
Maison >Périphériques technologiques >IA >Après la distillation Whisper d'OpenAI, la vitesse de reconnaissance vocale a été grandement améliorée : le nombre d'étoiles a dépassé les 1 000 en deux jours
Après la distillation Whisper d'OpenAI, la vitesse de reconnaissance vocale a été grandement améliorée : le nombre d'étoiles a dépassé les 1 000 en deux jours

- PHPzavant
- 2023-11-05 11:25:061556parcourir
Récemment, la vidéo de « Taylor Swift Showing off Chinese » est rapidement devenue populaire sur les principaux réseaux sociaux, et plus tard des vidéos similaires telles que « Guo Degang Showing off English » sont apparues. Beaucoup de ces vidéos sont produites par une application d'intelligence artificielle appelée "HeyGen"
Cependant, à en juger par la popularité actuelle de HeyGen, son utilisation pour créer des vidéos similaires peut prendre beaucoup de temps. Heureusement, ce n’est pas la seule façon d’y parvenir. Les amis qui comprennent la technologie peuvent également rechercher d'autres alternatives, telles que le modèle parole-texte Whisper, la traduction de texte GPT, le clonage vocal + la génération audio so-vits-svc et la génération de vidéos en forme de bouche qui correspondent à l'audio GeneFace++dengdeng.
Le contenu réécrit est : Parmi eux, Whisper est un modèle de reconnaissance automatique de la parole (ASR) développé et open source par OpenAI, très simple à utiliser. Ils ont formé Whisper sur 680 000 heures de données supervisées multilingues (98 langues) et multitâches collectées sur le Web. OpenAI estime que l'utilisation d'un ensemble de données aussi vaste et diversifié peut améliorer la capacité du modèle à reconnaître les accents, le bruit de fond et les termes techniques. En plus de la reconnaissance vocale, Whisper peut également transcrire plusieurs langues et traduire ces langues en anglais. Actuellement, Whisper a de nombreuses variantes et est devenu un composant nécessaire lors de la création de nombreuses applications d'IA
Récemment, l'équipe HuggingFace a proposé une nouvelle variante - Distil-Whisper. Cette variante est une version distillée du modèle Whisper, qui se caractérise par sa petite taille, sa vitesse rapide et sa très grande précision, ce qui la rend idéale pour une utilisation dans des environnements nécessitant une faible latence ou disposant de ressources limitées. Cependant, contrairement au modèle Whisper original qui peut gérer plusieurs langues, Distil-Whisper ne peut gérer que l'anglais

Lien papier : https://arxiv.org/pdf/2311.00430.pdf
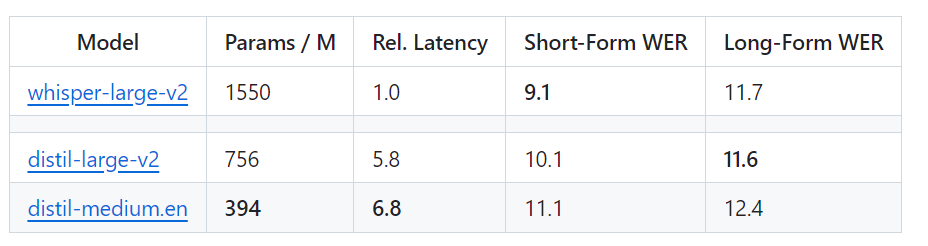
Spécifique et In en d'autres termes, Distil-Whisper a deux versions, avec des tailles de paramètres de 756M (distil-large-v2) et 394M (distil-medium.en)
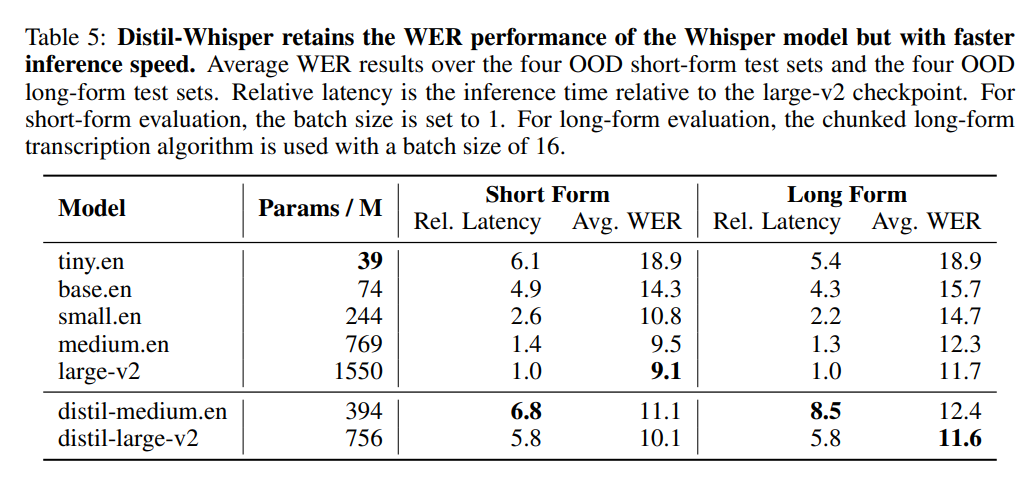
Par rapport à Whisper-large-v2 d'OpenAI, la version 756M Le nombre de Les paramètres de distill-large-v2 sont réduits de plus de moitié, mais il atteint une accélération de 6 fois et la précision est très proche de Whisper-large-v2. La différence dans le taux d'erreur de mot (WER) de l'audio court est de 1. Dans les %, encore mieux que Whisper-large-v2 sur l'audio long. En effet, grâce à une sélection et un filtrage minutieux des données, la robustesse de Whisper est maintenue et les hallucinations sont réduites.

La vitesse de la version Web de Whisper est intuitivement comparée à celle de Distil-Whisper. Source de l'image : https://twitter.com/xenovacom/status/1720460890560975103
Ainsi, bien qu'il ne soit sorti que depuis deux ou trois jours, Distil-Whisper a déjà dépassé le millier d'étoiles.
- Adresse du projet : https://github.com/huggingface/distil-whisper#1-usage
- Adresse du modèle : https://huggingface.co/models ? Autre = arXiv: 2311.00430
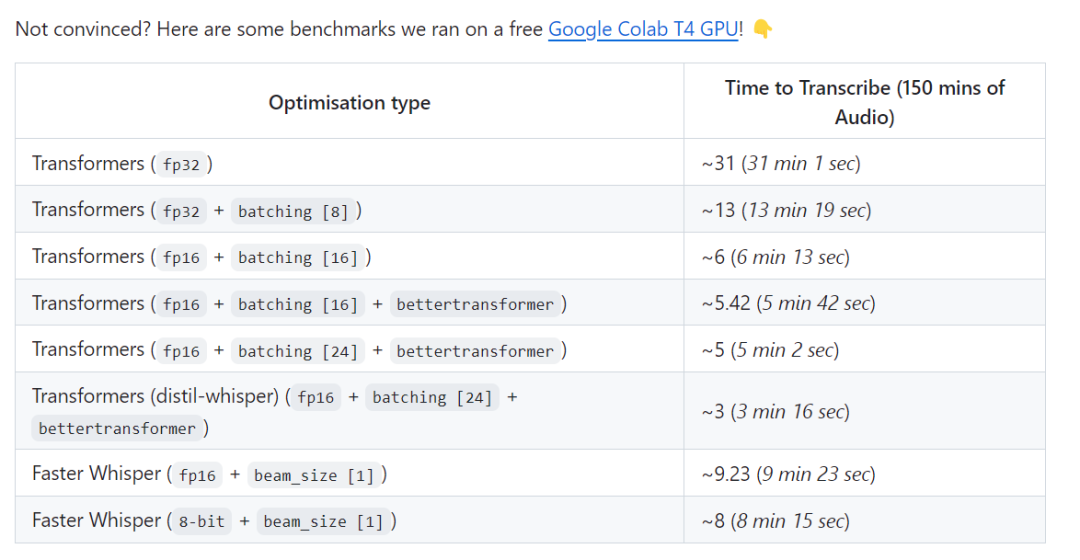
Dans l'addition, un résultat de test montre que le distil-whisper peut être 2,5 fois plus rapide que plus rapide lors du traitement de 150 minutes d'audio Le test le lien est : https://github.com/Vaibhavs10/insanely-fast-whisper#insanely-fast-whisper
Ce qui suit est une réécriture du contenu original : L'architecture de Distil-Whisper est illustrée dans la figure 1 ci-dessous. Les chercheurs ont initialisé le modèle étudiant en copiant l’intégralité de l’encodeur du modèle enseignant et l’ont figé pendant la formation. Ils ont copié la première et la dernière couche de décodeur des modèles Whisper-medium.en et Whisper-large-v2 d'OpenAI, et ont obtenu 2 points de contrôle de décodeur après distillation, nommés distil-medium.en et les détails dimensionnels du modèle obtenu par distillation de distill- large-v2
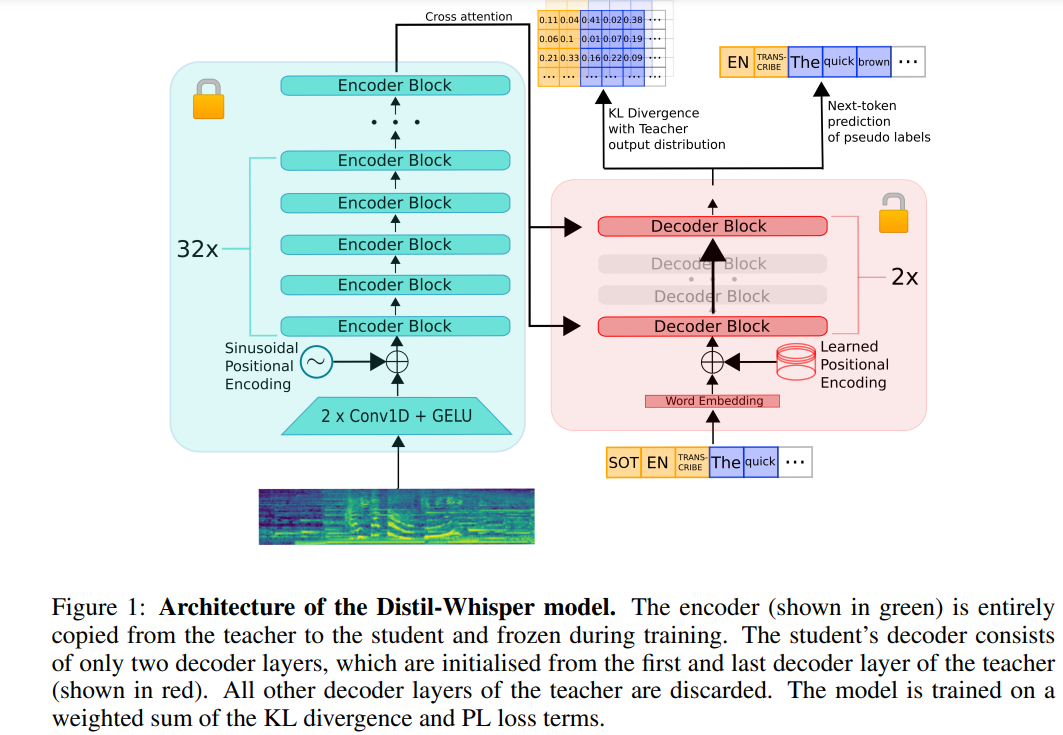
sont présentés dans le tableau 3.
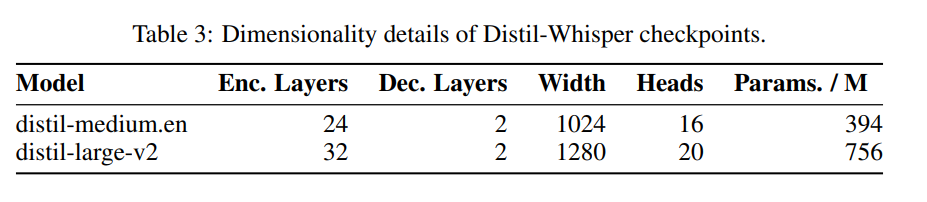
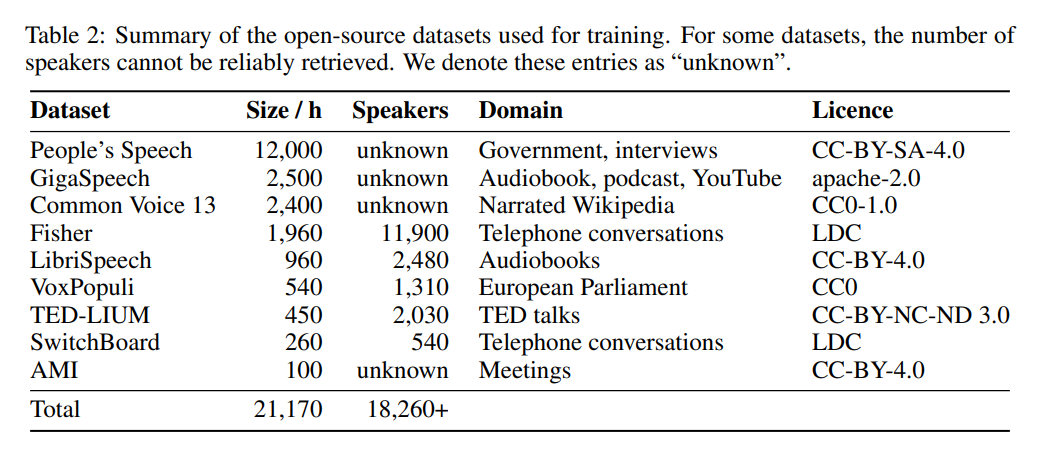
En termes de données, le modèle a été formé pendant 22 000 heures sur 9 ensembles de données open source différents (voir tableau 2). Les pseudo-balises sont générées par Whisper. Il est à noter qu’ils ont utilisé un filtre WER et que seules les balises avec un score WER supérieur à 10 % ont été retenues. L’auteur dit que c’est la clé du maintien des performances !
Le tableau 5 ci-dessous présente les principaux résultats de performances de Distil-Whisper.
Selon l'auteur, en gelant le fonctionnement de l'encodeur, Distil-Whisper se comporte de manière très robuste contre le bruit. Comme le montre la figure ci-dessous, Distil-Whisper suit une courbe de robustesse similaire à Whisper dans des conditions bruyantes et fonctionne mieux que d'autres modèles tels que Wav2vec2
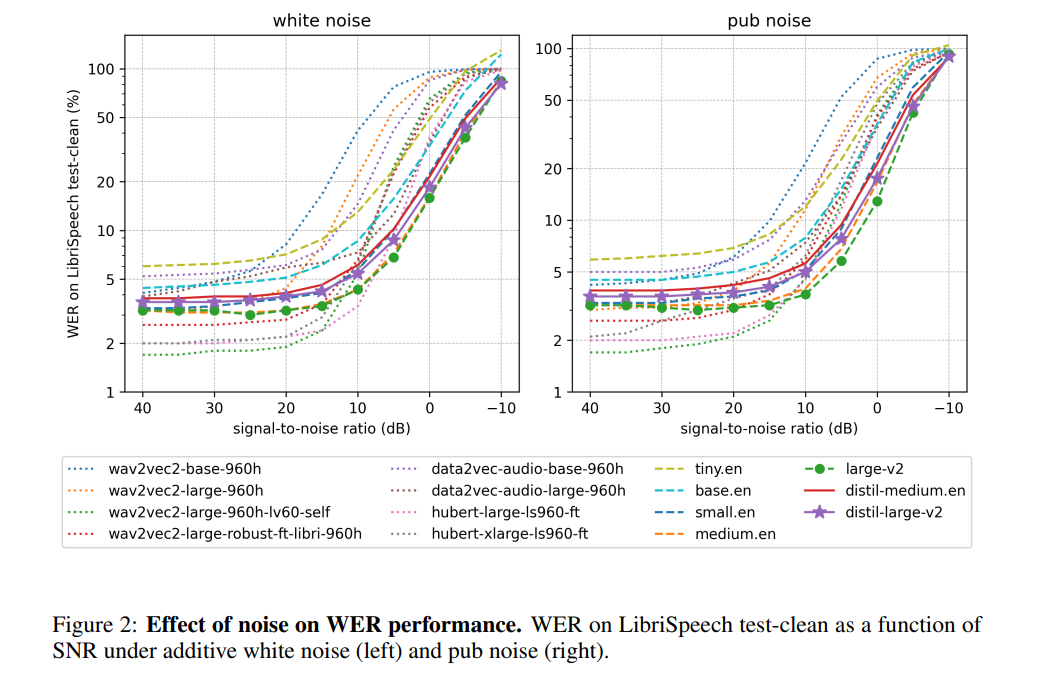
Par rapport à Whisper lors du traitement de fichiers audio plus longs, Distil-Whisper réduit efficacement hallucinations. Selon l'auteur, cela est principalement dû au filtrage WER. En partageant le même encodeur, Distil-Whisper peut être associé à Whisper pour un décodage spéculatif. Cela se traduit par une accélération 2x avec seulement une augmentation de 8 % des paramètres tout en produisant exactement le même résultat que Whisper.
Veuillez consulter l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment utiliser le modèle de boîte HTML5
- Explication détaillée de Three.js utilisant le plug-in de contrôle d'orbite (contrôle d'orbite) pour contrôler l'interaction du modèle
- Quelle est la touche de raccourci pour fusionner des calques dans AI ?
- Qu'est-ce que cai appelle un ordinateur ?
- En quoi la norme ieee802 divise-t-elle le modèle hiérarchique du réseau local en