
Maison >Périphériques technologiques >IA >Le robot a appris à faire tourner des stylos et à assietter des noix ! Bénédiction GPT-4, plus la tâche est complexe, meilleures sont les performances
Le robot a appris à faire tourner des stylos et à assietter des noix ! Bénédiction GPT-4, plus la tâche est complexe, meilleures sont les performances

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-23 08:21:281778parcourir

Produit par Big Data Digest
Family, après que l'intelligence artificielle (IA) ait conquis les échecs, Go et Dota, l'habileté de tourner le stylo a également été apprise par les robots IA.

Le robot tourne-stylo mentionné ci-dessus bénéficie d'un agent appelé Eureka, une étude de NVIDIA, de l'Université de Pennsylvanie, du California Institute of Technology et de l'Université du Texas à Austin.
Grâce aux « conseils » d'Eureka, le robot peut également ouvrir des tiroirs et des armoires, lancer et attraper des balles ou utiliser des ciseaux. Selon Nvidia, Eureka se décline en 10 types différents et peut effectuer 29 tâches différentes.
Vous devez savoir qu'avant, la fonction de transfert de stylo ne pouvait pas être réalisée aussi facilement par une programmation manuelle par des experts humains seuls.

Le robot prépare des noix
Et Eureka peut écrire son propre algorithme de récompense pour entraîner le robot, et sa puissance de codage est forte : le programme de récompense auto-écrit surpasse les experts humains dans 83 % des tâches , ce qui rend le robot plus performant. Les performances sont améliorées en moyenne de 52 %.
Eureka a été le pionnier d'une nouvelle façon d'apprendre sans gradient à partir des commentaires humains. Il peut facilement absorber les récompenses et les commentaires textuels fournis par les humains, améliorant ainsi encore son propre mécanisme de génération de récompenses.
Plus précisément, Eureka exploite le GPT-4 d'OpenAI pour écrire des programmes de récompense pour l'apprentissage par essais et erreurs des robots. Cela signifie que le système ne s'appuie pas sur des signaux humains spécifiques à une tâche ou sur des modèles de récompense prédéfinis.
Grâce à la simulation accélérée par GPU dans Isaac Gym, Eureka peut évaluer rapidement les mérites d'un grand nombre de récompenses de candidats, permettant ainsi un entraînement plus efficace. Eureka génère ensuite un résumé des statistiques clés des résultats de la formation et guide le LLM (Language Model) pour améliorer la génération de la fonction de récompense. De cette manière, l’agent IA est capable d’améliorer de manière indépendante ses instructions au robot.
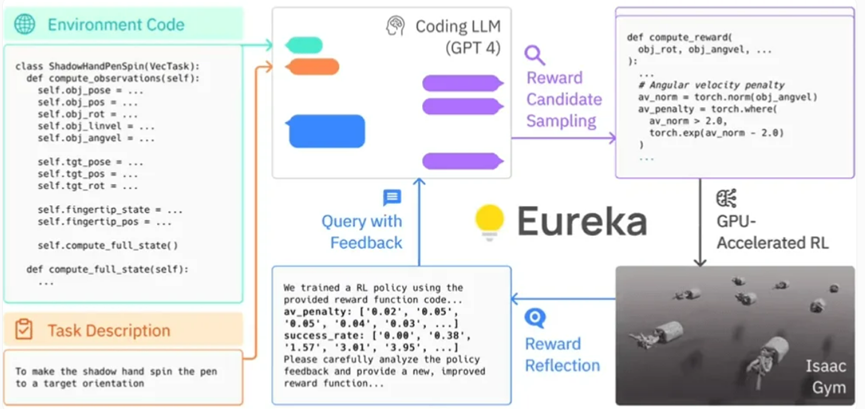
Le cadre d'Eureka
Les chercheurs ont également découvert que plus la tâche était complexe, plus les instructions de GPT-4 surpassaient les instructions humaines des soi-disant « ingénieurs de récompense ». Les chercheurs impliqués dans l’étude ont même qualifié Eureka d’« ingénieur de récompense surhumain ».
Eureka comble avec succès le fossé entre le raisonnement de haut niveau (encodage) et le contrôle moteur de bas niveau. Il utilise ce que l'on appelle une « architecture à gradient hybride » : une boîte noire d'inférence pure LLM (Language Model, modèle de langage) guide un réseau de neurones apprenable. Dans cette architecture, la boucle externe exécute GPT-4 pour optimiser la fonction de récompense (sans gradient), tandis que la boucle interne exécute un apprentissage par renforcement pour entraîner le contrôleur du robot (basé sur un gradient).
- Linxi "Jim" Fan, chercheur scientifique principal chez NVIDIA
Eureka peut intégrer les commentaires humains pour mieux ajuster les récompenses afin de mieux correspondre aux attentes des développeurs. Nvidia appelle ce processus « RLHF en contexte » (Contextual Learning from Human Feedback)
Il convient de noter que l'équipe de recherche de Nvidia a ouvert la bibliothèque d'algorithmes d'IA d'Eureka. Cela permettra aux individus et aux institutions d'explorer et d'expérimenter ces algorithmes via Nvidia Isaac Gym. Isaac Gym est construit sur la plateforme Nvidia Omniverse, un framework de développement permettant de créer des outils et des applications 3D basés sur le framework Open USD.

- Lien papier : https://arxiv.org/pdf/2310.12931.pdf
- Lien du projet : https://eureka-research.github.io/
- Lien code : https://github.com/eureka- Comment évaluez-vous la recherche/Eureka
?
L'apprentissage par renforcement a connu un grand succès au cours de la dernière décennie, mais nous devons reconnaître qu'il reste encore des défis à relever. Bien qu'il y ait eu des tentatives pour introduire des technologies similaires auparavant, par rapport à L2R (Learning to Reward) qui utilise des modèles de langage (LLM) pour aider à la conception des récompenses, Eureka est plus important car il élimine le besoin d'invites spécifiques à une tâche. Ce qui rend Eureka meilleur que L2R, c'est sa capacité à créer des algorithmes de récompense librement exprimés et à exploiter le code source environnemental comme information de base.
L'équipe de recherche de NVIDIA a mené une enquête pour déterminer si l'amorçage avec une fonction de récompense humaine offre certains avantages. Le but de l'expérience est de voir si vous pouvez réussir à remplacer la fonction de récompense humaine d'origine par le résultat de l'itération initiale d'Eureka.
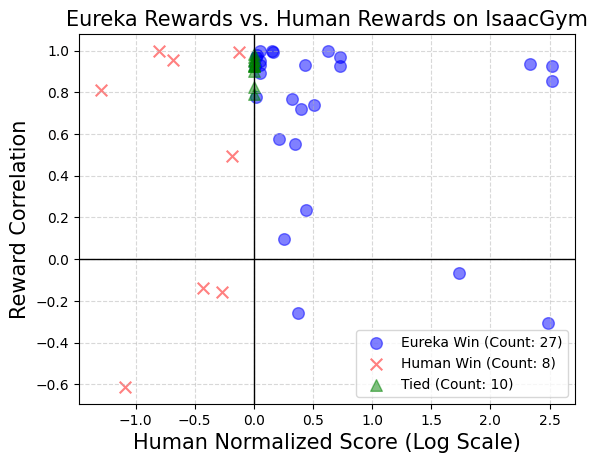
Lors des tests, l'équipe de recherche de NVIDIA a optimisé toutes les fonctions de récompense finale en utilisant le même algorithme d'apprentissage par renforcement et les mêmes hyperparamètres dans le contexte de chaque tâche. Pour tester si ces hyperparamètres spécifiques à une tâche sont bien réglés pour garantir l'efficacité des récompenses artificiellement conçues, ils ont utilisé une mise en œuvre bien réglée de l'optimisation de la politique proximale (PPO) basée sur des travaux antérieurs sans aucune modification. Pour chaque récompense, les chercheurs ont mené cinq sessions de formation PPO indépendantes et ont rapporté la moyenne des valeurs métriques de tâche maximales atteintes aux points de contrôle politique comme mesure de la performance des récompenses.
Les résultats montrent que les concepteurs humains ont souvent une bonne compréhension des variables d'état pertinentes, mais peuvent manquer d'une certaine compétence dans la conception de récompenses efficaces.
Cette recherche révolutionnaire de Nvidia ouvre de nouvelles frontières en matière d'apprentissage par renforcement et de conception de récompenses. Leur algorithme universel de conception de récompenses, Eureka, exploite la puissance des grands modèles de langage et de la recherche évolutive contextuelle pour générer des récompenses au niveau humain dans un large éventail de domaines de tâches robotiques sans avoir besoin d'invites spécifiques à une tâche ou d'intervention humaine, modifiant considérablement notre compréhension de IA et apprentissage automatique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que devez-vous apprendre sur l'intelligence artificielle Python ?
- Quelles sont les principales manifestations de l'intégration de l'intelligence artificielle et de l'éducation ?
- Comment s'appelle l'intelligence artificielle d'Oppo ?
- Le roi du GPT-4 est couronné ! Votre capacité à lire des images et à répondre aux questions est incroyable. Vous pouvez entrer à Stanford par vous-même.
- ChatGPT peut créer des vidéos pour vous ? Le GPT-4 de Microsoft arrive bientôt, sachez tout ce que vous devez savoir