
Maison >Périphériques technologiques >IA >Explorer l'impact de la sélection du vocabulaire sur la formation des modèles linguistiques : une étude révolutionnaire
Explorer l'impact de la sélection du vocabulaire sur la formation des modèles linguistiques : une étude révolutionnaire

- 王林avant
- 2023-10-04 14:25:011492parcourir
Comment les modèles linguistiques sont-ils affectés par les différentes listes de vocabulaire ? Comment équilibrer ces effets ?
Dans une expérience récente, les chercheurs ont pré-entraîné et affiné 16 modèles de langage avec différents corpus. Cette expérience a utilisé NanoGPT, une architecture à petite échelle (basée sur GPT-2 SMALL), et a entraîné un total de 12 modèles. La configuration de l'architecture réseau de NanoGPT est la suivante : 12 têtes d'attention, 12 couches de transformateurs, la dimension d'intégration des mots est de 768 et environ 400 000 itérations (environ 10 époques) ont été effectuées. Ensuite, 4 modèles ont été formés sur GPT-2 MEDIUM. L'architecture de GPT-2 MEDIUM a été définie sur 16 têtes d'attention, 24 couches de transformateurs, la dimension d'intégration du mot était de 1024 et 600 000 itérations ont été effectuées. Tous les modèles sont pré-entraînés à l'aide des ensembles de données NanoGPT et OpenWebText. En termes de réglage fin, les chercheurs ont utilisé l'ensemble de données d'instructions fourni par baize-chatbot et ont ajouté respectivement 20 000 et 500 000 entrées supplémentaires de « dictionnaire » aux deux types de modèles
À l'avenir, les chercheurs prévoient de publier Modèle de code et de pré-formation, modèle de réglage des instructions et ensemble de données de réglage fin
Cependant, en raison du manque de sponsors GPU (il s'agit d'un projet open source gratuit), afin de réduire les coûts, les chercheurs n'ont pas continué à poursuivre, même s’il reste encore du travail à faire pour améliorer encore l’espace du contenu de la recherche. En phase de pré-formation, ces 16 modèles doivent fonctionner sur 8 GPU pendant un total de 147 jours (un seul GPU doit être utilisé pendant 1 176 jours), pour un coût de 8 000 $ US
Les résultats de la recherche peuvent être résumé comme suit :
- En termes de méthode d'encodage, le vocabulaire TokenMonster (550256-strict-nocapcode) fonctionne mieux que GPT-2 Tokenizer et tiktoken p50k_base sur toutes les métriques.
- La taille optimale du vocabulaire est de 32 000.
- Plus le vocabulaire est simple, plus le modèle convergera rapidement, mais il ne produira pas nécessairement de meilleurs résultats après convergence.
- L'augmentation du ratio de mots (le nombre moyen de caractères correspondant à chaque jeton) n'aura pas d'impact négatif sur la seule qualité du modèle.
- Les vocabulaires avec un seul jeton correspondant à plusieurs mots ont un impact négatif de 5 % sur le benchmark SMLQA (ground Truth), mais un ratio de mots 13 % plus élevé.
- Avec le vocabulaire Capcode, le modèle prend plus de temps à apprendre, mais une fois que le modèle converge, il ne semble pas avoir d'impact sur les benchmarks SMLQA (vérité terrain) ou SQuAD (extraction de données) dans aucune direction.
- La perte de validation et la F1 sont des mesures dénuées de sens lorsque l'on compare différents tokenizers.
- Les défauts et la complexité du tokenizer ont un plus grand impact sur la capacité du modèle à apprendre des faits que sur la capacité du modèle à apprendre un langage.
Selon les résultats expérimentaux, les résultats du code anglais-32000-consistent sont les meilleurs. Cependant, comme mentionné ci-dessus, lors de l'utilisation de TokenMonster où un seul jeton correspond à plusieurs mots, il existe un compromis entre la précision SMLQA (Ground Truth) et le ratio de mots, ce qui augmente la pente de la courbe d'apprentissage. Les chercheurs croient fermement qu'en forçant 80 % des jetons à correspondre à un mot et 20 % des jetons à correspondre à plusieurs mots, ce compromis peut être minimisé et un vocabulaire « le meilleur des deux mondes » peut être obtenu. Les chercheurs estiment que cette méthode a les mêmes performances que la liste de vocabulaire d'un seul mot, tout en améliorant le ratio de mots d'environ 50 %.
Le sens de cette phrase est que les défauts et la complexité du segmenteur de mots ont un plus grand impact sur la capacité du modèle à apprendre des faits que sur sa capacité linguistique
Ce phénomène est une découverte intéressante au cours du processus de formation Caractéristiques, il est logique de réfléchir au fonctionnement de la formation sur modèle. Le chercheur ne dispose d’aucune preuve pour justifier son raisonnement. Mais essentiellement, comme la maîtrise du langage est plus facile à corriger lors de la rétropropagation que la factualité du langage (qui sont extrêmement subtiles et dépendantes du contexte), cela signifie que toute amélioration de l'efficacité du tokenizer sera moins cohérente que la factualité du langage, quel que soit le sexe. , il y aura un effet d’entraînement qui se traduira directement par une meilleure fidélité de l’information, comme le montre le benchmark SMLQA (Ground Truth). En termes simples : un meilleur tokenizer est un modèle plus réaliste, mais pas nécessairement un modèle plus fluide. Inversement : un modèle doté d'un tokenizer inefficace peut toujours apprendre à écrire couramment, mais le coût supplémentaire de la maîtrise réduit la crédibilité du modèle.
L'impact de la taille du vocabulaire
Avant d'effectuer ces tests, les chercheurs pensaient que 32 000 était la taille optimale du vocabulaire, et les résultats expérimentaux l'ont également confirmé. Les performances du modèle équilibré 50256 ne sont que 1 % supérieures à celles du modèle équilibré 32000 sur le benchmark SMLQA (Ground Truth), mais la taille du modèle augmente de 13 %. Afin de prouver clairement ce point de vue, dans de multiples modèles basés sur MEDIUM, cet article a mené des expérimentations en divisant le vocabulaire en 24000, 32000, 50256 et 100256 mots
.L'impact des modes d'optimisation
Les chercheurs ont testé TokenMonster et testé trois modes d'optimisation spécifiques : équilibré, cohérent et strict. Différents modes d'optimisation affecteront la façon dont les signes de ponctuation et les capcodes sont combinés avec les jetons de mots. Les chercheurs avaient initialement prédit que le mode cohérent fonctionnerait mieux (car il est moins complexe), bien que le rapport entre les mots (c'est-à-dire le rapport entre les caractères et les jetons) serait légèrement inférieur.
Les résultats expérimentaux semblent confirmer ce qui précède. conjecture, mais les chercheurs ont également observé certains phénomènes. Premièrement, le mode cohérent semble fonctionner environ 5 % mieux que le mode équilibré sur le benchmark SMLQA (Ground Truth). Cependant, le mode cohérent est nettement moins performant (28 %) sur le benchmark SQuAD (Data Extraction). Cependant, le benchmark SQuAD présente de grandes incertitudes (des exécutions répétées donnent des résultats différents) et n'est pas convaincant. Les chercheurs n’ont pas testé la convergence entre équilibré et cohérent, cela peut donc simplement signifier que le modèle cohérent est plus facile à apprendre. En fait, la cohérence peut donner de meilleurs résultats sur SQuAD (extraction de données) car SQuAD est plus difficile à apprendre et moins susceptible de produire des hallucinations.
C'est une découverte intéressante en soi, car cela signifie qu'il n'y a aucun problème évident à combiner la ponctuation et les mots en un seul jeton. Jusqu'à présent, tous les autres tokeniseurs ont soutenu que la ponctuation devait être séparée des lettres, mais comme vous pouvez le voir dans les résultats ici, les mots et la ponctuation peuvent être fusionnés en un seul jeton sans perte de performances notable. Ceci est également confirmé par 50256-consistent-oneword, une combinaison qui fonctionne à égalité avec 50256-strict-oneword-nocapcode et surpasse p50k_base. 50256-consistent-oneword combine une ponctuation simple avec le mot token (ce que les deux autres combinaisons ne font pas).
Après avoir activé le mode strict du capcode, cela aura des effets négatifs évidents. Sur SMLQA, 50256-strict-oneword-nocapcode obtient un score de 21,2 et sur SQuAD, il obtient un score de 23,8, tandis que 50256-strict-oneword obtient respectivement 16,8 et 20,0. La raison est évidente : le mode d'optimisation strict empêche la fusion des capcodes et des jetons de mots, ce qui nécessite davantage de jetons pour représenter le même texte, ce qui entraîne une réduction de 8 % du ratio de mots. En fait, strict-nocapcode ressemble plus au mode cohérent qu'au mode strict. Dans divers indicateurs, 50256-consistent-oneword et 50256-strict-oneword-nocapcode sont presque égaux
Dans la plupart des cas, les chercheurs ont conclu que le modèle est utile pour apprendre la signification des jetons contenant des signes de ponctuation et des mots Pas trop difficile . Autrement dit, le modèle de cohérence a une précision grammaticale plus élevée et moins d’erreurs grammaticales que le modèle équilibré. Tout bien considéré, les chercheurs recommandent à chacun d’utiliser le mode cohérence. Le mode strict ne peut être utilisé qu'avec le capcode désactivé
Impact sur la précision de la syntaxe
Comme mentionné ci-dessus, le mode cohérent a une précision de syntaxe plus élevée (moins d'erreurs de syntaxe) que le mode équilibré). Cela se reflète dans la très légère corrélation négative entre le ratio de mots et la grammaire, comme le montre la figure ci-dessous. Au-delà de cela, le point le plus remarquable est que les résultats de syntaxe pour GPT-2 tokenizer et tiktoken p50k_base sont terribles (respectivement) par rapport au 50256-strict-oneword-nocapcode de TokenMonster (98,6 % et 98,1 % et 97,5 %). . Les chercheurs ont d’abord pensé qu’il s’agissait simplement d’une coïncidence, mais plusieurs échantillons ont produit la même gamme de résultats. On ne sait pas quelle en est la cause.
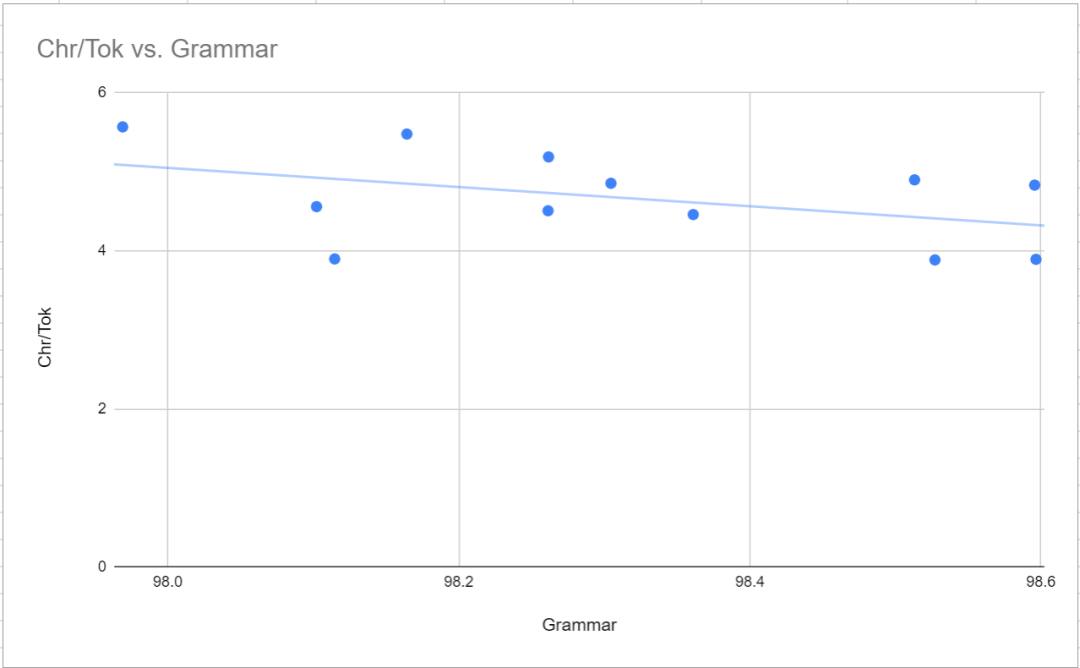
Impact sur MTLD
MTLD est utilisé pour représenter la diversité linguistique de l'exemple de texte généré. Cela semble être étroitement lié au paramètre n_embed et non à des fonctionnalités telles que la taille du vocabulaire, le mode d'optimisation ou le nombre maximum de mots par jeton. Cela est particulièrement évident dans le modèle équilibré 6000 (n_embd est 864) et le modèle cohérent 8000 (n_embd est 900)
Parmi les modèles moyens, p50k_base a le MTLD le plus élevé à 43,85, mais a également le score de syntaxe le plus bas. . La raison n’est pas claire, mais les chercheurs pensent que cela pourrait être dû à une étrange sélection de données d’entraînement.
Discussion sur SQuAD
Le but du benchmark SQuAD est d'évaluer la capacité d'un modèle à extraire des données d'un morceau de texte. La méthode spécifique consiste à fournir un paragraphe de texte et à poser une question, exigeant que la réponse soit trouvée dans le paragraphe de texte. Les résultats des tests ne sont pas très significatifs, il n’y a pas de tendances ou de corrélations évidentes et ils ne sont pas affectés par les paramètres globaux du modèle. En fait, le modèle équilibré à 8 000 avec 91 millions de paramètres a obtenu des résultats plus élevés dans SQuAD que le modèle à un mot cohérent à 50 256 avec 354 millions de paramètres. La raison en est peut-être qu'il n'y a pas suffisamment d'exemples de ce style ou qu'il y a trop de paires question-réponse dans l'ensemble de données de réglage fin. Ou peut-être que c'est juste un point de référence loin d'être idéal
Discussion sur SMLQA
Le point de référence SMLQA teste la « valeur de vérité » en posant des questions de bon sens avec des réponses objectives, telles que « La capitale de quel pays est Jakarta ? » et "Qui a écrit les livres de Harry Potter ?"
Il convient de noter que dans ce test de référence, les deux tokenizers de référence, GPT-2 Tokenizer et p50k_base, ont très bien fonctionné. Les chercheurs pensaient initialement avoir perdu des mois de temps et des milliers de dollars, mais il s’est avéré que tiktoken fonctionnait mieux que TokenMonster. Or, il s’avère que le problème est lié au nombre de mots correspondant à chaque jeton. Ceci est particulièrement évident dans le modèle "Medium" (MEDIUM), comme le montre la figure ci-dessous
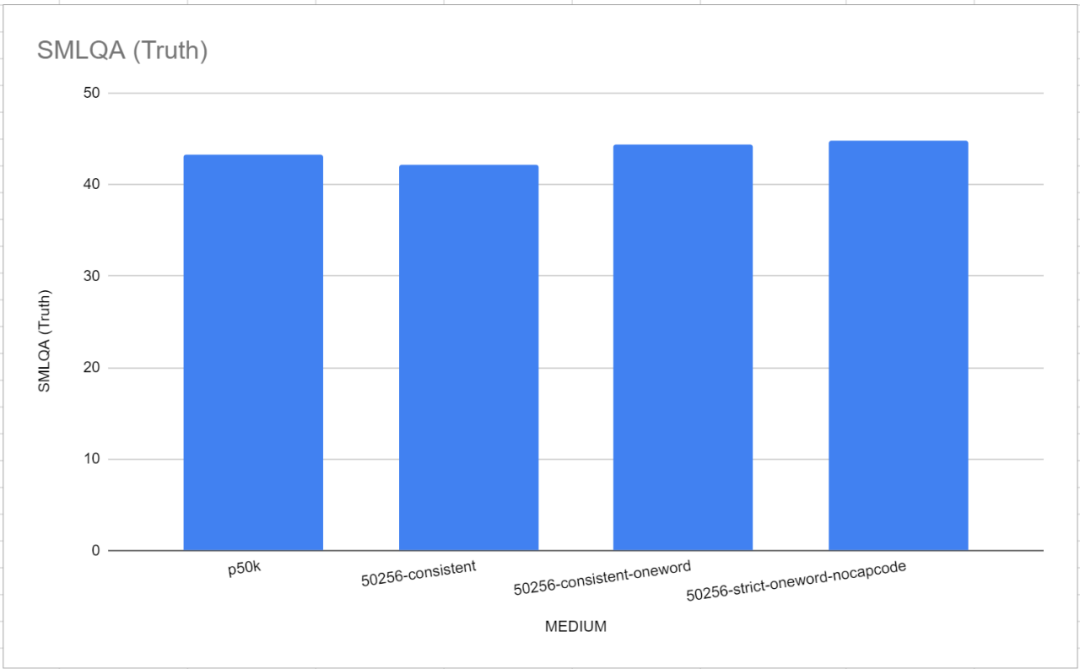
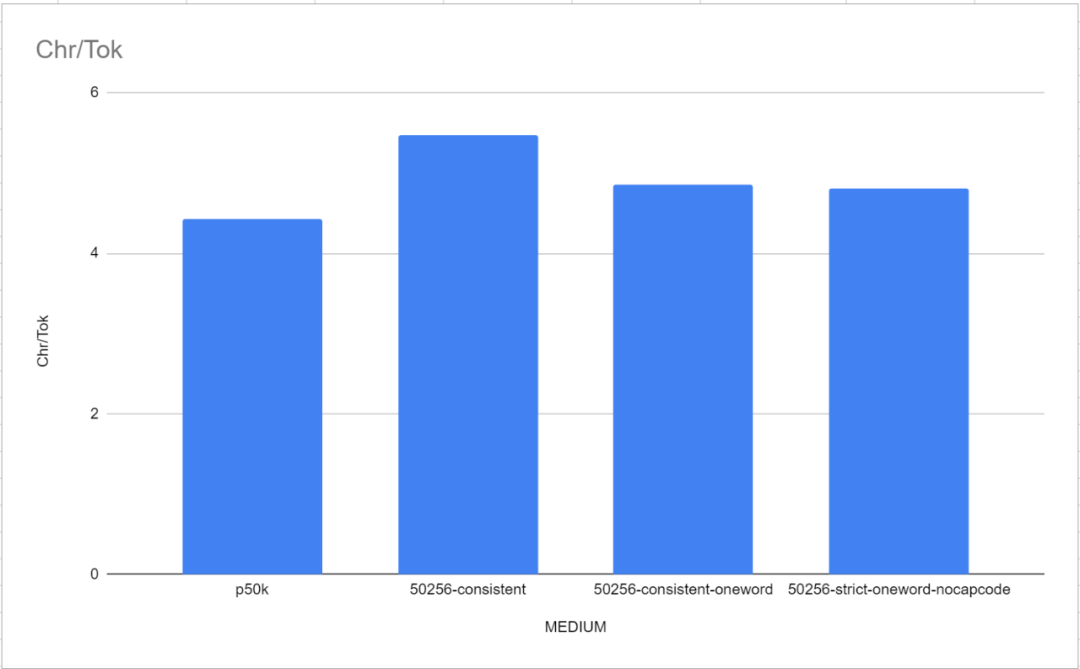 Les performances du vocabulaire à mot unique sont légèrement meilleures que celles par défaut de TokenMonster, chaque jeton correspondant à plusieurs liste de vocabulaire de mots.
Les performances du vocabulaire à mot unique sont légèrement meilleures que celles par défaut de TokenMonster, chaque jeton correspondant à plusieurs liste de vocabulaire de mots.
Une autre observation importante est que lorsque la taille du vocabulaire est inférieure à 32 000, la taille du vocabulaire affectera directement la vraie valeur, même si le paramètre n_embd du modèle est ajusté pour compenser la réduction de la taille du modèle. Ceci est contre-intuitif car les chercheurs pensaient à l'origine que 16 000 équilibré avec n_embd de 864 (paramètre de 121,34 millions) et 8 000 cohérent avec n_embd de 900 (paramètre de 123,86 millions) serait meilleur que 50 256 cohérent avec n_embd de 768 (paramètre de 768). 121,34 millions), 123,59 millions) ont obtenu de meilleurs résultats, mais ce n'est pas le cas - les deux ont obtenu des résultats bien pires (13,7 et 15,1 contre 16,4 pour la cohérence de 50256). Cependant, les deux modèles « ajustés » ont reçu le même temps de formation, ce qui a entraîné une réduction significative des temps de pré-formation (bien que le même temps)
Un petit modèle avec 12 couches de têtes d'attention, 12 couches de couches de transformateur Modèles
Les chercheurs ont formé 12 modèles sur l'architecture NanoGPT par défaut. L'architecture est basée sur l'architecture GPT-2 avec 12 têtes d'attention et 12 couches, et la taille des paramètres d'intégration est de 768. Aucun de ces modèles n’a atteint un état de convergence. En termes simples, ils n’ont pas atteint leur capacité d’apprentissage maximale. Le modèle a été entraîné pour 400 000 itérations, mais il semble que 600 000 itérations soient nécessaires pour atteindre une capacité d’apprentissage maximale. Les raisons de cette situation sont très simples, l'une est le problème budgétaire, et l'autre est l'incertitude du point de convergence
Les résultats du petit modèle :
La corrélation de Pearson du petit modèle :
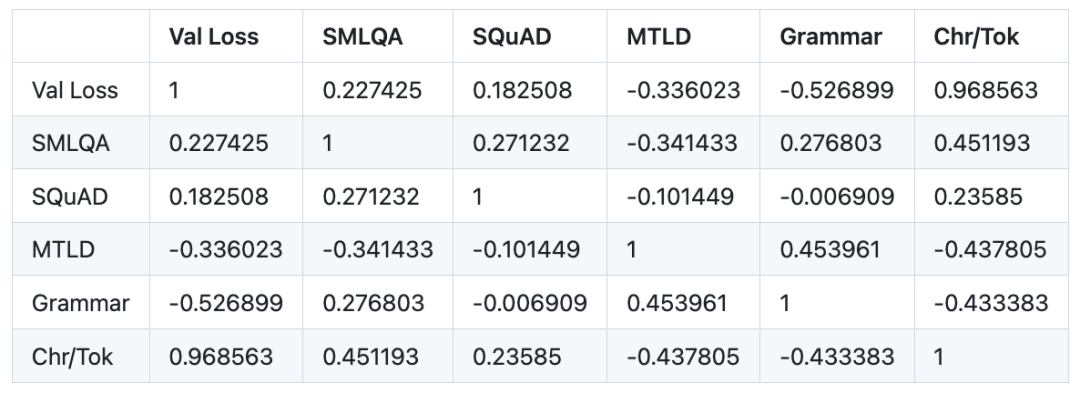
Conclusion du petit modèle :
Contenu réécrit : Le niveau de vocabulaire optimal a été atteint lorsque la taille du vocabulaire était de 32 000. Dans l'étape d'augmentation du vocabulaire de 8 000 à 32 000, l'augmentation du vocabulaire améliore la précision du modèle. Cependant, lorsque la taille du vocabulaire passe de 32 000 à 50 257, les paramètres totaux du modèle augmentent également en conséquence, mais l'amélioration de la précision n'est que de 1 %. Après avoir dépassé 32 000, le gain diminue rapidement
Une mauvaise conception du tokenizer aura un impact sur la précision du modèle, mais pas sur l'exactitude grammaticale ou la diversité linguistique. Performances sur le terrain pour les tokenizers avec des règles grammaticales plus complexes (telles que des jetons correspondant à plusieurs mots, des combinaisons de mots et de ponctuation, des jetons d'encodage de capcode et une réduction totale du vocabulaire) dans la plage de paramètres de 90 millions à 125 millions. Cependant, cette conception sophistiquée du tokenizer n’a pas eu d’impact statistiquement significatif sur la diversité linguistique ou l’exactitude grammaticale des textes générés. Même un modèle compact, tel qu’un modèle comportant 90 millions de paramètres, peut exploiter efficacement des marqueurs plus complexes. Un vocabulaire plus complexe prend plus de temps à apprendre, ce qui réduit le temps nécessaire pour acquérir des informations liées aux faits de base. Puisqu'aucun de ces modèles n'a été entièrement formé, le potentiel d'une formation continue pour combler l'écart de performance reste à voir
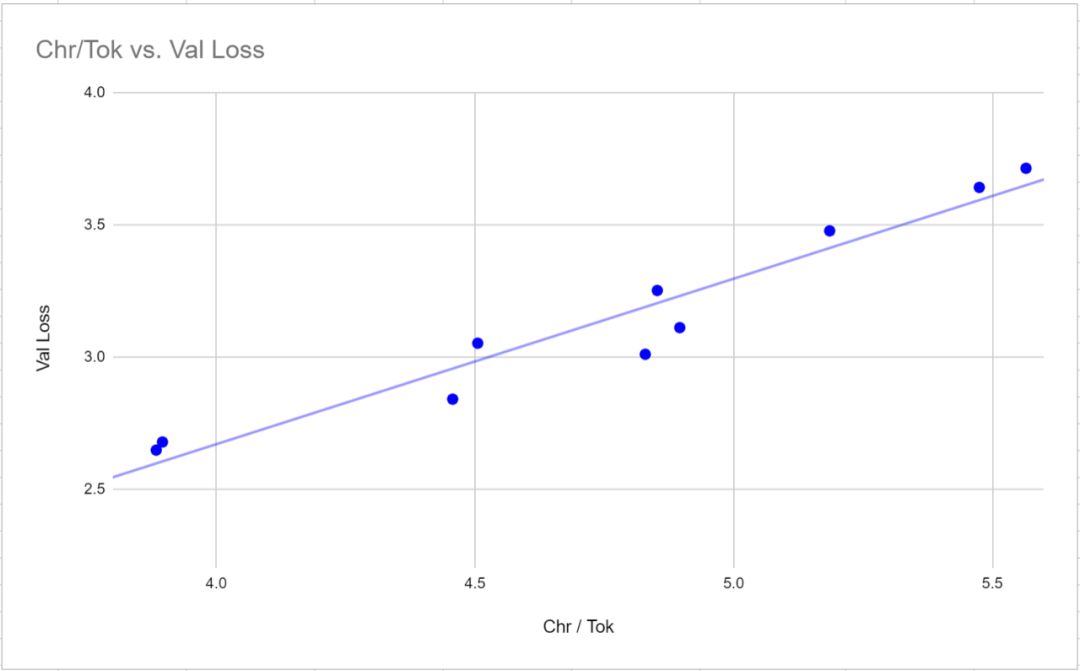
Réécrit en chinois : 3. La perte de validation n'est pas une mesure valide pour comparer des modèles utilisant différents tokenizers. La perte de validation a une très forte corrélation (corrélation de Pearson de 0,97) avec le ratio de mots (le nombre moyen de caractères par jeton) pour un tokenizer donné. Pour comparer les valeurs de perte entre les tokeniseurs, il peut être plus efficace de mesurer la perte par rapport aux personnages plutôt qu'aux jetons, puisque la valeur de perte est proportionnelle au nombre moyen de caractères correspondant à chaque jeton
4. ne convient pas comme métrique d'évaluation pour les modèles de langage, car ces modèles de langage sont formés pour générer des réponses de longueur variable (l'achèvement est indiqué par un marqueur de fin de texte). En effet, plus la séquence de texte est longue, plus la pénalité de la formule F1 est sévère. Les scores F1 ont tendance à produire des modèles de réponse plus courts
Tous les modèles (à partir de 90 millions de paramètres) ainsi que tous les tokenizers testés (d'une taille allant de 8 000 à 50 257) ont démontré qu'ils peuvent produire une capacité de réponse grammaticalement cohérente. Bien que ces réponses soient souvent incorrectes ou hallucinatoires, elles sont toutes relativement cohérentes et démontrent une compréhension du contexte contextuel.
La diversité lexicale et la précision grammaticale du texte généré augmentent considérablement à mesure que la taille de l'intégration augmente et présente une légère corrélation négative avec le mot. rapport. Cela signifie qu'un vocabulaire avec un rapport mot à mot plus grand rendra l'apprentissage de la diversité grammaticale et lexicale légèrement plus difficile
7 Lors de l'ajustement de la taille des paramètres du modèle, le rapport mot à mot est lié à SMLQA (Ground). Truth) ou SQuAD (Information Extraction) ) Il n'y a pas de corrélation statistiquement significative entre les benchmarks. Cela signifie qu'un tokenizer avec un rapport mot à mot plus élevé n'aura pas d'impact négatif sur les performances du modèle.
Par rapport à la catégorie « équilibrée », la catégorie « cohérente » semble avoir des performances légèrement meilleures sur le benchmark SMLQA (Ground Truth), mais bien pires sur le benchmark SQuAD (Information Extraction). Bien que davantage de données soient nécessaires pour confirmer cela
Modèle moyen avec 16 couches de têtes d'attention, 24 couches de couches de transformateur
Après avoir formé et comparé le petit modèle, l'étude Le chercheur a clairement constaté que les résultats mesurés reflétaient la vitesse d'apprentissage du modèle plutôt que la capacité d'apprentissage du modèle. De plus, les chercheurs n’ont pas optimisé le potentiel de calcul du GPU car les paramètres NanoGPT par défaut ont été utilisés. Afin de résoudre ce problème, les chercheurs ont choisi d’utiliser un tokenizer avec 50 257 jetons et un modèle de langage moyen pour étudier quatre variantes. Les chercheurs ont ajusté la taille du lot de 12 à 36 et ont réduit la taille des blocs de 1 024 à 256 pour garantir la pleine utilisation des capacités VRAM du GPU de 24 Go. Ensuite, 600 000 itérations ont été réalisées au lieu de 400 000 comme dans le modèle plus petit. La pré-formation pour chaque modèle a duré en moyenne un peu plus de 18 jours, soit trois fois les 6 jours requis pour les modèles plus petits.
La formation du modèle à la convergence réduit considérablement la différence de performances entre les vocabulaires plus simples et plus complexes. Les résultats des benchmarks SMLQA (Ground Truth) et SQuAD (Data Extraction) sont très proches. La principale différence est que la cohérence 50256 présente l'avantage d'un ratio de mots 23,5 % plus élevé que p50k_base. Cependant, pour les vocabulaires comportant plusieurs mots par jeton, le coût de performance des valeurs de vérité est inférieur, mais cela peut être résolu en utilisant la méthode dont j'ai parlé en haut de la page. Résultats des modèles dans
:
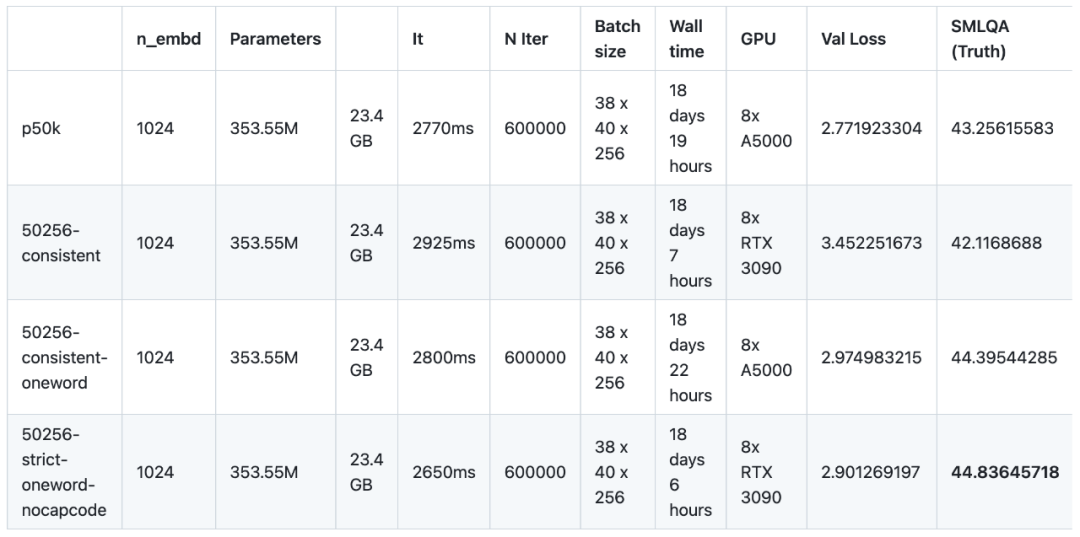
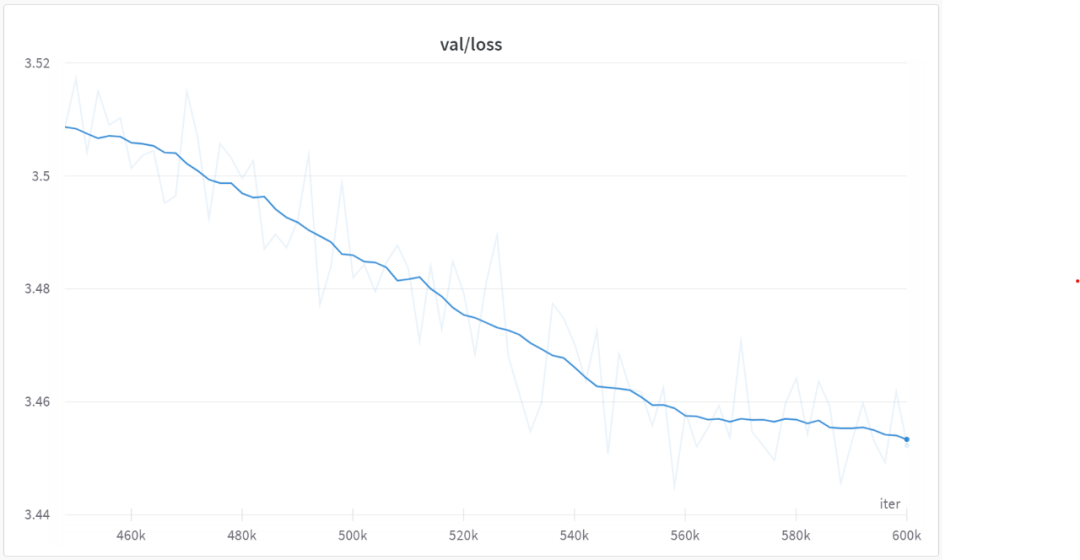
Après 560 000 itérations, tous les modèles ont commencé à converger, comme le montre la figure ci-dessous :
Outlook
Dans la prochaine étape, nous utiliserons le code anglais-32000-consistent pour former et comparer le modèle de MEDIUM. Ce vocabulaire contient 80 % de jetons de mots et 20 % de jetons multi-mots
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!