
Maison >Périphériques technologiques >IA >Regardons des photos de grands modèles plus efficacement que de taper ! Une nouvelle recherche dans NeurIPS 2023 propose une méthode de requête multimodale, augmentant la précision de 7,8 %
Regardons des photos de grands modèles plus efficacement que de taper ! Une nouvelle recherche dans NeurIPS 2023 propose une méthode de requête multimodale, augmentant la précision de 7,8 %

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-23 11:45:09821parcourir
La capacité à « reconnaître les images » des grands modèles est si forte, pourquoi recherchent-ils toujours les mauvaises choses ?
Par exemple, confondre des chauves-souris avec des chauves-souris qui ne se ressemblent pas, ou ne pas reconnaître des poissons rares dans certains ensembles de données...
En effet, lorsque nous demandons à de grands modèles de "trouver des choses", nous saisissons souvent The is le texte.
Si la description est ambiguë ou trop biaisée, comme « chauve-souris » (chauve-souris ou chauve-souris ?) ou « diable » (Cyprinodon diabolis) , l'IA sera grandement confuse.
Cela conduit au fait que lors de l'utilisation de grands modèles pour effectuer des détection de cibles, en particulier en monde ouvert (scènes inconnues)tâches de détection de cibles, les résultats ne sont souvent pas aussi bons que prévu.
Maintenant, un article inclus dans NeurIPS 2023 résout enfin ce problème.

L'article propose une méthode de détection de cible basée sur une requête multimodaleMQ-Det En ajoutant simplement un exemple d'image à l'entrée, la précision de la recherche d'éléments dans un grand modèle peut être considérablement améliorée.
Sur l'ensemble de données de détection de référence LVIS, sans avoir besoin d'un réglage fin du modèle de tâche en aval, MQ-Detaméliore en moyenne la précision du grand modèle de détection grand public GLIP d'environ 7,8% sur 13 référence. petit échantillon de tâches en aval, l'amélioration moyenne est de 6,3%Précision.
Comment cela se fait-il ? Jetons un coup d'oeil.
Le contenu suivant est reproduit par l'auteur de l'article et blogueur Zhihu @沁园夏 :
Table des matières
- MQ-Det : Un grand modèle de détection de cible en monde ouvert pour les requêtes multimodales
- 1.1 De la requête textuelle à la requête multimodale avec état
- 1.2 Architecture de modèle de requête multimodale plug-and-play MQ-Det
- 1.3 Stratégie de formation efficace MQ-Det
- 1.4 Résultats expérimentaux : évaluation sans réglage fin
- 1.5 Expérimental résultats : évaluation en quelques étapes
- 1.6 Les perspectives de la détection d'objets de requête multimodale
MQ-Det : un grand modèle de détection d'objets en monde ouvert pour les requêtes multimodales
Nom de l'article :Requête multimodale Détection d'objets dans la nature
Lien papier : https://www.php.cn/link/9c6947bd95ae487c81d4e19d3ed8cd6f
Adresse du code : https://www.php.cn/link/2307ac1cfee5db3a 5402aac9db25cc5d

1.1 De la requête textuelle à la requête multi-modalité
Une image vaut mille mots : Avec l'essor de la pré-formation image et texte, avec la sémantique ouverte du texte, la détection de cible entre progressivement en scène de perception du monde ouvert. À cette fin, de nombreux grands modèles de détection suivent le modèle de requête textuelle, qui utilise des descriptions textuelles catégorielles pour interroger des cibles potentielles dans les images cibles. Cependant, cette approche se heurte souvent au problème d’être « large mais imprécise ».
Par exemple, (1) objet à grain fin (espèces de poissons) détection sur la figure 1, il est souvent difficile de décrire diverses espèces de poissons à grain fin avec un texte limité, (2) ambiguïté de catégorie ("chauve-souris" les deux Il peut faire référence à la fois à une batte et à une raquette).
Cependant, les problèmes ci-dessus peuvent être résolus grâce à des exemples d'images. Par rapport au texte, les images peuvent fournir des indices de fonctionnalités plus riches de l'objet cible, mais en même temps, le texte a également une généralisation puissante.
Ainsi, comment combiner organiquement les deux méthodes de requête est devenu une idée naturelle.
Difficulté à obtenir des capacités de requête multimodale : Comment obtenir un tel modèle avec une requête multimodale, il y a trois défis : (1) Un réglage fin direct avec des exemples d'images limités peut facilement conduire à un oubli catastrophique (2) ; ) ) Former un grand modèle de détection à partir de zéro aura une meilleure généralisation mais consommera beaucoup d'argent. Par exemple, former GLIP sur une seule carte nécessite 30 millions de volumes de données pour être formés pendant 480 jours.
Détection de cibles de requêtes multimodales : Sur la base des considérations ci-dessus, l'auteur propose une stratégie de conception et de formation de modèle simple et efficace - MQ-Det.
MQ-Det insère un petit nombre de modules de perception fermée (GCP) sur la base du modèle de détection de requêtes de grand texte gelé existant pour recevoir les entrées d'exemples visuels. En même temps, il conçoit une prédiction de langage de masque de condition visuelle. stratégie de formation pour obtenir efficacement un détecteur A élevé pour les requêtes multimodales performantes.
1.2 Architecture de modèle de requête multimodale plug-and-play MQ-Det
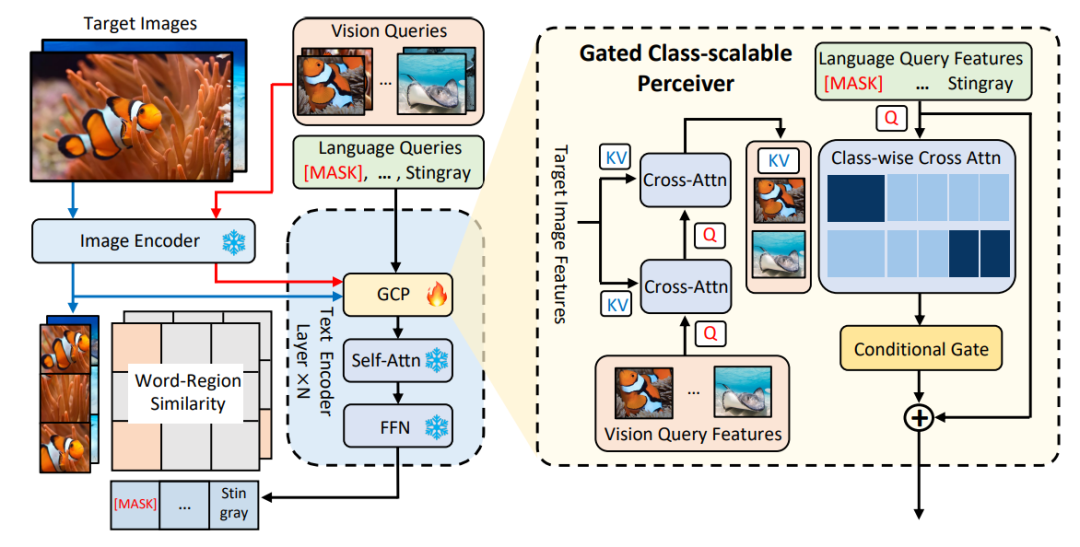
△Figure 1 Schéma d'architecture de la méthode MQ-Det
Module de détection fermée
Comme le montre la figure 1, l'auteur a Le texte L'extrémité de l'encodeur du grand modèle de détection de requête de texte gelé est insérée dans le module de perception fermée (GCP) couche par couche. Le mode de fonctionnement de GCP peut être succinctement exprimé par la formule suivante :
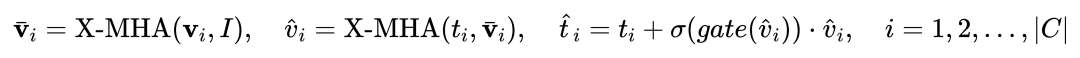
Pour le i-ième. catégorie, entrée L'exemple visuel Vi effectue d'abord une attention croisée (X-MHA) avec l'image cible I pour obtenir 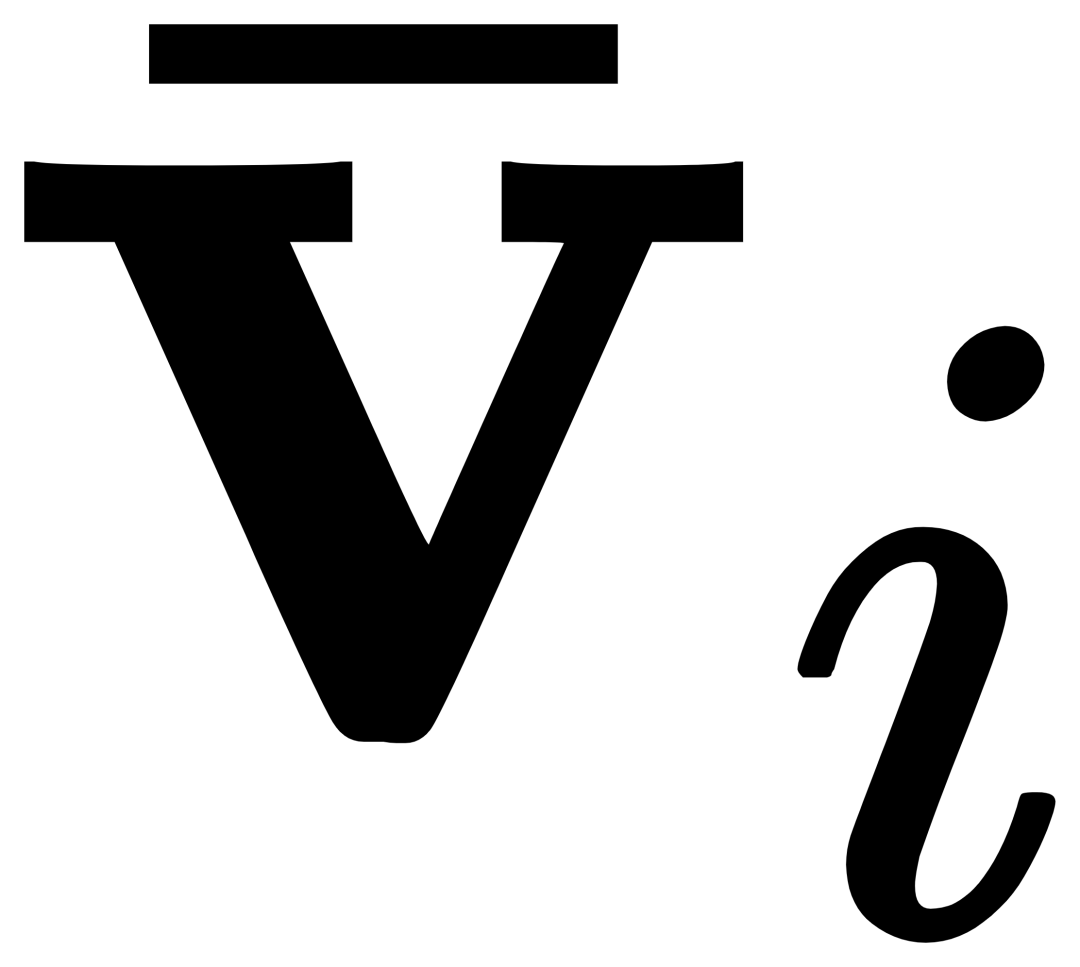 pour améliorer sa capacité de représentation, puis chaque texte de catégorie ti effectuera une attention croisée avec l'exemple visuel
pour améliorer sa capacité de représentation, puis chaque texte de catégorie ti effectuera une attention croisée avec l'exemple visuel 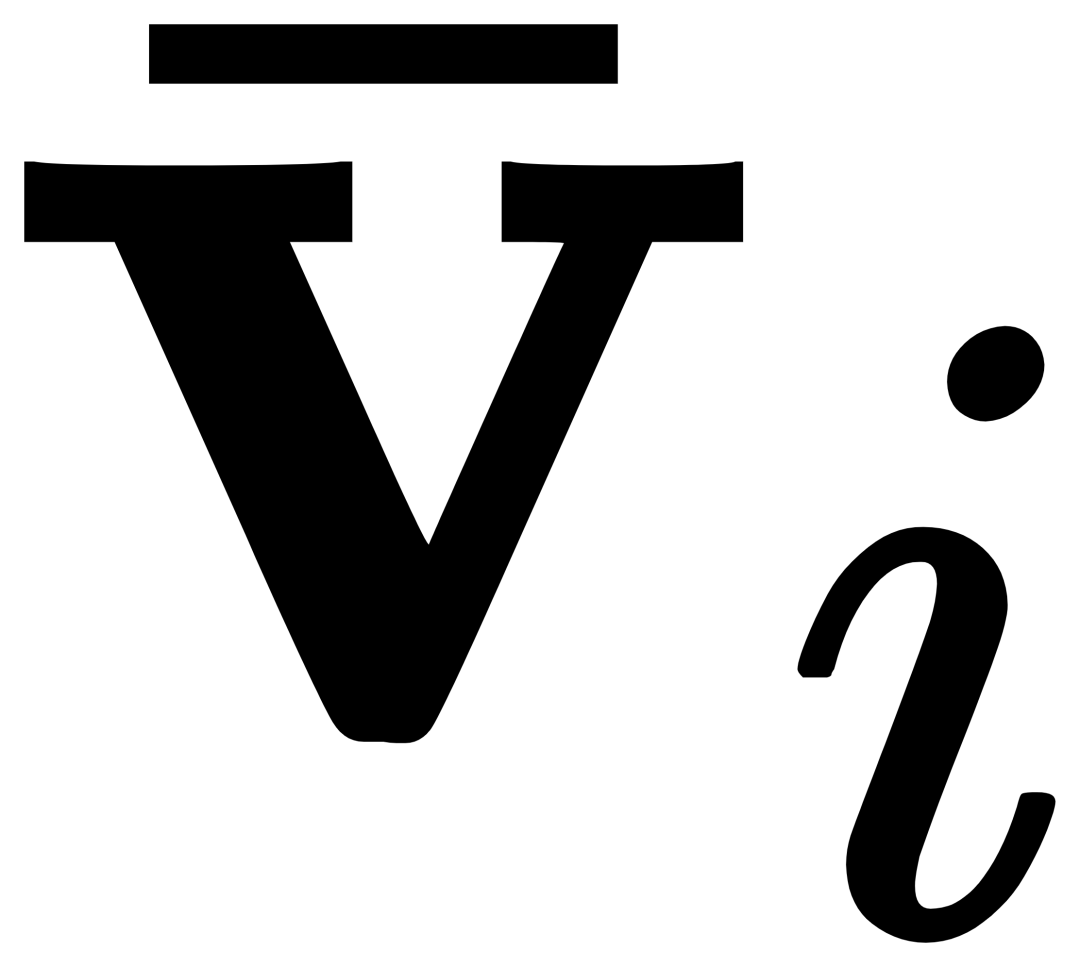 du correspondant catégorie à obtenir
du correspondant catégorie à obtenir 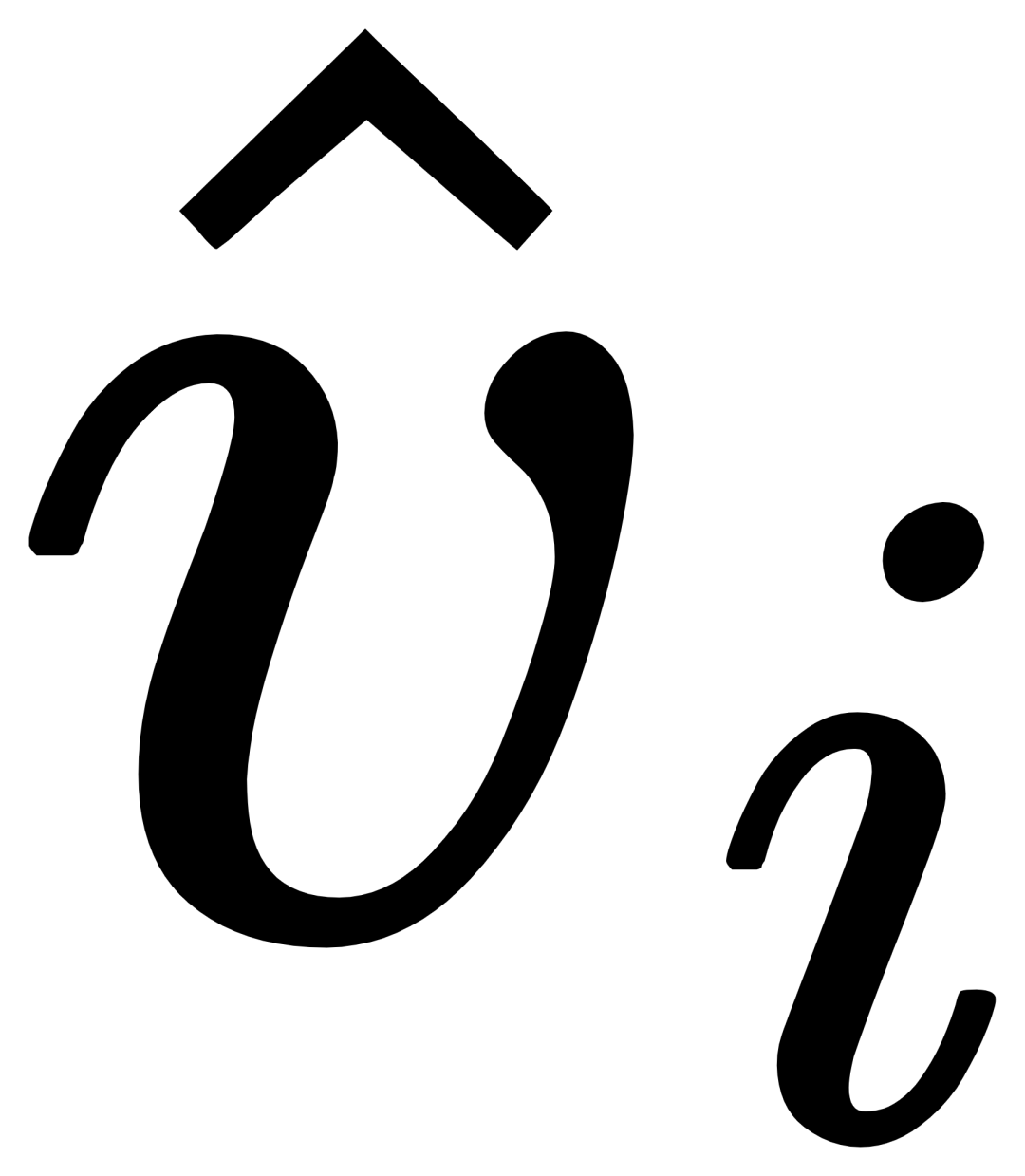 , puis fusionnez le texte original ti et le texte visuellement augmenté
, puis fusionnez le texte original ti et le texte visuellement augmenté 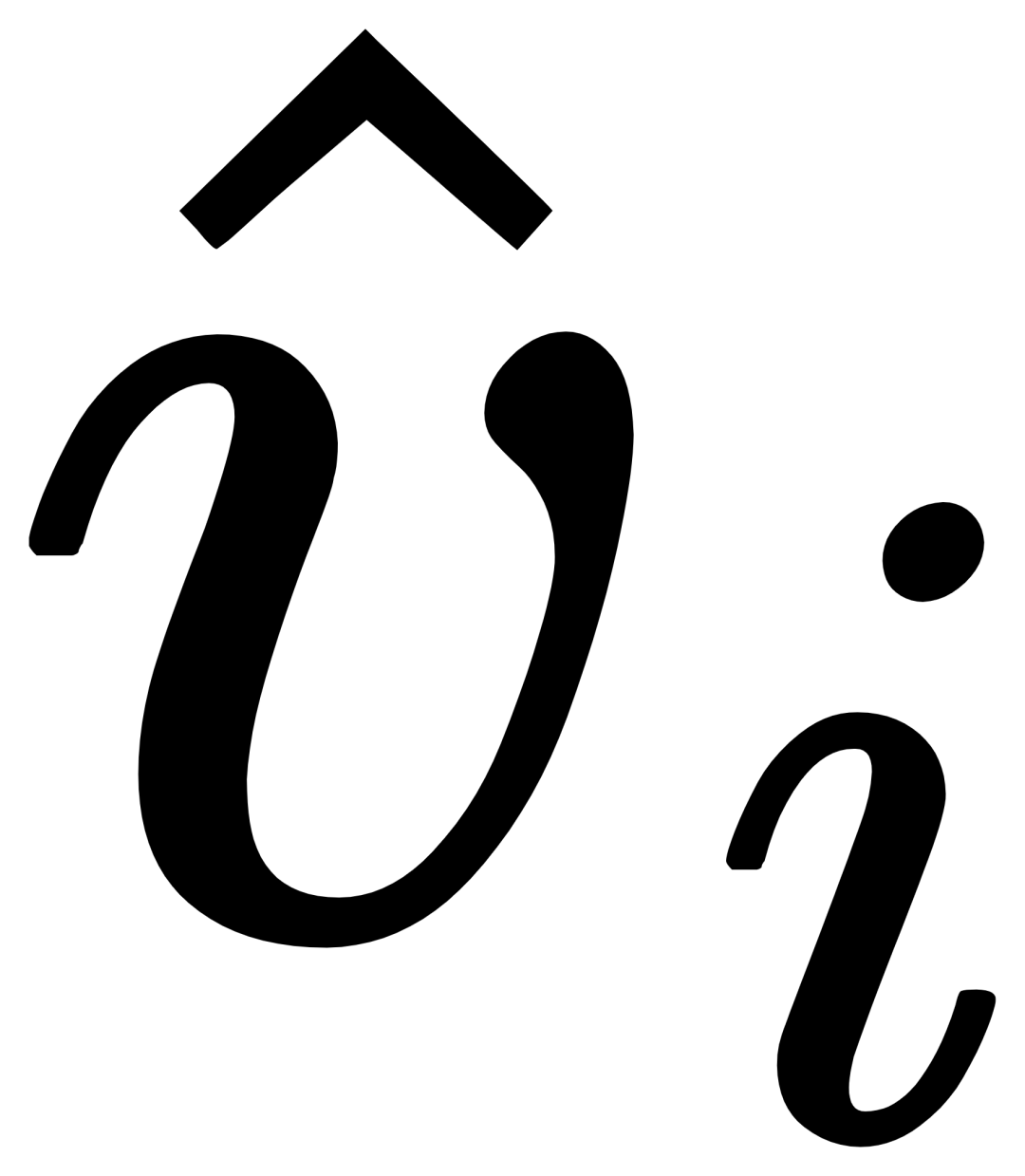 via un module de gate pour obtenir la sortie de la couche actuelle
via un module de gate pour obtenir la sortie de la couche actuelle 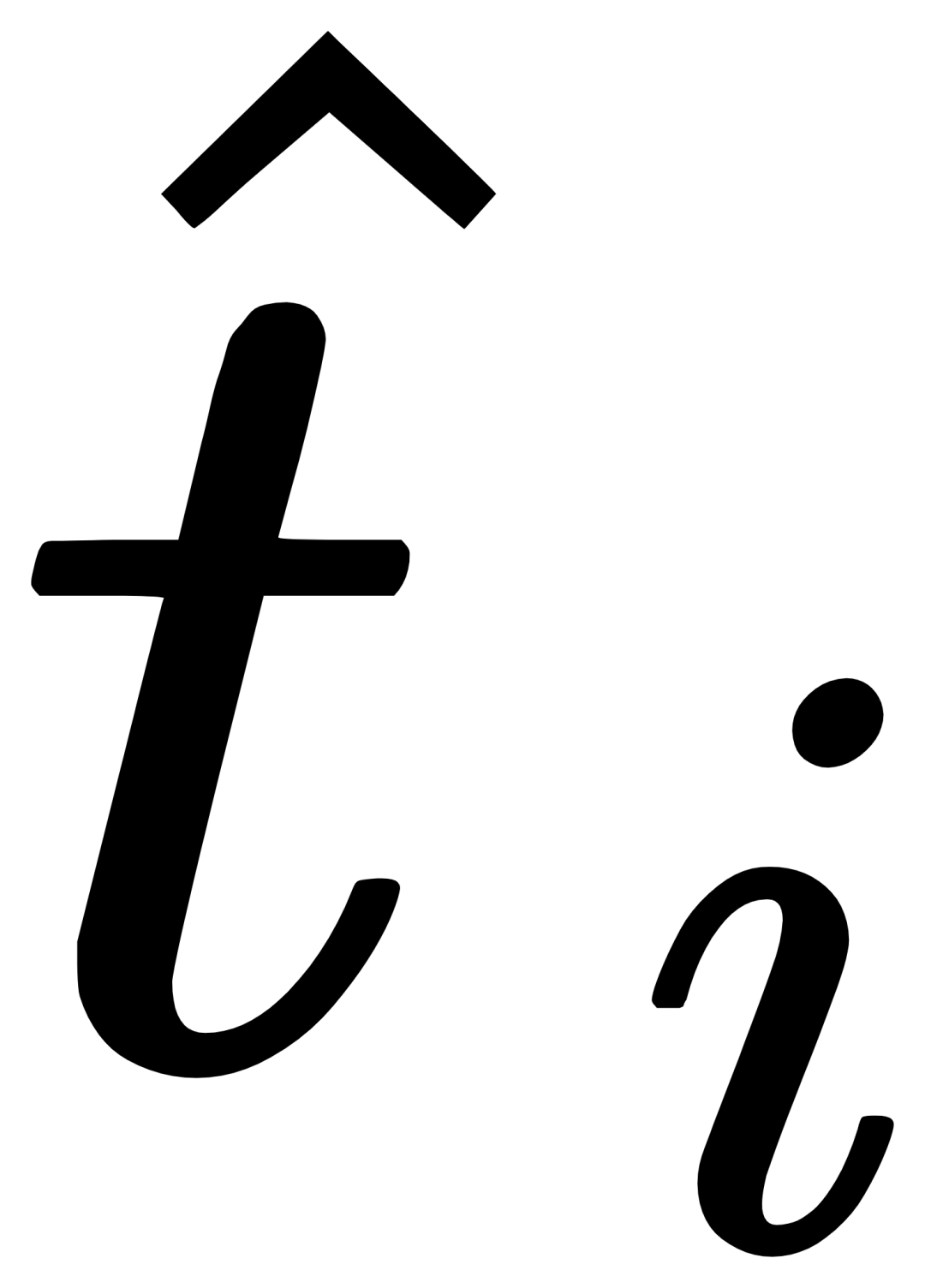 . Une conception aussi simple suit trois principes : (1) évolutivité des catégories ; (2) complétion sémantique (3) anti-oubli. Pour une discussion détaillée, voir le texte original.
. Une conception aussi simple suit trois principes : (1) évolutivité des catégories ; (2) complétion sémantique (3) anti-oubli. Pour une discussion détaillée, voir le texte original.
1.3 Stratégie de formation efficace MQ-Det
Formation de modulation basée sur un détecteur de requêtes linguistiques gelées
Étant donné que le grand modèle actuel de détection pré-entraînée des requêtes de texte lui-même a une bonne généralisation, l'auteur de l'article estime qu'il suffit de faire légers ajustements avec des détails visuels basés sur les caractéristiques du texte original.
Il y a également une démonstration expérimentale spécifique dans l'article qui a révélé qu'un réglage fin après l'ouverture des paramètres du modèle pré-entraîné d'origine peut facilement conduire au problème d'un oubli catastrophique et fait perdre à la place la capacité de détecter le monde ouvert.
Ainsi, MQ-Det peut insérer efficacement des informations visuelles dans le détecteur de requêtes textuelles existantes en modulant uniquement le module GCP entraîné basé sur le détecteur pré-entraîné de requêtes textuelles figées.
Dans l'article, l'auteur applique la conception structurelle et la technologie de formation de MQ-Det aux modèles SOTA actuels GLIP et GroundingDINO respectivement pour vérifier la polyvalence de la méthode.
Stratégie d'entraînement à la prédiction du langage masqué conditionnée par la vision
L'auteur a également proposé une stratégie d'entraînement à la prédiction du langage masqué conditionnée par la vision pour résoudre le problème de l'inertie d'apprentissage causée par le gel du modèle pré-entraîné.
La soi-disant inertie d'apprentissage signifie que le détecteur a tendance à conserver les fonctionnalités de la requête textuelle d'origine pendant le processus de formation, ignorant ainsi les fonctionnalités de requête visuelle nouvellement ajoutées.
À cette fin, MQ-Det remplace aléatoirement les jetons de texte par des jetons [MASK] pendant la formation, obligeant le modèle à apprendre du côté de la fonctionnalité de requête visuelle, c'est-à-dire :
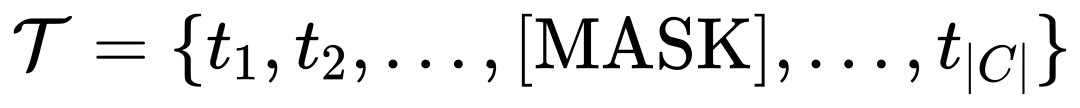
Cette stratégie est simple, mais très efficace. Les résultats expérimentaux montrent que cette stratégie apporte des améliorations significatives des performances.
1.4 Résultats expérimentaux : évaluation sans réglage fin
Sans réglage fin : par rapport à l'évaluation traditionnelle zero-shot (zero-shot) qui utilise uniquement le texte de catégorie pour les tests, MQ-Det propose une stratégie d'évaluation plus réaliste : sans réglage fin. Il est défini comme suit : sans aucun réglage fin en aval, les utilisateurs peuvent utiliser du texte de catégorie, des exemples d'images ou une combinaison des deux pour effectuer la détection d'objets.
Dans le cadre du paramètre sans réglage fin, MQ-Det sélectionne 5 exemples visuels pour chaque catégorie et combine le texte de la catégorie pour la détection de cible. Cependant, d'autres modèles existants ne prennent pas en charge les requêtes visuelles et ne peuvent utiliser que des descriptions en texte brut. Le tableau ci-dessous montre les résultats de détection sur LVIS MiniVal et LVIS v1.0. On peut constater que l’introduction de requêtes multimodales améliore considérablement la capacité de détection de cibles dans le monde ouvert.
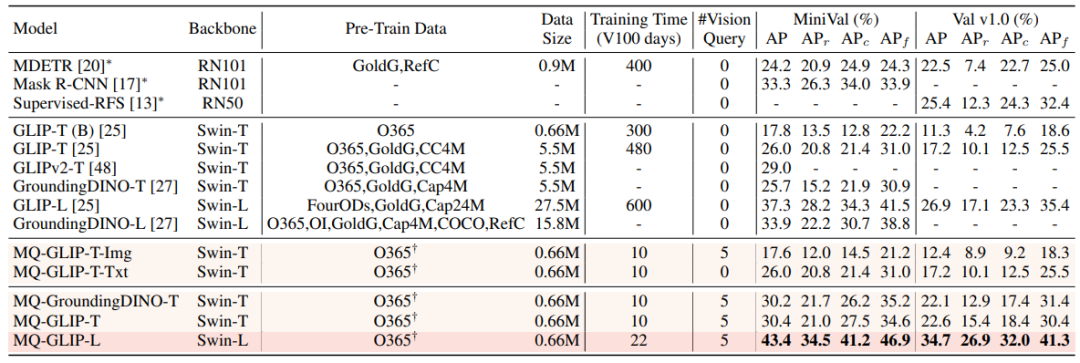
△Tableau 1 Les performances sans réglage fin de chaque modèle de détection dans le cadre de l'ensemble de données de référence LVIS
Comme le montre le tableau 1, MQ-GLIP-L a augmenté l'AP de plus de 7 % sur la base de GLIP-L , et l'effet est très bon !
1.5 Résultats expérimentaux : évaluation de quelques tirs
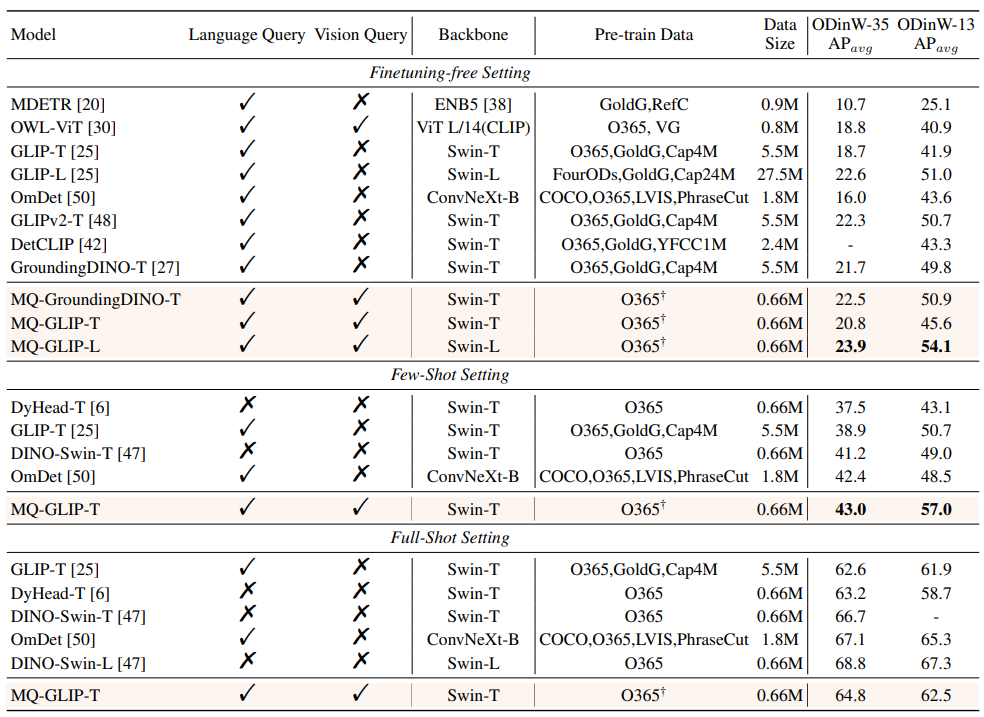
△Tableau 2 Performances de chaque modèle dans 35 tâches de détection ODinW-35 et ses 13 sous-ensembles ODinW-13
L'auteur a également effectué 35 tâches de détection en aval Des expériences complètes ont été menée à ODinW-35. Comme le montre le tableau 2, en plus de ses puissantes performances sans réglage fin, MQ-Det possède également de bonnes capacités de détection de petits échantillons, ce qui confirme encore le potentiel des requêtes multimodales. La figure 2 montre également l'amélioration significative de MQ-Det sur GLIP.
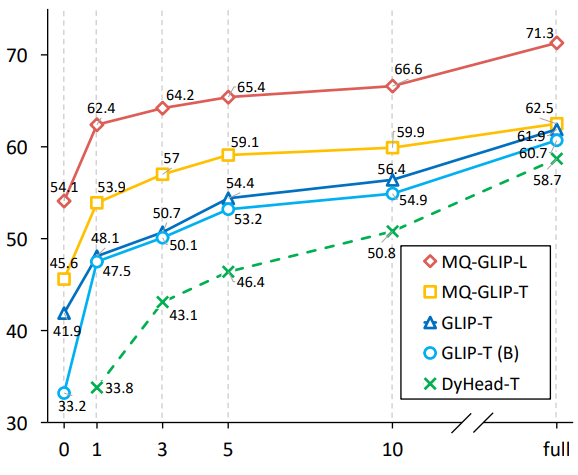
△Figure 2 Comparaison de l'efficacité de l'utilisation des données ; axe horizontal : nombre d'échantillons d'entraînement, axe vertical : AP moyen sur OdinW-13
1.6 La perspective d'une détection de cible de requête multimodale
la détection de cible en tant que méthode pratique application Il s'agit d'un domaine de recherche fondamental et attache une grande importance à la mise en œuvre d'algorithmes.
Bien que les précédents modèles de détection de cibles de requêtes en texte brut aient montré une bonne généralisation, il est difficile pour le texte de couvrir des informations fines dans la détection réelle du monde ouvert, et la riche granularité des informations dans les images complète parfaitement cela.
Jusqu'à présent, nous pouvons constater que le texte est général mais pas précis, et les images sont précises mais pas générales. Si nous pouvons combiner efficacement les deux, c'est-à-dire une requête multimodale, cela fera avancer la détection de cibles dans le monde ouvert.
MQ-Det a franchi la première étape dans les requêtes multimodales, et son amélioration significative des performances montre également l'énorme potentiel de la détection de cibles de requêtes multimodales.
Dans le même temps, l'introduction de descriptions textuelles et d'exemples visuels offre aux utilisateurs plus de choix, rendant la détection de cible plus flexible et conviviale.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les trois modèles de données de la base de données ?
- Quels sont les trois modèles de données de base de données courants ?
- Comment importer la mise en page du modèle CAO
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?