
Maison >Périphériques technologiques >IA >Chien robot CMU, debout à l'envers et descendant les escaliers ! La version est open source
Chien robot CMU, debout à l'envers et descendant les escaliers ! La version est open source

- 王林avant
- 2023-10-04 11:21:081276parcourir
Il y a vraiment trop d'astuces pour les chiens robots——
Mais aujourd'huiJ'étais encore étonné.
Les derniers résultats de la CMU permettent aux chiens d'apprendre directement :
le saut en hauteur deux fois la longueur du corps, le saut en longueur, le poirier et même le poirier dans les escaliers
Pas grand chose à dire, il suffit de montrer la photo pour expérimentez-le Vague :

△ C'est le saut en longueur

△ C'est le saut en hauteur

△ Le poirier

Le contenu qui doit être réécrit est : Appui renversé les escaliers
Je dois dire, surtout la "lutte" dans la section de saut en hauteur rend le chien particulièrement émouvant.
En plus de ces opérations, la CMU a également diffusé plusieurs vidéos de parkour, complètement autonomes.
C'est une sensation tellement rafraîchissante de marcher sur la crête, de passer par la brèche et de traverser la pente

Même s'il y a quelques "erreurs" au milieu, cela n'affectera pas sa progression immédiate

laugh Rat a même organisé un stress test, et le résultat a bien sûr été "réussi" ~

La chose la plus étonnante est que, selon la CMU, toutes les opérations extrêmes ci-dessus sont réalisées par un seul réseau neuronal.
Frère LeCun a dû lever le pouce après avoir entendu cela.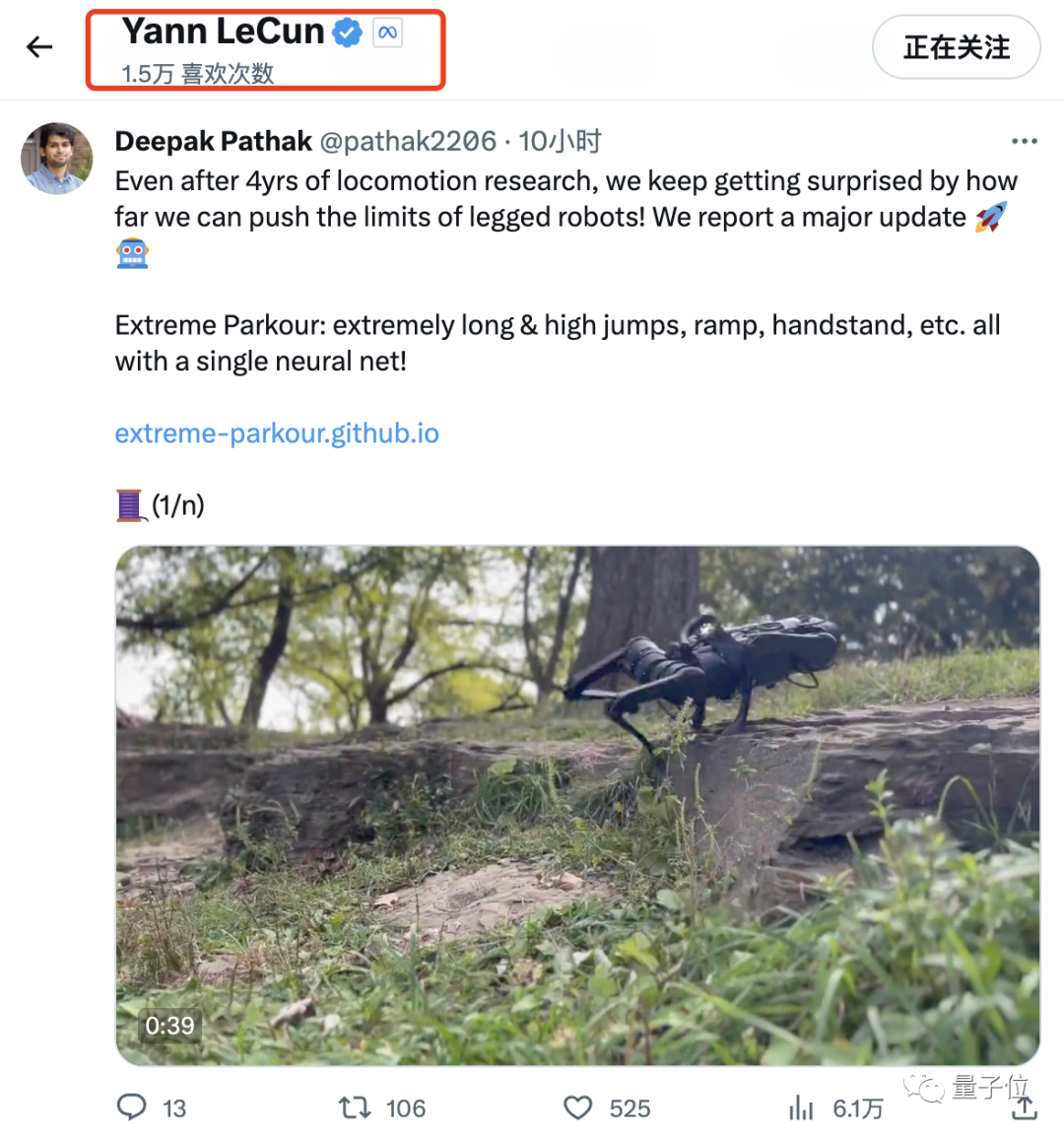
sim2real pour obtenir un contrôle précis du pied et des défis pour maximiser les avantages mécaniques.
Parmi eux, Gym est utilisé pour le simulateurDe plus, le poirier. Évidemment, marcher sur deux pattes est beaucoup plus difficile que marcher sur quatre Cependant, le chien robot de l'Université Carnegie Mellon utilise la même approche de base pour accomplir les deux tâches en même temps, et est même capable de descendre les escaliers tout en maintenant l'état inverséTroisièmement, pour l'opération de parkour
(au centre de cette recherche), le chien robot doit décider de sa propre direction grâce à une coordination précise des « muscles oculaires », plutôt que d'obéir aux commandes humaines. Par exemple, lorsqu'il passe deux rampes d'affilée, il doit sauter sur la rampe selon un angle très spécifique, puis changer immédiatement de direction
Pour apprendre ces directions correctes, la CMU utilise 
( Mixed Teacher Student) système pour enseigner le chien robot. Le système ne l'adoptera que si la direction prédite est proche de la vraie valeur
Plus précisément, le système est divisé en deux étapes: Dans la première étape, RL est d'abord utilisé pour apprendre une stratégie de mouvement . Le processus peut accéder à certaines informations privilégiées. En plus des paramètres environnementaux et des points de scan (scandots)
, CMU fournit également despoints de marquage (waypoints) de manière appropriée pour le chien robot, dans le but de guider le chien. orientation générale.
Ensuite, l'adaptation en ligne régularisée (Adaptation en ligne régularisée, ROA) est utilisée pour former l'évaluateur à récupérer les informations environnementales à partir de l'historique d'observation.
Dans la deuxième étape, la stratégie est extraite des points de scan (scandots) , et le système décidera de manière autonome comment avancer en fonction de la stratégie et des informations de profondeur, émettant ainsi des commandes motrices de manière agile.
L'ensemble du processus est comme "l'enseignant enseigne, les élèves apprennent par analogie"
En plus de ce système, puisque le parkour nécessite une variété d'actions différentes pour franchir les obstacles, il est également important de concevoir une fonction de récompense spécifique pour chaque obstacle. Un mal de tête.
Ici, l'auteur a choisi de formuler une fonction de récompense de produit interne unifiée et simple pour toutes les tâches.
Il peut générer automatiquement diverses récompenses et s'adapter pleinement à différentes formes de terrain

Sans cela, les performances du chien seraient comme ceci :

Enfin, la CMU également Une nouvelle méthode de double distillation est proposée pour extraire instructions de mouvement agiles et directions avant fluctuantes rapidement à partir des images de profondeur. De même, sans lui, le chien se comporte comme un ivrogne :
 Après les étapes ci-dessus, le chien a enfin appris un nouveau parkour autonome et a pu effectuer des actions difficiles
Après les étapes ci-dessus, le chien a enfin appris un nouveau parkour autonome et a pu effectuer des actions difficiles
N'est-ce pas excitant ? Ne vous inquiétez pas :
CMU
a tous les résultats ci-dessus en open source(regardez cette date, il fait encore chaud).
 Parallèlement, ce document a également été publié. Vous pouvez obtenir la
Parallèlement, ce document a également été publié. Vous pouvez obtenir la
Introduction à l'auteur à la fin
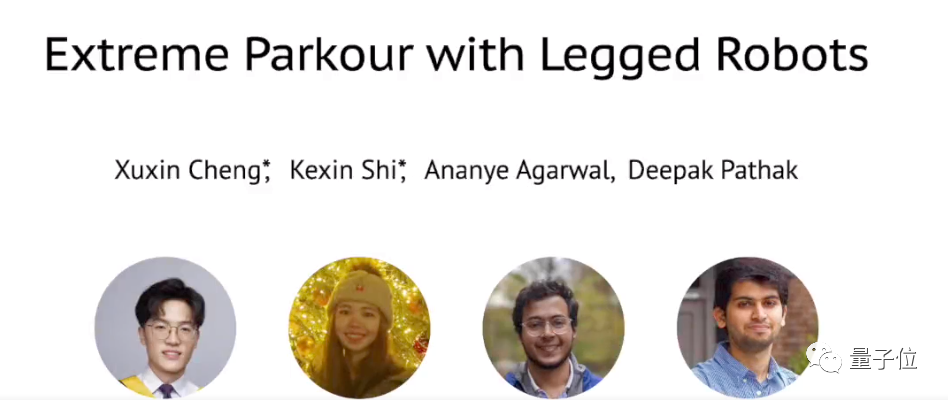
Cette recherche a été réalisée par l'Université Carnegie Mellon, et un total de quatre auteurs ont participé
 Parmi eux
Parmi eux
: L'un s'appelle Xuxin Cheng. Ce travail a été réalisé alors qu'il était étudiant diplômé à la CMU. Il est maintenant doctorant à l'Université de Californie à San Diego
(UCSD), et son superviseur est Wang Xiaolong . L'autre s'appelle Shi Kexin, chercheur invité au CMU Robotics Institute. Elle est diplômée de l'Université Jiaotong de Xi'an avec un baccalauréat.
Lien de la page d'accueil du projet : https://extreme-parkour.github.io/ (y compris des liens vers des articles, des codes, etc.)Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment enregistrer des images PS au format AI
- Les fichiers ai peuvent-ils être ouverts avec ps ?
- Raisons pour lesquelles l'IA ne peut pas colorier en temps réel
- Quel est le format de fichier .ai ?
- Le chien robot Max, développé par Tencent, a été mis à niveau pour « courir et sauter » pour effectuer des actions d'évitement d'obstacles.