
Maison >Périphériques technologiques >IA >Créez des pipelines de données de deep learning efficaces avec Ray
Créez des pipelines de données de deep learning efficaces avec Ray

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-11-02 20:17:15932parcourir
Le GPU requis pour la formation du modèle d'apprentissage profond est puissant mais coûteux. Pour utiliser pleinement le GPU, les développeurs ont besoin d'un canal de transfert de données efficace, capable de transférer rapidement les données vers le GPU lorsqu'il est prêt à calculer la prochaine étape de formation. L'utilisation de Ray peut améliorer considérablement l'efficacité du canal de transmission de données
1 La structure du pipeline de données de formation
Prenons d'abord un coup d'œil au pseudocode de la formation du modèle
for step in range(num_steps):sample, target = next(dataset) # 步骤1train_step(sample, target) # 步骤2
À l'étape 1, obtenez les échantillons et les étiquettes de. le prochain mini-lot. À l'étape 2, ils sont transmis à la fonction train_step, qui les copie sur le GPU, effectue une passe avant et arrière pour calculer la perte et le gradient, et met à jour les poids de l'optimiseur.
Veuillez en savoir plus sur l'étape 1. Lorsque l'ensemble de données est trop volumineux pour tenir en mémoire, l'étape 1 récupère le mini-lot suivant à partir du disque ou du réseau. De plus, l’étape 1 comprend également un certain nombre de prétraitements. Les données d'entrée doivent être converties en tenseurs numériques ou en collections de tenseurs avant d'être introduites dans le modèle. Dans certains cas, d'autres transformations sont également effectuées sur le tenseur avant d'être transmises au modèle, telles que la normalisation, la rotation autour de l'axe, le brassage aléatoire, etc.
Si le workflow est exécuté strictement en séquence, c'est-à-dire que l'étape 1 est effectuée en premier , puis effectuez l'étape 2, le modèle devra alors toujours attendre les opérations d'entrée, de sortie et de prétraitement du prochain lot de données. Le GPU ne sera pas utilisé efficacement et restera inactif pendant le chargement du prochain mini-lot de données.
Pour résoudre ce problème, le pipeline de données peut être considéré comme un problème producteur-consommateur. Le pipeline de données génère de petits lots de données et les écrit dans des tampons limités. Le modèle/GPU consomme des mini-lots de données du tampon, effectue des calculs avant/arrière et met à jour les pondérations du modèle. Si le pipeline de données peut générer de petits lots de données aussi rapidement que le modèle/GPU le consomme, le processus de formation sera très efficace.
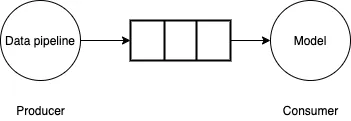 Pictures
Pictures
2. API Tensorflow tf.data
L'API Tensorflow tf.data fournit un riche ensemble de fonctionnalités qui peuvent être utilisées pour créer efficacement des pipelines de données, en utilisant des threads d'arrière-plan pour obtenir de petits lots de données, de sorte que le modèle n'a pas besoin d'attendre. La pré-récupération des données ne suffit pas. Si la génération de petits lots de données est plus lente que le GPU ne peut consommer les données, vous devez alors utiliser la parallélisation pour accélérer la lecture et la transformation des données. À cette fin, Tensorflow fournit une fonctionnalité d'entrelacement pour exploiter plusieurs threads pour lire des données en parallèle, et une fonctionnalité de mappage parallèle pour utiliser plusieurs threads pour transformer de petits lots de données.
Étant donné que ces API sont basées sur le multi-threading, elles peuvent être restreintes par le Python Global Interpreter Lock (GIL). Le GIL de Python limite le bytecode à un seul thread exécuté à la fois. Si vous utilisez du code TensorFlow pur dans votre pipeline, vous ne souffrez généralement pas de cette limitation car le moteur d'exécution principal de TensorFlow fonctionne en dehors de la portée du GIL. Cependant, si la bibliothèque tierce utilisée ne lève pas les restrictions GIL ou utilise Python pour effectuer un grand nombre de calculs, il n'est pas possible de s'appuyer sur le multithread pour paralléliser le pipeline
3. pipeline
Considérez la fonction génératrice suivante, qui simule le chargement et l'exécution de certains calculs pour générer des mini-lots d'échantillons de données et d'étiquettes.
def data_generator():for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000):passyield (np.random.random((4, 1000000, 3)).astype(np.float32), np.random.random((4, 1)).astype(np.float32))
Ensuite, utilisez le générateur dans un pipeline de formation factice et mesurez le temps moyen nécessaire pour générer des mini-lots de données.
generator_dataset = tf.data.Dataset.from_generator(data_generator,output_types=(tf.float64, tf.float64),output_shapes=((4, 1000000, 3), (4, 1))).prefetch(tf.data.experimental.AUTOTUNE)st = time.perf_counter()times = []for _ in generator_dataset:en = time.perf_counter()times.append(en - st)# 模拟训练步骤time.sleep(0.1)st = time.perf_counter()print(np.mean(times))
Il a été observé que le temps moyen pris était d'environ 0,57 seconde (mesuré sur un ordinateur portable Mac équipé d'un processeur Intel Core i7). S'il s'agissait d'une véritable boucle d'entraînement, l'utilisation du GPU serait assez faible, il ne passerait que 0,1 seconde à effectuer le calcul, puis resterait inactif pendant 0,57 seconde en attendant le prochain lot de données.
Pour accélérer le chargement des données, vous pouvez utiliser un générateur multi-processus.
from multiprocessing import Queue, cpu_count, Processdef mp_data_generator():def producer(q):for _ in range(10):# 模拟获取# 从磁盘/网络time.sleep(0.5)# 模拟计算for _ in range(10000000):passq.put((np.random.random((4, 1000000, 3)).astype(np.float32),np.random.random((4, 1)).astype(np.float32)))q.put("DONE")queue = Queue(cpu_count()*2)num_parallel_processes = cpu_count()producers = []for _ in range(num_parallel_processes):p = Process(target=producer, args=(queue,))p.start()producers.append(p)done_counts = 0while done_counts <p>Maintenant, si l'on mesure le temps passé à attendre le prochain mini-lot de données, on obtient un temps moyen de 0,08 seconde. Presque 7 fois plus rapide, mais idéalement, j'aimerais que ce temps soit proche de 0. </p><p>Si vous l'analysez, vous constaterez qu'un temps considérable est consacré à la préparation de la désérialisation des données. Dans un générateur multi-processus, le processus producteur renvoie de grands tableaux NumPy, qui doivent être préparés puis désérialisés dans le processus principal. Alors, comment améliorer l’efficacité lors du passage de grands tableaux entre les processus ? </p><h2>4. Utilisez Ray pour paralléliser le pipeline de données</h2><p>C'est là que Ray entre en jeu. Ray est un framework permettant d'exécuter l'informatique distribuée en Python. Il est livré avec un magasin d'objets en mémoire partagée pour transférer efficacement des objets entre différents processus. En particulier, les tableaux Numpy du magasin d'objets peuvent être partagés entre les travailleurs sur le même nœud sans aucune sérialisation ni désérialisation. Ray facilite également la mise à l'échelle du chargement des données sur plusieurs machines et l'utilisation d'Apache Arrow pour sérialiser et désérialiser efficacement de grandes baies. </p><p>Ray est livré avec une fonction utilitaire from_iterators qui peut créer des itérateurs parallèles, et les développeurs peuvent l'utiliser pour envelopper la fonction de générateur data_generator. </p><pre class="brush:php;toolbar:false">import raydef ray_generator():num_parallel_processes = cpu_count()return ray.util.iter.from_iterators([data_generator]*num_parallel_processes).gather_async()En utilisant ray_generator, le temps passé à attendre le prochain mini-lot de données a été mesuré à 0,02 seconde, ce qui est 4 fois plus rapide qu'en utilisant un traitement multi-processus.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de la façon d'obtenir le nom de la clé du tableau en utilisant php array_keys()
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?
- 13 distributions de probabilité qu'il faut maîtriser en deep learning
- Comment améliorer les modèles de deep learning à l'aide de petits ensembles de données ?
- Comment utiliser le langage Go pour le développement du deep learning ?