
Maison >Périphériques technologiques >IA >Votre GPU peut-il faire fonctionner de gros modèles tels que Llama 2 ? Essayez-le avec ce projet open source
Votre GPU peut-il faire fonctionner de gros modèles tels que Llama 2 ? Essayez-le avec ce projet open source

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-23 14:29:011494parcourir
À une époque où la puissance de calcul est reine, votre GPU peut-il exécuter de grands modèles (LLM) en douceur ?
Beaucoup de gens ont du mal à donner une réponse exacte à cette question et ne savent pas comment calculer la mémoire GPU. Étant donné que déterminer quels LLM un GPU peut gérer n'est pas aussi simple que de regarder la taille du modèle, les modèles peuvent occuper beaucoup de mémoire lors de l'inférence (cache KV), par exemple llama-2-7b a une longueur de séquence de 1 000 et nécessite 1 Go de mémoire. mémoire supplémentaire. De plus, lors de la formation du modèle, le cache KV, l'activation et la quantification occuperont beaucoup de mémoire.
Nous ne pouvons nous empêcher de nous demander si nous pouvons connaître à l’avance l’utilisation de la mémoire ci-dessus. Ces derniers jours, un nouveau projet est apparu sur GitHub, qui peut vous aider à calculer la quantité de mémoire GPU nécessaire lors de la formation ou de l'inférence de LLM. De plus, avec l'aide de ce projet, vous pouvez également connaître la répartition détaillée de la mémoire et. méthodes d'évaluation. Méthode de quantification, longueur maximale du contexte traité et autres problèmes pour aider les utilisateurs à choisir la configuration GPU qui leur convient.
Adresse du projet : https://github.com/RahulSChand/gpu_poor
Non seulement cela, ce projet est également interactif, comme indiqué ci-dessous, il peut calculer la mémoire GPU requise pour exécuter LLM, c'est aussi simple que de remplir les espaces vides. L'utilisateur n'a qu'à saisir certains paramètres nécessaires, puis cliquer sur le bouton bleu et la réponse apparaîtra.
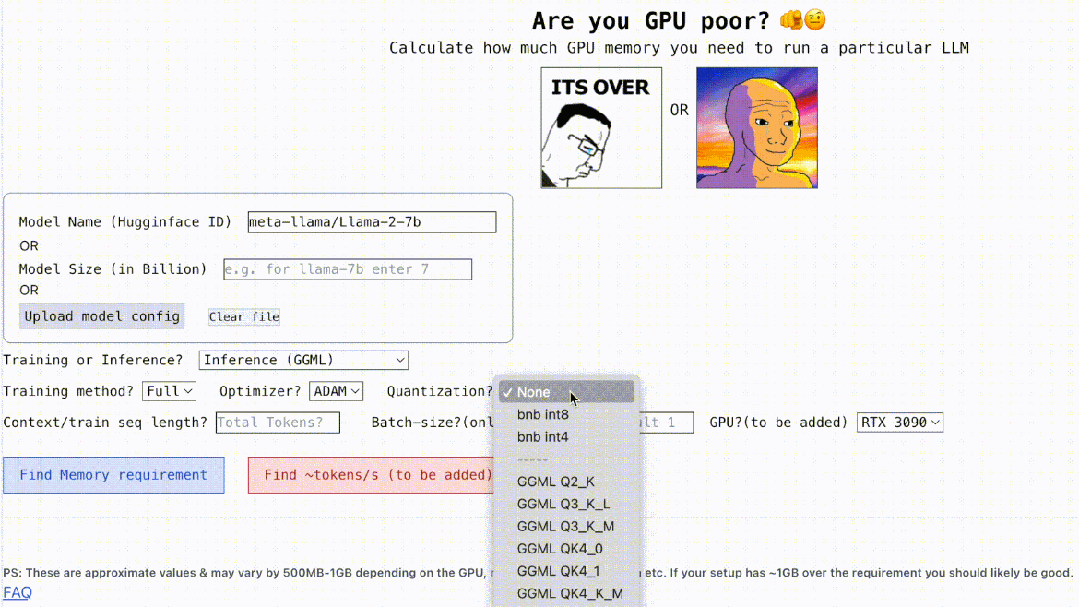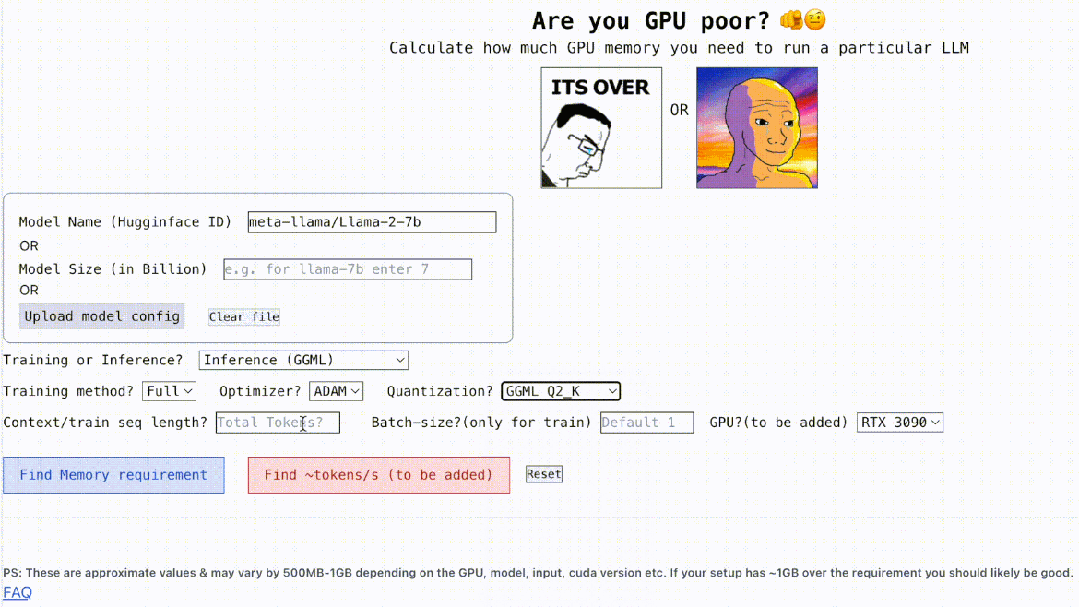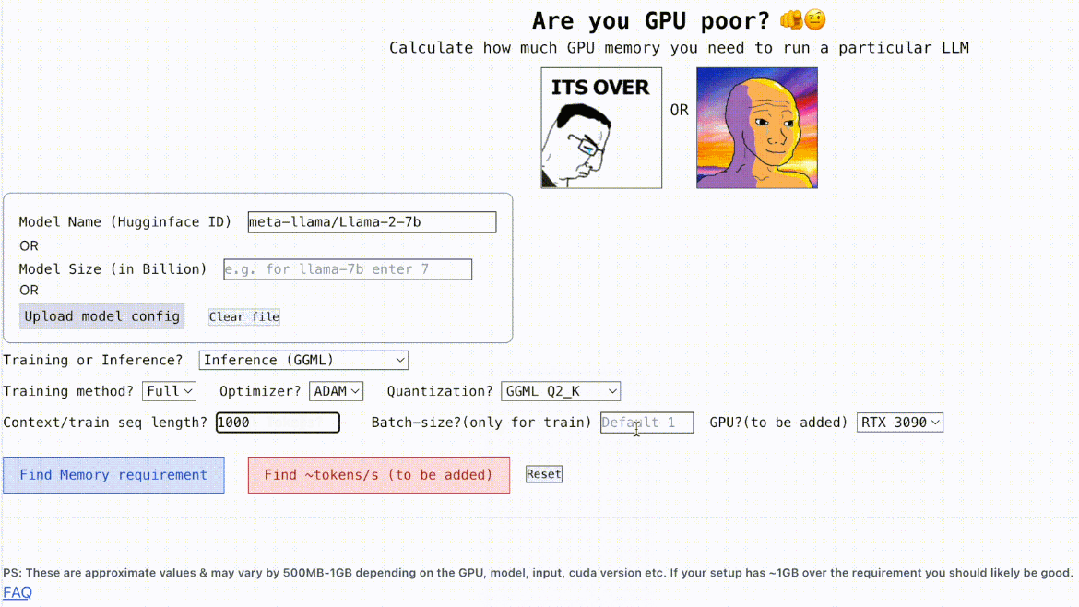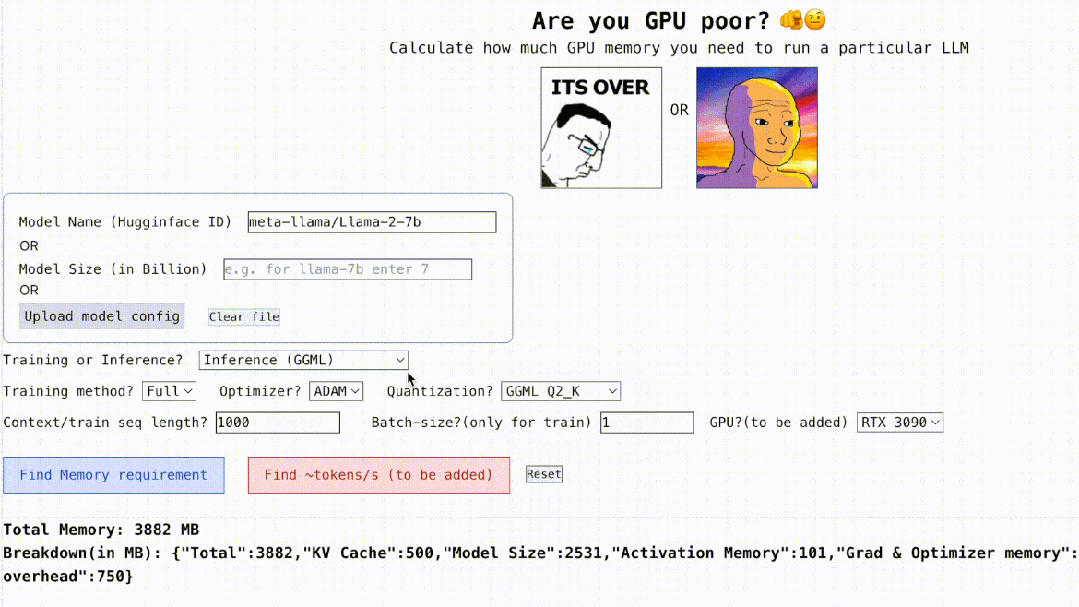
Adresse interactive : https://rahulschand.github.io/gpu_poor/
Le formulaire de sortie final est comme ceci :
{"Total": 4000,"KV Cache": 1000,"Model Size": 2000,"Activation Memory": 500,"Grad & Optimizer memory": 0,"cuda + other overhead":500}
Quant à la raison pour laquelle nous voulons faire ce projet, le l'auteur Rahul Shiv Chand a déclaré qu'il y a les raisons suivantes :
- Quelle méthode de quantification doit être utilisée pour adapter le modèle lors de l'exécution de LLM sur GPU
- Quelle est la longueur maximale du contexte que le GPU peut gérer ;
- Quel type de méthode de réglage fin vous convient le mieux ? Plein ? LoRA ? Ou QLoRA ?
- Quel est le lot maximum pouvant être utilisé lors du réglage fin
- Quelle tâche consomme de la mémoire GPU et comment l'ajuster pour que LLM puisse s'adapter au GPU.
Alors, comment on l'utilise ?
La première étape consiste à traiter le nom du modèle, l'identifiant et la taille du modèle. Vous pouvez saisir l'ID du modèle sur Huggingface (par exemple metal-llama/Llama-2-7b). Actuellement, le projet a codé en dur et enregistré des configurations de modèles pour les 3 000 LLM les plus téléchargés sur Huggingface.
Si vous utilisez un modèle personnalisé ou si l'ID Hugginface n'est pas disponible, vous devez alors télécharger la configuration json (reportez-vous à l'exemple de projet) ou entrez simplement la taille du modèle (par exemple, lama-2-7b fait 7 milliards ).
Vient ensuite la quantification, actuellement le projet prend en charge les bitsandbytes (bnb) int8/int4 et GGML (QK_8, QK_6, QK_5, QK_4, QK_2). Ce dernier n'est utilisé que pour l'inférence, tandis que bnb int8/int4 peut être utilisé à la fois pour la formation et l'inférence.
La dernière étape est l'inférence et la formation. Pendant le processus d'inférence, utilisez l'implémentation de HuggingFace ou utilisez les méthodes vLLM ou GGML pour trouver la vRAM utilisée pour l'inférence pendant le processus de formation, recherchez la vRAM pour un réglage précis ou une utilisation complète du modèle ; LoRA (le projet actuel a été une configuration LoRA codée en dur r=8), QLoRA pour le réglage fin.
Cependant, l'auteur du projet a déclaré que les résultats finaux peuvent varier en fonction du modèle utilisateur, des données d'entrée, de la version CUDA, des outils de quantification, etc. Dans l'expérience, l'auteur a essayé de prendre ces facteurs en considération et de s'assurer que le résultat final se situait dans les 500 Mo. Le tableau ci-dessous permet à l'auteur de recouper l'utilisation de la mémoire des modèles 3b, 7b et 13b fournis sur le site Web par rapport à ce que l'auteur a obtenu sur les GPU RTX 4090 et 2060. Toutes les valeurs sont inférieures à 500 Mo.
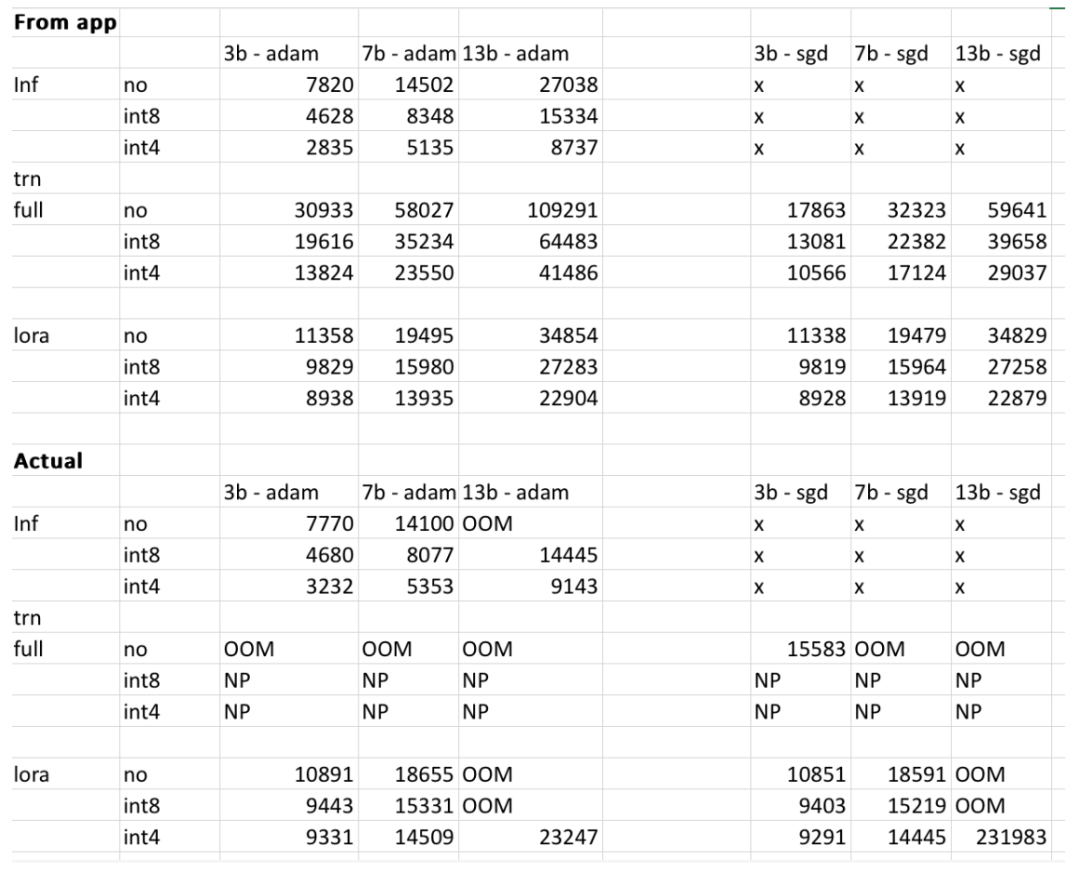
Les lecteurs intéressés peuvent en faire l'expérience par eux-mêmes. Si les résultats donnés sont inexacts, l'auteur du projet a déclaré que le projet sera optimisé et amélioré en temps opportun.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!