les performances de VLM ont subi une perte plus importante. D'une part, cela illustre l'importance d'informations visuelles complètes et structurées pour VLM. D'autre part, cela reflète également que VLM doit s'appuyer sur la connexion intrinsèque entre les images visuelles pour répondre à une entrée visuelle. cela affectera grandement les performances de VLM
GPT-4
De plus, les chercheurs ont également effectué des tests et des statistiques sur les performances de GPT-4 et GPT-4V dans l'environnement de simulation.
Ce qui doit être réécrit est : 1. GPT-4
Pour GPT-4, pendant le processus de test, le chercheur fournit exactement les mêmes informations textuelles que celles saisies lorsqu'il l'utilise pour collecter des données de formation. Dans la tâche de test, GPT-4 peut effectuer la moitié des tâches, d'une part, cela montre que le VLM existant a encore beaucoup de marge d'amélioration en termes de performances par rapport aux modèles de langage tels que GPT-4 ; , cela montre également que même s'il s'agit d'un modèle de langage très performant tel que GPT-4, face à des tâches d'intelligence incorporée, ses capacités de planification de tâches et d'exécution de tâches doivent encore être améliorées.
Le contenu qui doit être réécrit est : 2. GPT-4V
Depuis que GPT-4V vient de publier une API pouvant être appelée directement, les chercheurs n'ont pas encore eu le temps de l'essayer, mais les chercheurs ont également testé manuellement quelques exemples pour démontrer les performances de GPT-4V. À travers quelques exemples, les chercheurs pensent que GPT-4V possède de fortes capacités de généralisation à échantillon nul pour les tâches dans l'environnement de simulation et peut également générer du code exécutable correspondant basé sur une entrée visuelle, mais il est légèrement inférieur à certaines planifications de tâches. -à l'écoute des données collectées dans l'environnement de simulation.
Résumé
Les chercheurs ont souligné certaines limites des travaux en cours :
Le modèle Octopus actuel ne fonctionne pas bien lors de la gestion de tâches complexes. Face à des tâches complexes, Octopus fait souvent de mauvais plans et s'appuie fortement sur les informations de retour de l'environnement, ce qui rend difficile l'exécution de l'ensemble de la tâche
2 Le modèle Octopus est uniquement formé dans l'environnement de simulation, mais comment le transférer vers. le monde réel Il y aura une série de problèmes rencontrés. Par exemple, dans l'environnement réel, il sera difficile pour le modèle d'obtenir des informations plus précises sur la position relative des objets, et il deviendra plus difficile de construire une compréhension de la scène par les objets.
3. Actuellement, l'entrée visuelle des poulpes est constituée d'images statiques discrètes, ce qui les rend capables de traiter des vidéos en continu devient un défi futur. Les vidéos continues peuvent encore améliorer les performances du modèle dans l'exécution des tâches, mais la manière de traiter et de comprendre efficacement l'entrée visuelle continue deviendra la clé pour améliorer les performances du VLM
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment devenir un excellent ingénieur full-stack en autodidacte ?
- Étapes détaillées pour créer un nouveau projet C++ complet dans VS2015
- Que fait un ingénieur en tests logiciels ?
- Les ingénieurs logiciels sont-ils des programmeurs ?
- Quelle est la différence entre une spécialisation en logiciel informatique et un génie logiciel ?