
Maison >Périphériques technologiques >IA >iFLYTEK ICDAR 2023 : la reconnaissance d'images et de textes atteint à nouveau une plus grande gloire en remportant quatre championnats
iFLYTEK ICDAR 2023 : la reconnaissance d'images et de textes atteint à nouveau une plus grande gloire en remportant quatre championnats

- WBOYavant
- 2023-11-08 08:17:28682parcourir
ICDAR 2023 (International Conference on Document Analysis and Recognition), en tant que l'une des conférences internationales les plus importantes dans le domaine de l'analyse et de la reconnaissance d'images de documents, a récemment reçu des nouvelles passionnantes :
iFlytek Research Institute de l'USTC et le National Institute of Speech et traitement de l'information linguistique de l'USTC Le Centre de recherche en ingénierie (ci-après dénommé le Centre de recherche) a remporté quatre championnats dans trois compétitions : reconnaissance de formules multilignes, localisation et extraction d'informations documentaires et extraction d'informations textuelles structurées.
MLHMETop : Focus sur "l'écriture multiligne", une autre avancée dans la complexité
MLHME (Multi-line Formula Recognition Competition) teste l'exactitude de la sortie de l'algorithme correspondant à la chaîne LaTex après la saisie d'une image contenant formules mathématiques manuscrites. Il convient de mentionner que, par rapport aux précédents concours de reconnaissance de formules mathématiques, ce concours a fait de « l'écriture multiligne » le principal défi pour la première fois dans l'industrie et, contrairement aux formules précédentes de reconnaissance de l'écriture manuscrite numérisée et en ligne, cette fois-ci. reconnaîtra l'écriture manuscrite photographiée. Principalement des formules multilignes.

L'équipe de reconnaissance d'images et de texte de l'iFlytek Research Institute a remporté le championnat avec un score de 67,9% et a largement dépassé les autres équipes participantes dans le principal indicateur d'évaluation-taux de rappel de formule
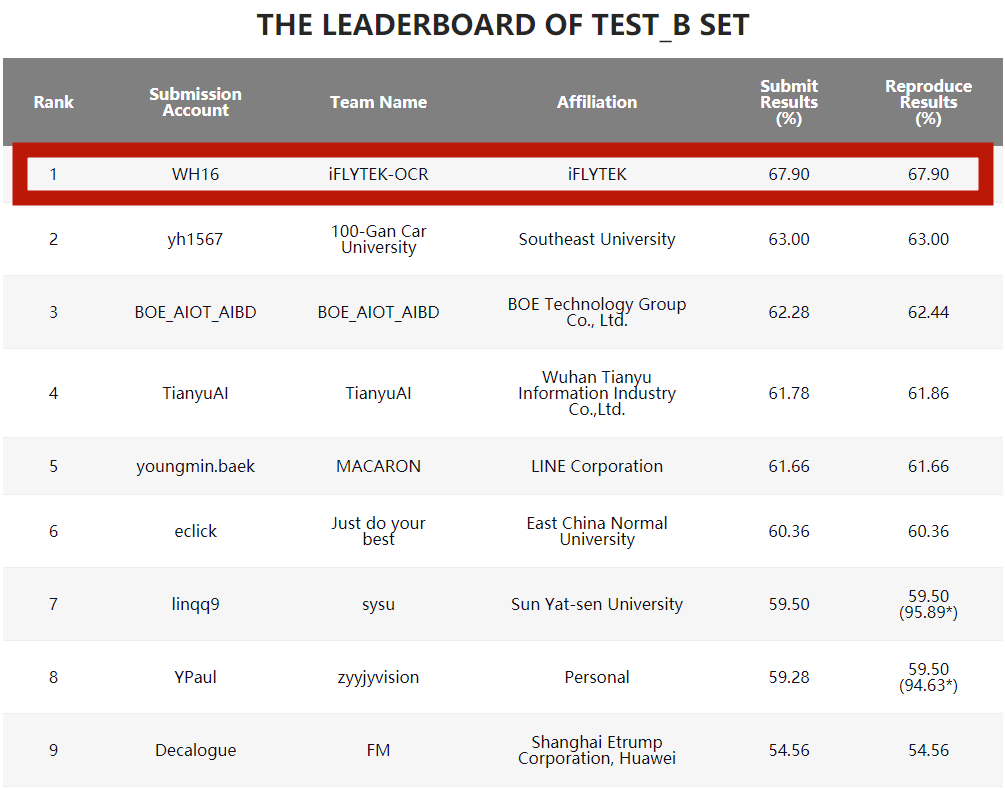
taux et liste de rappel de formule Correspondant aux résultats de soumission dans
Les formules multilignes sont plus complexes que les structures sur une seule ligne, et la taille changera lorsque le même caractère apparaît plusieurs fois dans la formule en même temps, l'ensemble de données utilisé dans le concours vient ; à partir de scènes réelles, les images de formule d'écriture manuscrite photographiées présentent même des problèmes tels qu'une mauvaise qualité, des interférences d'arrière-plan, des interférences de texte, des maculages et des interférences d'annotation. Ces facteurs rendent le jeu plus difficile.
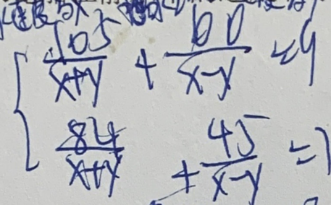
La formule a une structure complexe et occupe plusieurs lignes
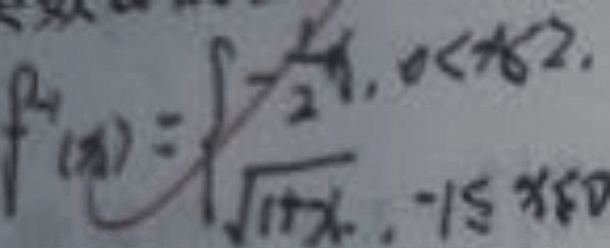
La qualité de l'image n'est pas élevée et la correction interfère
En réponse au problème selon lequel la formule a une structure complexe et occupe plusieurs lignes, le l'équipe utilise Conv2former avec un grand noyau de convolution comme structure d'encodeur pour étendre. Elle élargit le champ de vision du modèle et capture mieux les caractéristiques structurelles des formules multilignes ; propose de manière innovante un décodeur de séquence structurée basé sur un transformateur, qui modélise explicitement les relations hiérarchiques ; au sein des formules multilignes, améliorant considérablement la généralisation des structures complexes, de meilleurs modèles de sémantique structurée.
En réponse au problème d'ambiguïté des caractères causé par des problèmes de qualité d'image, l'équipe a proposé de manière innovante un algorithme d'entraînement du décodeur sémantiquement amélioré grâce à un entraînement conjoint de la sémantique et de la vision, le décodeur est doté d'une connaissance intrinsèque du domaine. Lorsque les caractères sont difficiles à identifier, le modèle peut utiliser de manière adaptative la connaissance du domaine pour faire des inférences et donner les résultats de reconnaissance les plus raisonnables.
En réponse au problème des changements importants dans la taille des caractères, l'équipe a proposé un algorithme adaptatif d'estimation de l'échelle des caractères et une stratégie de décodage par fusion multi-échelle, qui ont considérablement amélioré la robustesse du modèle aux changements de taille des caractères.
DocILETop : "Pick one from the line", le concours à double voie de localisation et d'extraction d'informations de documents arrive en tête de liste
DocILE (Document Information Location and Extraction Competition) évalue les méthodes d'apprentissage automatique dans les entreprises semi-structurées Performance dans la localisation, l'extraction et l'identification des éléments d'information clés dans les documents.
Le jeu est divisé en deux tâches de piste : KILE et LIR. La tâche KILE doit localiser l'emplacement des informations clés des catégories prédéfinies dans le document. Sur cette base, la tâche LIR regroupe en outre chaque information clé en différents éléments de ligne (Line Item), par exemple un seul objet (quantité, prix) dans un. ligne dans le tableau. )attendez. iFlytek et le Centre de Recherche ont finalement remporté le championnat sur deux pistes
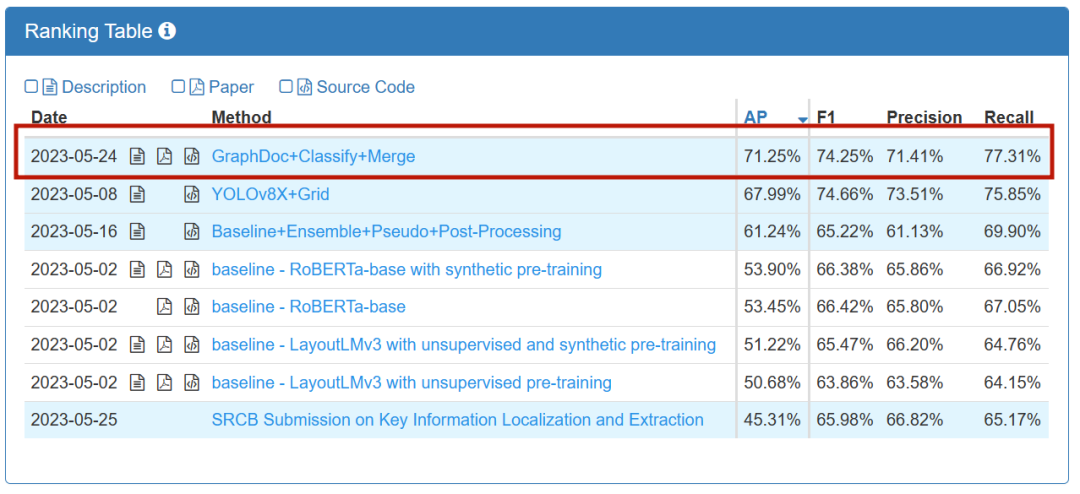 Liste des pistes KILE
Liste des pistes KILE
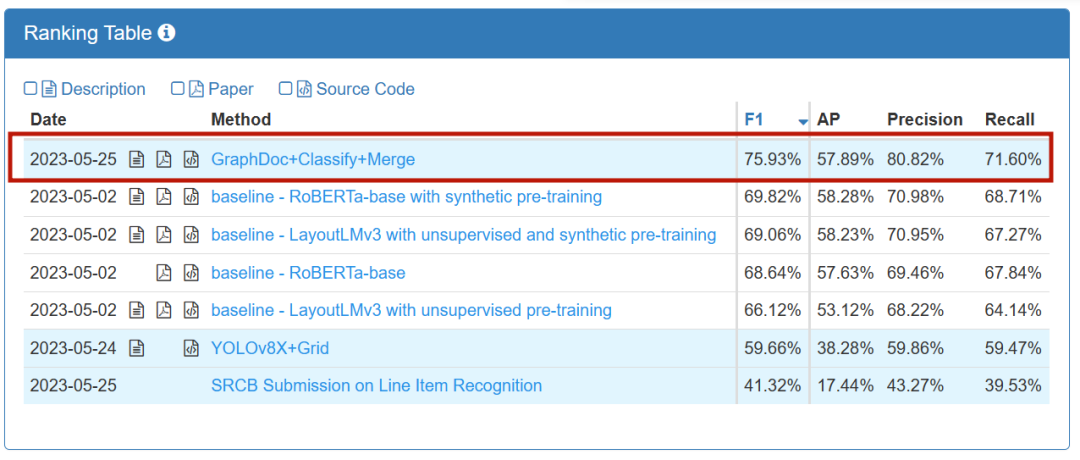
Liste des pistes LIR

Description de la piste KILE à gauche et description de la piste LIR à droite
Comme on peut le voir à partir de l'icône de tâche donnée par le responsable de l'événement, les types d'informations à extraire du document sont très complexes. Parmi elles, la tâche KILE doit non seulement extraire les informations clés des catégories prédéfinies, mais également obtenir l'emplacement spécifique des informations clés dans la tâche LIR, un élément de ligne peut avoir plusieurs lignes de texte dans un seul tableau ; De plus, il existe de nombreux types d'informations et des formats de documents complexes et divers dans l'ensemble de données de ce concours, ce qui augmente considérablement le défi.
L'équipe commune a proposé deux solutions d'innovation technologique au niveau algorithmique :
Dans la phase de pré-formation, nous avons conçu un filtre de documents basé sur la qualité OCR en extrayant 2,74 millions de pages d'images de documents à partir de documents non annotés fournis par l'organisateur. Ensuite, nous utilisons un modèle de langage pré-entraîné pour obtenir la représentation sémantique de chaque ligne de texte du document, et utilisons la tâche de récupération de représentation de phrase masquée, pré-entraînée sous différentes configurations Top-K (capacité d'attention du document dans le GraphDoc modèle (un hyperparamètre)
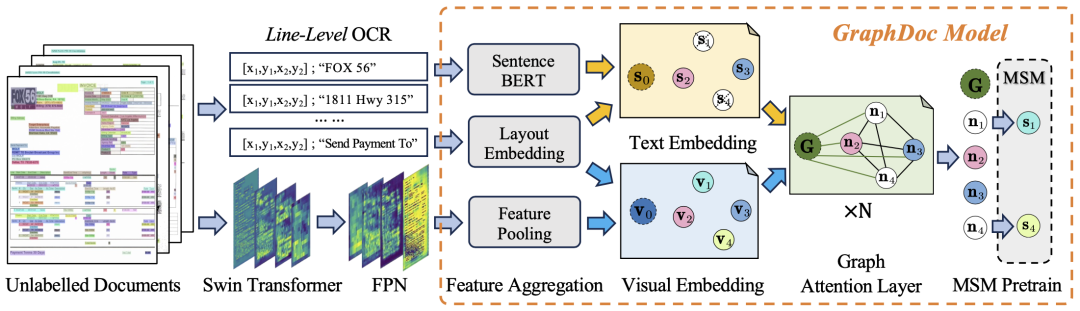
Dans la phase de réglage fin de l'ensemble de données, l'équipe a utilisé le GraphDoc pré-entraîné pour extraire la représentation multimodale de la zone de texte et effectuer des opérations de classification. Sur la base des résultats de classification, des représentations multimodales sont envoyées au module de fusion d'attention de bas niveau pour l'agrégation d'instances. Sur la base de l'agrégation d'instances, le module de fusion d'attention de haut niveau est utilisé pour réaliser l'agrégation d'instances d'éléments de ligne. La fusion d'attention proposée Les modules ont la même structure mais ne partagent pas de paramètres entre eux. Ils peuvent être utilisés à la fois pour les tâches KILE et LIR avec de bons résultats.
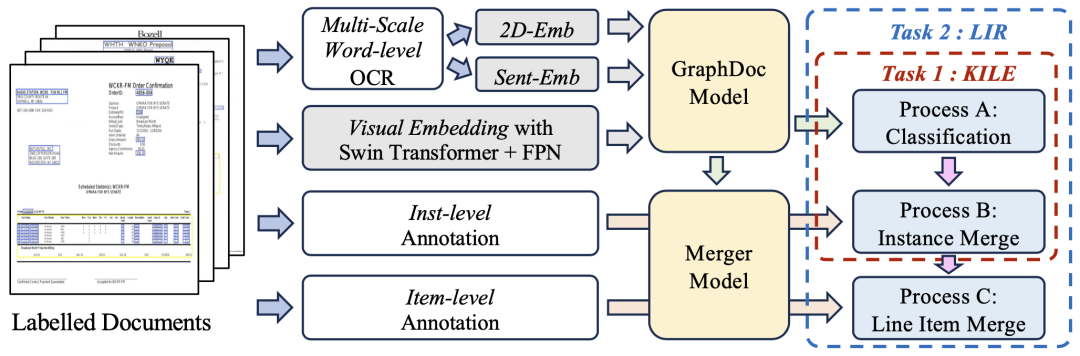
SVRDHaut : Premier dans la tâche d'extraction d'informations structurées sans échantillon, un grand test du modèle de pré-formation
Le concours SVRD (Structured Text Information Extraction) est divisé en 4 sous-pistes tâches, iFlytek a remporté la première place dans la sous-piste très difficile d'extraction d'informations structurées sur échantillon zéro (Tâche 3 : Extraction de texte structuré sur échantillon zéro E2E) avec le centre de recherche
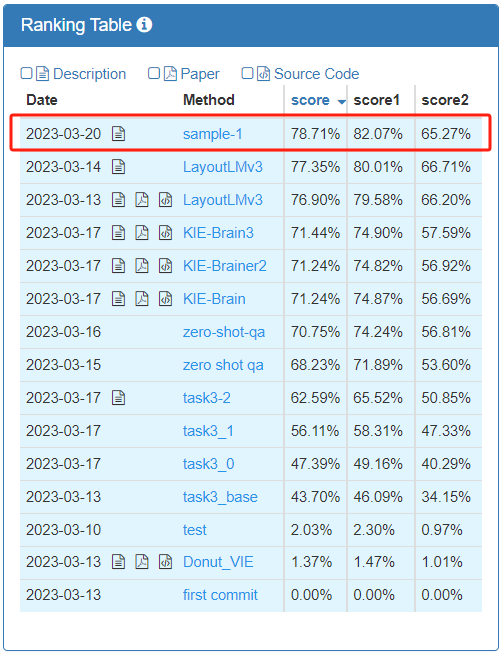
ordre de classement
dans les différents types officiellement désignés de factures qui doivent être extraites Dans le contexte des éléments clés, la piste demande aux équipes participantes d'utiliser le modèle pour afficher le contenu correspondant de ces éléments clés dans l'image « Échantillon zéro » signifie qu'il n'y a pas de chevauchement entre les types de factures. l'ensemble d'entraînement et l'ensemble de test ; la piste examine la prédiction de bout en bout du modèle. Pour plus de précision, prenez la moyenne pondérée du score1 et du score2 comme indice d'évaluation final.
Pour les modèles pré-entraînés, aucun échantillon ne propose des exigences plus élevées. Dans le même temps, différents formats de facture sont utilisés dans le cadre du concours, et les noms des arrêts, les heures de départ et d'autres éléments dans chaque format sont différents. De plus, les photos des factures présentent des problèmes tels que des interférences d'arrière-plan, des reflets et des chevauchements de texte, ce qui augmente encore la difficulté d'identification et d'extraction. L'équipe a initialement adopté la stratégie de décodage à double branche générée par copie pour effectuer des modèles d'extraction de fonctionnalités lorsque la confiance du résultat OCR frontal est élevée, le résultat OCR est directement copié lorsque la confiance du résultat OCR est faible ; , un nouveau résultat de prédiction est généré pour atténuer les erreurs de reconnaissance frontale introduites par le modèle OCR
De plus, l'équipe a également extrait les fonctionnalités graphdoc au niveau des phrases basées sur les résultats OCR en tant qu'entrée dans le modèle d'extraction de fonctionnalités. fonctionnalités multimodales d'image, de texte, d'emplacement et de mise en page Par rapport à la saisie monomodale, la saisie de texte brut a une représentation de fonctionnalités plus forte. 
Des applications ont été mises en œuvre dans les domaines de l'éducation, de la finance, des soins médicaux, etc. pour aider les grands modèles à améliorer leurs capacités multimodales. -technologies liées Il a également pénétré des domaines tels que l'éducation, la finance, les soins médicaux, la justice et le matériel intelligent, donnant ainsi du pouvoir à de multiples entreprises et produits. 
;
Il n'y a pas si longtemps, l'assistant de recherche scientifique Spark a été publié sur le forum principal de l'iFlytek Global 1024 Developer Festival. L'une des trois fonctions principales de la lecture d'articles permet de réaliser une interprétation intelligente des articles et de répondre rapidement aux questions connexes. Par la suite, sur la base de la reconnaissance de formules de haute précision, l'effet des formules structurelles chimiques organiques, des graphiques, des icônes, des organigrammes, des tableaux et autres reconnaissances de scènes structurées sera également amélioré. Cette fonction aidera également les chercheurs scientifiques à améliorer leur efficacité ;La technologie de positionnement et d'extraction d'informations documentaires est largement utilisée dans le domaine financier, comme l'extraction et l'examen d'éléments de contrat, l'extraction d'éléments de facture bancaire, l'examen de la protection des consommateurs de contenu marketing et d'autres scénarios. Ces technologies peuvent réaliser des fonctions telles que l'analyse de données, l'extraction d'informations et l'examen comparatif de documents ou de fichiers, et aider les données commerciales à être rapidement saisies, extraites et comparées, améliorant ainsi l'efficacité du processus d'examen et réduisant les coûts
Dans cet événement principal 1024 L'assistant personnel de santé IA publié sur le forum est iFlytek Xiaoyi. Il peut non seulement analyser les listes de contrôle et les commandes de tests et fournir des analyses et des suggestions, mais il peut également analyser les piluliers, effectuer des demandes de renseignements supplémentaires et fournir des suggestions de médicaments auxiliaires. Pour les rapports d'examen physique, les utilisateurs peuvent prendre des photos et les télécharger, et iFlytek Xiaoyi peut identifier les informations clés, interpréter de manière exhaustive les indicateurs anormaux, s'enquérir de manière proactive et fournir une aide supplémentaire. Cette fonction repose sur la prise en charge de la technologie de positionnement et d'extraction d'informations documentaires

La technologie de reconnaissance d'images et de texte d'iFlytek continue de faire des percées dans les algorithmes, de la reconnaissance de mots uniques et de lignes de texte à la reconnaissance de structures bidimensionnelles et de chapitres plus complexes. .repérage du niveau. Une technologie de reconnaissance d'image et de texte plus puissante peut améliorer l'effet et le potentiel des grands modèles multimodaux dans la description d'image, les questions et réponses d'image, la création de reconnaissance d'image, la compréhension et le traitement de documents, etc. combine la reconnaissance vocale, la synthèse vocale, la traduction automatique et d'autres technologies ont formé des innovations systématiques, et les produits autonomes ont montré des fonctions plus puissantes et des avantages de valeur plus évidents après application. Les projets connexes ont également remporté le premier prix du Wu Wenjun Artificial Intelligence Technology Progress Award 2022. . Dans le nouveau voyage, « d'autres floraisons » dans plusieurs concours ICDAR 2023 ne sont pas seulement un retour d'expérience sur les progrès continus d'iFlytek dans la profondeur de la technologie de reconnaissance et de compréhension d'images et de textes, mais aussi l'affirmation de son expansion continue en termes d'ampleur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un long article de 10 000 mots丨Déconstruire la chaîne industrielle de la sécurité de l'IA, les solutions et les opportunités entrepreneuriales
- China Mobile a pris l'initiative de créer la Yuanverse Industry Alliance, avec un total de 24 membres, dont iFlytek, Mango TV, etc.
- [Trend Weekly] Tendance mondiale du développement de l'industrie de l'intelligence artificielle : OpenAI a soumis une demande de marque 'GPT-5' auprès de l'Office américain des brevets
- La machine d'apprentissage IA d'iFLYTEK a été récemment mise à niveau, introduisant le grand modèle V2.0 pour obtenir un enseignement personnalisé en fonction des aptitudes.
- Cette entreprise de Changning a lancé de nouveaux produits lors de la World VR Industry Conference !