
Maison >Périphériques technologiques >IA >Plus il y a de mots dans le document, plus le modèle sera excité ! KOSMOS-2.5 : grand modèle de langage multimodal pour la lecture d''images riches en texte'
Plus il y a de mots dans le document, plus le modèle sera excité ! KOSMOS-2.5 : grand modèle de langage multimodal pour la lecture d''images riches en texte'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-29 20:13:10745parcourir
Une tendance claire est actuellement à la construction de modèles plus grands et plus complexes avec des dizaines/centaines de milliards de paramètres capables de générer un résultat linguistique impressionnant
Cependant, les grands modèles linguistiques existants sont principalement axés sur les informations textuelles et incapables de comprendre les informations visuelles.
Ainsi, les progrès dans le domaine des grands modèles linguistiques multimodaux (MLLM) visent à remédier à cette limitation, les MLLM fusionnent les informations visuelles et textuelles en un seul modèle basé sur Transformer, permettant au modèle de s'adapter aux deux modalités d'apprentissage et de génération de contenu.
Les MLLM montrent du potentiel dans diverses applications pratiques, notamment la compréhension d'images naturelles et la compréhension d'images textuelles. Ces modèles exploitent la modélisation du langage comme interface commune pour gérer les problèmes multimodaux, leur permettant de traiter et de générer des réponses basées sur des entrées textuelles et visuelles.
Cependant, actuellement, l'accent est mis principalement sur les MLLM d'images naturelles de faible résolution, qui sont dense pour le texte Il y a eu relativement peu de recherches sur les images. Par conséquent, utiliser pleinement la pré-formation multimodale à grande échelle pour traiter les images de texte est devenu une direction importante de la recherche MLLM
En incorporant des images de texte dans le processus de formation et en développant des modèles basés sur du texte et des informations visuelles, nous peut ouvrir de nouvelles voies impliquant de nouvelles possibilités haute résolution pour les applications multimodales d'images à forte densité de texte.
 Pictures
Pictures
Adresse papier : https://arxiv.org/abs/2309.11419
KOSMOS-2.5 est un modèle de langage multimodal à grande échelle basé sur des images denses en texte, qui est développé dans KOSMOS- Développé sur la base de 2, il met en évidence les capacités de lecture et de compréhension multimodales des images à forte teneur en texte (Multimodal Literate Model).
La proposition de ce modèle met en évidence ses excellentes performances dans la compréhension des images à forte teneur en texte, comblant ainsi le fossé entre la vision et le texte
En même temps, elle marque également l'évolution du paradigme de tâche par rapport au codage précédent. Architecture de décodeur-décodeur à architecture de décodeur pure
L'objectif de KOSMOS-2.5 est de permettre un traitement transparent des données visuelles et textuelles dans des images riches en texte afin de comprendre le contenu de l'image et de générer des descriptions textuelles structurées.
 Figure 1 : Présentation de KOSMOS-2.5
Figure 1 : Présentation de KOSMOS-2.5
KOSMOS-2.5 est un modèle multimodal, comme le montre la figure 1, qui vise à utiliser un cadre unifié pour gérer deux tâches étroitement liées
La première tâche consiste à générer un bloc de texte spatialement conscient, c'est-à-dire à générer simultanément le contenu et le cadre de coordonnées du bloc de texte. Ce qui doit être réécrit est : La première tâche consiste à générer un bloc de texte spatialement conscient, c'est-à-dire à générer simultanément le contenu du bloc de texte et la boîte de coordonnées
La deuxième tâche consiste à générer une sortie de texte structurée à l'aide du format Markdown, et capturez divers styles et structures
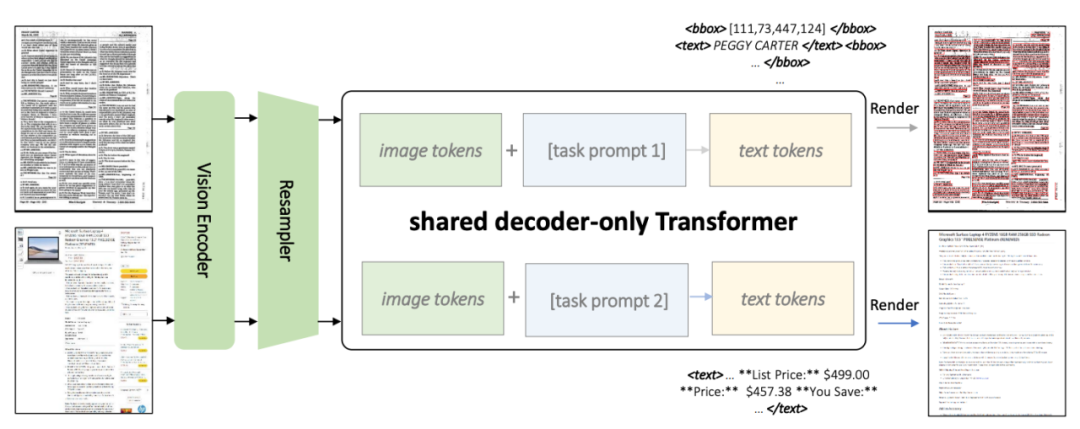 Figure 2 : diagramme d'architecture KOSMOS-2.5
Figure 2 : diagramme d'architecture KOSMOS-2.5
Comme le montre la figure 2, les deux tâches utilisent une architecture Transformer partagée et des astuces spécifiques aux tâches
KOSMOS-2.5 combine un encodeur visuel basé sur ViT (Vision Transformer) avec un décodeur basé sur l'architecture Transformer, connecté via un module de rééchantillonnage.
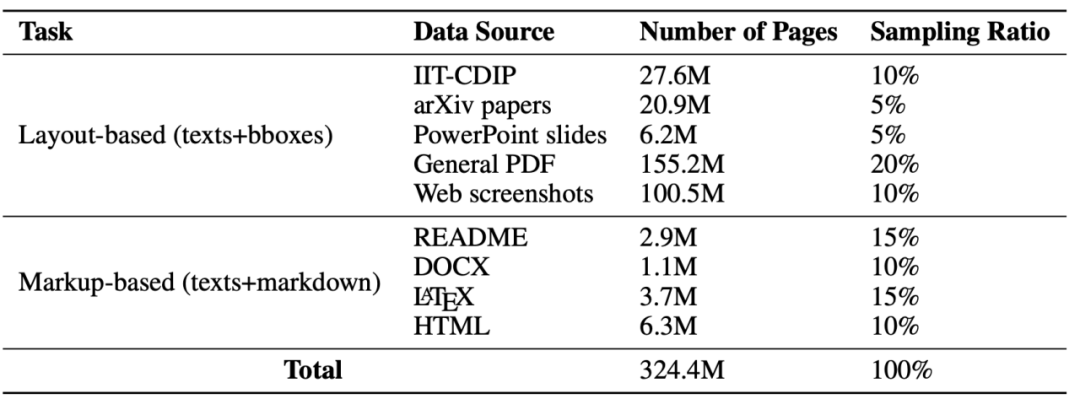 Figure 3 : Ensemble de données de pré-entraînement
Figure 3 : Ensemble de données de pré-entraînement
Afin d'entraîner ce modèle, l'auteur a préparé un énorme ensemble de données d'une taille de 324,4 M, comme le montre la figure 3
 Figure 4 : Exemple d'exemple d'entraînement pour des lignes de texte avec des cadres de délimitation
Figure 4 : Exemple d'exemple d'entraînement pour des lignes de texte avec des cadres de délimitation
 Figure 5 : Exemple d'exemple d'entraînement au format Markdown
Figure 5 : Exemple d'exemple d'entraînement au format Markdown
Cet ensemble de données contient différents types d'images denses en texte, y compris des lignes de texte avec des cadres de délimitation et du texte brut au format Markdown. Les figures 4 et 5 sont des exemples de visualisations de formation.
Cette méthode de formation multitâche améliore les capacités multimodales globales de KOSMOS-2.5
 [Figure 6] Expérience de reconnaissance de texte de bout en bout au niveau du document
[Figure 6] Expérience de reconnaissance de texte de bout en bout au niveau du document
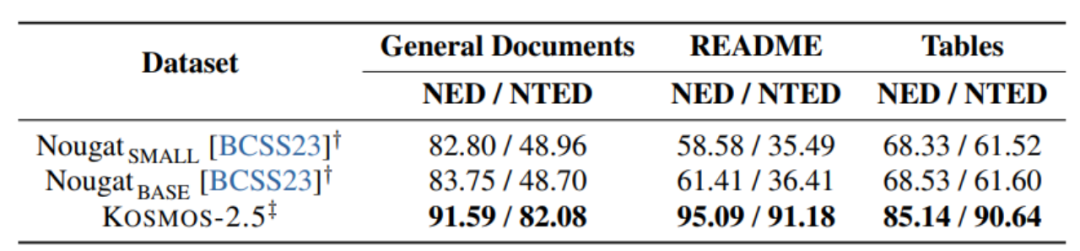 Figure 7 : Expérience sur la génération de texte au format Markdown à partir d'images
Figure 7 : Expérience sur la génération de texte au format Markdown à partir d'images
Comme le montrent les figures 6 et 7, KOSMOS- 2.5 Il est évalué sur deux tâches : la reconnaissance de texte de bout en bout au niveau du document et la génération de texte au format Markdown à partir d'images.
KOSMOS-2.5 fonctionne bien dans le traitement des tâches d'image à forte teneur en texte, et les résultats expérimentaux le démontrent
 Figure 8 : Exemple d'affichage d'entrée et de sortie de KOSMOS-2.5
Figure 8 : Exemple d'affichage d'entrée et de sortie de KOSMOS-2.5
KOSMOS- 2.5 le démontre des capacités prometteuses dans les scénarios d'apprentissage en quelques plans et en zéro plan, ce qui en fait un outil polyvalent pour des applications pratiques dans le traitement d'images riches en texte. Il peut être considéré comme un outil polyvalent capable de gérer efficacement des images riches en texte et de montrer des capacités prometteuses dans le cas de l'apprentissage en quelques coups et de l'apprentissage en zéro coup. L'auteur souligne que le réglage fin des instructions est une solution très prometteuse. La méthode prospect peut atteindre une capacité d’application plus large du modèle.
Dans le domaine de la recherche plus large, une direction importante réside dans le développement ultérieur de la capacité à étendre les paramètres du modèle.
Alors que les tâches continuent de croître en portée et en complexité, la mise à l'échelle des modèles pour gérer de plus grandes quantités de données est essentielle pour le développement de modèles multimodaux à forte intensité de texte.
L'objectif ultime est de développer un modèle capable d'interpréter efficacement les données visuelles et textuelles et de généraliser avec succès à des tâches multimodales plus gourmandes en texte.
Lors de la réécriture du contenu, il doit être réécrit en chinois et la phrase originale n'a pas besoin d'apparaître
https://arxiv.org/abs/2309.11419
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont les trois modèles de données de la base de données ?
- Comment supprimer des pages supplémentaires dans un document Word
- Comment augmenter la taille de la police d'un document Word au-delà de 72
- Comment taper des lignes horizontales dans des documents
- Quel est le modèle de couleur utilisé par les écrans d'ordinateur ?