
Maison >Périphériques technologiques >IA >Le grand modèle prend-il des raccourcis pour « battre les classements » ? Le problème de la pollution des données mérite attention
Le grand modèle prend-il des raccourcis pour « battre les classements » ? Le problème de la pollution des données mérite attention

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-09 14:25:111387parcourir
Au cours de la première année de l’IA générative, le rythme de travail de chacun est devenu beaucoup plus rapide.
Surtout cette année, tout le monde travaille dur pour déployer de grands modèles : Récemment, des géants de la technologie nationaux et étrangers et des start-ups se sont relayés pour lancer de grands modèles. Dès le début de la conférence de presse, ils l'ont tous été. des percées majeures, et chacune a actualisé une liste de référence importante, classée première ou au premier niveau.
Après avoir été enthousiasmés par les progrès rapides de la technologie, de nombreuses personnes trouvent qu'il semble y avoir quelque chose qui ne va pas : pourquoi tout le monde a-t-il sa part dans le classement numéro un ? Quel est ce mécanisme ?
Depuis lors, la question du « list-swiping » a également commencé à attirer l'attention.
Récemment, nous avons remarqué qu'il y a de plus en plus de discussions dans les communautés WeChat Moments et Zhihu sur la question du « swiping the classements » des grands mannequins. En particulier, un article sur Zhihu : Comment évaluez-vous le phénomène souligné par le rapport technique des grands modèles de Tiangong, selon lequel de nombreux grands modèles utilisent des données sur le terrain pour améliorer les classements ? Cela a suscité la discussion de tout le monde.
Lien : https://www.zhihu.com/question/628957425
De nombreux mécanismes de classement de grands modèles ont été exposés
Cette recherche provient de l'Université "Tiangong" de Kunlun Wanwei. L'équipe de recherche a publié un rapport technique sur la plateforme de papier pré-imprimé arXiv à la fin du mois dernier.

Lien papier : https://arxiv.org/abs/2310.19341
L'article lui-même est une introduction à Skywork-13B, une série de grands modèles de langage (LLM) de Tiangong. Les auteurs présentent une méthode de formation en deux étapes utilisant des corpus segmentés, ciblant respectivement la formation générale et la formation approfondie spécifique à un domaine.
Comme d'habitude avec les nouvelles recherches sur les grands modèles, les auteurs ont déclaré que sur les tests de référence populaires, leur modèle non seulement fonctionnait bien, mais atteignait également le niveau de pointe (le meilleur de l'industrie) sur de nombreuses tâches de branche chinoise. . bien).
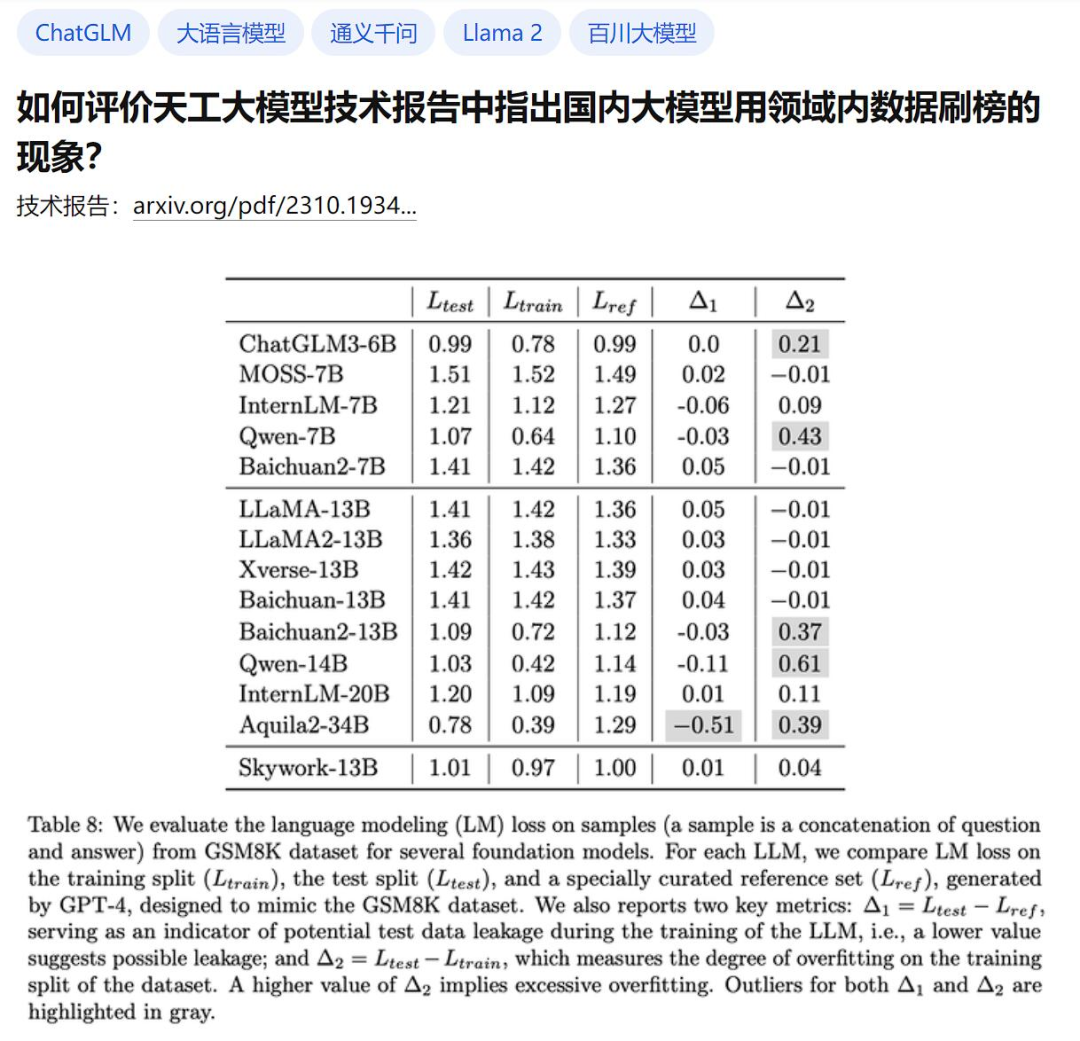
Le point clé est que le rapport a également vérifié les effets réels de nombreux grands modèles et a souligné que certains autres grands modèles nationaux sont soupçonnés d'être opportunistes. Voici le tableau 8 :
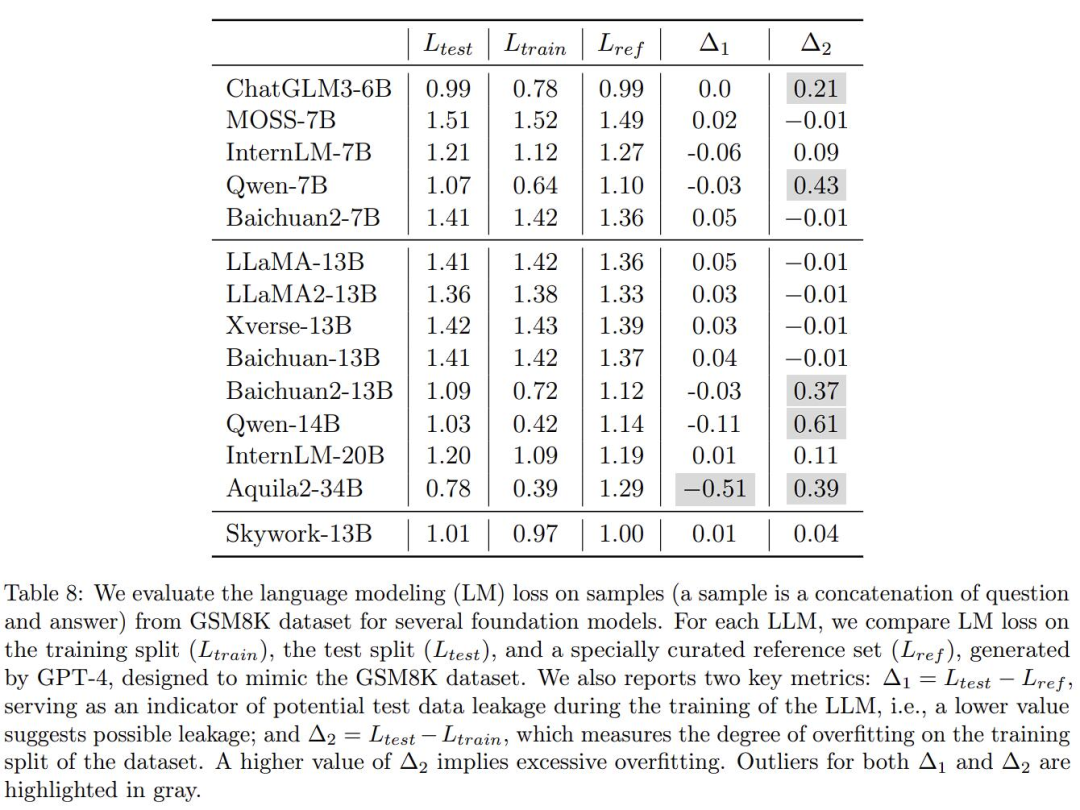
Ici, afin de vérifier le degré de surapprentissage de plusieurs grands modèles courants dans l'industrie sur le test de problème d'application mathématique GSM8K, l'auteur a utilisé GPT-4 pour générer des échantillons GSM8K. avec le même formulaire ont été vérifiés manuellement pour leur exactitude, et ces modèles ont été comparés sur l'ensemble de données généré avec l'ensemble de formation et l'ensemble de test d'origine de GSM8K, et la perte a été calculée. Ensuite, il y a deux métriques :
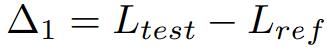
Δ1 sert d'indicateur de fuite potentielle de données de test lors de la formation du modèle, avec des valeurs plus faibles indiquant une fuite possible. Sans formation sur l'ensemble de test, la valeur doit être nulle.
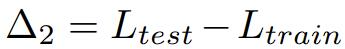
Δ2 mesure le degré de surapprentissage de la répartition d'entraînement de l'ensemble de données. Une valeur Δ2 plus élevée signifie un surapprentissage. S'il n'a pas été entraîné sur l'ensemble d'entraînement, la valeur doit être nulle.
Pour l'expliquer avec des mots simples : si un modèle utilise directement les « vraies questions » et « réponses » du test de référence comme matériel d'apprentissage pendant la formation, et veut les utiliser pour marquer des points, alors ici ce sera anormal.
D'accord, les zones problématiques de Δ1 et Δ2 sont judicieusement mises en évidence en gris ci-dessus.
Les internautes ont commenté que quelqu'un avait finalement révélé le secret de polichinelle de la "pollution des ensembles de données".
Certains internautes ont également déclaré que le niveau d'intelligence des grands modèles dépend toujours de capacités de tir nul, qui ne peuvent pas être atteintes par les tests de référence existants.

Photo : Capture d'écran des commentaires des internautes de Zhihu
Dans l'interaction entre l'auteur et les lecteurs, l'auteur a également déclaré qu'il espérait « permettre à tout le monde d'aborder la question de la triche de manière plus rationnelle. Il y a encore un grand écart entre de nombreux modèles et GPT4 ».
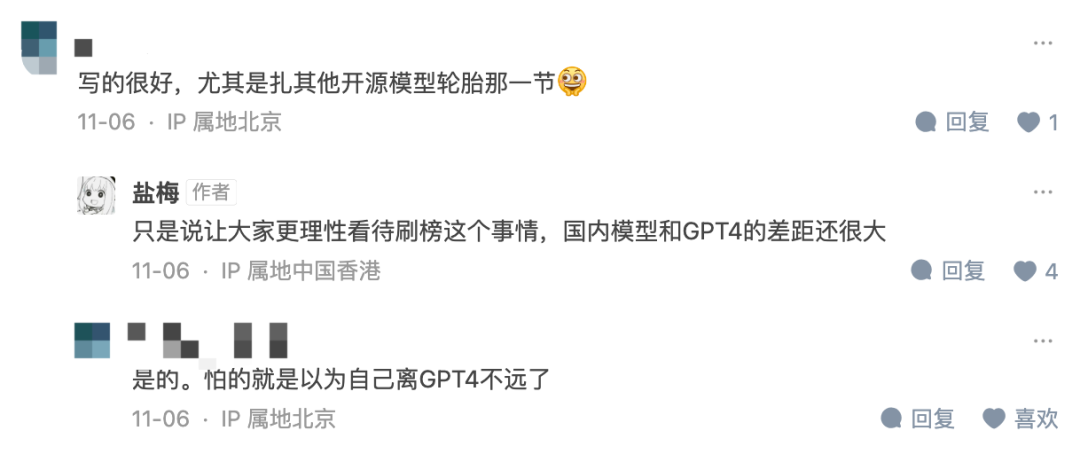
Photo : Capture d'écran de l'article de Zhizhihu https://zhuanlan.zhihu.com/p/664985891
Le problème de la pollution des données mérite attention
En fait, ce n'est pas un phénomène temporaire . Depuis l'introduction de Benchmark, de tels problèmes sont survenus de temps en temps, comme le soulignait le titre d'un article très ironique sur arXiv en septembre de cette année : La pré-formation sur l'ensemble de test est tout ce dont vous avez besoin.

De plus, une étude formelle récente de l'Université Renmin et de l'Université de l'Illinois à Urbana-Champaign a également souligné des problèmes dans l'évaluation des grands modèles. Le titre est très accrocheur « Ne faites pas de votre LLM un tricheur de référence d'évaluation » :

Lien papier : https://arxiv.org/abs/2311.01964
Le journal souligne que Le domaine actuel des grands modèles est celui des grands modèles. Les gens se soucient des classements de référence, mais leur équité et leur fiabilité sont remises en question. Le principal problème est la contamination et la fuite des données, qui peuvent être déclenchées involontairement parce que nous ne connaissons peut-être pas les futurs ensembles de données d'évaluation lors de la préparation du corpus de pré-formation. Par exemple, GPT-3 a révélé que le corpus de pré-formation contenait l'ensemble de données du Children's Book Test, et l'article LLaMA-2 mentionnait l'extraction du contenu contextuel d'une page Web à partir de l'ensemble de données BoolQ.
Les ensembles de données nécessitent beaucoup d'efforts de la part de nombreuses personnes pour collecter, organiser et étiqueter. Si un ensemble de données de haute qualité est suffisamment bon pour être utilisé à des fins d'évaluation, il peut naturellement être utilisé par d'autres pour former de grands modèles.
D'un autre côté, lors de l'évaluation à l'aide de benchmarks existants, les résultats des grands modèles que nous avons évalués ont été principalement obtenus en s'exécutant sur un serveur local ou via des appels API. Au cours de ce processus, tout moyen inapproprié (tel que la contamination des données) susceptible de conduire à des améliorations anormales des performances de l'évaluation n'a pas été rigoureusement examiné.
Ce qui est pire, c'est que la composition détaillée du corpus de formation (comme les sources de données) est souvent considérée comme le « secret » central des grands modèles existants. Cela rend plus difficile l’exploration du problème de la pollution des données.
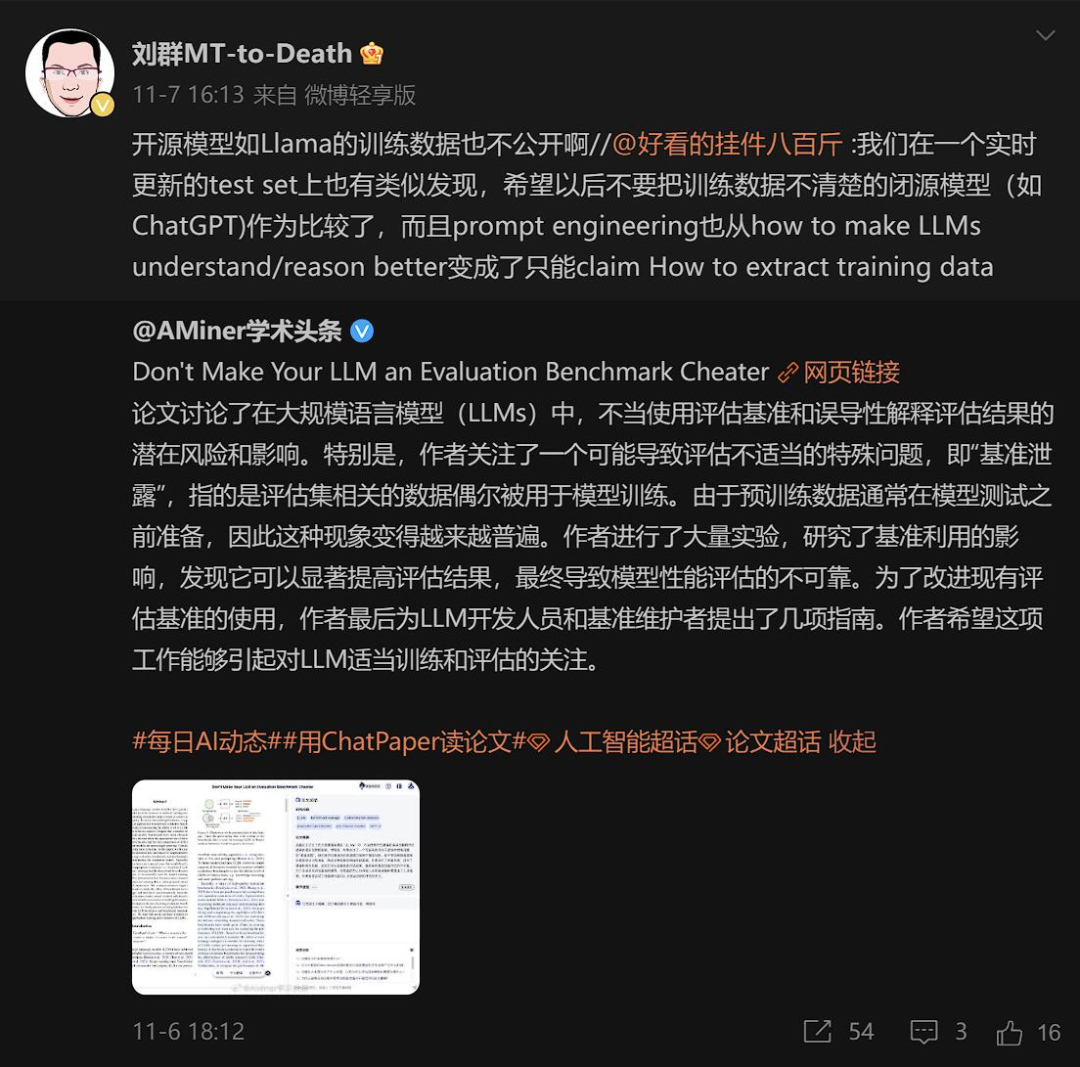
En d'autres termes, la quantité d'excellentes données est limitée, et sur de nombreux ensembles de tests, GPT-4 et Llama-2 ne posent pas nécessairement de problème. Par exemple, GSM8K a été mentionné dans le premier article et GPT-4 a mentionné l'utilisation de son ensemble de formation dans le rapport technique officiel.
Ne dites-vous pas que les données sont très importantes ? Alors, les performances d'un grand modèle qui utilise de « vraies questions » s'amélioreront-elles parce que les données d'entraînement sont meilleures ? La réponse est non.
Des chercheurs ont découvert expérimentalement que les fuites de référence peuvent amener de grands modèles à générer des résultats exagérés : par exemple, un modèle 1,3B peut dépasser un modèle 10 fois plus grand sur certaines tâches. Mais l’effet secondaire est que si nous utilisons uniquement ces données divulguées pour affiner ou entraîner le modèle, les performances de ces grands modèles spécifiques aux tests sur d’autres tâches de test normales peuvent être affectées.
Par conséquent, l'auteur suggère qu'à l'avenir, lorsque les chercheurs évalueront de grands modèles ou étudieront de nouvelles technologies, ils devraient :
- Utilisez davantage de références provenant de différentes sources couvrant les capacités de base (par exemple, la génération de texte) et les capacités avancées (par exemple, le raisonnement complexe) pour évaluer pleinement les capacités du LLM.
- Lors de l'utilisation d'un benchmark d'évaluation, il est important d'effectuer des contrôles de nettoyage des données entre les données de pré-entraînement et toutes les données associées (telles que les ensembles d'entraînement et de test). En outre, les résultats de l’analyse de la pollution pour l’évaluation de référence doivent être communiqués à titre de référence. Si possible, il est recommandé de rendre publique la composition détaillée des données de pré-formation.
- Il est recommandé d'utiliser des invites de test diversifiées pour réduire l'impact de la sensibilité des invites. Il serait également judicieux de mener une analyse de contamination entre les données de base et les corpus de pré-formation existants pour alerter sur tout risque potentiel de contamination. Aux fins d'évaluation, il est recommandé que chaque soumission soit accompagnée d'un rapport spécial d'analyse de la contamination.
Enfin, heureusement, cette question a commencé à attirer l'attention de tous. Qu'il s'agisse de rapports techniques, de recherches papier ou de discussions communautaires, tout le monde a commencé à prêter attention à la question du « swiping » des grands modèles.
Quels sont vos avis et suggestions efficaces à ce sujet ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- comment créer une base de données SQL
- À quelle couche du modèle de référence OSI correspond la couche de transport du modèle de référence TCP/IP ?
- Dans le modèle de référence ISO/OSI, quelles sont les principales fonctions de la couche réseau ?
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Quel est le modèle OSI