
Maison >Périphériques technologiques >IA >DeepMind a souligné que 'Transformer ne peut pas généraliser au-delà des données préalables à l'entraînement', mais certaines personnes l'ont remis en question.
DeepMind a souligné que 'Transformer ne peut pas généraliser au-delà des données préalables à l'entraînement', mais certaines personnes l'ont remis en question.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-07 21:13:10731parcourir
Transformer est-il destiné à être incapable de résoudre de nouveaux problèmes au-delà des « données d'entraînement » ?
En parlant des capacités impressionnantes démontrées par les grands modèles de langage, l'une d'elles est la capacité de réaliser un apprentissage en quelques étapes en fournissant des échantillons en contexte et en demandant au modèle de générer une réponse basée sur l'entrée finale fournie. Cela s'appuie sur la technologie d'apprentissage automatique sous-jacente « modèle Transformer », et ils peuvent également effectuer des tâches d'apprentissage contextuel dans des domaines autres que la langue.
Sur la base de l'expérience passée, il a été prouvé que pour les familles de tâches ou les classes de fonctions bien représentées dans le mélange pré-entraîné, il n'y a presque aucun coût pour sélectionner les classes de fonctions appropriées pour l'apprentissage contextuel. Par conséquent, certains chercheurs pensent que Transformer peut bien se généraliser aux tâches ou fonctions distribuées avec la même distribution que les données d'entraînement. Cependant, une question courante mais non résolue est la suivante : comment ces modèles fonctionnent-ils sur des échantillons qui ne sont pas cohérents avec la distribution des données d'entraînement ?
Dans une étude récente, des chercheurs de DeepMind ont exploré cette question à l'aide de recherches empiriques. Ils expliquent le problème de généralisation comme suit : « Un modèle peut-il générer de bonnes prédictions avec des exemples contextuels en utilisant des fonctions qui n'appartiennent à aucune classe de fonctions de base dans le mélange de données pré-entraînées à partir d'une fonction qui n'appartient à aucune classe de fonctions de base ? classes de fonctions vues dans le mélange de données de pré-entraînement ? )》
L'objectif de ce contenu est d'explorer l'impact des données utilisées dans le processus de pré-entraînement sur la capacité d'apprentissage en quelques étapes du modèle Transformer résultant. Afin de résoudre ce problème, les chercheurs ont d'abord étudié la capacité de Transformer à sélectionner différentes familles de fonctions pour la sélection du modèle pendant le processus de pré-formation (Section 3), puis ont répondu au problème de généralisation OOD de plusieurs cas clés (Section 4)

Lien papier : https://arxiv.org/pdf/2311.00871.pdf
Ce qui suit a été découvert dans leur recherche : Premièrement, le Transformer pré-entraîné a de mauvaises performances dans la prédiction des fonctions extraites de la classe de fonctions pré-entraînée. C'est très difficile lorsqu'il est combiné de manière convexe ; deuxièmement, bien que Transformer puisse généraliser efficacement des parties plus rares de l'espace des classes de fonctions, Transformer fera toujours des erreurs lorsque la tâche dépasse sa plage de distribution
Transformer ne peut pas généraliser au-delà de la cognition des données de pré-entraînement, et donc ne peut pas résoudre les problèmes au-delà de la cognition

En général, les contributions de cet article sont les suivantes :
Utiliser un mélange de différentes classes de fonctions pour pré-entraîner le modèle Transformer, afin de procéder à un apprentissage contextuel et de décrire les caractéristiques du comportement de sélection du modèle ;
Pour les fonctions "incohérentes" avec les classes de fonctions dans les données de pré-entraînement, le comportement du modèle Transformer pré-entraîné en apprentissage contextuel est étudié
Fort Fort Il a été démontré que les modèles peuvent effectuer une sélection de modèles parmi les classes de fonctions pré-entraînées pendant l'apprentissage du contexte avec un faible coût statistique supplémentaire, mais il existe également des preuves limitées que les modèles peuvent exécuter des comportements d'apprentissage du contexte au-delà de leur portée de données de pré-entraînement.
Ce chercheur estime que cela peut être une bonne nouvelle pour la sécurité, au moins le modèle ne se comportera pas comme il le souhaite

Mais certaines personnes ont souligné que le modèle utilisé dans cet article n'est pas adapté ——"GPT -2 scale" signifie que le modèle présenté dans cet article comporte environ 1,5 milliard de paramètres, ce qui est en effet difficile à généraliser. 

Ensuite, jetons un coup d'œil aux détails du document.
Phénomène de sélection de modèle
Lors du pré-entraînement des mélanges de données de différentes classes de fonctions, vous serez confronté à un problème : lorsque le modèle rencontre des échantillons de contexte pris en charge par le mélange de pré-entraînement, comment sélectionner entre différentes classes de fonctions Faire un choix ?
Dans la recherche, il a été constaté que lorsqu'un modèle est exposé à des échantillons contextuels liés aux classes de fonctions dans les données de pré-entraînement, il est capable de faire les meilleures prédictions (ou presque). Les chercheurs ont également examiné les performances du modèle sur des fonctions qui n'appartiennent à aucune classe de fonctions de composant unique et discutent de fonctions qui n'ont aucun rapport avec les données de pré-entraînement dans la section 4
Tout d'abord, nous commençons par l'étude des fonctions linéaires. Nous pouvons voir que les fonctions linéaires ont attiré une large attention dans le domaine de l'apprentissage contextuel. L'année dernière, Percy Liang et d'autres de l'Université de Stanford ont publié un article « Que peuvent apprendre les transformateurs en contexte ? » Une étude de cas d'une classe de fonctions simples a montré que le transformateur pré-entraîné fonctionnait très bien dans l'apprentissage de nouveaux contextes de fonctions linéaires, atteignant presque le niveau optimal
Ils ont considéré deux modèles en particulier : un dans les fonctions linéaires denses (modèle linéaire A formé sur une fonction linéaire clairsemée (tous les coefficients du modèle sont non nuls) et l'autre est un modèle entraîné sur une fonction linéaire clairsemée (seuls 2 coefficients sur 20 sont non nuls). Chaque modèle a fonctionné de manière comparable à la régression linéaire et à la régression Lasso sur la nouvelle fonction linéaire dense et la fonction linéaire clairsemée, respectivement. De plus, les chercheurs ont comparé ces deux modèles avec des modèles pré-entraînés sur un mélange de fonctions linéaires clairsemées et de fonctions linéaires denses.
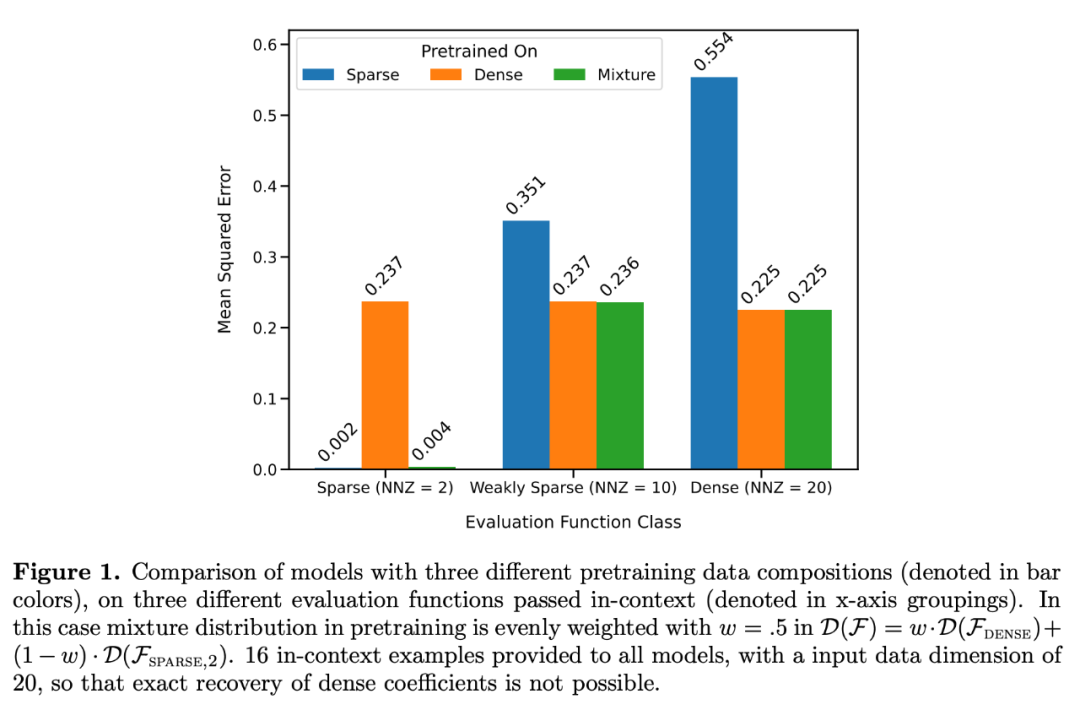
Comme le montre la figure 1, les performances du modèle en apprentissage contextuel sur un 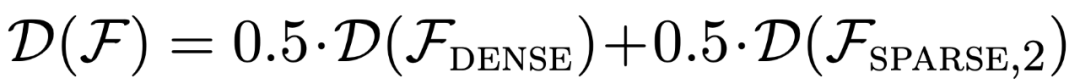 mixture sont similaires à celles d'un modèle pré-entraîné sur une seule classe de fonctions. Étant donné que les performances du modèle hybride pré-entraîné sont similaires au modèle théorique optimal de Garg et al [4], les chercheurs en déduisent que le modèle est également proche de l'optimal. La courbe d'apprentissage ICL de la figure 2 montre que cette capacité de sélection de modèle de contexte est relativement cohérente avec le nombre d'exemples de contexte fournis. On peut également voir sur la figure 2 que pour des classes de fonctions spécifiques, divers poids non triviaux
mixture sont similaires à celles d'un modèle pré-entraîné sur une seule classe de fonctions. Étant donné que les performances du modèle hybride pré-entraîné sont similaires au modèle théorique optimal de Garg et al [4], les chercheurs en déduisent que le modèle est également proche de l'optimal. La courbe d'apprentissage ICL de la figure 2 montre que cette capacité de sélection de modèle de contexte est relativement cohérente avec le nombre d'exemples de contexte fournis. On peut également voir sur la figure 2 que pour des classes de fonctions spécifiques, divers poids non triviaux 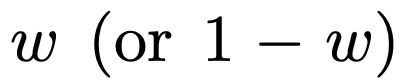 sont utilisés.
sont utilisés.
La courbe d'apprentissage de l'ICL est presque cohérente avec la meilleure complexité d'échantillon de base. L'écart est faible et diminue rapidement à mesure que le nombre d'échantillons ICL augmente, conformément aux points de la courbe d'apprentissage ICL de la figure 1. La figure 2 montre que la généralisation ICL du modèle Transformer sera affectée par les effets de non-distribution. Bien que la classe linéaire dense et la classe linéaire clairsemée soient des fonctions linéaires, vous pouvez voir que la courbe rouge de la figure 2a (correspondant au transformateur qui est uniquement pré-entraîné sur la fonction linéaire clairsemée et évalué sur les données linéaires denses) a de mauvaises performances. , Vice versa, les performances de la courbe brune de la figure 2b sont également médiocres. Les chercheurs ont également observé un comportement similaire dans d'autres classes de fonctions non linéaires
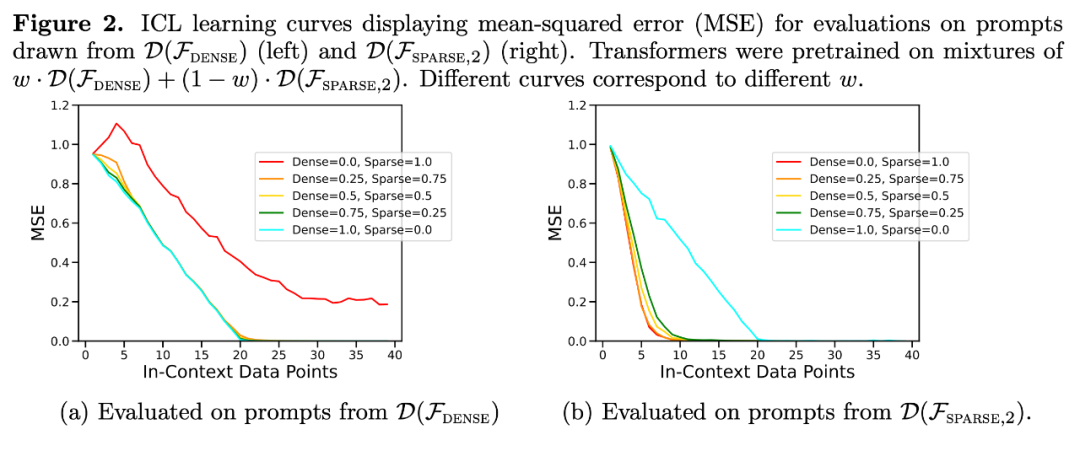 Retour à l'expérience de la figure 1, traçant l'erreur en fonction du nombre de coefficients non nuls sur toute la plage possible, les résultats montrent que lorsque w = . Le modèle préconditionné sur le mélange de 5,
Retour à l'expérience de la figure 1, traçant l'erreur en fonction du nombre de coefficients non nuls sur toute la plage possible, les résultats montrent que lorsque w = . Le modèle préconditionné sur le mélange de 5,
 En fait, la figure 3b montre que lorsque les échantillons fournis dans le contexte proviennent de fonctions soit très clairsemées, soit très denses, les prédictions sont presque identiques à celles d'un modèle pré-entraîné utilisant uniquement des données clairsemées ou uniquement des données denses. Cependant, entre les deux, lorsque le nombre de coefficients non nuls est ≈ 4, les prédictions hybrides s'écartent de celles du transformateur pré-entraîné purement dense ou purement clairsemé.
En fait, la figure 3b montre que lorsque les échantillons fournis dans le contexte proviennent de fonctions soit très clairsemées, soit très denses, les prédictions sont presque identiques à celles d'un modèle pré-entraîné utilisant uniquement des données clairsemées ou uniquement des données denses. Cependant, entre les deux, lorsque le nombre de coefficients non nuls est ≈ 4, les prédictions hybrides s'écartent de celles du transformateur pré-entraîné purement dense ou purement clairsemé.
Cela montre que le modèle pré-entraîné sur le mélange ne sélectionne pas simplement une seule classe de fonctions à prédire, mais prédit un résultat intermédiaire.
Limitations de la capacité de sélection du modèleEnsuite, les chercheurs ont examiné la capacité de généralisation ICL du modèle sous deux perspectives. Premièrement, les performances ICL des fonctions auxquelles le modèle n'a pas été exposé pendant la formation sont testées ; deuxièmement, les performances ICL des versions extrêmes des fonctions auxquelles le modèle a été exposé pendant la pré-formation sont évaluées. Peu de preuves d'une généralisation hors distribution ont été trouvées. Lorsque la fonction diffère grandement de la fonction observée lors du pré-entraînement, la prédiction sera instable ; lorsque la fonction est suffisamment proche des données de pré-entraînement, le modèle peut bien se rapprocher
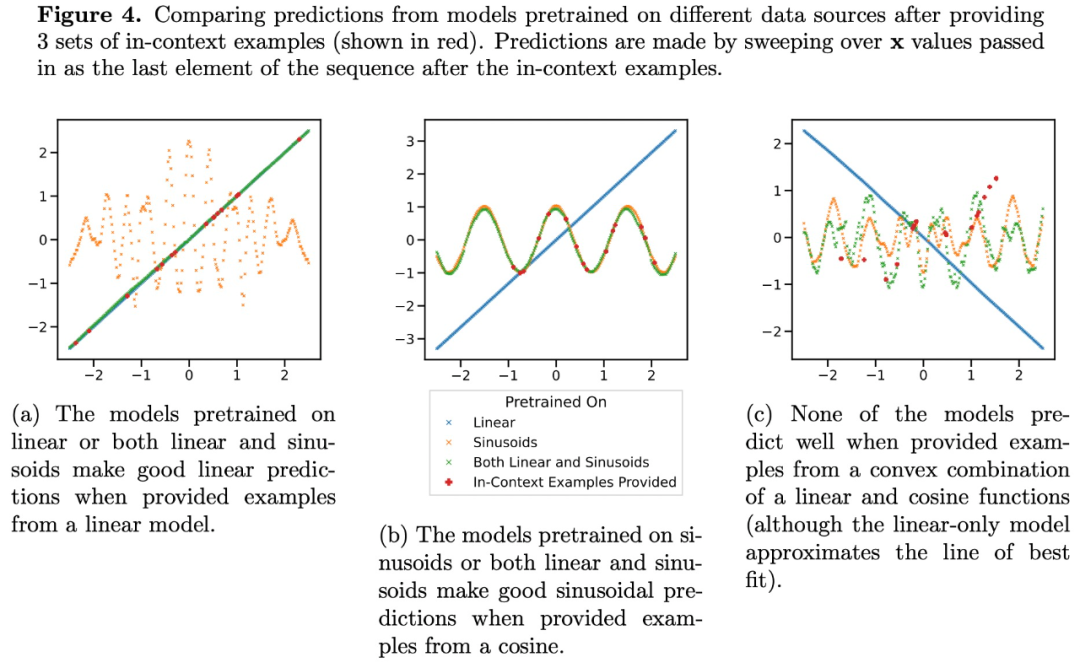
Les prédictions de Transformer à des niveaux de parcimonie moyens (nnz = 3 à 7) ne sont pas similaires aux prédictions d'une classe de fonctions fournies par la pré-entraînement, mais se situent quelque part entre les deux, comme le montre la figure 3a. Par conséquent, nous pouvons en déduire que le modèle présente une sorte de biais inductif qui lui permet de combiner des classes de fonctions pré-entraînées de manière non triviale. Par exemple, nous pouvons soupçonner que le modèle peut générer des prédictions basées sur la combinaison de fonctions observées lors du pré-entraînement. Pour tester cette hypothèse, nous avons exploré la possibilité d'effectuer des ICL sur des fonctions linéaires, des sinusoïdes et des combinaisons convexes des deux. Ils se concentrent sur le cas unidimensionnel pour faciliter l'évaluation et la visualisation de la classe de fonctions non linéaires
La figure 4 montre que même si le modèle pré-entraîné sur un mélange de fonctions linéaires et de sinusoïdes (c'est-à-dire  ) est capable de prédire les deux séparément Soit l'une des fonctions fait de bonnes prédictions, elle ne peut pas correspondre à une fonction de combinaison convexe des deux. Cela suggère que le phénomène d'interpolation de fonctions linéaires illustré à la figure 3b n'est pas un biais inductif généralisable de l'apprentissage contextuel de Transformer. Cependant, il continue de soutenir l'hypothèse plus étroite selon laquelle lorsque l'échantillon de contexte est proche de la classe de fonctions apprise lors de la pré-formation, le modèle est capable de sélectionner la meilleure classe de fonctions pour la prédiction.
) est capable de prédire les deux séparément Soit l'une des fonctions fait de bonnes prédictions, elle ne peut pas correspondre à une fonction de combinaison convexe des deux. Cela suggère que le phénomène d'interpolation de fonctions linéaires illustré à la figure 3b n'est pas un biais inductif généralisable de l'apprentissage contextuel de Transformer. Cependant, il continue de soutenir l'hypothèse plus étroite selon laquelle lorsque l'échantillon de contexte est proche de la classe de fonctions apprise lors de la pré-formation, le modèle est capable de sélectionner la meilleure classe de fonctions pour la prédiction.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelle est la vitesse de téléchargement théorique qu'un système de réseau 4G peut atteindre ?
- Transformer imite le cerveau, surpasse 42 modèles en matière de prédiction de l'imagerie cérébrale et peut également simuler la transmission entre les sens et le cerveau
- Transformers+world model, peut-il sauver l'apprentissage par renforcement profond ?