
Maison >Périphériques technologiques >IA >Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?
Qu'est-ce que le NeRF ? La reconstruction 3D basée sur NeRF est-elle basée sur des voxels ?

- PHPzavant
- 2023-10-16 11:33:092009parcourir
1 Introduction
Les champs de rayonnement neuronal (NeRF) sont un paradigme relativement nouveau dans le domaine de l'apprentissage profond et de la vision par ordinateur. La technique a été introduite dans l'article de l'ECCV 2020 « NeRF : Representing Scenes as Neural Radiation Fields for View Synthesis » (qui a remporté le prix du meilleur article), et a depuis explosé en popularité, avec près de 800 citations à ce jour [ 1]. Cette approche marque un changement radical dans la manière traditionnelle dont l’apprentissage automatique traite les données 3D.
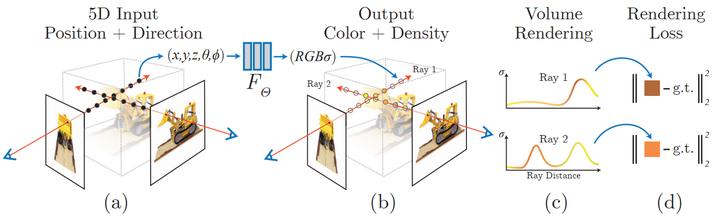
Représentation de la scène du champ de rayonnement neuronal et processus de rendu différenciable :
Synthétisez l'image en échantillonnant les coordonnées 5D (position et direction de visualisation) le long du rayon de la caméra et introduisez ces positions dans un MLP pour produire une densité de couleur et de volume et l'utiliser ; Les techniques de rendu volumique synthétisent ces valeurs dans une image ; la fonction de rendu est différentiable et optimise donc la représentation de la scène en minimisant l'écart résiduel entre l'image synthétisée et l'image réelle observée.
2 Qu'est-ce qu'un NeRF ?
NeRF est un modèle génératif qui génère de nouvelles vues d'une scène 3D à partir d'une image, conditionnée par une image et une pose précise, un processus souvent appelé « synthèse de nouvelles vues ». De plus, il définit également clairement la forme et l'apparence 3D de la scène en tant que fonction continue, qui peut générer des maillages 3D en faisant défiler des cubes. Bien qu’ils apprennent directement à partir des données d’image, ils n’utilisent ni couches convolutionnelles ni transformateurs.
Au fil des années, il existe de nombreuses façons de représenter des données 3D dans les applications d'apprentissage automatique, des voxels 3D aux nuages de points en passant par les fonctions de distance signées. Leur plus grand inconvénient commun est la nécessité de supposer un modèle 3D à l'avance, soit en utilisant des outils tels que la photogrammétrie ou le lidar pour générer des données 3D, soit en créant manuellement le modèle 3D. Cependant, de nombreux types d'objets, tels que les objets hautement réfléchissants, les objets « en forme de grille » ou les objets transparents, ne peuvent pas être numérisés à grande échelle. Les méthodes de reconstruction 3D souffrent également souvent d’erreurs de reconstruction, qui peuvent entraîner des effets d’étape ou une dérive affectant la précision du modèle.
En revanche, NeRF est basé sur le concept de champs de rayons lumineux. Un champ lumineux est une fonction qui décrit comment la transmission de la lumière se produit dans un volume 3D. Il décrit la direction dans laquelle un rayon de lumière se déplace à chaque coordonnée x = (x, y, z) dans l'espace et dans chaque direction d, décrits comme les angles θ et ξ ou vecteurs unitaires. Ensemble, ils forment un espace de fonctionnalités 5D qui décrit la transmission de la lumière dans une scène 3D. Inspiré par cette représentation, NeRF tente d'approcher une fonction qui mappe cet espace à un espace 4D composé de la couleur c = (R, V, B) et de la densité (densité) σ, qui peut être considéré comme cet espace de coordonnées 5D. possibilité que le rayon soit terminé (par exemple par occlusion). Par conséquent, le NeRF standard est une fonction de la forme F : (x, d) -> (c, σ).
L'article NeRF original a paramétré cette fonction à l'aide d'un perceptron multicouche formé sur un ensemble d'images avec des poses connues. Il s'agit d'une méthode d'une classe de techniques appelées reconstruction de scène généralisée, qui vise à décrire des scènes 3D directement à partir d'une collection d'images. Cette approche possède de très belles propriétés :
- Apprendre directement à partir des données
- La représentation continue de la scène permet des structures très fines et complexes telles que des feuilles ou des maillages
- Propriétés physiques implicites telles que la spécularité et la rugosité
- Présenter implicitement le éclairage dans la scène
Depuis lors, une série de documents d'amélioration ont vu le jour, tels que l'apprentissage en quelques plans et en un seul plan [2, 3], la prise en charge des scènes dynamiques [4, 5], l'intégration de la généralisation du champ lumineux pour présenter domaines [6], apprentissage à partir de collections d'images non calibrées sur le Web [7], intégration de données lidar [8], représentation de scènes à grande échelle [9], apprentissage sans réseaux neuronaux [10], etc.
3 Architecture NeRF
Dans l'ensemble, étant donné un modèle NeRF entraîné et une caméra avec des dimensions de pose et d'image connues, nous construisons la scène selon le processus suivant :
- Pour chaque pixel, à partir du centre optique de la caméra, tirez un rayon à travers le scène pour collecter un ensemble d'échantillons à la position (x, d)
- Utiliser le point et la direction de vue (x, d) de chaque échantillon comme entrée pour produire la valeur de sortie (c, σ) (rgbσ)
- Utiliser le classique technologie de rendu de volume pour construire des images
La fonction du champ lumineux (de nombreux documents le traduisent par "champ de rayonnement", mais le traducteur estime que le "champ lumineux" est plus intuitif) n'est qu'un parmi plusieurs composants. Une fois combiné, vous pouvez créer. les effets visuels que vous avez vus dans la vidéo précédente. Dans l'ensemble, cet article comprend les parties suivantes :
- Encodage de position
- approximateur de fonction de champ lumineux (MLP)
- Rendu de volume différentiel (rendu de volume différentiel)
- Échantillonnage stratifié Échantillonnage de volume hiérarchique
Afin de maximiser la clarté de la description, cet article affiche les éléments clés de chaque composant dans le code le plus concis possible. Il est fait référence à l'implémentation originale de bmild et à l'implémentation PyTorch de yenchenlin et krrish94.
3.1 Encodeur de position
Tout comme le modèle de transformateur [11] introduit en 2017, NeRF bénéficie également d'un encodeur de position comme entrée. Il utilise des fonctions haute fréquence pour mapper ses entrées continues dans un espace de dimension supérieure afin d'aider le modèle à apprendre les changements à haute fréquence dans les données, ce qui donne lieu à un modèle plus propre. Cette méthode contourne le biais du réseau neuronal sur les fonctions basse fréquence, permettant ainsi à NeRF de représenter des détails plus clairs. L'auteur fait référence à un article sur ICML 2019 [12].
Si vous êtes familier avec l'encodage positionnel de Transformerd, l'implémentation associée de NeRF est assez standard, avec les mêmes expressions sinus et cosinus alternées. Implémentation de l'encodeur de position :
# pyclass PositionalEncoder(nn.Module):# sine-cosine positional encoder for input points.def __init__( self,d_input: int,n_freqs: int,log_space: bool = False ):super().__init__()self.d_input = d_inputself.n_freqs = n_freqs # 是不是视线上的采样频率?self.log_space = log_spaceself.d_output = d_input * (1 + 2 * self.n_freqs)self.embed_fns = [lambda x: x] # 冒号前面的x表示函数参数,后面的表示匿名函数运算# Define frequencies in either linear or log scaleif self.log_space:freq_bands = 2.**torch.linspace(0., self.n_freqs - 1, self.n_freqs)else:freq_bands = torch.linspace(2.**0., 2.**(self.n_freqs - 1), self.n_freqs)# Alternate sin and cosfor freq in freq_bands:self.embed_fns.append(lambda x, freq=freq: torch.sin(x * freq))self.embed_fns.append(lambda x, freq=freq: torch.cos(x * freq))def forward(self, x) -> torch.Tensor:# Apply positional encoding to input.return torch.concat([fn(x) for fn in self.embed_fns], dim=-1)
Réflexion : Cet encodage de position encode les points d'entrée. Ce point d'entrée est-il un point d'échantillonnage sur la ligne de visée ? Ou un angle de vue différent ? self.n_freqs est-elle la fréquence d'échantillonnage sur la ligne de mire ? À partir de cette compréhension, il devrait s'agir de la position d'échantillonnage sur la ligne de visée, car si la position d'échantillonnage sur la ligne de visée n'est pas codée, ces positions ne peuvent pas être représentées efficacement et leur RGBA ne peut pas être entraîné.
3.2 Fonction de champ de rayonnement
Dans le texte original, la fonction de champ de lumière est représentée par le modèle NeRF. Le modèle NeRF est un perceptron multicouche typique qui prend les points 3D codés et la direction de visualisation en entrée et renvoie les valeurs RGBA. comme sortie. Bien que cet article utilise des réseaux de neurones, n’importe quel approximateur de fonctions peut être utilisé ici. Par exemple, l’article de suivi de Yu et al., Plenoxels, utilise des harmoniques sphériques pour obtenir un entraînement beaucoup plus rapide tout en obtenant des résultats compétitifs [10].
 Photos
Photos
Le modèle NeRF a 8 couches de profondeur et la plupart des couches ont des dimensions de 256. Les connexions restantes sont placées au niveau de la couche 4. Après ces couches, les valeurs RVB et σ sont générées. Les valeurs RVB sont ensuite traitées avec une couche linéaire, puis concaténées avec la direction de visualisation, puis passées à travers une autre couche linéaire et enfin recombinées avec σ en sortie. Implémentation du module PyTorch du modèle NeRF :
class NeRF(nn.Module):# Neural radiance fields module.def __init__( self,d_input: int = 3,n_layers: int = 8,d_filter: int = 256,skip: Tuple[int] = (4,), # (4,)只有一个元素4的元组 d_viewdirs: Optional[int] = None): super().__init__()self.d_input = d_input# 这里是3D XYZ,?self.skip = skip# 是要跳过什么?为啥要跳过?被遮挡?self.act = nn.functional.reluself.d_viewdirs = d_viewdirs# d_viewdirs 是2D方向?# Create model layers# [if_true 就执行的指令] if [if_true条件] else [if_false]# 是否skip的区别是,训练输入维度是否多3维,# if i in skip =if i in (4,),似乎是判断i是否等于4# self.d_input=3 :如果层id=4,网络输入要加3维,这是为什么?第4层有何特殊的?self.layers = nn.ModuleList([nn.Linear(self.d_input, d_filter)] +[nn.Linear(d_filter + self.d_input, d_filter) if i in skip else \ nn.Linear(d_filter, d_filter) for i in range(n_layers - 1)])# Bottleneck layersif self.d_viewdirs is not None:# If using viewdirs, split alpha and RGBself.alpha_out = nn.Linear(d_filter, 1)self.rgb_filters = nn.Linear(d_filter, d_filter)self.branch = nn.Linear(d_filter + self.d_viewdirs, d_filter // 2)self.output = nn.Linear(d_filter // 2, 3) # 为啥要取一半?else:# If no viewdirs, use simpler outputself.output = nn.Linear(d_filter, 4) # d_filter=256,输出是4维RGBAdef forward(self,x: torch.Tensor, # ?viewdirs: Optional[torch.Tensor] = None) -> torch.Tensor: # Forward pass with optional view direction.if self.d_viewdirs is None and viewdirs is not None:raise ValueError('Cannot input x_direction')# Apply forward pass up to bottleneckx_input = x# 这里的x是几维?从下面的分离RGB和A看,应该是4D# 下面通过8层MLP训练RGBAfor i, layer in enumerate(self.layers):# 8层,每一层进行运算x = self.act(layer(x)) if i in self.skip:x = torch.cat([x, x_input], dim=-1)# Apply bottleneckbottleneck 瓶颈是啥?是不是最费算力的模块?if self.d_viewdirs is not None:# 从网络输出分离A,RGB还需要经过更多训练alpha = self.alpha_out(x)# Pass through bottleneck to get RGBx = self.rgb_filters(x) x = torch.concat([x, viewdirs], dim=-1)x = self.act(self.branch(x)) # self.branch shape: (d_filter // 2)x = self.output(x) # self.output shape: (3)# Concatenate alphas to outputx = torch.concat([x, alpha], dim=-1)else:# Simple outputx = self.output(x)return x
Réflexion : Quelles sont les entrées et sorties de cette classe NERF ? Que se passe-t-il à travers ce cours ? Il peut être vu à partir des paramètres de la fonction __init__ qu'elle définit principalement l'entrée, le niveau et la dimension du réseau neuronal d'entrée, c'est-à-dire la position du point de vue et la direction de la ligne de visée, et la sortie est RGBA. Question : la sortie RGBA est-elle d'un point ? Ou s'agit-il d'une série de lignes de mire ? S'il s'agit d'une série, je n'ai pas vu comment le codage de position détermine le RGBA de chaque point d'échantillonnage ? Je n'ai vu aucune instruction comme l'intervalle d'échantillonnage si c'est un point, quel point sur la ligne de visée fait-il ? ce RGBA appartient-il ? Est-ce le point RGBA qui est le résultat d'un ensemble de points d'échantillonnage visuel vus par les yeux ? Il ressort du code de classe NERF que l'entraînement anticipatif multicouche est principalement effectué en fonction de la position du point de vue et de la direction de la ligne de visée. La position du point de vue 5D et la direction de la ligne de visée sont entrées et le RGBA 4D est émis.
3.3 Rendu de volume différentiable
Les points de sortie RGBA sont situés dans l'espace 3D, donc pour les synthétiser en une image, vous devez appliquer l'intégrale de volume décrite dans les équations 1 à 3 de la section 4 de l'article. Essentiellement, une sommation pondérée de tous les échantillons le long de la ligne de visée de chaque pixel est effectuée pour obtenir une valeur de couleur estimée pour ce pixel. Chaque échantillon RVB est pondéré par sa valeur alpha de transparence : des valeurs alpha plus élevées indiquent une plus grande probabilité que la zone échantillonnée soit opaque, et donc les points plus loin le long du rayon sont plus susceptibles d'être obscurcis. L'opération de produit cumulatif garantit que ces points supplémentaires sont supprimés.
Rendu en volume de la sortie du modèle NeRF original :
def raw2outputs(raw: torch.Tensor,z_vals: torch.Tensor,rays_d: torch.Tensor,raw_noise_std: float = 0.0,white_bkgd: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor]:# 将原始的NeRF输出转为RGB和其他映射# Difference between consecutive elements of `z_vals`. [n_rays, n_samples]dists = z_vals[..., 1:] - z_vals[..., :-1]# ?这里减法的意义是啥?dists = torch.cat([dists, 1e10 * torch.ones_like(dists[..., :1])], dim=-1)# 将每个距离乘以其对应方向光线的范数,以转换为真实世界的距离(考虑非单位方向)dists = dists * torch.norm(rays_d[..., None, :], dim=-1)# 将噪声添加到模型对密度的预测中,用于在训练期间规范网络(防止漂浮物伪影)noise = 0.if raw_noise_std > 0.:noise = torch.randn(raw[..., 3].shape) * raw_noise_std# Predict density of each sample along each ray. Higher values imply# higher likelihood of being absorbed at this point. [n_rays, n_samples]alpha = 1.0 - torch.exp(-nn.functional.relu(raw[..., 3] + noise) * dists)# Compute weight for RGB of each sample along each ray. [n_rays, n_samples]# The higher the alpha, the lower subsequent weights are driven.weights = alpha * cumprod_exclusive(1. - alpha + 1e-10)# Compute weighted RGB map.rgb = torch.sigmoid(raw[..., :3])# [n_rays, n_samples, 3]rgb_map = torch.sum(weights[..., None] * rgb, dim=-2)# [n_rays, 3]# Estimated depth map is predicted distance.depth_map = torch.sum(weights * z_vals, dim=-1)# Disparity map is inverse depth.disp_map = 1. / torch.max(1e-10 * torch.ones_like(depth_map),depth_map / torch.sum(weights, -1))# Sum of weights along each ray. In [0, 1] up to numerical error.acc_map = torch.sum(weights, dim=-1)# To composite onto a white background, use the accumulated alpha map.if white_bkgd:rgb_map = rgb_map + (1. - acc_map[..., None])return rgb_map, depth_map, acc_map, weightsdef cumprod_exclusive(tensor: torch.Tensor) -> torch.Tensor:# (Courtesy of https://github.com/krrish94/nerf-pytorch)# Compute regular cumprod first.cumprod = torch.cumprod(tensor, -1)# "Roll" the elements along dimension 'dim' by 1 element.cumprod = torch.roll(cumprod, 1, -1)# Replace the first element by "1" as this is what tf.cumprod(..., exclusive=True) does.cumprod[..., 0] = 1.return cumprod
Question : Quelle est la fonction principale ici ? Qu'est-ce qui a été saisi ? Qu’est-ce que la sortie ?
3.4 Échantillonnage stratifié
La valeur RVB finale captée par la caméra est l'accumulation d'échantillons de lumière le long de la ligne de visée passant par le pixel. La méthode classique de rendu de volume consiste à accumuler des points le long de la ligne de visée, puis à intégrer les éléments. points à chaque point estimation de la probabilité qu'un rayon de lumière se déplace sans heurter aucune particule. Par conséquent, chaque pixel doit échantillonner des points le long du rayon qui le traverse. Pour se rapprocher au mieux de l'intégrale, leur méthode d'échantillonnage stratifié divise uniformément l'espace en N groupes et prélève un échantillon uniformément dans chaque groupe. Plutôt que de simplement prélever des échantillons à intervalles égaux, la méthode d'échantillonnage stratifié permet au modèle d'échantillonner dans un espace continu, conditionnant ainsi le réseau à apprendre sur un espace continu.
Images Échantillonnage hiérarchique implémenté dans PyTorch :
Échantillonnage hiérarchique implémenté dans PyTorch :
def sample_stratified(rays_o: torch.Tensor,rays_d: torch.Tensor,near: float,far: float,n_samples: int,perturb: Optional[bool] = True,inverse_depth: bool = False) -> Tuple[torch.Tensor, torch.Tensor]:# Sample along ray from regularly-spaced bins.# Grab samples for space integration along rayt_vals = torch.linspace(0., 1., n_samples, device=rays_o.device)if not inverse_depth:# Sample linearly between `near` and `far`z_vals = near * (1.-t_vals) + far * (t_vals)else:# Sample linearly in inverse depth (disparity)z_vals = 1./(1./near * (1.-t_vals) + 1./far * (t_vals))# Draw uniform samples from bins along rayif perturb:mids = .5 * (z_vals[1:] + z_vals[:-1])upper = torch.concat([mids, z_vals[-1:]], dim=-1)lower = torch.concat([z_vals[:1], mids], dim=-1)t_rand = torch.rand([n_samples], device=z_vals.device)z_vals = lower + (upper - lower) * t_randz_vals = z_vals.expand(list(rays_o.shape[:-1]) + [n_samples])# Apply scale from `rays_d` and offset from `rays_o` to samples# pts: (width, height, n_samples, 3)pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals[..., :, None]return pts, z_vals
3.5 Échantillonnage de volume hiérarchique (échantillonnage de volume hiérarchique)
Le champ de rayonnement est représenté par deux perceptrons multicouches : l'un fonctionne à un niveau grossier et la scène L’un code des propriétés structurelles étendues ; l’autre affine les détails à un niveau fin, permettant des structures fines et complexes telles que des maillages et des branches. De plus, les échantillons qu'ils reçoivent sont différents, avec des modèles grossiers traitant des échantillons larges, pour la plupart régulièrement espacés tout au long du rayon, tandis que des modèles fins se perfectionnent dans des régions avec des priorités fortes pour obtenir des informations importantes.
这种“珩磨”过程是通过层次体积采样流程完成的。3D空间实际上非常稀疏,存在遮挡,因此大多数点对渲染图像的贡献不大。因此,对具有对积分贡献可能性高的区域进行过采样(oversample)更有好处。他们将学习到的归一化权重应用于第一组样本,以在光线上创建PDF,然后再将inverse transform sampling应用于该PDF以收集第二组样本。该集合与第一集合相结合,并被馈送到精细网络以产生最终输出。
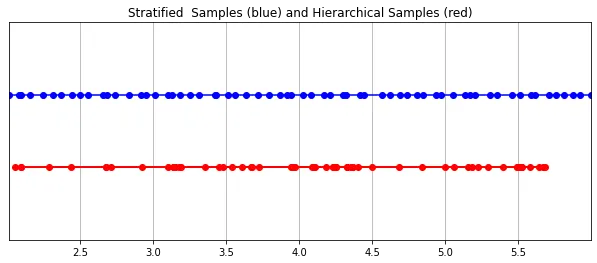
分层采样PyTorch实现:
def sample_hierarchical(rays_o: torch.Tensor,rays_d: torch.Tensor,z_vals: torch.Tensor,weights: torch.Tensor,n_samples: int,perturb: bool = False) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:# Apply hierarchical sampling to the rays.# Draw samples from PDF using z_vals as bins and weights as probabilities.z_vals_mid = .5 * (z_vals[..., 1:] + z_vals[..., :-1])new_z_samples = sample_pdf(z_vals_mid, weights[..., 1:-1], n_samples, perturb=perturb)new_z_samples = new_z_samples.detach()# Resample points from ray based on PDF.z_vals_combined, _ = torch.sort(torch.cat([z_vals, new_z_samples], dim=-1), dim=-1)# [N_rays, N_samples + n_samples, 3]pts = rays_o[..., None, :] + rays_d[..., None, :] * z_vals_combined[..., :, None]return pts, z_vals_combined, new_z_samplesdef sample_pdf(bins: torch.Tensor, weights: torch.Tensor, n_samples: int, perturb: bool = False) -> torch.Tensor:# Apply inverse transform sampling to a weighted set of points.# Normalize weights to get PDF.# [n_rays, weights.shape[-1]]pdf = (weights + 1e-5) / torch.sum(weights + 1e-5, -1, keepdims=True) # Convert PDF to CDF.cdf = torch.cumsum(pdf, dim=-1) # [n_rays, weights.shape[-1]]# [n_rays, weights.shape[-1] + 1]cdf = torch.concat([torch.zeros_like(cdf[..., :1]), cdf], dim=-1) # Take sample positions to grab from CDF. Linear when perturb == 0.if not perturb:u = torch.linspace(0., 1., n_samples, device=cdf.device)u = u.expand(list(cdf.shape[:-1]) + [n_samples]) # [n_rays, n_samples]else:# [n_rays, n_samples]u = torch.rand(list(cdf.shape[:-1]) + [n_samples], device=cdf.device) # Find indices along CDF where values in u would be placed.u = u.contiguous() # Returns contiguous tensor with same values.inds = torch.searchsorted(cdf, u, right=True) # [n_rays, n_samples]# Clamp indices that are out of bounds.below = torch.clamp(inds - 1, min=0)above = torch.clamp(inds, max=cdf.shape[-1] - 1)inds_g = torch.stack([below, above], dim=-1) # [n_rays, n_samples, 2]# Sample from cdf and the corresponding bin centers.matched_shape = list(inds_g.shape[:-1]) + [cdf.shape[-1]]cdf_g = torch.gather(cdf.unsqueeze(-2).expand(matched_shape), dim=-1,index=inds_g)bins_g = torch.gather(bins.unsqueeze(-2).expand(matched_shape), dim=-1, index=inds_g)# Convert samples to ray length.denom = (cdf_g[..., 1] - cdf_g[..., 0])denom = torch.where(denom <h3>4 Training</h3><p>论文中训练NeRF推荐的每网络8层、每层256维的架构在训练过程中会消耗大量内存。缓解这种情况的方法是将前传(forward pass)分成更小的部分,然后在这些部分上积累梯度。注意与minibatching的区别:梯度是在采样光线的单个小批次上累积的,这些光线可能已经被收集成块。如果没有论文中使用的NVIDIA V100类似性能的GPU,可能必须相应地调整块大小以避免OOM错误。Colab笔记本采用了更小的架构和更适中的分块尺寸。</p><p>我个人发现,由于局部极小值,即使选择了许多默认值,NeRF的训练也有些棘手。一些有帮助的技术包括早期训练迭代和早期重新启动期间的中心裁剪(center cropping)。随意尝试不同的超参数和技术,以进一步提高训练收敛性。</p><h4>初始化</h4><pre class="brush:php;toolbar:false">def init_models():# Initialize models, encoders, and optimizer for NeRF training.encoder = PositionalEncoder(d_input, n_freqs, log_space=log_space)encode = lambda x: encoder(x)# View direction encodersif use_viewdirs:encoder_viewdirs = PositionalEncoder(d_input, n_freqs_views,log_space=log_space)encode_viewdirs= lambda x: encoder_viewdirs(x)d_viewdirs = encoder_viewdirs.d_outputelse:encode_viewdirs = Noned_viewdirs = Nonemodel = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)model.to(device)model_params = list(model.parameters())if use_fine_model:fine_model = NeRF(encoder.d_output, n_layers=n_layers, d_filter=d_filter, skip=skip,d_viewdirs=d_viewdirs)fine_model.to(device)model_params = model_params + list(fine_model.parameters())else:fine_model = Noneoptimizer= torch.optim.Adam(model_params, lr=lr)warmup_stopper = EarlyStopping(patience=50)return model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper
训练
def train():# Launch training session for NeRF.# Shuffle rays across all images.if not one_image_per_step:height, width = images.shape[1:3]all_rays = torch.stack([torch.stack(get_rays(height, width, focal, p), 0) for p in poses[:n_training]], 0)rays_rgb = torch.cat([all_rays, images[:, None]], 1)rays_rgb = torch.permute(rays_rgb, [0, 2, 3, 1, 4])rays_rgb = rays_rgb.reshape([-1, 3, 3])rays_rgb = rays_rgb.type(torch.float32)rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0train_psnrs = []val_psnrs = []iternums = []for i in trange(n_iters):model.train()if one_image_per_step:# Randomly pick an image as the target.target_img_idx = np.random.randint(images.shape[0])target_img = images[target_img_idx].to(device)if center_crop and i = rays_rgb.shape[0]:rays_rgb = rays_rgb[torch.randperm(rays_rgb.shape[0])]i_batch = 0target_img = target_img.reshape([-1, 3])# Run one iteration of TinyNeRF and get the rendered RGB image.outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)# Backprop!rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, target_img)loss.backward()optimizer.step()optimizer.zero_grad()psnr = -10. * torch.log10(loss)train_psnrs.append(psnr.item())# Evaluate testimg at given display rate.if i % display_rate == 0:model.eval()height, width = testimg.shape[:2]rays_o, rays_d = get_rays(height, width, focal, testpose)rays_o = rays_o.reshape([-1, 3])rays_d = rays_d.reshape([-1, 3])outputs = nerf_forward(rays_o, rays_d, near, far, encode, model, kwargs_sample_stratified=kwargs_sample_stratified, n_samples_hierarchical=n_samples_hierarchical, kwargs_sample_hierarchical=kwargs_sample_hierarchical, fine_model=fine_model, viewdirs_encoding_fn=encode_viewdirs, chunksize=chunksize)rgb_predicted = outputs['rgb_map']loss = torch.nn.functional.mse_loss(rgb_predicted, testimg.reshape(-1, 3))val_psnr = -10. * torch.log10(loss)val_psnrs.append(val_psnr.item())iternums.append(i)# Check PSNR for issues and stop if any are found.if i == warmup_iters - 1:if val_psnr <h4>训练</h4><pre class="brush:php;toolbar:false"># Run training session(s)for _ in range(n_restarts):model, fine_model, encode, encode_viewdirs, optimizer, warmup_stopper = init_models()success, train_psnrs, val_psnrs = train()if success and val_psnrs[-1] >= warmup_min_fitness:print('Training successful!')breakprint(f'Done!')5 Conclusion
辐射场标志着处理3D数据的方式发生了巨大变化。NeRF模型和更广泛的可微分渲染正在迅速弥合图像创建和体积场景创建之间的差距。虽然我们的组件可能看起来非常复杂,但受vanilla NeRF启发的无数其他方法证明,基本概念(连续函数逼近器+可微分渲染器)是构建各种解决方案的坚实基础,这些解决方案可用于几乎无限的情况。
原文:NeRF From Nothing: A Tutorial with PyTorch | Towards Data Science
原文链接:https://mp.weixin.qq.com/s/zxJAIpAmLgsIuTsPqQqOVg
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Exemple de tutoriel sur l'utilisation de base64 pour améliorer les effets visuels
- Comment exporter un modèle dans Navicat
- Dans le modèle de référence ISO/OSI, quelles sont les principales fonctions de la couche réseau ?
- Technologie de vision industrielle et d'apprentissage profond en PHP
- Un article pour comprendre la vision par ordinateur, plein d'informations utiles