
Maison >Périphériques technologiques >IA >MiniGPT-4 a été mis à niveau vers MiniGPT-v2. Les tâches multimodales peuvent toujours être effectuées sans GPT-4.
MiniGPT-4 a été mis à niveau vers MiniGPT-v2. Les tâches multimodales peuvent toujours être effectuées sans GPT-4.

- PHPzavant
- 2023-10-17 14:41:091516parcourir
Il y a quelques mois, plusieurs chercheurs de KAUST (Université des sciences et technologies King Abdullah, Arabie Saoudite) ont proposé un projet appelé MiniGPT-4 , qui peut fournir une compréhension et un dialogue similaires des images GPT-4. capacités.
Par exemple, MiniGPT-4 peut répondre à la scène de l'image ci-dessous : "L'image décrit un cactus poussant sur un lac gelé. Il y a d'énormes cristaux de glace autour du cactus et il y a des sommets enneigés au loin. ..." Si vous demandez alors si ce scénario pourrait se produire dans le monde réel ? La réponse donnée par MiniGPT-4 est que cette image n’est pas courante dans le monde réel et c’est pourquoi.

Récemment, quelques mois se sont écoulés, l'équipe KAUST et les chercheurs de Meta ont annoncé avoir mis à niveau MiniGPT-4 vers la version MiniGPT-v2.

Adresse papier : https://arxiv.org/pdf/2310.09478.pdf
Page d'accueil papier : https://minigpt-v2.github.io/
Démo : https : //minigpt-v2.github.io/
Plus précisément, MiniGPT-v2 peut servir d'interface unifiée pour mieux gérer diverses tâches visuo-linguistiques. Dans le même temps, cet article recommande d'utiliser des symboles d'identification uniques pour différentes tâches lors de la formation du modèle. Ces symboles d'identification aident le modèle à distinguer facilement chaque instruction de tâche et à améliorer l'efficacité d'apprentissage de chaque modèle de tâche.
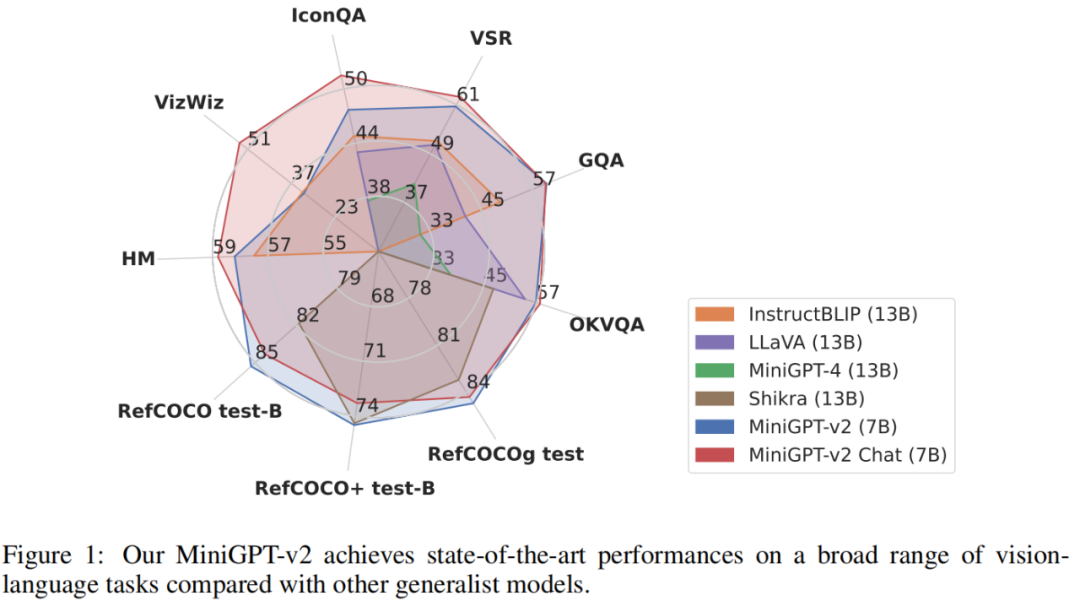
Pour évaluer les performances du modèle MiniGPT-v2, les chercheurs ont mené des expériences approfondies sur différentes tâches de langage visuel. Les résultats montrent que MiniGPT-v2 atteint des performances SOTA ou comparables sur divers benchmarks par rapport aux précédents modèles polyvalents de langage de vision tels que MiniGPT-4, InstructBLIP, LLaVA et Shikra. Par exemple, MiniGPT-v2 surpasse MiniGPT-4 de 21,3 %, InstructBLIP de 11,3 % et LLaVA de 11,7 % sur le benchmark VSR.
Ci-dessous, nous utilisons des exemples spécifiques pour illustrer le rôle des symboles d'identification MiniGPT-v2.
Par exemple, en ajoutant le symbole de reconnaissance [mise à la terre], le modèle peut facilement générer une description d'image avec une connaissance de la localisation spatiale :

En ajoutant le symbole de reconnaissance [détection], le modèle peut directement extraire le texte saisi Objets à l'intérieur et trouver leurs positions spatiales dans l'image :

Encadrer un objet dans l'image En ajoutant [identifier], le modèle peut identifier directement le nom de l'objet :
 . Passez Ajoutez [refer] et une description d'un objet, et le modèle peut directement vous aider à trouver la position spatiale correspondante de l'objet :
. Passez Ajoutez [refer] et une description d'un objet, et le modèle peut directement vous aider à trouver la position spatiale correspondante de l'objet :

Vous pouvez également identifier la correspondance sans ajouter de tâches et avoir une conversation avec la photo :

La perception spatiale du modèle est également devenue plus forte Vous pouvez directement demander au modèle qui apparaît à gauche, au milieu et à droite de la photo :

Introduction à la méthode.
L'architecture du modèle MiniGPT-v2 est présentée dans la figure ci-dessous. Elle se compose de trois parties : l'épine dorsale visuelle, la couche de projection linéaire et le grand modèle de langage.

Squelette visuelle : MiniGPT-v2 utilise EVA comme modèle de base, et la colonne vertébrale visuelle est gelée pendant l'entraînement. Le modèle est formé sur une résolution d'image de 448 x 448 et un codage de position est inséré pour s'adapter à des résolutions d'image plus élevées.
Couche de projection linéaire : cet article vise à projeter tous les jetons visuels du squelette visuel gelé dans l'espace du modèle de langage. Cependant, pour les images à plus haute résolution (par exemple 448 x 448), la projection de tous les jetons d'image entraîne des entrées de séquence très longues (par exemple 1 024 jetons), réduisant considérablement l'efficacité de la formation et de l'inférence. Par conséquent, cet article concatène simplement 4 jetons visuels adjacents dans l'espace d'intégration et les projette ensemble dans une seule intégration dans le même espace de fonctionnalités d'un grand modèle de langage, réduisant ainsi le nombre de jetons d'entrée visuels d'un facteur 4.
Modèle de langage à grande échelle : MiniGPT-v2 utilise le chat open source LLaMA2 (7B) comme épine dorsale du modèle de langage. Dans cette recherche, le modèle de langage est considéré comme une interface unifiée pour diverses entrées de langage visuel. Cet article utilise directement les jetons de langage LLaMA-2 pour effectuer diverses tâches de langage visuel. Pour les tâches de vision de base qui nécessitent de générer des emplacements spatiaux, cet article nécessite directement que le modèle de langage génère des représentations textuelles de cadres de délimitation pour représenter leurs emplacements spatiaux.
Formation d'instructions multitâches
Cet article utilise des instructions symboliques de reconnaissance de tâches pour entraîner le modèle, qui est divisé en trois étapes. Les ensembles de données utilisés à chaque étape de la formation sont présentés dans le tableau 2.

Phase 1 : Pré-formation. Cet article donne un taux d'échantillonnage élevé aux ensembles de données faiblement étiquetés pour obtenir des connaissances plus diversifiées.
Phase 2 : Formation multitâches. Afin d'améliorer les performances de MiniGPT-v2 sur chaque tâche, l'étape actuelle se concentre uniquement sur l'utilisation d'ensembles de données à granularité fine pour entraîner le modèle. Les chercheurs ont exclu les ensembles de données faiblement supervisés tels que GRIT-20M et LAION de l'étape 1 et ont mis à jour le taux d'échantillonnage des données en fonction de la fréquence de chaque tâche. Cette stratégie permet à notre modèle de donner la priorité aux données image-texte alignées de haute qualité, ce qui entraîne des performances supérieures dans une variété de tâches.
Phase 3 : Réglage des instructions multimodales. Par la suite, cet article se concentre sur l’utilisation d’ensembles de données d’instructions plus multimodales pour affiner le modèle et améliorer ses capacités conversationnelles en tant que chatbot.
Enfin, le responsable propose également une démo que les lecteurs peuvent tester. Par exemple, sur le côté gauche de l'image ci-dessous, nous téléchargeons une photo, puis sélectionnons [Détection], puis saisissons « ballon rouge », le modèle. pourra identifier le ballon rouge sur la photo :

Les lecteurs intéressés peuvent consulter la page d'accueil du journal pour plus d'informations.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!