
Maison >Périphériques technologiques >IA >La percée du modèle 3D de Vincent ! MVDream arrive, générant des modèles 3D ultra réalistes en une phrase
La percée du modèle 3D de Vincent ! MVDream arrive, générant des modèles 3D ultra réalistes en une phrase

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-11 11:37:011683parcourir
C'est incroyable !
Vous pouvez désormais créer facilement de superbes modèles 3D de haute qualité en quelques mots ?
Non, un blog étranger a déclenché Internet et nous a présenté quelque chose appelé MVDream.
Les utilisateurs peuvent créer un modèle 3D réaliste en quelques mots.

Et ce qui est différent d'avant, c'est que MVDream semble vraiment « comprendre » la physique.
Voyons à quel point ce MVDream est incroyable~
MVDream
Le petit frère a dit qu'à l'ère des grands modèles, nous avons vu trop de modèles de génération de texte et de modèles de génération d'images. Et les performances de ces modèles deviennent de plus en plus puissantes.
Nous avons ensuite assisté de nos propres yeux à la naissance du modèle vidéo Vincent, et bien sûr du modèle 3D que nous allons mentionner aujourd'hui
Imaginez qu'en tapant simplement une phrase, vous puissiez générer un objet qui ressemble comme s'il existe dans le monde réel, le modèle contient même tous les détails nécessaires, comme c'est cool une telle scène
Et ce n'est certainement pas une tâche facile, surtout lorsque l'utilisateur doit générer un modèle avec suffisamment de détails réalistes.
Jetons d'abord un coup d'oeil à l'effet ~

Sous la même invite, ce qui est montré à l'extrême droite est le produit fini de MVDream
L'écart entre les 5 Les modèles sont visibles à l’œil nu. Les premiers modèles violent complètement les faits objectifs et ne sont corrects que sous certains angles.
Par exemple, dans les quatre premières images, le modèle généré a en réalité plus de deux oreilles. Bien que la quatrième image semble plus détaillée, lorsqu'on la tourne sous un certain angle, on peut constater que le visage du personnage est concave, avec une oreille collée dessus.
Qui sait ? L'éditeur s'est immédiatement souvenu de la vue de face de Peppa Pig, qui était très populaire auparavant.

C'est une situation qui vous est montrée sous certains angles, mais elle ne doit pas être vue sous d'autres angles, elle mettra la vie en danger
Le modèle généré de MVDream à l'extrême droite est évidemment pas pareil. Quelle que soit la façon dont le modèle 3D est tourné, vous ne ressentirez rien d’extraordinaire.
C'est ce qui a été mentionné précédemment, MVDream connaît bien les connaissances en physique et ne créera pas de choses étranges pour s'assurer que chaque vue a deux oreilles
Le petit frère a souligné que juger un modèle 3D est la clé du succès est d'observer si les différentes perspectives sont réalistes et de haute qualité
, et également de s'assurer que le modèle est spatialement cohérent, pas comme le modèle à oreilles multiples ci-dessus.
L'une des principales méthodes de génération de modèles 3D consiste à simuler la perspective de la caméra, puis à générer ce qui peut être vu depuis une certaine perspective.
En d’autres termes, cela s’appelle le levage 2D. Cela signifie assembler différentes perspectives pour former le modèle 3D final.
La situation multi-oreilles ci-dessus se produit parce que le modèle génératif ne saisit pas complètement les informations de forme de l'objet entier dans l'espace tridimensionnel. Et MVDream n’est qu’un grand pas en avant à cet égard.
Ce nouveau modèle résout le problème de cohérence précédent en perspective 3D
Échantillonnage par distillation fractionnée
Cette méthode est appelée échantillonnage par distillation fractionnée et a été développée par DreamFusion The
Avant de commencer à apprendre la distillation fractionnée technique d'échantillonnage, nous devons d'abord comprendre l'architecture adoptée par cette méthode
En d'autres termes, il ne s'agit en fait que d'un autre modèle de diffusion d'image bidimensionnel, similaire aux modèles DALLE, MidJourney et Stable Diffusion
Plus précisément, tout part du modèle DreamBooth pré-entraîné. DreamBooth est un modèle open source basé sur des graphiques bruts de diffusion stable.
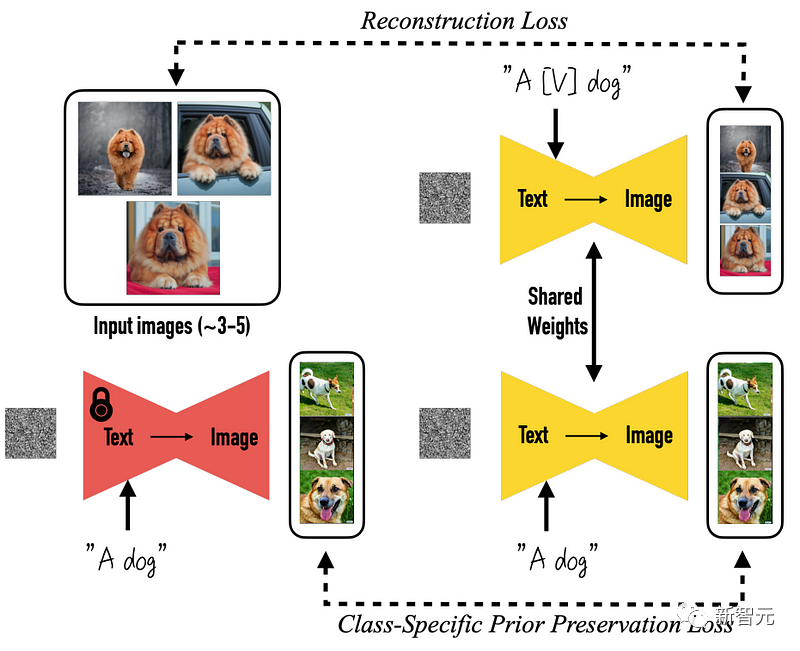
Des changements arrivent, ce qui signifie que les choses ont changé
Ce que l'équipe de recherche a ensuite fait, c'est de restituer directement un ensemble d'images multi-vues au lieu de simplement restituer une seule image. Cette étape nécessite un rendu tridimensionnel. des ensembles de données de divers objets peuvent être complétés.
Ici, les chercheurs ont pris plusieurs vues d'un objet 3D à partir d'un ensemble de données, les ont utilisées pour entraîner un modèle, puis l'ont utilisé pour générer ces vues à l'envers.
La méthode spécifique consiste à changer le bloc d'auto-attention bleu dans l'image ci-dessous en un bloc d'auto-attention tridimensionnel, c'est-à-dire que les chercheurs n'ont besoin que d'ajouter une dimension pour reconstruire plusieurs images au lieu d'une. image.
Dans l'image ci-dessous, nous pouvons voir que la caméra et le pas de temps sont entrés dans le modèle pour chaque vue afin d'aider le modèle à comprendre quelle image sera utilisée où et quel type de vue doit être généré
Désormais, toutes les images sont connectées entre elles et la génération se fait également ensemble. Ils peuvent ainsi partager des informations et mieux comprendre la situation dans son ensemble.
Tout d'abord, le texte est introduit dans le modèle, qui est ensuite entraîné pour reconstruire avec précision les objets à partir de l'ensemble de données
Et c'est là que l'équipe de recherche a appliqué le processus d'échantillonnage par distillation fractionnée multi-vues.
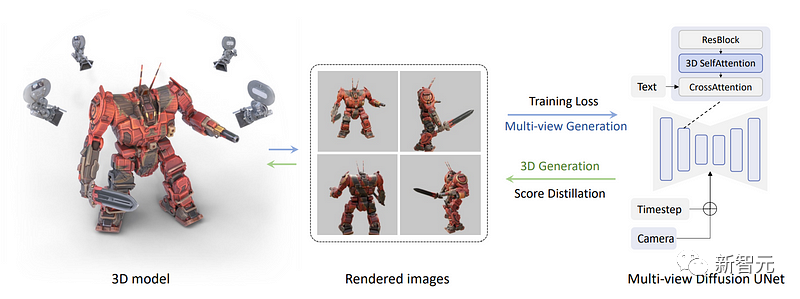
Désormais, avec un modèle de diffusion multi-vues, l'équipe peut générer plusieurs vues d'un objet.
Ensuite, nous devons utiliser ces vues pour reconstruire un modèle tridimensionnel cohérent avec le monde réel, pas seulement des vues
Ici, nous devons utiliser NeRF (champs de rayonnement neuronal, champs de rayonnement neuronal) pour réaliser, comme Identique à DreamFusion mentionné plus tôt.
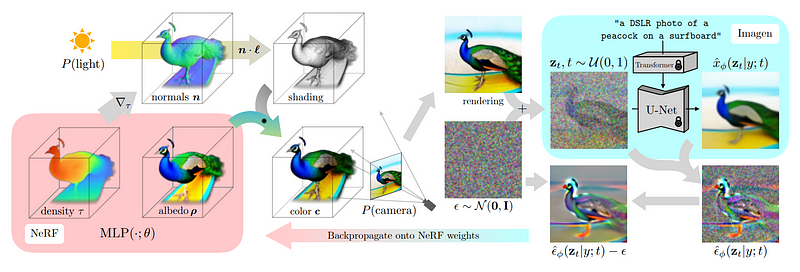
Dans cette étape, notre objectif est de figer le modèle de diffusion multi-vues précédemment formé. En d'autres termes, nous utilisons simplement les images de chaque perspective ci-dessus dans cette étape et ne nous entraînons plus
Guidés par le rendu initial, les chercheurs ont commencé à utiliser un modèle de diffusion multi-vues pour générer des versions d'images initiales bruyantes
Pour que le modèle comprenne que différentes versions de l'image doivent être générées, les chercheurs ont ajouté du bruit tout en étant en mesure de recevoir des informations de fond
Ensuite, ce modèle peut être utilisé pour générer davantage d'images de meilleure qualité
Ajoutez l'image utilisée pour générer cette image et supprimez le bruit que nous avons ajouté manuellement pour utiliser les résultats pour guider et améliorer le modèle NeRF à l'étape suivante.
Pour générer de meilleurs résultats à l'étape suivante, le but de ces étapes est de mieux comprendre sur quelle partie de l'image le modèle NeRF doit se concentrer
Continuez à répéter ce processus jusqu'à ce qu'un modèle 3D satisfaisant soit généré
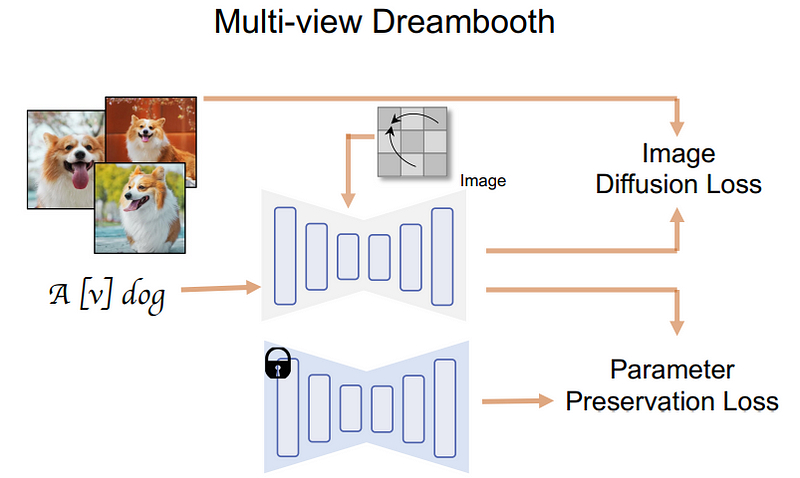
Quant à l'évaluation de la qualité de génération d'images du modèle de diffusion multi-vues et au jugement de la manière dont différentes conceptions affecteront ses performances, voici comment fonctionne l'équipe.
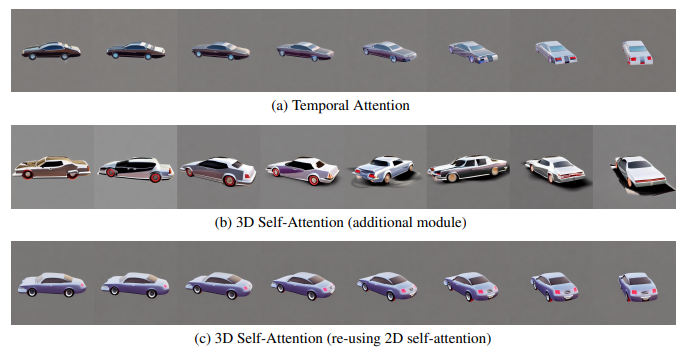
Tout d'abord, ils ont comparé les choix de modules d'attention pour construire des modèles de cohérence multi-vues.
Ces options incluent :
(1) L'auto-attention temporelle unidimensionnelle largement utilisée dans les modèles de diffusion vidéo ;
(2) L'ajout d'un nouveau module d'auto-attention tridimensionnelle aux modèles existants ;
(3) Réutilisez le module d'auto-attention 2D existant pour une attention 3D.
Afin de démontrer avec précision les différences entre ces modules, dans cette expérience, les chercheurs ont utilisé 8 images de changements de perspective à 90 degrés pour entraîner le modèle à correspondre plus étroitement aux paramètres vidéo
Dans l'expérience, l'équipe de recherche simultanément La résolution d'image plus élevée est maintenue, c'est-à-dire 512 × 512 comme le modèle SD d'origine. Comme le montre la figure ci-dessous, les chercheurs ont découvert que même avec des changements de perspective aussi limités dans des scènes statiques, l'auto-attention temporelle est toujours affectée par les changements de contenu et ne peut pas maintenir la cohérence de la perspective.
L'équipe émet l'hypothèse que c'est parce que l'attention temporelle peut n'échangent des informations qu'entre les mêmes pixels dans des images différentes, et lorsque le point de vue change, les pixels correspondants peuvent être éloignés les uns des autres.
D'un autre côté, ajouter une nouvelle attention 3D sans apprendre la cohérence peut entraîner une grave dégradation de la qualité.
Les chercheurs pensent que cela est dû au fait que l'apprentissage de nouveaux paramètres à partir de zéro consommera plus de données et de temps d'entraînement, ce qui n'est pas applicable à cette situation où le modèle tridimensionnel est limité. Ils ont proposé une stratégie pour réutiliser le mécanisme d'auto-attention 2D pour obtenir une cohérence optimale sans dégrader la qualité de la génération
L'équipe a également remarqué que si la taille de l'image est réduite à 256, le nombre de vues est réduit à 4, les différences entre ces modules sera beaucoup plus petit. Cependant, pour obtenir la meilleure cohérence possible, les chercheurs ont fait leurs choix sur la base d’observations préliminaires lors des expériences suivantes.
De plus, les chercheurs ont mis en œuvre un échantillonnage de distillation fractionnée multi-vues dans la bibliothèque threestudio (thr) et ont introduit un guidage de diffusion multi-vues. Cette bibliothèque implémente des méthodes de génération de modèles texte en 3D de pointe dans un cadre unifié
Les chercheurs utilisent le volume implicite dans threestudio pour implémenter la représentation 3D, y compris la multi-résolution. La grille de hachage (hash -grid)
Lors de l'étude de la vue de la caméra, les chercheurs ont échantillonné la caméra exactement de la même manière que lors du rendu de l'ensemble de données 3D
En plus de cela, les chercheurs ont également optimisé le modèle 3D pour 10 000 étapes, en utilisant l'optimiseur AdamW et en réglant le taux d'apprentissage à 0,01
Dans l'échantillonnage de distillation fractionnée, dans les 8000 premières étapes, les pas de temps maximum et minimum étaient de 0,98 pas à 0,5 pas et 0,02 pas
La résolution de départ de le rendu est de 64 × 64, qui augmente progressivement jusqu'à 256 × 256 après 5 000 étapes. synthèse, et grâce à un processus itératif, a créé une méthode de modèle texte en 3D
Cette nouvelle méthode présente actuellement certaines limites. Le problème principal est que la résolution de l'image générée n'est que de 256x256 pixels, ce qui peut être considéré comme étant. très faible
 De plus, les chercheurs ont également souligné que la taille de l'ensemble de données pour effectuer cette tâche doit dans une certaine mesure limiter la polyvalence de cette méthode, car si l'ensemble de données est trop petit, elle ne pourra pas pour refléter notre monde complexe de manière plus réaliste.
De plus, les chercheurs ont également souligné que la taille de l'ensemble de données pour effectuer cette tâche doit dans une certaine mesure limiter la polyvalence de cette méthode, car si l'ensemble de données est trop petit, elle ne pourra pas pour refléter notre monde complexe de manière plus réaliste.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment supprimer les données en double dans Excel pour qu'il n'en reste qu'une seule
- Comment vlookup fait correspondre deux colonnes de données
- Quelle est l'instruction SQL pour créer une base de données ?
- Quelles sont les étapes pour se connecter à la base de données à l'aide de jdbc ?
- Attention des médias américains : combien d'électricité faut-il pour entraîner ChatGPT ?